Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Web, Ops & Data - Octobre 2020
kubernetes ingress yaml pipeline gitlab traefik rootless mesh yq jq devops data maturité mariadb s3 flows warp10 timeseries influxdb pulsar amqp mqtt kafka python git vscode arm nvidiaDes nouvelles du Paris Time Series Meetup : l’éditions 6 sur TimescaleDB et l’édition 7 sur QuestDB
CI/CD
- 3 YAML tips for better pipelines : la troisième est certainement la plus intéressante - il est possible d’avoir des mécanismes de “composabilité” / “héritage” avec YAML et Gitlab. Si les
includeetextendssont déjà sympathiques, lesanchorsont l’air de faire des choses intéressantes aussi !
Code
- What’s New In Python 3.9 et un thread twitter qui donne des exemples des principales nouveautés : au programme nouvelle syntaxe pour la fuston des dictionnaires, des méthides pour supprimer des suffixes/préfixes sur les strings, du typage et plein d’autres améliorations et corrections.
- Fortunately, I don’t squash my commits : s’il peut être tentant sur une MR/PR de faire un squash des commits, l’article vous confortera dans l’idée que ce n’est pas une bonne idée. En écrasant l’historique des commits, on y perd sur nos capacités de debug. Par ailleurs, il est conseillé de faire des petits commits pour capturer un ensemble de changements traduisant un moment précis du développement.
Container et orchestration
- Kubernetes Ingress Goes GA : l’apparition de IngressClassName dans k8s 1.19 va plus loin qu’un simple renommage de champ comme je l’avais compris initialement. C’est une vraie ressource et cela ouvre aussi des possibilités. Avant de l’utiliser, vérifiez aussi que vos ingress controller le supporte (en plus d’attendre d’être en 1.19)
- Houston, we have Plugins! Traefik 2.3 Announcement : la version 2.3 dont on a déjà parlé ici, est arrivé en version stable avec son support des plugins, son intégration avec Traefik Pilot, le support d’Amazone ECS et le support de la ressource IngressClassName. Au passage, Containous, la société éditrice de Traefik s’appelle maintenant Traefik Labs.
- Introducing Traefik Pilot 1.0: the Traefik Control Center : Version 1.0 de ce nouveau “Control Plane” de Traefik qui permet d’avoir une vision globale sur ses instances traefik, d’utiliser les plugins et d’avoir un monitoring et des alertes autour de la disponibilité, des performances et de la sécurité.
- Rootless mode : A voir si cela pourra être inclus dans la version 1.20 mais le rootless mode est clairement une tendance de fond dans kubernetes et les conteneurs en général. Si vous ne vous y êtes pas déjà mis, ne tardez pas !
- Announcing Traefik Mesh 1.4 - New Name, New Features : nouvelle version du service mesh par Traefik Labs et qui s’appelle maintenant Traefik Mesh (et non uniquement Maesh). Le reste des améliorations semble porter sur le filtrage des headers et des paths.
- yq : A command line tool that will help you handle your YAML resources better : vous voulez faire des opératoins sur des fichiers YAML sans faire un chart helm ou sortir kustomize, vous pouvez faire des choses minimalistes avec yq (le pendant yaml de jq).
- Bridge to Kubernetes GA, “bridge to kubernetes” est une extension pour vscode permettant de connecter une application tournant en local avec d’autres applications situées dans un ckuster kubernetes et faciliter ainsi l’expérience des développeurs.
Culture DevOps
- La culture de la résilience à travers le DevOps, DevPO, et DevQA : article intéressant de Paul Leclerq sur la résilience et la collaboration au sein d’une équipe.
Data
- How to Measure Your Organization’s Data Maturity : les différents stade de maturité de votre organisation concernant la gestion et l’exploitation des données.
- Announcing MQTT-on-Pulsar: Bringing Native MQTT Protocol Support to Apache Pulsar: Apache Pulsar, la plateforme de message distribué et de streaming, se dote d’un plugin “MQTT On Pulsar” (MoP) permettant ainsi de migrer vos applications MQTT sur Apache Pulsar. Après le plugin Kafka (KoP) il y a quelques mois en partenariat avec OVHCloud, Pulsar ajoute une corde à son arc pour devenir la plateforme universelle. Le protocole AMQP est déjà aussi supporté depuis plusieurs mois.
- Building An Event-Driven Orchestration Engine : retour d’expérience sur les raisons de la migration à Apache Pulsar e la simplificaiton apportée en ayant une platforme riche et complète (streaming + queue + fonctions + data tiering sur S3 + …)
Hardware
- NVidia’s Planned Acquisition of Arm Portends Radical Data Center Changes : une analyse assez en profondeur sur le rachat d’arm par nvidia et les autres acteurs du marché comme AMD.
IaC
- Announcing HashiCorp Terraform 0.14 Beta: la capacité à marquer des variables comme sensibles pour éviter que leur valeur soit visible dans les logs/diff/…, un diff plus concis, un lock sur les providers et des binaires disponibles pour arm64.
Monitoring
- Long-term store for Prometheus, with the combined power of SQL and PromQL : Timescale s’ajoute à la liste des solutions permettant un stockage long terme à vos données Prometheus. En plus de ce stockage long terme, elle fournit une couche d’analytics. Un connecteur récupère les données dans Prometheus et les injecte dans TimescaleDB. On en parle dans l’édition 6 du PTSM.
Pratique
- endoflife.date : recense les dates de fin de support de vos langages et technologies préférées. Tout n’est pas complètement à jour mais cela permet de récupérer rapidement les informations.
SQL
- Exciting and New Features in MariaDB 10.5 : évoqué au mois d’aout, le support de S3 dans MariaDB est disponible en version GA dans la version 10.5. D’autres améliorations existent comme le support du type INET6, des améliorations sur ColumnStore, la gestion des privilèges, le cluster Galera supporte complètement le GTID, du refactoring au niveau d’InnoDB et enfin les binaires mariadb vont enfin s’appeler mariadb et non plus mysql (avec une couche de compatibilité via des liens symboliques)
Time Series
- Introducing FLoWS, a functional language for Time Series Analytics : FLoWS est arrivé - il vous faudra utiliser une version 2.7.1+ de Warp10 pour profiter de cette approche fonctionnelle en alternative à Warpscript.
- How can you tell which Time Series Database is suited to your needs? : un petit rappel sur les critères à prendre en compte pour choisir une base de données séries temporelles ; j’avais déjà parlé du guide de Senx sur le sujet - il est disponible en fin de billet.
- InfluxDB 2.0 Release Candidate Now Available : la première Relese Candidate (RC0) pour InfluxDB 2.0 OSS avec le retour du moteur de stockage de la V1 - qui contrairement à ce que j’ai pu dire le mois dernier ne concernerait que la façon dont les données sont stockées sur disque et pas le reste d’une part et sera maintenu et amélioré par Influxdata d’autre part. Quelques changements sur le port (retour au port 8086). Pour ceux qui étaient en version alpha/beta, il faudra suivre une procédure de migration. La migration depuis une version 1.x n’est pas encore disponible, cela devrait être dans une prochaine RC. Vous pourrez tester néanmoins les API 1.x, les templates, une version récente de Flux ou encore les améliorations de la CLI.
- Release Announcement: InfluxDB 2.0.0 RC 1 : cette version apporte essentiellement l’upgrade des données 1.x vers 2.x et une mise à jour de Flux.
- Store and Access Time Series Data at Any Scale with Amazon Timestream – Now Generally Available - Getting Started with Amazon Timestream - AWS Releases Amazon Timestream into General Availability : AWS sort enfin son produit orienté time series après l’avoir annoncé il y a deux ans.
Sur la base des informations disponibles pour le moment :
- vous définissez une période de rétention en mémoire (entre 1h et 1 an) et une période de rétention sur stockage magnétique (1 jour à 200 ans),
- le requêtage des données se fait en SQL (via Presto ?),
- les données à requêter communément sont à mettre dans la même table,
- le join est limité à la même table,
- des mesures simples (pas de multi mesures pour un même enregistrement),
- une intégration avec l’écosystème comme telegraf, grafana, etc en plus de l’intégration avec différents composants AWS
Pour les moins bons côtés :
- pas d’UPDATE/DELETE sur vos données ; en cas de doublons, c’est le premier arrivé qui gagne
- pas de bulk import de vos données, donc pas de reprise de vos données existantes. En effet, il n’est pas possible d’ingérer des données plus vieille que la période en mémoire,
- dans la même veine, si un incident de production dépasse votre période de rétention, vous ne pourrez pas réinjecter vos données
- il ne semble pas possible de mettre à jour ses durées de rétention - donc pas de ménage possible ou d’ajustements en cours de route
Une solution a priori très orienté pour du monitoring et qui semble souffir des mêmes travers qu’InfluxDB avec InfluxQL et pourtant en passe d’être résolus avec Flux.
On devrait en parler plus en détail dans une prochaine édition du Paris Time Series Meetup avec des personnes de chez AWS ;-)
Work
- Virtual First Toolkit : toolkit proposé par Dropbox dans le cadre de leur passage non pas à Remote first mais à virtual first.
Warp 10 - Interactions avec une instance InfluxDB - FLoWS edition
warp10 timeseries influxdb warpscript warpfleet flowsMaintenant que FLoWS est officiellement disponible, je vous propose de revisiter l’article de la semaine dernière Warp 10 - Interactions avec une instance InfluxDB en utliisant FLoWS à la place de WarpScript pour se faire une idée.
Pré-requis: warpfleet
Installons déjà warpfleet, le gestionnaire de package conçu pour Warp 10.
# Installation de npm
sudo dnf install -y npm
# installation de warpfleet
sudo npm install -g @senx/warpfleet
# Vérification de la bonne installation de warpfleet
wf version
___ __ _______________ _____
__ | / /_____ __________________ ____/__ /___________ /_
__ | /| / /_ __ `/_ ___/__ __ \_ /_ __ /_ _ \ _ \ __/
__ |/ |/ / / /_/ /_ / __ /_/ / __/ _ / / __/ __/ /_
____/|__/ \__,_/ /_/ _ .___//_/ /_/ \___/\___/\__/
/_/ ™
version: 1.0.31
1.0.31
Installation de l’extension warp10-ext-influxdb
Sans trop rentrer dans les détails de warpfleet, il utilise un système de namespace appelés “Groups” pour ces packages et qui permettent de définir ses propres dépots. Pour l’extension warp10-ext-influxdb, le “group” est io.warp10.
Ce qui pour l"installation donne la commande suivante :
# Si votre utilisateur n'a pas accès à /path/to/warp10, il vous faudra utiliser sudo
(sudo) wf g -w /path/to/warp10 io.warp10 warp10-ext-influxdb
warpfleet va vous demander quelle version de l’extension vous souhaitez puis va procéder à son téléchargement et son installation.
Cela donne :
sudo wf g -w /opt/warp10 io.warp10 warp10-ext-influxdb
___ __ _______________ _____
__ | / /_____ __________________ ____/__ /___________ /_
__ | /| / /_ __ `/_ ___/__ __ \_ /_ __ /_ _ \ _ \ __/
__ |/ |/ / / /_/ /_ / __ /_/ / __/ _ / / __/ __/ /_
____/|__/ \__,_/ /_/ _ .___//_/ /_/ \___/\___/\__/
/_/ ™
version: 1.0.31
? Which revision do you want to retrieve? latest
✔ ext io.warp10:warp10-ext-influxdb#1.0.1-uberjar retrieved
✔ Download successful: gradle-wrapper.jar
✔ Download successful: gradle-wrapper.properties
✔ Download successful: gradlew
✔ Download successful: gradlew.bat
✔ Dependency warp10-ext-influxdb-1.0.1-uberjar.jar successfully deployed
✔ Done
Note: Pour éviter un bug dans la fonction INFLUXDB.UPDATE identifié lors de la rédaction de ce billet, assurez-vous d’avoir une version >= 1.0.1
Ensuite, il faut créer le fichier /path/to/warp10/etc/conf.d/90--influxdb-extension.conf et y ajouter la ligne suivante:
warpscript.extension.influxdb = io.warp10.script.ext.influxdb.InfluxDBWarpScriptExtension
Je préfère créer un fichier plutôt que d’éditer un fichier existant pour le suivi des mises à jour et j’ai utilisé le prefix 90 car il n’est pas utilisé par les fichiers de Warp10.
