Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Ma comptabilité, une série temporelle comme les autres - partie 2 - actualisation des données et des prévisions
warp10 timeseries comptabilité prévision forecastSuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021 (ce billet)
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512
- Partie 6 - Les FEC et le compte de résultat
L’année dernière, nous avions travaillé sur Warp 10 et mes données de comptabilité et jouer un peu avec les algo de prévision.
Les données comptables ayant été un peu ajustées entre temps et la librairie de prévision ayant aussi évolué coté SenX, les résultats ne sont plus tout à fait les mêmes. Nous allons donc reprendre tout ça.
Rappel des fais et prévisions à fin 2020
En septembre dernier, nous avions ce code pour avoir les données jusqu’au mois de Mai 2020 et une prévision jusqu’à la fin d’année:
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de dépenses / chiffre d'affaires / résult pour la période du 01/01/2017 -> 31/05/2020
// Chaque série est stockée dans une variable
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// On affiche les trois courbes
$revenue
$exp
$result
// On génère et affiche les prévisions - on renomme les séries pour mieux les différencier ensuite au niveau dataviz
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_expense" RENAME
Au global :
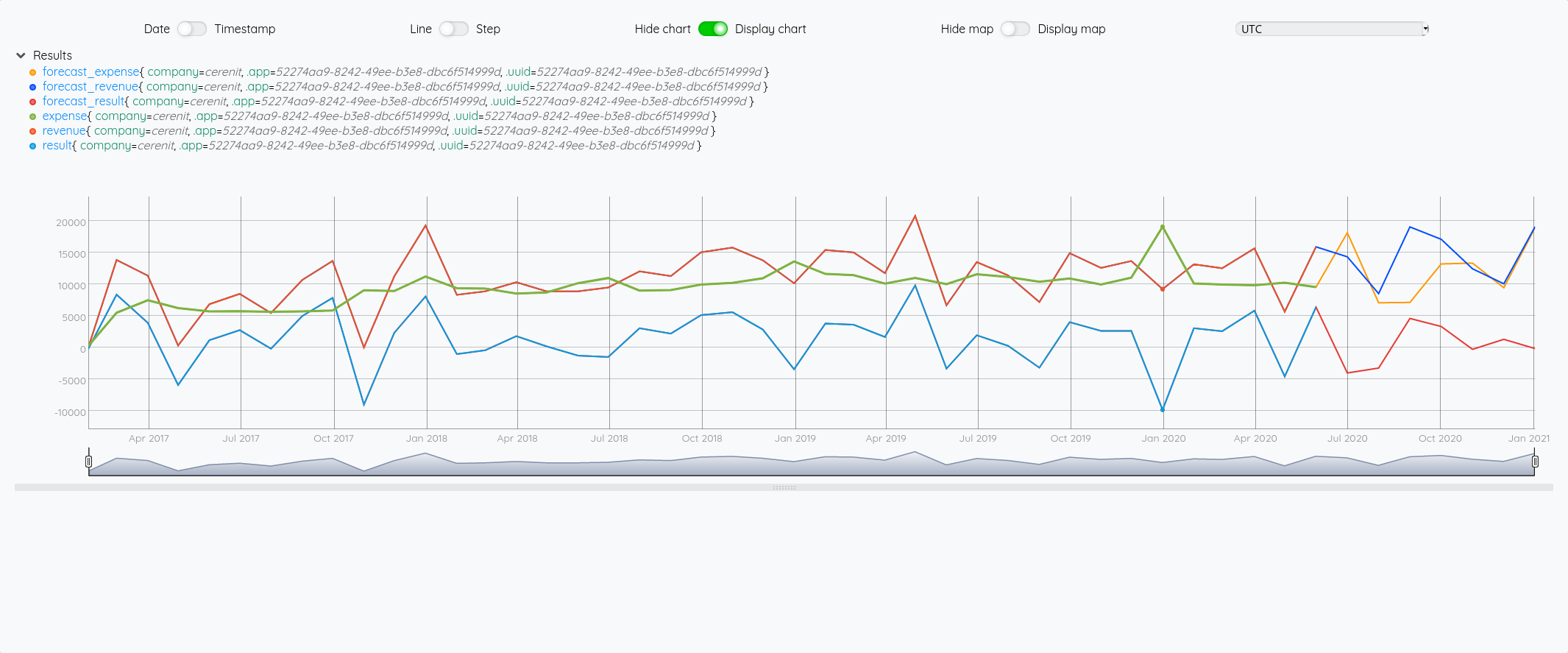
Focus 2020 avec la partie prévision à partir de juin :
Si on fait la même chose en prenant un algo incluant un effet de saisonnalité :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de dépenses / chiffre d'affaires / résult pour la période du 01/01/2017 -> 31/05/2020
// Chaque série est stockée dans une variable
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// On affiche les trois courbes