Relancer ensuite Warp 10 pour que le plugin soit chargé au démarrage de l’instance :
(sudo) /path/to/warp10/bin/warp10-standalone.init restart
Dans /path/to/warp10/logs/warp10.log, vous devriez voir apparaitre :
2020-09-17T10:59:23,742 main INFO script.WarpScriptLib - LOADED extension 'io.warp10.script.ext.influxdb.InfluxDBWarpScriptExtension'
Installation de FLoWS
Assurez-vous d’avoir préalablement une version >= 2.7.1 de Warp 10
sudo wf g -w /opt/warp10 io.warp10 warp10-ext-flows
___ __ _______________ _____
__ | / /_____ __________________ ____/__ /___________ /_
__ | /| / /_ __ `/_ ___/__ __ \_ /_ __ /_ _ \ _ \ __/
__ |/ |/ / / /_/ /_ / __ /_/ / __/ _ / / __/ __/ /_
____/|__/ \__,_/ /_/ _ .___//_/ /_/ \___/\___/\__/
/_/ ™
version: 1.0.31
? Which revision do you want to retrieve? latest
✔ ext io.warp10:warp10-ext-flows#0.1.0-uberjar retrieved
✔ Download successful: gradle-wrapper.jar
✔ Download successful: gradle-wrapper.properties
✔ Download successful: gradlew
✔ Download successful: gradlew.bat
✔ Dependency warp10-ext-flows-0.1.0-uberjar.jar successfully deployed
warpscript.extension.flows = io.warp10.ext.flows.FLoWSWarpScriptExtension
? Choose what you want to add (Press <space> to select, <a> to toggle all, <i> to invert selection)warpscript.extension.flows = io.warp10.ext.flows.FLoWSWarpScriptExtension
✔ warpscript.extension.flows = io.warp10.ext.flows.FLoWSWarpScriptExtension added to /opt/warp10/etc/conf.d/io.warp10-warp10-ext-flows.conf
✔ Done
Relancer ensuite Warp 10 pour que le plugin soit chargé au démarrage de l’instance :
(sudo) /path/to/warp10/bin/warp10-standalone.init restart
Dans /path/to/warp10/logs/warp10.log, vous devriez voir apparaitre :
2020-10-08T10:59:51,288 main INFO script.WarpScriptLib - LOADED extension 'io.warp10.ext.flows.FLoWSWarpScriptExtension'
Préalable sur FLoWS
FLoWS ne dispose pas encore d’un endpoint /flows ; nous continuons donc à utiliser les “endpoints historiques warpscript compatibles”.
Ce qui nous amène à réaliser une seule action en RPN/NPI (Notation Polonaise Inversée) lorsque l’on soumet du code FLoWS à Warp 10 :
# Multiligne WarpScript qui permet de mettre son code FLoWS
<'
... Code FLoWS ...
'>
# Applique la fonction FLOWS au code ci-dessus
FLOWS
Pour les types, les notations, etc - je voue renvoie au billet de blog introduisant FLoWS.
Requêtage d’une instance InfluxDB 1.x
La semaine dernière nous écrivions en WarpScript :
# Requête INFLUXQL et informations de connection à InfluxDB 1.X
{ 'influxql' "select * from cpu where host=%27myHost%27 and time > now() - 1h" 'db' "myDatabase" 'password' "myPassword" 'user' "myUser" 'url' "http://url.to.influxdb:8086" }
INFLUXDB.FETCH
# On récupère une liste de liste de séries GTS. Il n'y a qu'un seul élément dans cette liste. Nous le prenons pour n'avoir plus qu'une liste de séries GTS.
0 GET
# Sauvegarde de la liste dans une variable cpu
'cpu' STORE
# Affichage de la liste de GTS
$cpu
Cette semaine, nous écrivons en FLoWS :
<'
# Récupération de la liste de GTS
cpu_fetch = INFLUXDB.FETCH({'influxql':'select * from cpu where host=%27myHost%27 and time > now() - 1h', 'db':'myDatabase', 'password':'myPassword', 'user':'myUser', 'url':'http://url.to.influxdb:8086'})
# Récupération de la GTS en prenant l'index 0 de la liste
cpu = GET(cpu_fetch, 0)
# Affichage de la liste de GTS
return cpu
'>
FLOWS
On peut déjà noter :
- la lecture du code correspond plus à nos habitudes dans les autres lanagage
- les fonctions ont les mêmes noms, leur signature ne change pas non plus
- le mot clé
returnest nouveau ici et permet d’afficher la GTS dans le studio par ex. - les tableaux (MAP) sont plus lisibles (arguments séparés par des virugules, la clé et la valeur sont séparés par deux points) et moins sources d’erreurs (gestion des espaces plus sensibles en WarpScript)
Le résultat est identique :
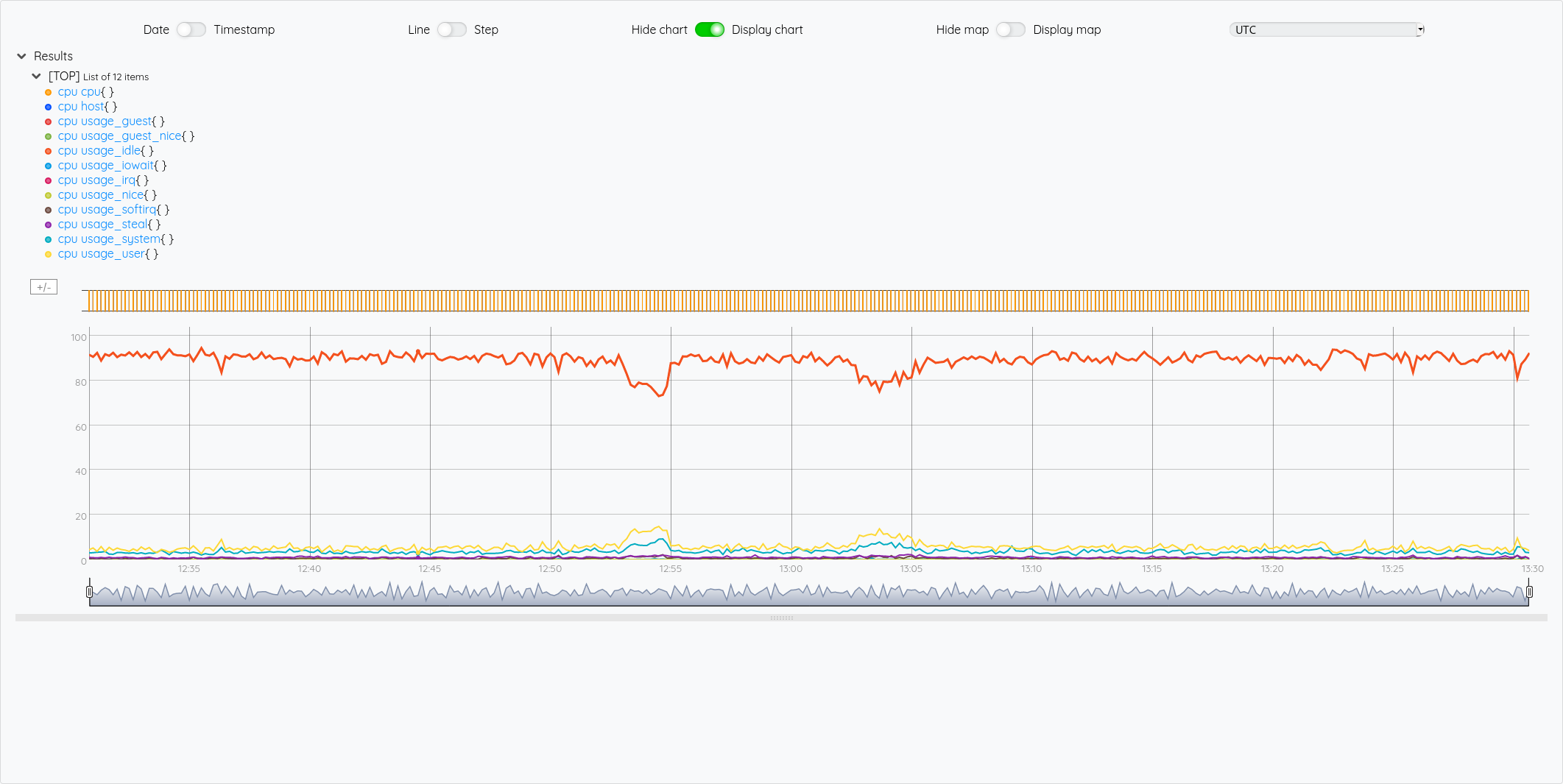
Pour illustrer cette liste de liste de GTS, si on veut récupérer la GTS du cpu idle, on voit dans le graphique que c’est la 5ème courbe, donc un indice 4.
En WarpScript :
{ 'influxql' "select * from cpu where host=%27myHost%27 and time > now() - 1h" 'db' "myDatabase" 'password' "myPassword" 'user' "myUser" 'url' "http://url.to.influxdb:8086" }
INFLUXDB.FETCH
0 GET
'cpu' STORE
# Récupération de la 5ème liste (indice 4)
$cpu 4 GET
En FLoWS :
<'
cpu_fetch = INFLUXDB.FETCH({'influxql':'select * from cpu where host=%27myHost%27 and time > now() - 1h', 'db':'myDatabase', 'password':'myPassword', 'user':'myUser', 'url':'http://url.to.influxdb:8086'})
cpu = GET(cpu_fetch, 0)
# Récupération de la 5ème liste (indice 4)
# on pourrait écrire : return GET(cpu, 4) mais on peut aussi écrire de façon plus concise :
return cpu[4]
'>
FLOWS
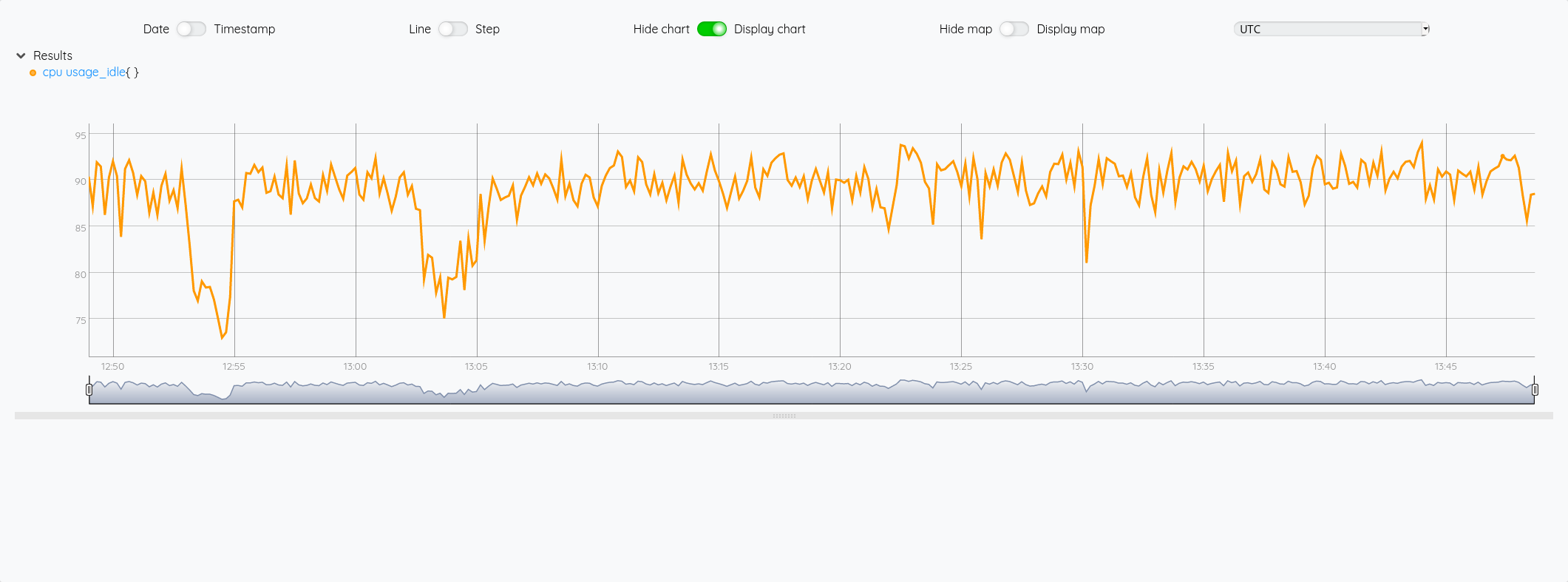
Requêtage d’une instance InfluxDB 2.x
La semaine dernière, nous écrivions en WarpScript :
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
<'
from(bucket: "crntbackup")
|> range(start: -1h, stop: now())
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> aggregateWindow(every: 1s, fn: mean, createEmpty: false)
|> yield(name: "mean")
'>
'fluxquery' STORE
# Paramètres de la fonction INFLUX.FLUX avec la requête flux (la variable fluxquery) et les informations de connection à InfluxDB 2.x
{ 'flux' $fluxquery 'org' "myOrganisation" 'token' "myToken" 'url' "http://url.to.influxdb2:9999" }
INFLUXDB.FLUX
# Sauvegarde de la liste dans une variable cpu
'cpu' STORE
# Affichage de la liste de GTS
$cpu
En FLoWS :
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
<'
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
fluxquery = 'from(bucket: "crntbackup")
|> range(start: -1h, stop: now())
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> aggregateWindow(every: 1s, fn: mean, createEmpty: false)
|> yield(name: "mean")'
# Paramètres de la fonction INFLUX.FLUX avec la requête flux (la variable fluxquery) et les informations de connection à InfluxDB 2.x
params = {'flux':fluxquery, 'org':'myOrganisation', 'token':'myToken', 'url':'http://url.to.influxdb2:9999' }
# Sauvegarde de la liste dans une variable cpu
cpu = INFLUXDB.FLUX(params)
# Affichage de la liste de GTS
return cpu
'>
FLOWS
On obtient :
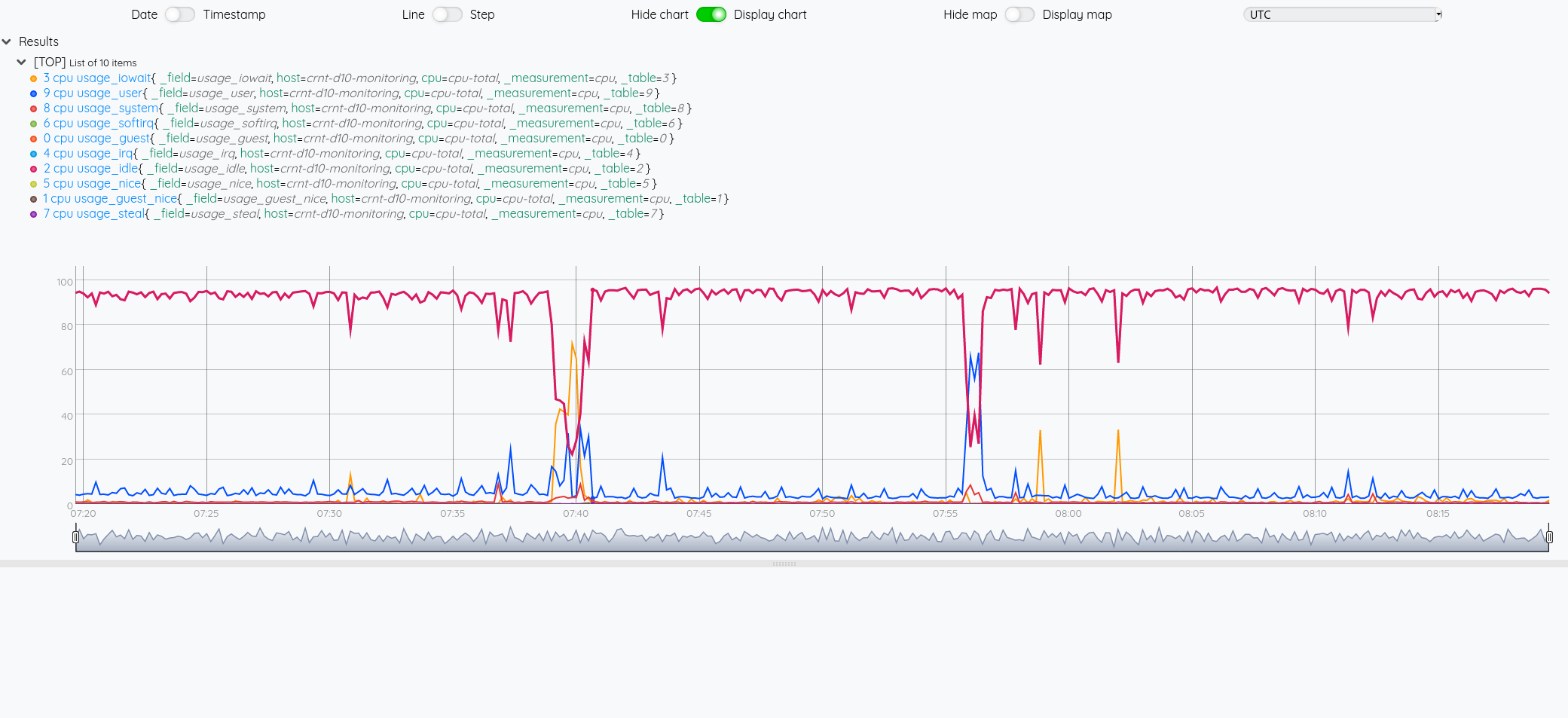
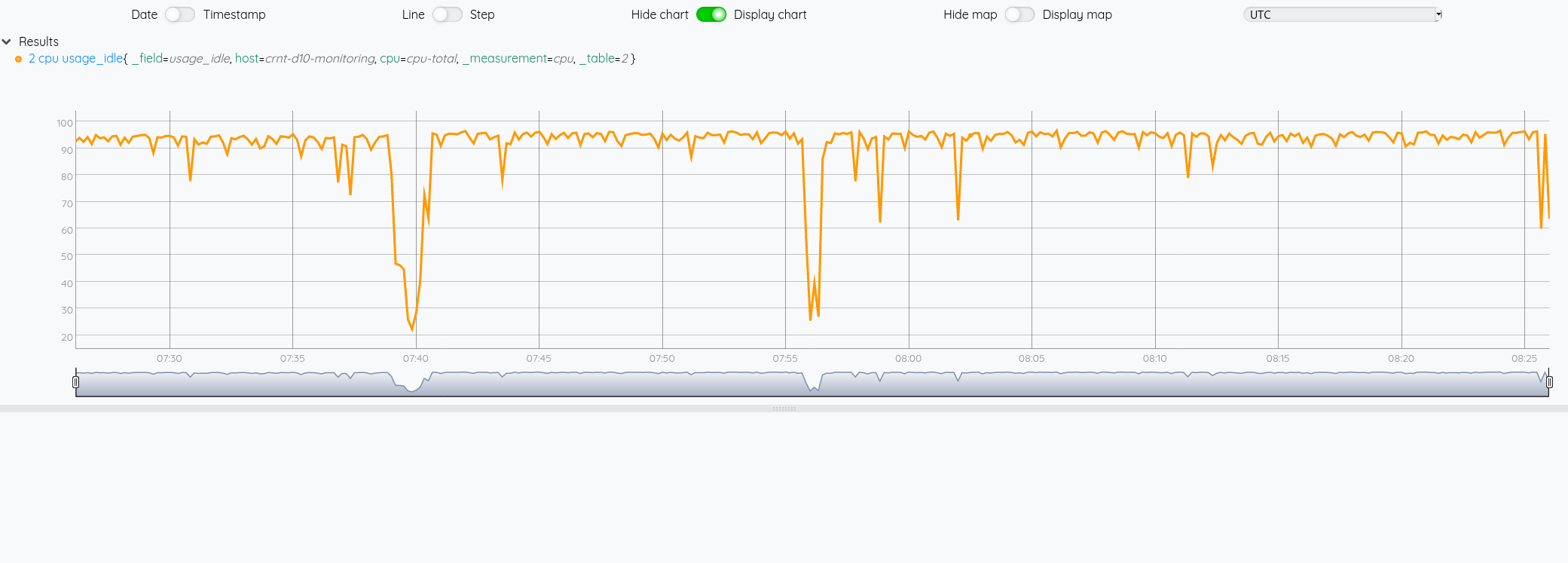
Si on veut comme précédemment avec InfluxQL afficher la courbe du CPU idle.
En WarpScript :
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
<'
from(bucket: "crntbackup")
|> range(start: -1h, stop: now())
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> aggregateWindow(every: 1s, fn: mean, createEmpty: false)
|> yield(name: "mean")
'>
'fluxquery' STORE
# Paramètres de la fonction INFLUX.FLUX avec la requête flux (la variable fluxquery) et les informations de connection à InfluxDB 2.x
{ 'flux' $fluxquery 'org' "myOrganisation" 'token' "myToken" 'url' "http://url.to.influxdb2:9999" }
INFLUXDB.FLUX
# Sauvegarde de la liste dans une variable cpu
'cpu' STORE
# Affiche la 7eme liste (incide 6)
$cpu 6 GET
En FLoWS :
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
<'
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
fluxquery = 'from(bucket: "crntbackup")
|> range(start: -1h, stop: now())
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> aggregateWindow(every: 1s, fn: mean, createEmpty: false)
|> yield(name: "mean")'
# Paramètres de la fonction INFLUX.FLUX avec la requête flux (la variable fluxquery) et les informations de connection à InfluxDB 2.x
params = {'flux':fluxquery, 'org':'myOrganisation', 'token':'myToken', 'url':'http://url.to.influxdb2:9999' }
# Sauvegarde de la liste dans une variable cpu
cpu = INFLUXDB.FLUX(params)
# Affiche la 7eme liste (incide 6)
return cpu[6]
'>
FLOWS
Sauvegarder des données dans InfluxDB
La semaine dernière, nous écrivions en WarpScript :
'<read_token>' 'readToken' STORE
'<write_token>' 'writeToken' STORE
# Récupération des dépenses sous la forme d'une série (GTS)
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
# Récupération du chiffre d'affaires mensuel sous la forme d'une série (GTS)
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
# Calcul du résulat mensuel
$revenue $exp -
# Stockage de la série obtenue dans une série appelée "result"
"result" RENAME
{ "company" "cerenit" } RELABEL
$writeToken UPDATE
# Récupération du résultat mensuel sous la forme d'une série (GTS)
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
# Version 1.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' true 'url' "http://url.to.influxdb:8086" 'measurement' "result" 'db' "crntcompta" 'password' "myPassword" 'user' "myUser" }
'params' STORE
# Utilisatoin de la fonction INFLUXDB.UPDATE qui prend la variable 'params' pour les paramètres de connection et une GTS ou liste de GTS pour les données à sauvegarder
$result $params INFLUXDB.UPDATE
# Version 2.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' false 'url' "http://url.to.influxdb:9999" 'measurement' "result" 'bucket' "crntcompta" 'token' "myToken" 'org' "myOrganisation" }
'params' STORE
$result $params INFLUXDB.UPDATE
En FLoWS, cela donne :
<'
# Gestion des tokens de lecture et écriture
readToken = '<read_token>'
writeToken = '<write_token>'
# Récupération de la liste de GTS dans Warp 10
expense_fetch = FETCH([readToken, 'expense', {'company':'cerenit'}, '2016-12-01T00:00:00Z', '2020-06-01T00:00:00Z'])
# On n'a toujours qu'une liste à 1 élement, on récupère donc la GTS en prenant l'index 0 de la liste
expense = expense_fetch[0]
# Même logique pour le chiffre d'affaires
revenue_fetch = FETCH([readToken, 'revenue', {'company':'cerenit'}, '2016-12-01T00:00:00Z', '2020-06-01T00:00:00Z'])
revenue = revenue_fetch[0]
# On calcule la résultat en faisant la différence entre les 2 GTS revenue et expense
r = revenue - expense
# la GTS obtenue n'ayant pas de nom, on lui en fournit un
RENAME(r, 'result')
# On ajoute les labels manquants
RELABEL(r, {"company":"cerenit"})
# On persiste la GTS dans Warp 10
UPDATE(r, writeToken)
# On récupère la contenu de la GTS result sur le même modèle que revenue et expense précédemment
result_fetch = FETCH([readToken, 'result', {'company':'cerenit'}, '2016-12-01T00:00:00Z', '2020-06-01T00:00:00Z'])
result = result_fetch[0]
# InfluxDB 1.X
# Définition des paramètres de connection
params = {'v1':true, 'url':"http://url.to.influxdb:8086", 'measurement':"result", 'db':"crntcompta", 'password':"myPassword", 'user':"myUser"}
# Persistance des données dans InfluxDB 1.x
INFLUXDB.UPDATE(result, params)
# InfluxDB 2.X
# Définition des paramètres de connection
params = {'v1':false, 'url':"http://url.to.influxdb:9999", 'measurement':"result", 'bucket':"crntcompta", 'token':"myToken", 'org':"myOrganisation" }
# Persistance des données dans InfluxDB 2.x
INFLUXDB.UPDATE(result, params)
'>
# Fin du code FLoWS
# Application de la fonction FLOWS à notre ensemble de code
FLOWS
Coté InfluxDB, on retrouve bien nos données :
Si au contraire, je veux regrouper plusieurs valeurs dans un même measurement InfluxDB, il faut passer une liste de GTS à INFLUXDB.UPDATE.