$revenue
$exp
$result
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_expense" RENAME
Au global :
Focus 2020 avec la partie prévision à partir de juin :
On a bien un petit écart de comportement sur la prévision entre les deux modèles (focus sur 2020 avec les différentes prévisions à partir de juin) :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de dépenses / chiffre d'affaires / résult pour la période du 01/01/2017 -> 31/05/2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_expense" RENAME
// On génère et affiche les prévisions - on renomme les séries pour mieux les différencier ensuite au niveau dataviz
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_expense" RENAME
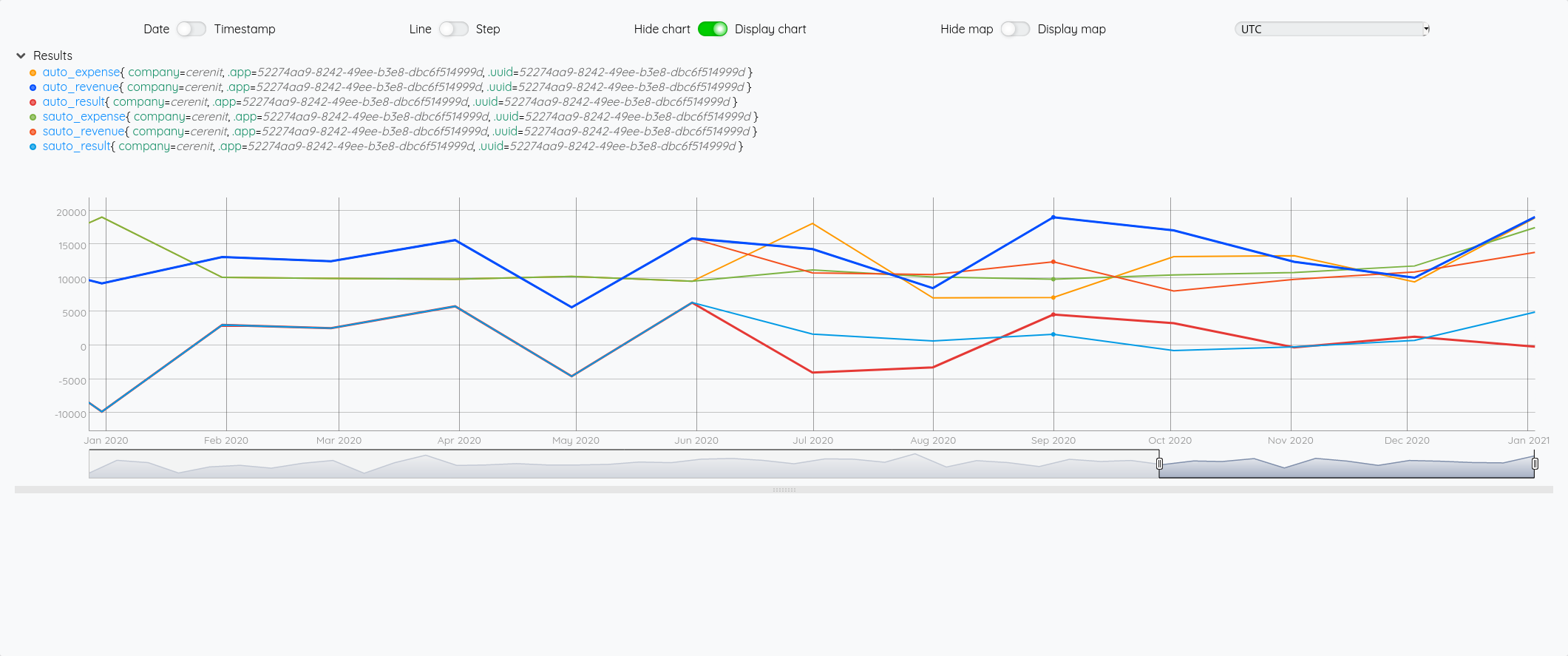
Prévisions vs réalité
Comparons maintenant les prévisions à la réalité - je vais rajouter les requêtes pour avoir la vue complète des données - pour éviter de trop surcharger le graphique, comme les séries forecast_* reprennent les données sources et y ajoutent la prévision, je ne vais afficher que ces séries et les séries réelles :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de base qui serviront ensuite pour la prévision