La semaine dernière, nous écrivions en WarpScript :
# Version 1.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' true 'url' "http://url.to.influxdb:8086" 'measurement' "accountancy" 'db' "crntcompta" 'password' "myPassword" 'user' "myUser" }
'params' STORE
# Passage d'une liste de GTS plutôt qu'une seule série de l'expemple précédent
[ $result $revenue $exp ] $params INFLUXDB.UPDATE
# Version 2.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' false 'url' "http://url.to.influxdb:9999" 'measurement' "accountancy" 'bucket' "crntcompta" 'token' "myToken" 'org' "myOrganisation" }
'params' STORE
# Passage d'une liste de GTS plutôt qu'une seule série de l'expemple précédent
[ $result $revenue $exp ] $params INFLUXDB.UPDATE
Cette semaine en FLoWS :
# InfluxDB 1.X
# Définition des paramètres de connection
params = {'v1':true, 'url':'http://url.to.influxdb:8086', 'measurement':'result', 'db':'crntcompta', 'password':'myPassword', 'user':'myUser'}
# Persistance des données dans InfluxDB 1.x en passant une liste de GTS
INFLUXDB.UPDATE([result, revenue, expense], params)
# InfluxDB 2.X
# Définition des paramètres de connection
params = {'v1':false, 'url':'http://url.to.influxdb:9999', 'measurement':'result', 'bucket':'crntcompta', 'token':'myToken', 'org':'myOrganisation' }
# Persistance des données dans InfluxDB 2.x en passant une liste de GTS
INFLUXDB.UPDATE([result, revenue, expense], params)
'>
FLOWS
Coté InfluxDB, on retrouve bien nos données :
Conclusion
Personnellement, au travers de cette exercice, je trouve FLoWS plutôt agréable à utiliser et il remplit bien son objectif de faciliter la prise en main de Warp 10 :
- Même si je commençais à m’habituer à la NPI/RPN, avoir une approche plus traditionnelle évite de devoir se concentrer sur l’ordre,
- La séparation par des virgules et/ou par des deux points (:) dans les listes et tableaux (MAP) facilitent leur lisiblité
- La migration d’un code en Warpscript vers FLoWS peut se faire de façon très progressive puisque les deux peuvent cohabiter ; c’est d’ailleurs comme ça que j’ai procédé pour ce billet et valider ainsi que je ne perdais rien au fur et à mesure. Il suffit à la fin d’enlever tous les blocs intermédiaires pour n’avoir plus qu’un seul bloc de code en FLoWS. C’est plutôt malin ! Et si une extension ou un code ne serait pas encore disponible en FLoWS, il est possible de débrancher sur du Warpscript.
- Il manque la complétion FLOWS dans le studio (et VSCode je présume) mais c’est pour bientôt !
- Le code gagne en lisiblité car on identifie les blocs qui vont ensemble.
Pour illustrer ce dernier point : quand je repense au code du tutoriel sur les cyclone “Number per year”, nous avons ce code à un moment :
$fetch_wind $end $end $start - TIMECLIP NONEMPTY SIZE
La fonction TIMECLIP prend trois arguments sauf que là, j’en vois potentiellement cinq. Il faut alors comprendre que le troisième argument est en fait le résulat de l’opération $end $start -.
En FLoWS, on aura alors :
TIMECLIP(fetch_wind, end, end - start)
et au global (non testé) :
SIZE(NONEMPTY(TIMECLIP(fetch_wind, end, end - start)))
Ce qui me semble nettement plus clair/lisible.
Le pari de FLoWS était de rendre Warp 10 plus accessible et de rendre les développeurs productifs plus rapidement, il semblerait bien que les objectifs soient remplis.
Warp 10 - Interactions avec une instance InfluxDB
warp10 timeseries influxdb warpscript warpfleetAprès les premiers pas avec Warp10 et en attendant que l’extension FLoWS soit disponible pour la version 2.7.0, j’ai mis à jour mon instance Warp 10 en 2.7.0 et j’ai voulu jouer avec l’extension warp10-ext-influxdb. Cette extension permet de requêter une instance InfluxDB 1.x ou 2.x avec du WarpScript.
Attention à ne pas confondre le plugin natif InfluxDB qui permet d’envoyer des métriques au format Line Protocol d’InfluxDB dans Warp10 et l’extension InfluxDB qui permet d’interagir avce une base InfluxDB en WarpScript.
Pré-requis: warpfleet
Installons déjà warpfleet, le gestionnaire de package conçu pour Warp 10.
# Installation de npm
sudo dnf install -y npm
# installation de warpfleet
sudo npm install -g @senx/warpfleet
# Vérification de la bonne installation de warpfleet
wf version
___ __ _______________ _____
__ | / /_____ __________________ ____/__ /___________ /_
__ | /| / /_ __ `/_ ___/__ __ \_ /_ __ /_ _ \ _ \ __/
__ |/ |/ / / /_/ /_ / __ /_/ / __/ _ / / __/ __/ /_
____/|__/ \__,_/ /_/ _ .___//_/ /_/ \___/\___/\__/
/_/ ™
version: 1.0.31
1.0.31
Installation de l’extension warp10-ext-influxdb
Sans trop rentrer dans les détails de warpfleet, il utilise un système de namespace appelés “Groups” pour ces packages et qui permettent de définir ses propres dépots. Pour l’extension warp10-ext-influxdb, le “group” est io.warp10.
Ce qui pour l"installation donne la commande suivante :
# Si votre utilisateur n'a pas accès à /path/to/warp10, il vous faudra utiliser sudo
(sudo) wf g -w /path/to/warp10 io.warp10 warp10-ext-influxdb
warpfleet va vous demander quelle version de l’extension vous souhaitez puis va procéder à son téléchargement et son installation.
Cela donne :
sudo wf g -w /opt/warp10 io.warp10 warp10-ext-influxdb
___ __ _______________ _____
__ | / /_____ __________________ ____/__ /___________ /_
__ | /| / /_ __ `/_ ___/__ __ \_ /_ __ /_ _ \ _ \ __/
__ |/ |/ / / /_/ /_ / __ /_/ / __/ _ / / __/ __/ /_
____/|__/ \__,_/ /_/ _ .___//_/ /_/ \___/\___/\__/
/_/ ™
version: 1.0.31
? Which revision do you want to retrieve? latest
✔ ext io.warp10:warp10-ext-influxdb#1.0.1-uberjar retrieved
✔ Download successful: gradle-wrapper.jar
✔ Download successful: gradle-wrapper.properties
✔ Download successful: gradlew
✔ Download successful: gradlew.bat
✔ Dependency warp10-ext-influxdb-1.0.1-uberjar.jar successfully deployed
✔ Done
Note: Pour éviter un bug dans la fonction INFLUXDB.UPDATE identifié lors de la rédaction de ce billet, assurez-vous d’avoir une version >= 1.0.1
Ensuite, il faut créer le fichier /path/to/warp10/etc/conf.d/90--influxdb-extension.conf et y ajouter la ligne suivante:
warpscript.extension.influxdb = io.warp10.script.ext.influxdb.InfluxDBWarpScriptExtension
Je préfère créer un fichier plutôt que d’éditer un fichier existant pour le suivi des mises à jour et j’ai utilisé le prefix 90 car il n’est pas utilisé par les fichiers de Warp10.
Relancer ensuite Warp 10 pour que le plugin soit chargé au démarrage de l’instance :
(sudo) /path/to/warp10/bin/warp10-standalone.init restart
Dans /path/to/warp10/logs/warp10.log, vous devriez voir apparaitre :
2020-09-17T10:59:23,742 main INFO script.WarpScriptLib - LOADED extension 'io.warp10.script.ext.influxdb.InfluxDBWarpScriptExtension'
Requêtage d’une instance InfluxDB 1.x
Note: La librairie influxdb-java ne semble pas supporter un reverse proxy http/2 devant l’instance InfluxDB. Il faut donc accéder à InfluxDB en direct via le port 8086.
# Requête INFLUXQL et informations de connection à InfluxDB 1.X
{ 'influxql' "select * from cpu where host=%27myHost%27 and time > now() - 1h" 'db' "myDatabase" 'password' "myPassword" 'user' "myUser" 'url' "http://url.to.influxdb:8086" }
INFLUXDB.FETCH
# On récupère une liste de liste de séries GTS. Il n'y a qu'un seul élément dans cette liste. Nous le prenons pour n'avoir plus qu'une liste de séries GTS.
0 GET
# Sauvegarde de la liste dans une variable cpu
'cpu' STORE
# Affichage de la liste de GTS
$cpu
Dans ce qu’il faut noter ici:
INFLUXDB.FETCHprend ses paramètres dans une MAP ayant pour paramètres:influxql,db,password,usereturl.- Pour la directive where, il faut encoder les apostrophes via
%27: en InfluxQL, on écrirait... where host='myHost'; là, il faut écrirewhere host=%27myHost%27 - Si dans InfluxDB, on a un measurements (cpu) avec n items (usage_guest, usage_idle, etc), on a une conversion en une liste de n GTS avec une valeur chacune.
influxqlprend une ou plusieurs requêtes séparées par des points virgules. Cela donnera en sortie plusieurs listes de listes de GTS (vu que comme dit au dessus, pour une requête influxql sur un measurement on a 1 à n GTS ; donc pour y requêtes, on aura y listes de n listes de GTS)
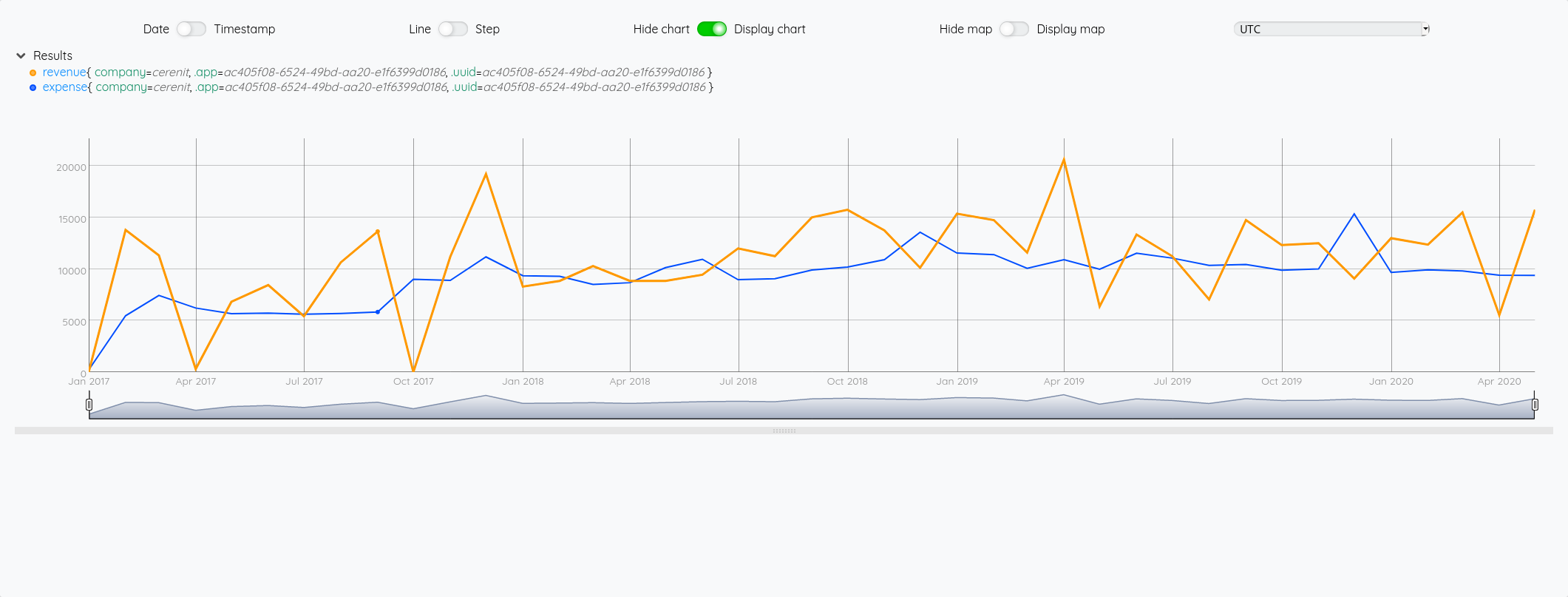
Pour illustrer cette liste de liste de GTS, si on veut récupérer la GTS du cpu idle, on voit dans le graphique que c’est la 5ème courbe, donc un indice 4.