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// Récupération des données réelles de la période 01/01/2017 > 31/12/2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_result' STORE
// Génération des prévisions
// Pour SAUTO, il faut définir en plus un cycle, ici 12 mois
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_expense" RENAME
$real_result
$real_revenue
$real_exp
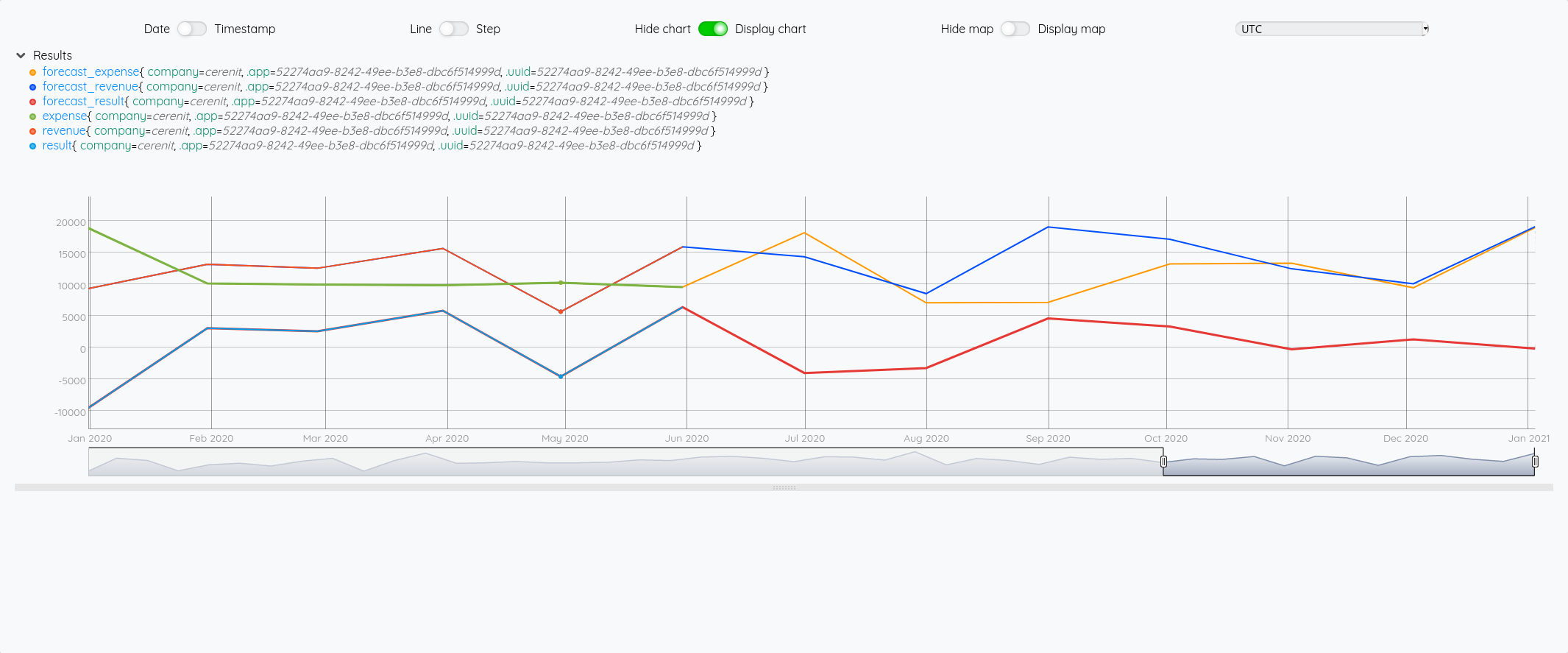
Ce qui nous donne au global :
et avec le focus 2020 :
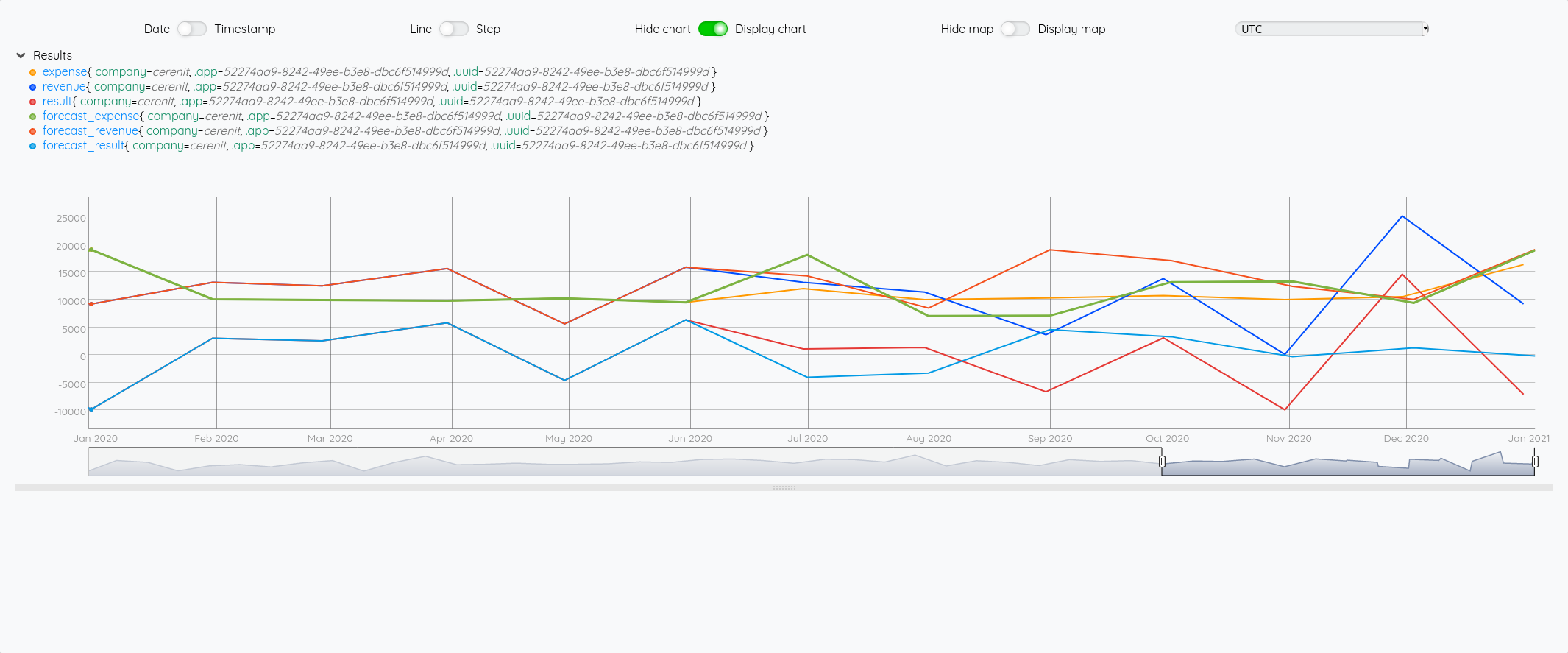
Si on fait la même chose avec SAUTO
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de base qui serviront ensuite pour la prévision