{ 'influxql' "select * from cpu where host=%27myHost%27 and time > now() - 1h" 'db' "myDatabase" 'password' "myPassword" 'user' "myUser" 'url' "http://url.to.influxdb:8086" }
INFLUXDB.FETCH
0 GET
'cpu' STORE
# Récupération de la 5ème liste (indice 4)
$cpu 4 GET
Requêtage d’une instance InfluxDB 2.x
Note: La librairie influxdb-client-java ne semble pas plus supporter un reverse proxy http/2 devant l’instance InfluxDB. Il faut donc accéder à InfluxDB en direct via le port 9999.
Si on fait une requête similaire en flux :
# Requête FLUX et informations de connection à InfluxDB 2.x
{ 'flux' "from(bucket: %22myBucket%22) |> range(start: -1h, stop: now()) |> filter(fn: (r) => r[%22_measurement%22] == %22cpu%22) |> filter(fn: (r) => r[%22cpu%22] == %22cpu-total%22) |> aggregateWindow(every: 1s, fn: mean, createEmpty: false) |> yield(name: %22mean%22)" 'org' "myOrganisation" 'token' "myToken" 'url' "http://url.to.influxdb2:9999" }
INFLUXDB.FLUX
# On récupère une liste de séries GTS
# Sauvegarde de la liste dans une variable cpu
'cpu' STORE
# Affichage de la liste de GTS
$cpu
On note que la requête flux n’est pas très lisible de par l’encodage des guillemets et de son coté monoligne. On peut améliorer ça avec une variable STRING en multi-ligne :
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
<'
from(bucket: "crntbackup")
|> range(start: -1h, stop: now())
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> aggregateWindow(every: 1s, fn: mean, createEmpty: false)
|> yield(name: "mean")
'>
'fluxquery' STORE
# Paramètres de la fonction INFLUX.FLUX avec la requête flux (la variable fluxquery) et les informations de connection à InfluxDB 2.x
{ 'flux' $fluxquery 'org' "myOrganisation" 'token' "myToken" 'url' "http://url.to.influxdb2:9999" }
INFLUXDB.FLUX
# Sauvegarde de la liste dans une variable cpu
'cpu' STORE
# Affichage de la liste de GTS
$cpu
On y gagne en lisibilité et pas besoin d’encoder les guillements !
Dans les deux cas, on obtient :
On note d’ailleurs que les méta-données (nom du measurement, nom du champ et les tags sont repris sous la forme de labels)
Contraiement à la requête en InfluxQL, on ne peut passer qu’une requête à la fois mais ce qui permet d’avoir directment une liste de GTS puis la GTS. On n’a plus une liste de liste de GTS.
Si on veut comme précédemment avec InfluxQL afficher la courbe du CPU idle:
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
<'
from(bucket: "crntbackup")
|> range(start: -1h, stop: now())
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> aggregateWindow(every: 1s, fn: mean, createEmpty: false)
|> yield(name: "mean")
'>
'fluxquery' STORE
# Paramètres de la fonction INFLUX.FLUX avec la requête flux (la variable fluxquery) et les informations de connection à InfluxDB 2.x
{ 'flux' $fluxquery 'org' "myOrganisation" 'token' "myToken" 'url' "http://url.to.influxdb2:9999" }
INFLUXDB.FLUX
# Sauvegarde de la liste dans une variable cpu
'cpu' STORE
# Affiche la 7eme liste (incide 6)
$cpu 6 GET
Je ne vais pas pousser l’exemple plus loin, il ne tient qu’à vous de poursuivre la manipulation de vos données en WarpScript. On pourrait se demander où mettre la limite entre la requête en Flux/InfluxQL et les manipulations à faire en WarpScript ensuite. Tout dépendra de votre cas d’usage.
Sauvegarder des données dans InfluxDB
Pour le moment, nous avons requêté des données stockées dans InfluxDB 1.x ou 2.x ; mais nous pouvons très bien imaginer un cas où les données sont issues d’une autre source de données ou bien ont été générées avec WarpScript mais qu’on veuille les persister dans InfluxDB 1.x ou 2.x
Reprenons mon exercice de compatbilité et de prédictions et sauvegardons tout ça dans InfluxDB.
Pour rappel, nous avons fait ceci :
'<read_token>' 'readToken' STORE
'<wrtie_token>' 'writeToken' STORE
# Récupération des dépenses sous la forme d'une série (GTS)
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
# Récupération du chiffre d'affaires mensuel sous la forme d'une série (GTS)
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
# Calcul du résulat mensuel
$revenue $exp -
# Stockage de la série obtenue dans une série appelée "result"
"result" RENAME
{ "company" "cerenit" } RELABEL
$writeToken UPDATE
# Récupération du résultat mensuel sous la forme d'une série (GTS)
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
Si je veux sauvegarder une série dans un measurement influxdb :
# Version 1.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' true 'url' "http://url.to.influxdb:8086" 'measurement' "result" 'db' "crntcompta" 'password' "myPassword" 'user' "myUser" }
'params' STORE
# Utilisatoin de la fonction INFLUXDB.UPDATE qui prend la variable 'params' pour les paramètres de connection et une GTS ou liste de GTS pour les données à sauvegarder
$result $params INFLUXDB.UPDATE
# Version 2.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' false 'url' "http://url.to.influxdb:9999" 'measurement' "result" 'bucket' "crntcompta" 'token' "myToken" 'org' "myOrganisation" }
'params' STORE
$result $params INFLUXDB.UPDATE
Coté InfluxDB, on retrouve bien nos données :
Si au contraire, je veux regrouper plusieurs valeurs dans un même measurement InfluxDB, il faut passer une liste de GTS à INFLUXDB.UPDATE.
# Version 1.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' true 'url' "http://url.to.influxdb:8086" 'measurement' "accountancy" 'db' "crntcompta" 'password' "myPassword" 'user' "myUser" }
'params' STORE
# Passage d'une liste de GTS plutôt qu'une seule série de l'expemple précédent
[ $result $revenue $exp ] $params INFLUXDB.UPDATE
# Version 2.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' false 'url' "http://url.to.influxdb:9999" 'measurement' "accountancy" 'bucket' "crntcompta" 'token' "myToken" 'org' "myOrganisation" }
'params' STORE
# Passage d'une liste de GTS plutôt qu'une seule série de l'expemple précédent
[ $result $revenue $exp ] $params INFLUXDB.UPDATE
Coté InfluxDB, on retrouve bien nos données :
On arrive au bout de ce billet, nous avons vu que nous pouvons :
- En WarpScript, requêter des données stockées dans InfluxDB 1.x et 2.x
- En WarpScript, manipuler des données issues de Warp 10 puis les stocker dans InfluxDB 1.x et 2.x
Nous pourrions aller plus loin avec :
- des scénarios d’enrichissement de données en s’interfaçant par ex avec des données de sources SQL (référentiels, etc)
- des scénarios d’analytics en croisant des données issues de Warp10, InfluxDB ou d’autres sources de données (bases SQL, etc)
- des scénarios de projection en appliquant par exemple les algorythmes de machine learning sur des données issues d’InfluxDB
- …
WarpScript semble ainsi permettre d’avoir un langage de manipulation de séries temporelles multi-sources et d’offrir une expérience unifiée de manipulatoin de ces données. Dans les prochains billets, nous explorerons d’avantage la partie visualisation et alerting.
Web, Ops & Data - Septembre 2020
podman timezone grafana dashboard terraform sécurité terrascan terracost nvidia arm cni csi network storage cilium calico longhorn portworx openebs rancher python gke warp10 influxdb data-engineer date-scientist sqlCloud
- terrascan : terrascan va scanner vos fichiers terraform et les valider contre 500+ règles de sécurité (au format Open Policy Agent) afin d’identifier les éventuels problèmes de sécurité. L’outil supporte AWS, GCP et Azure.
- infracost : estimez le coût de vos projets terraform à l’heure ou au mois. Il est même possible de faire apparaitre les évolutions de vos coûts d’infra lors d’une MR/PR. A défaut d’être forcément précis, cela pourra au moins donner une idée et permettra peut être de sensibiliser les développeurs et/ou les clients aux évolutions de couts de leurs projets.
Code
- All Python versions before 3.6 are now totally unsupported : Python 2 n’est plus supporté depuis le début de l’année - c’est au tour de Python 3.5 de ne plus l’être depuis le 13 sept. Pour Python 3.6, ce sera décembre 2021.
- nackjicholson/aiosql : juste milieu (?) entre du SQL brut et un ORM, aiosql semble permettre d’associer une requête SQL à une fonction pour une manipulation assez simple ensuite dans le code par la suite.
Container et orchestration
- Tick-tock. Does your container know what time it is? : le fichier
/etc/localtimeest en général défini dans votre image de base et peut ne pas convenir à votre fuseau horaire. Podman permet de surcharger cela en précisant à l’exécution ou via un point de configuration le fuseau horaire à utiliser. Pratique plutôt que de modifier le fichier via votre Dockerfile. - Kubernetes Storage Performance Comparison v2 (2020 Updated) : une comparaison des solutions de stockage rook/Ceph, Azure PVC, Azure hosyPath, GlusterFS, Portworx, OpenEBS MayaStor et Rancher Longhorn. La conclusion se termine par un trio de tête emmené par Portworx, OpenEBS et Longhorn. Ce dernier étant plus adapté pour des besoins légers de stockage.
- New GKE Dataplane V2 increases security and visibility for containers & Google announces Cilium & eBPF as the new networking dataplane for GKE : GKE va utilise Cilium comme CNI pour son data plane v2 (il utilise actuellement Calico comme CNI si les network policy sont activées lors de la création de votre cluster)
- Benchmark results of Kubernetes network plugins (CNI) over 10Gbit/s network (Updated: August 2020) : pour des petits clusters, la solution la plus performante serait/resterait Calico et Cilium ne serait efficace que pour des gros clusters.
(Big) data
- #19. Lucien Fregosi - Hugo Larcher - Erika Gelinard - Dessine moi un data engineer : Pour cette saison 2 de DataBuzzWord, des réflexions intéressantes autour du Data Engineer / Data Scientists, le Data Engineer qui fait du Build/Run, les pipelines & job as a service et de l’importance de simplifier / déporter le run pour que le Data Engineer et a fortiori le Data Scientist se concentrent sur leurs pipelines ou leur exploitation et gérer moins d’infrastructure.
Hardware
- NVIDIA to Acquire Arm for $40 Billion, Creating World’s Premier Computing Company for the Age of AI : Nvidia sur le point d’acheter ARM pour en faire un leader des processeurs (CPU/GPU) et de l’IA. On voit que le sujet est politique dans le soin qui est apporté au site ARM de Cambridge et de son développement à venir.
Time Series
- InfluxDB OSS 2.0 General Availability Roadmap : un bon résumé sur les avancées d’Influx 2.0 OSS et la transition 1.x vers 2.x ; Début septembre, j’étais sceptique quand même avec le retour du stockage et du requêtage da la V1 dans la branche v2 (cf la PR “Port TSM1 storage engine”) et ce à un mois de la date de release prévue annoncés aux Influxdays de Londres (ie fin septembre). Au final, la version 2.0 OSS et Entreprise auront les feautres “frontend” de la V2 (Tasks, Dashobards, etc) mais uniquement le moteur de stockage de la V1. Si je comprends le besoin pour ne pas perdre leurs clients dans la migration, c’est un écart de plus entre les version OSS/Entreprise et la version Cloud. Les couches hautes (API, UI, fonctionnalités type Task/Dashboards/…) seront commmunes mais sous le capot (stockage, ingestion), cela diffère. On peut raisonnablement se demander si c’est une phase intermédiaire avant une migration ultérieure sur le moteur de stockage de la 2.0 quand InfluxData aura plus de recul sur le sujet ou bien si les projets Cloud et OSS/Entreprise ne vont pas diverger significativement à moyen terme. Ceux qui ont commencé à alimenter leur base InfluxDB 2.0 sur la base des versions beta devront repartir de zéro du fait de cette incompatibilité de version de moteur de stockage.
- Popular community plugins that can improve your Grafana dashboards : une collection de plugins Grafana pour améliorer vos dashboards.
- September 2020: Warp 10 release 2.7.0, ready for FLoWS : la version 2.7 de Warp 10 est disponible et est la première version qui va supporter FLoWS, la syntaxe fonctionnelle alternative à WarpScript. Pour en savoir plus sur FLoWS, je vous renvoie à l’édition 5 du Paris Time Series Meetup avec la présentation de FLoWS. D’autres améliorations font partie de cette release, tant d’un point de vue fonctionnalités que performances.
Premiers pas avec Warp 10 : comptabilité et prévisions de fin d'année
warp10 timeseries forecast dashboard warpstudio arimaSuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année (ce billet)
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512
- Partie 6 - Les FEC et le compte de résultat
Cherchant à me familiariser avec la base de données orientée série temporelles Warp 10 d’une part et à améliorer mes tableaux de bord comptables pour me faire des projections à fin d’année (parce que bon, faire juste la moyenne des mois précédents comme valeur pour les mois à venir, c’est un peu trop facile), je me suis dit que c’était un exercice qui pouvait répondre aux deux besoins après avoir lu Time series forecasts in WarpScript.
Pour ceux qui ne connaissent pas encore Warp 10 , c’est une solution de geo-timeseries (séries spatio temporelles) open source, éditée par SenX, société française basée à Brest. Pour en savoir plus sur Warp 10 , vous pouvez regarder l’éditions 1 et l’édition 5 du Paris Time Series Meetup.
Pour prendre en main Warp 10 et appréhender le langage de programmation Warpscript, je vous invite à suivre le tutoriel sur les cyclones en utilisant la Sandbox Warp10 mise à disposition par Senx.
Le jeu de données
Pour le jeu de données, j’ai donc récupéré de mes tableaux de bords mon chiffre d’affaires et mes dépenses mensuels sur la période Janvier 2017 à Mai 2020.
Nous allons donc créer 2 séries (appelées aussi GTS)
Soit crnt-revenue.gts:
# 2017
1483225200000000// revenue{company=cerenit} 0
1485903600000000// revenue{company=cerenit} 13800
1488322800000000// revenue{company=cerenit} 11325
1490997600000000// revenue{company=cerenit} 300
1493589600000000// revenue{company=cerenit} 6825
1496268000000000// revenue{company=cerenit} 8450
1498860000000000// revenue{company=cerenit} 5425
1501538400000000// revenue{company=cerenit} 10650
1504216800000000// revenue{company=cerenit} 13650
1506808800000000// revenue{company=cerenit} 0
1509490800000000// revenue{company=cerenit} 11200
1512082800000000// revenue{company=cerenit} 19225
# 2018
1514761200000000// revenue{company=cerenit} 8300
1517439600000000// revenue{company=cerenit} 8850
1519858800000000// revenue{company=cerenit} 10285
1522533600000000// revenue{company=cerenit} 8850
1525125600000000// revenue{company=cerenit} 8850
1527804000000000// revenue{company=cerenit} 9450
1530396000000000// revenue{company=cerenit} 12000
1533074400000000// revenue{company=cerenit} 11250
1535752800000000// revenue{company=cerenit} 15013
1538344800000000// revenue{company=cerenit} 15750
1541026800000000// revenue{company=cerenit} 13750
1543618800000000// revenue{company=cerenit} 10125
# 2019
1546297200000000// revenue{company=cerenit} 15375
1548975600000000// revenue{company=cerenit} 14750
1551394800000000// revenue{company=cerenit} 11600
1554069600000000// revenue{company=cerenit} 20622
1556661600000000// revenue{company=cerenit} 6376
1559340000000000// revenue{company=cerenit} 13350
1561932000000000// revenue{company=cerenit} 11250
1564610400000000// revenue{company=cerenit} 7050
1567288800000000// revenue{company=cerenit} 14750
1569880800000000// revenue{company=cerenit} 12326
1572562800000000// revenue{company=cerenit} 12513
1575154800000000// revenue{company=cerenit} 9082
# 2020
1577833200000000// revenue{company=cerenit} 13000
1580511600000000// revenue{company=cerenit} 12375
1583017200000000// revenue{company=cerenit} 15500
1585692000000000// revenue{company=cerenit} 5525
1588284000000000// revenue{company=cerenit} 15750
et crnt-expenses.gts:
# 2017
1483225200000000// expense{company=cerenit} 219
1485903600000000// expense{company=cerenit} 5471
1488322800000000// expense{company=cerenit} 7441
1490997600000000// expense{company=cerenit} 6217
1493589600000000// expense{company=cerenit} 5676
1496268000000000// expense{company=cerenit} 5719
1498860000000000// expense{company=cerenit} 5617
1501538400000000// expense{company=cerenit} 5690
1504216800000000// expense{company=cerenit} 5831
1506808800000000// expense{company=cerenit} 9015
1509490800000000// expense{company=cerenit} 8903
1512082800000000// expense{company=cerenit} 11181
# 2018
1514761200000000// expense{company=cerenit} 9352
1517439600000000// expense{company=cerenit} 9297
1519858800000000// expense{company=cerenit} 8506
1522533600000000// expense{company=cerenit} 8677
1525125600000000// expense{company=cerenit} 10136
1527804000000000// expense{company=cerenit} 10949
1530396000000000// expense{company=cerenit} 8971
1533074400000000// expense{company=cerenit} 9062
1535752800000000// expense{company=cerenit} 9910
1538344800000000// expense{company=cerenit} 10190
1541026800000000// expense{company=cerenit} 10913
1543618800000000// expense{company=cerenit} 13569
# 2019
1546297200000000// expense{company=cerenit} 11553
1548975600000000// expense{company=cerenit} 11401
1551394800000000// expense{company=cerenit} 10072
1554069600000000// expense{company=cerenit} 10904
1556661600000000// expense{company=cerenit} 9983
1559340000000000// expense{company=cerenit} 11541
1561932000000000// expense{company=cerenit} 11065
1564610400000000// expense{company=cerenit} 10359
1567288800000000// expense{company=cerenit} 10450
1569880800000000// expense{company=cerenit} 9893
1572562800000000// expense{company=cerenit} 10014
1575154800000000// expense{company=cerenit} 15354
# 2020
1577833200000000// expense{company=cerenit} 9673
1580511600000000// expense{company=cerenit} 9933
1583017200000000// expense{company=cerenit} 9815
1585692000000000// expense{company=cerenit} 9400
1588284000000000// expense{company=cerenit} 9381
Pour chaque fichier:
- le premier champ est un timestamp correspondant au 1er jour de chaque mois à 00h00.
- la partie
//indique qu’il n’y a pas de position spatiale (longitude, lattitude, élévation) expenseetrevenuesont les noms des classes qui vont stocker mes informationscompanyest un label que je positionne sur mes données avec le nom de mon entreprise- le dernier champ est la valeur de mon chiffre d’affaires ou de mes dépenses mensuels.
Pour plus d’information sur la modélisation, cf GTS Input Format.
Insertion des données
Lorsque vous utilisez la Sandbox, 3 tokens vous sont donnés :
- un token pour lire les données ; j’y ferai référence via
<readToken>par la suite - un token pour écrire les données ; j’y ferai référence via
<writeToken>par la suite - un token pour supprimer les données ; j’y ferai référence via
<deleteToken>par la suite
#!/usr/bin/env bash
for file in crnt-expenses crnt-revenue ; do
curl -v -H 'Transfer-Encoding: chunked' -H 'X-Warp10-Token: <writeToken>' -T ${file}.gts 'https://sandbox.senx.io/api/v0/update'
done
Premières requêtes
Pour ce faire, nous allons utiliser le Warp Studio ; pour la datasource, il conviendra de veiller à ce que la SenX Sandbox soit bien sélectionnée.
L’équivalent de “SELECT * FROM *” peut se faire de la façon suivante :
# Authentification auprès de l'instance en lecture
'<readToken> 'readToken' STORE
# FETCH permet de récupérer une liste de GTS, ici on demande toutes les classes via ~.* et tous les labels en prenanr les 1000 dernières valeurs ; on récupère donc toutes les séries.
[ $readToken '~.*' {} NOW -1000 ] FETCH
Si vous cliquez sur l’onglet “Dataviz”, vous avez alors immédiatement une représentation graphique de vos points.
Maintenant que nos données sont bien présentes, on va vouloir aller un peu plus loin dans nos manipulations.
Premières manipulations
Ce que nous voulons faire :
- Sélectionner chaque série et la stocker dans une variable,
- Calculer le résultat mensuel et le persister dans une troisième série temporelle
- Afficher les trois séries.
Pour sélectionner chaque série et la stocker dans une variable:
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# FETCH : permet de récupérer une liste de série, ici on filtre sur la classe expense, sur le label company = cerenit et sur les dates du 01/12/2016 au 01/06/2020.
# 0 GET : on sait que l'on a qu'une seule série qui correspond à la requête. Donc on ne retient que le 1er élément pour passer d'une liste de GTS à une seule et unique GTS.
# STORE : stocke le résultat dans une variable exp.
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
# Idem pour la classe revenue, stockée dans une variable revenue.
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
# Affiche les 2 séries
$exp
$revenue
A ce stade, vous avez la même représentation graphique que précédemment si vous cliquez sur Dataviz.
Calculons maintenant le résultat mensuel (chiffre d’affaires - dépenses) :
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# Le même bloc que précédemment
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
# Calcul: il suffit se soustraire les deux éléments pour avoir le résultat
$revenue $exp -
# on affiche également les deux autres variables pour la dataviz
$exp
$revenue
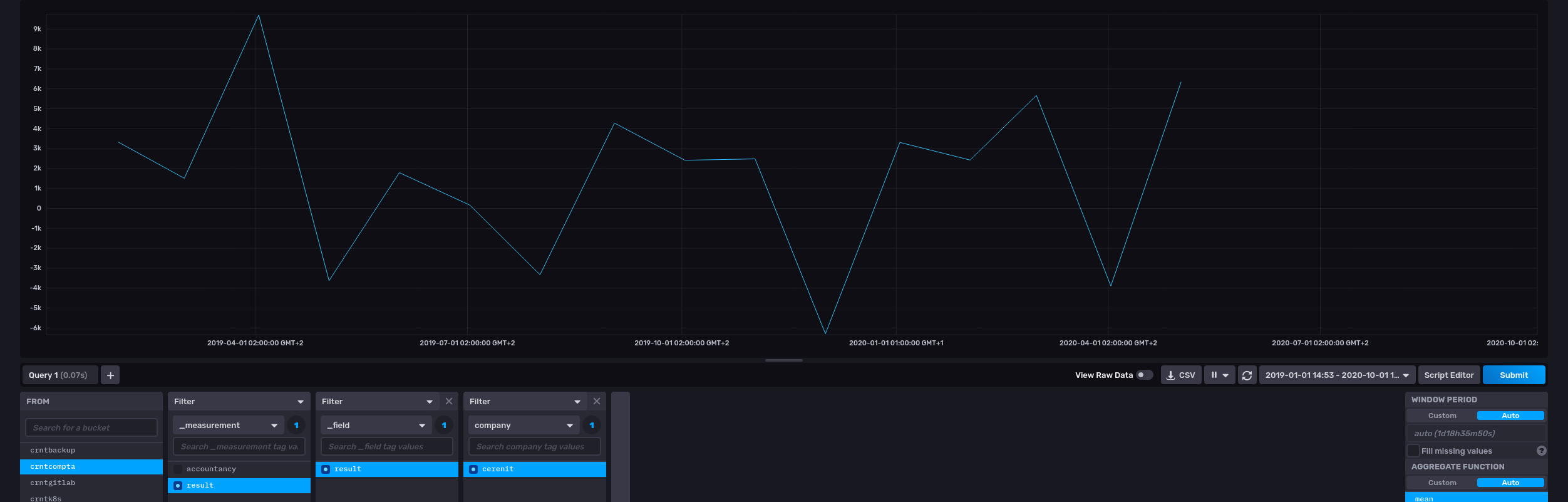
A ce stade :
- Au niveau de la dataviz, la légende ne fournit aucune information sur la nature de la série
- Cette donnée n’est pas encore persistée
Jusqu’à présent, nous avons utilisé que le <readToken> pour lire les données. Pour la persistence, nous allons utilier le <writeToken>.
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# Authentification auprès de l'instance en écriture
'<writeToken>' 'writeToken' STORE
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
# La première ligne est inchangée, elle calcule le résultat mensuel et la donnée est de type GTS
# Du coup, comme nous sommes dans une pile et que l'on hérite de ce qu'il s'est passé avant, on peut lui assigner un nom via RENAME
# Puis lui ajouter le label company avec pour valeur cerenit
# Et utiliser la fonction UPDATE pour stocker en base la GTS ainsi obtenue.
$revenue $exp -
"result" RENAME
{ "company" "cerenit" } RELABEL
$writeToken UPDATE
# Comme pour revenue et expense, on récupère les données sous la forme d'une GTS que l'on stocke dans une variable
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
# On vide la pile
CLEAR
# On affiche les variables créées
$revenue
$exp
$result
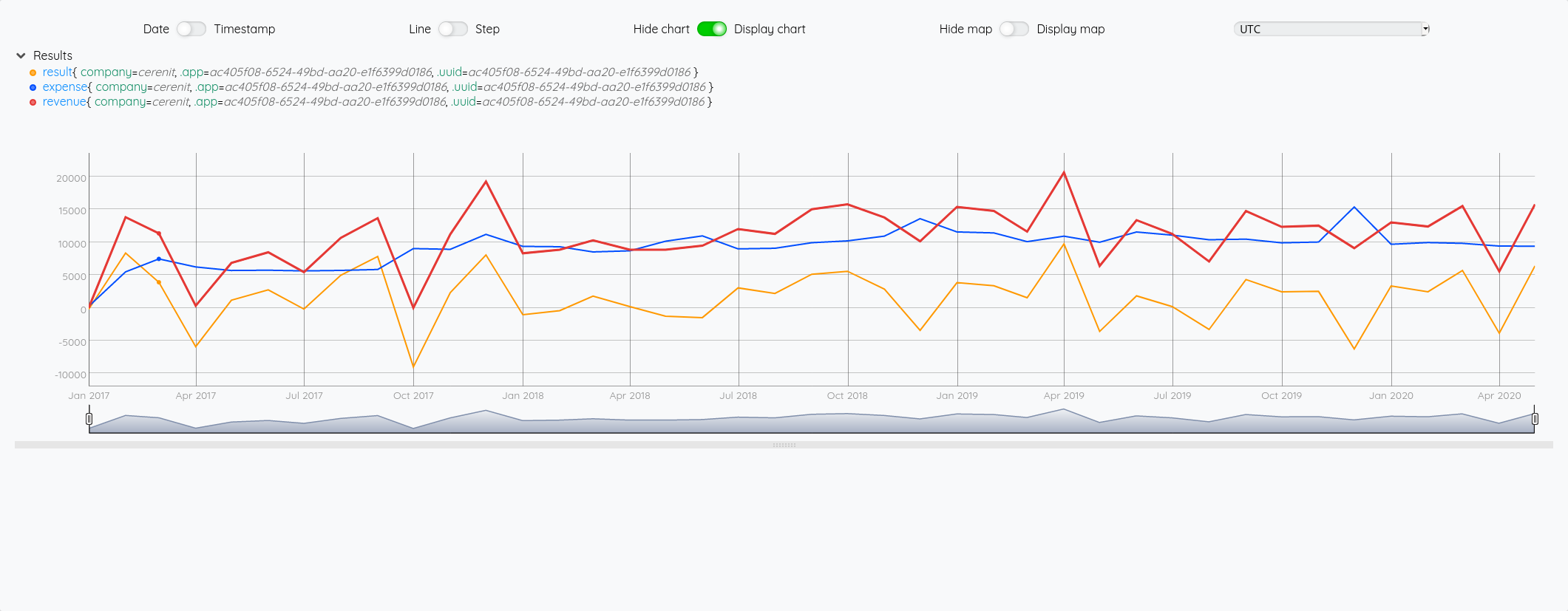
Et voilà !
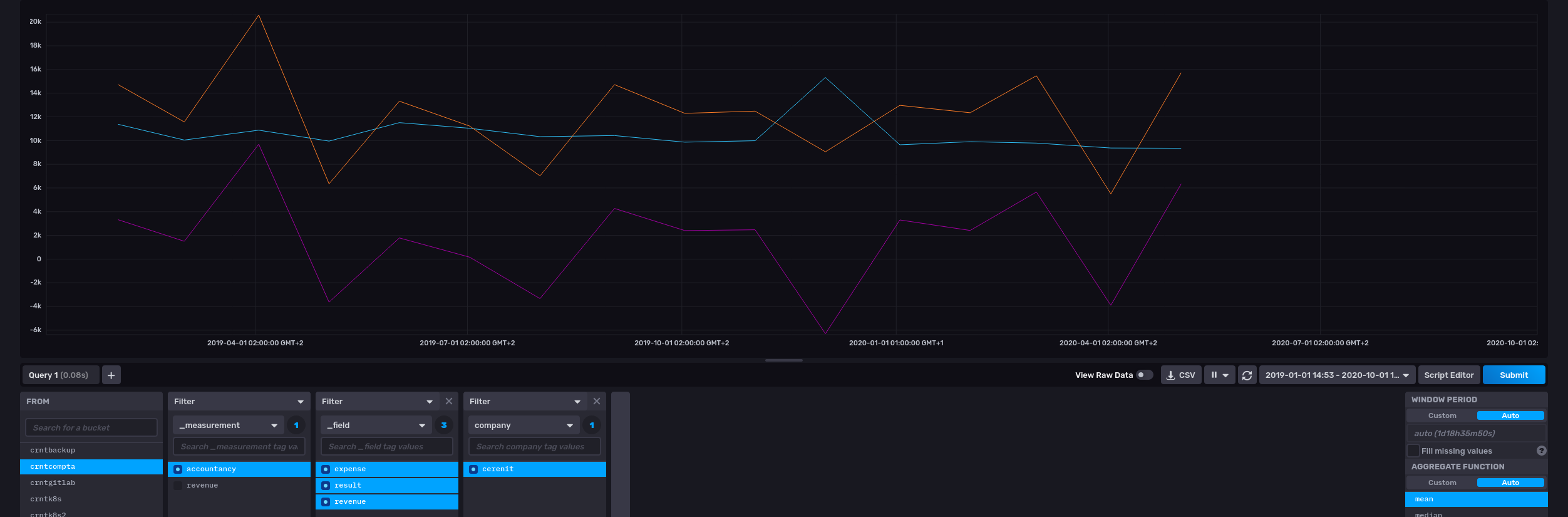
Prévoyons le futur
Warp10 dispose d’une extension propriétaire et payante permettant d’appliquer des algorithmes de prévisions sur des séries temporelles : warp10-ext-forecasting. Il est possible d’utiliser cette extension sur la Sandbox Warp10 mise à disposition par SenX.
Il existe une fonction AUTO et SAUTO (version saisonnière) qui applique automatiquement des algorythmes d’AutoML sur vos données.
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# Récupération des trois séries
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
CLEAR
$revenue
$exp
$result
# MAP: la fonction `AUTO` s'attend à manipuler des nombres au format `DOUBLE` et non des entiers. Il faut donc faire la conversion.
# FORECAST: sur les données obtenues du MAP, on applique la fonction AUTO et on demande les 8 prochaines occurents (pour aller jusqu'à la fin d'année)
# Le .ADDVALUES permet de "fusionner" les prévisions avec la série parente (sans les persister en base à ce stade)
# Commes les 3 projections sont disponibles dans la pile, elles sont également affichées
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
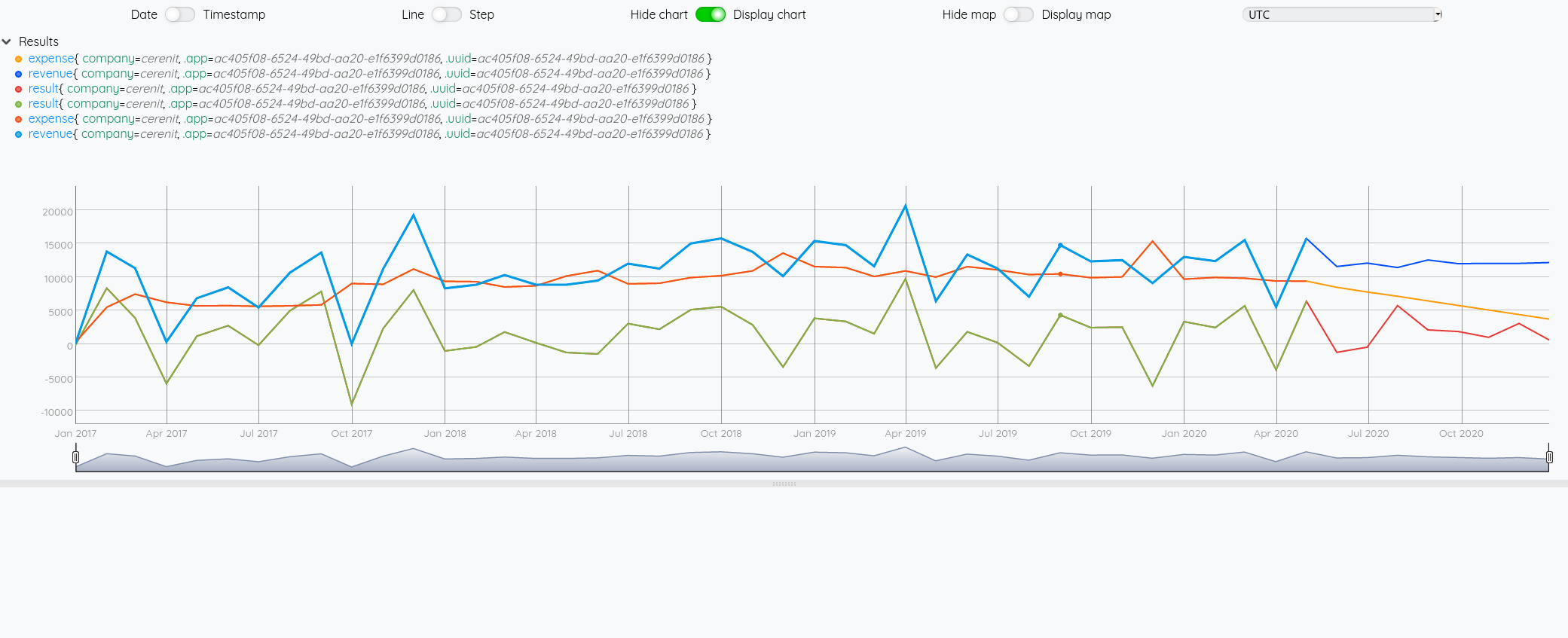
Du fait du FORECAST.ADDVALUES, on pourrait se passer d’afficher les trois premières séries. Mais vistuellement, cela permet de voir la différence entre la série originale et la projection.
Une fois l’effet Whaou passé, on peut se demander quel modèle a été appliqué. Pour cela il y a la fonction MODELINFO
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# Récupération des trois séries
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
CLEAR
[ $result mapper.todouble 0 0 0 ] MAP
AUTO MODELINFO
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO MODELINFO
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO MODELINFO
Dans l’onglet des résultats, on voit l’information: "model": "ARIMA".

Si on veut alors faire la même chose en utilisant le modèle ARIMA :
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# Récupération des trois séries
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
CLEAR
# SEARCH.ARIMA: applique un modèle ARIMA (ARMA ou ARIMA) sur la GTS passée en paramètre
# FORECAST.ADDVALUES: fait une précision sur les 7 prochaines occurences et les fusionne avec la série sur laquelle la projection est faite.
# Les 3 projections restant dans la pile, elles sont affichées
[ $revenue mapper.todouble 0 0 0 ] MAP
SEARCH.ARIMA
7 FORECAST.ADDVALUES
[ $exp mapper.todouble 0 0 0 ] MAP
SEARCH.ARIMA
7 FORECAST.ADDVALUES
[ $result mapper.todouble 0 0 0 ] MAP
SEARCH.ARIMA
7 FORECAST.ADDVALUES
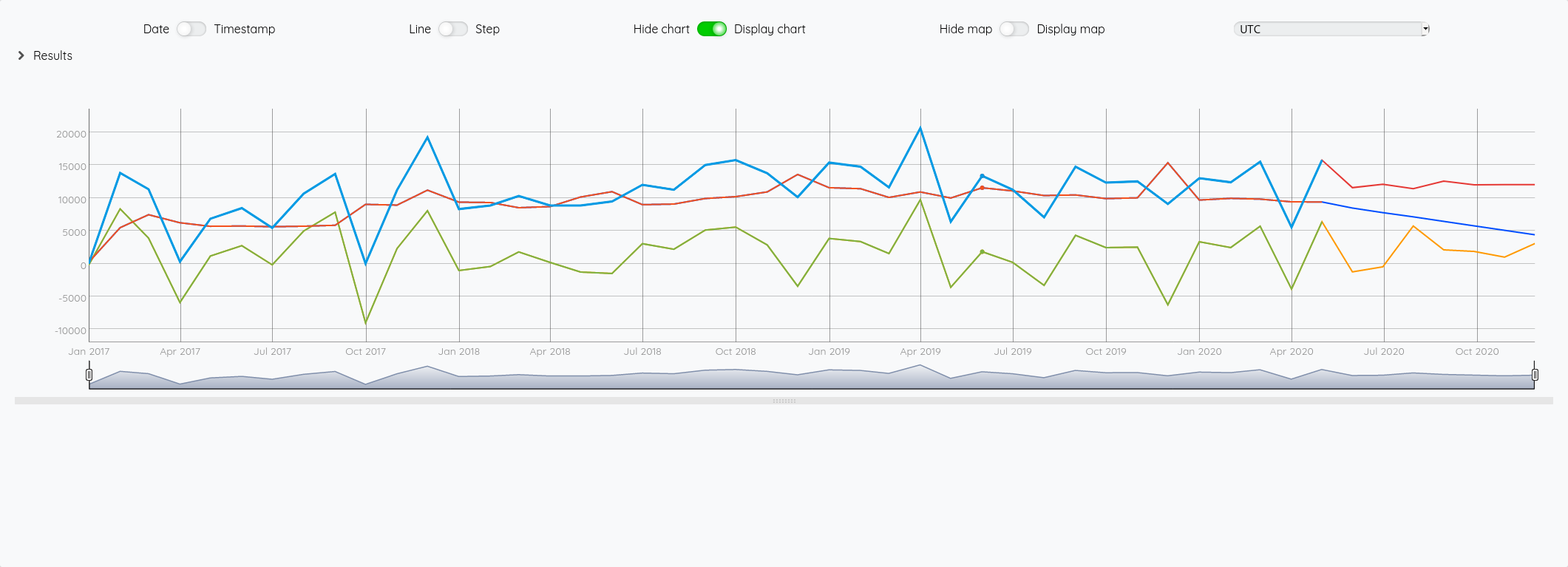
Et nous obtenons bien le même résultat.
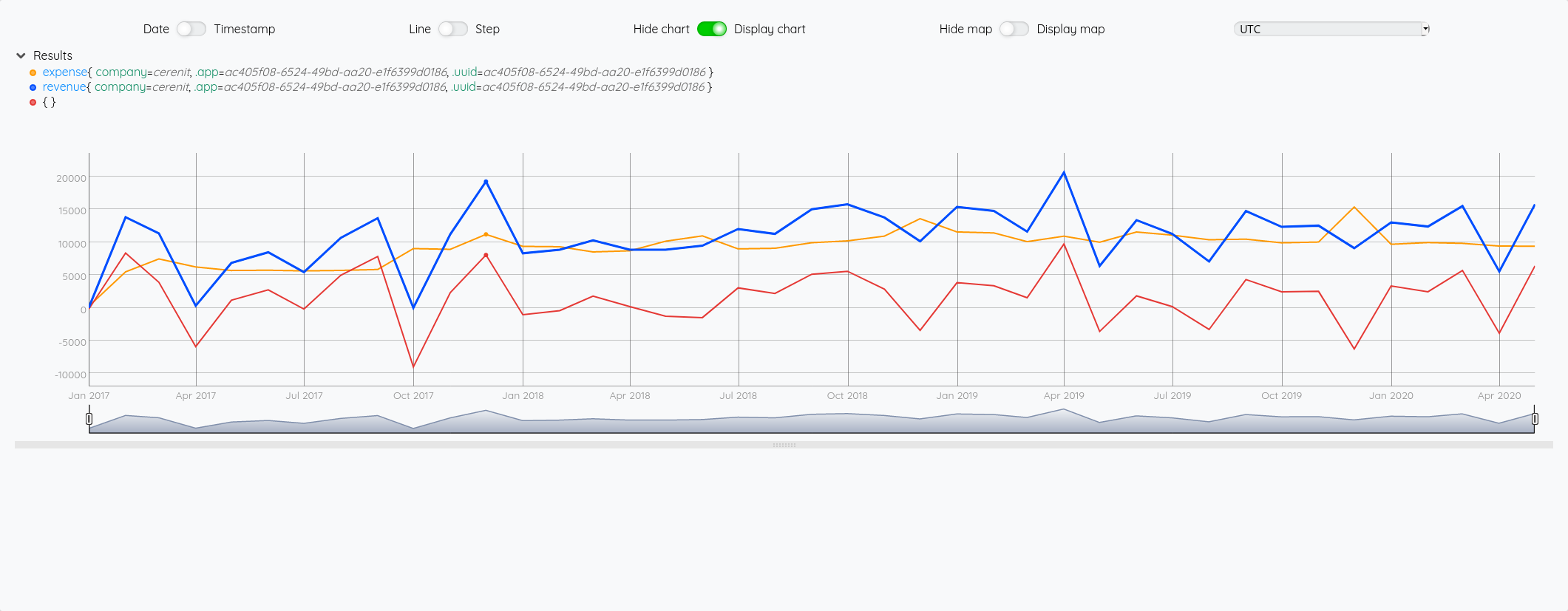
On peut se poser alors la question de voir si la projection sur le résultat est la même que la soustraction entre la projection de chiffres d’affaires et de dépenses et mesurer l’éventuel écart.
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
[[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
CLEAR
# La différence sur les 3 projections est que l'on stocke chaque résultat dans une variable
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
'fresult' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
'frevenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
'fexp' STORE
$frevenue
$fexp
$fresult
# ici on calcule la projection du résultat sur la base des projections de chiffres d'affaires et de dépenses
$frevenue $fexp -
On constate bien un écart entre la courbe orange (la soustraction des projections) et la courbe bleu (la projection du résultat).
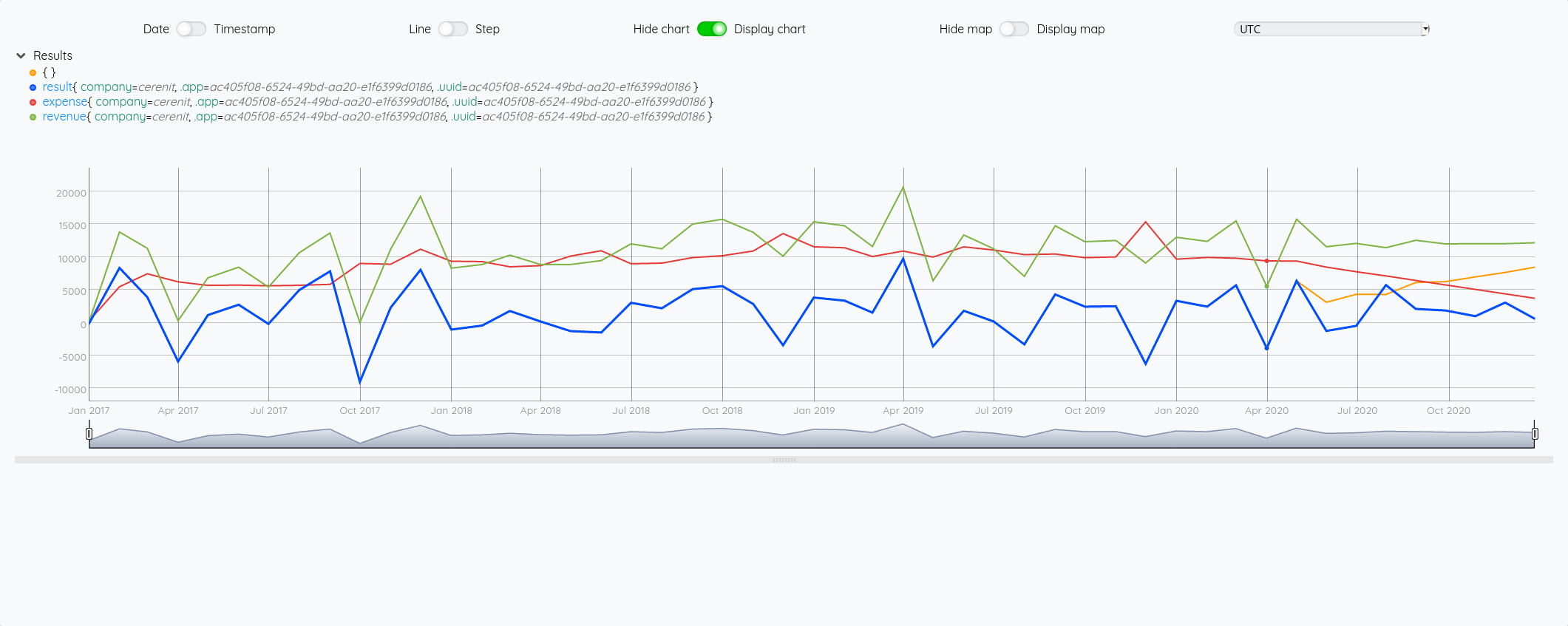
Nous voilà à la fin de ce billet, j’espère que ce tour du propriétaire vous aura permis d’apprécier Warp10 et ses capacités.
Il ne reste plus qu’à voir en fin d’année dans quelles mesures ces projections seront valides ou pas !
Mon bilan sur Warp10 à ce stade :
- Il faut absolument suivre le tutoriel sur les cyclones, cela permet de se mettre progressivement à Warpscript et de comprendre les mécanismes de fonctionnement du langage et de la pile (stack).
- la notation de Warpscript est particulière au début mais on s’y fait petit à petit et sinon FLoWS devrait lever les dernières réticences.
- Comme on a une pile, il ne faut pas hésiter à utiliser
STOPetTYPOEOFnotamment pour savoir ce que l’on manipule comme donnée à un instant T ; cf Debugging WarpScript - Le WarpStudio ou l’extension VSCode permettent d’avoir un contexte de développement agréable avec l’autocomplétion, la documentation des fonctions, etc.
- Contrairement à InfluxDB où tout s’articule autour du measurement (équivalent de la classe ici), le fait d’avoir un langage de manipulation (et pas principalement de requêtage avec quelques transformations) de données permet d’avoir une modélisation plus souple et de réconcilier les données ensuite. Le même exercice dans InfluxDB supposerait d’avoir un seul measurement et d’avoir les différentes valeurs en son sein. Du coup, cela empêcherait le calcul et le stockage du résultat par ex. Il aurait fallu le calculer au préalable et l’insérer dans la base en même temps que les données de chiffre d’affaires et de dépenses pour que les données soient ensemble. Certes Flux et InfluxDB 2.0 vont lever quelques contraintes de modélisation et de manipulation de données, mais le prisme de la modélisation autour du measurement reste primordial dans le produit.
- Avoir un langage de manipulation de données et non uniquement de requêtage et quelques transformation évite aussi de devoir sortir les données pour les analyser puis les renvoyer vers la base de données le cas échéant. Non seulement on reste au plus près de la donnée (éxécution coté serveur) mais on évite aussi les problématiques de drivers, conversion dans les structures de données du langage cible, etc.
- Les classes de warpscript sont certes mono valeurs (même si le multivalue existe) mais je présume que cela sert surtout pour des données de même nature plutôt que pour des données hétérogènes. En effet, il s’agit d’une liste et non d’un tableau de données. (NDLR: Mathias me précise qu’une multivalue est une GTS et non une simple liste - cela est précisé si on lit bien la totalité de la doc de multivalue)
Une expérience au final positive qui pousse à aller creuser plus loin les fonctionnalités de cette plateforme. Ce sera l’opportunité de rédiger d’autres billets à l’avenir.