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// Récupération des données réelles de la période 01/01/2017 > 31/12/2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_result' STORE
// Génération des prévisions
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_expense" RENAME
$real_result
$real_revenue
$real_exp
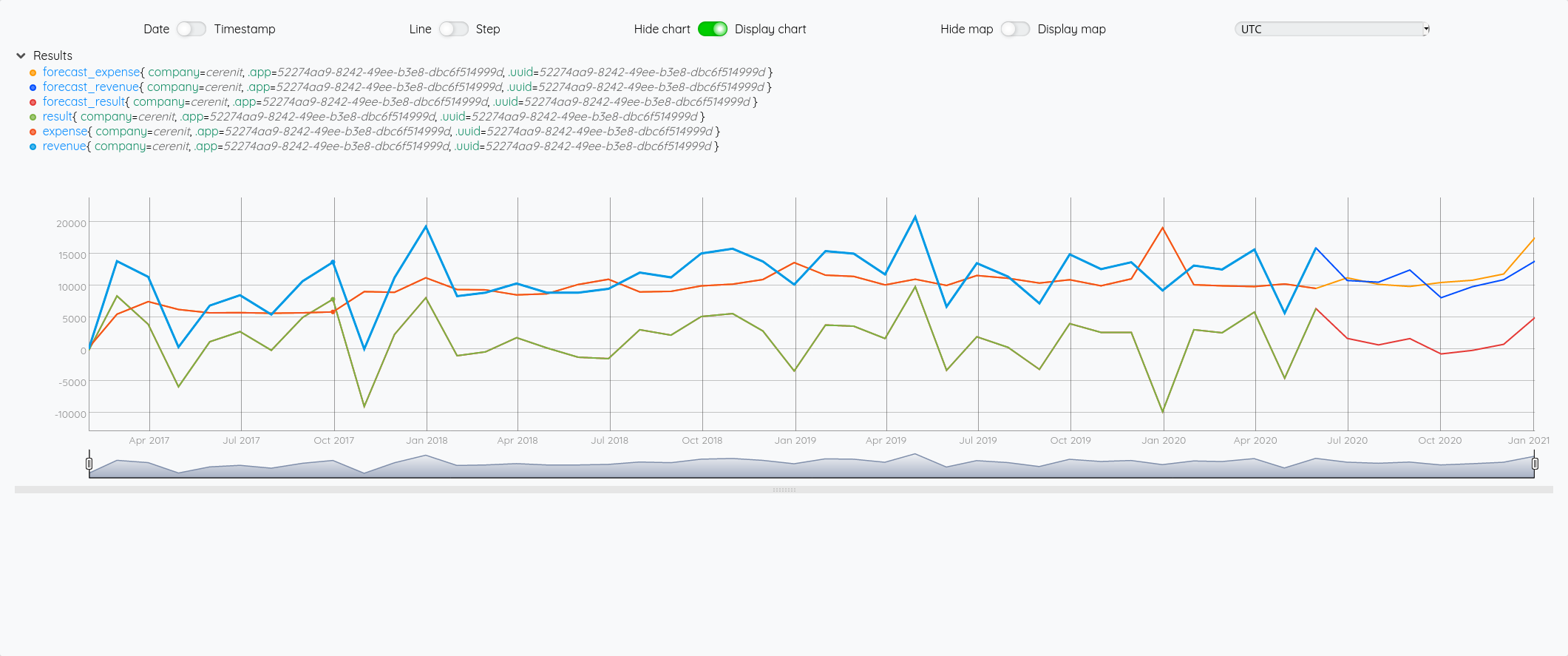
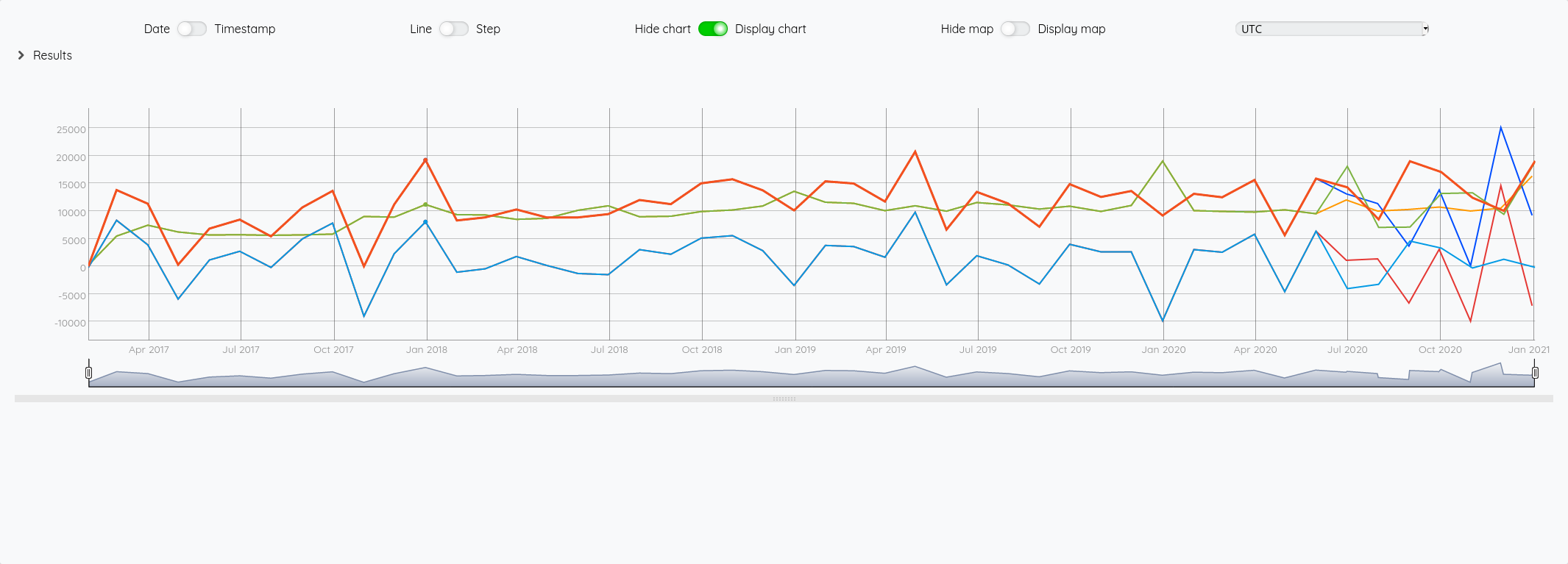
Au global :
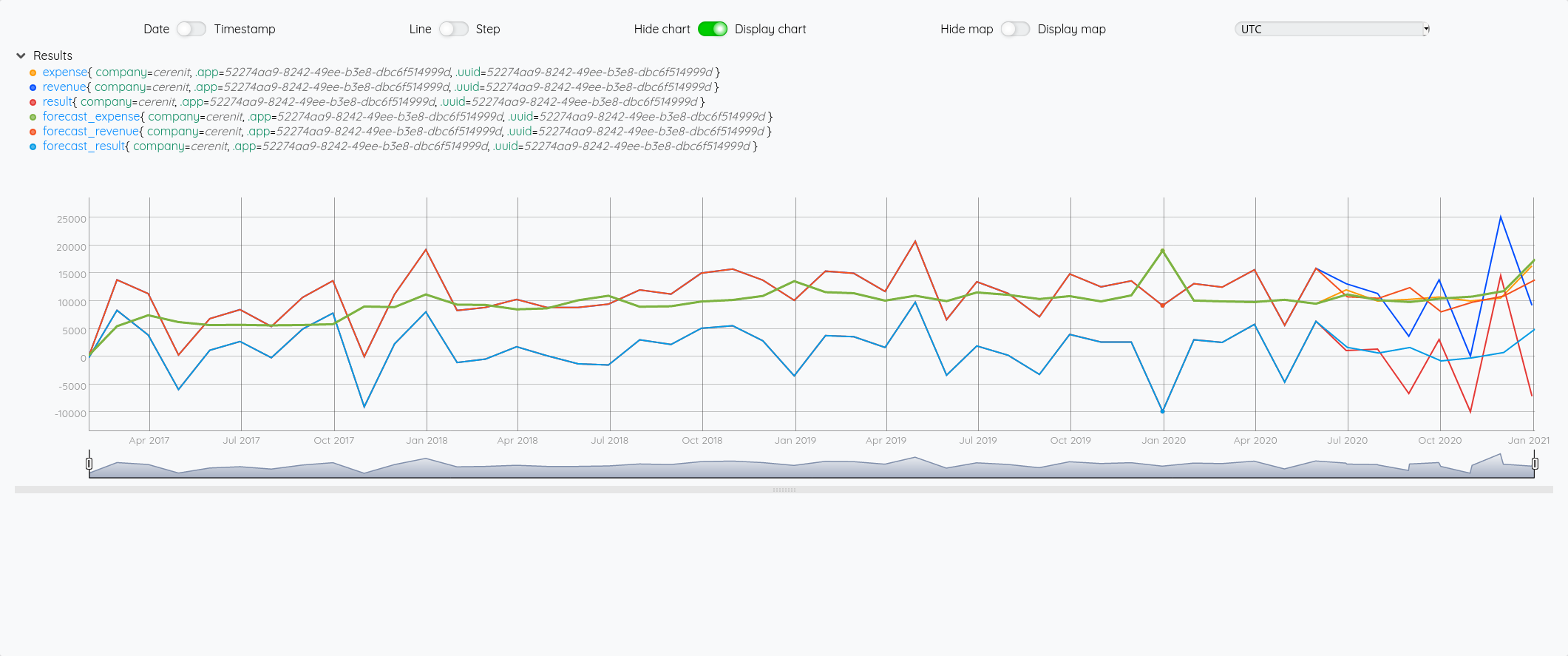
Focus 2020 avec la partie prévision à partir de juin :
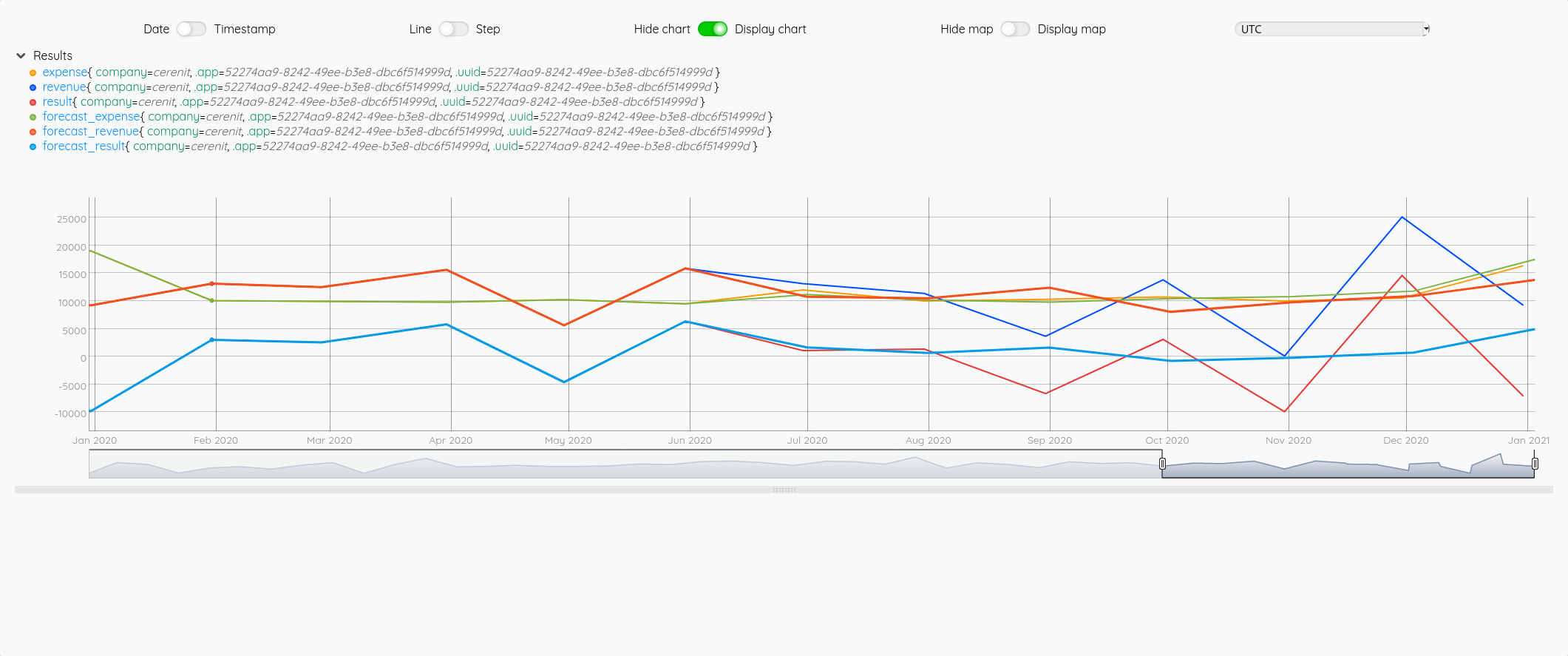
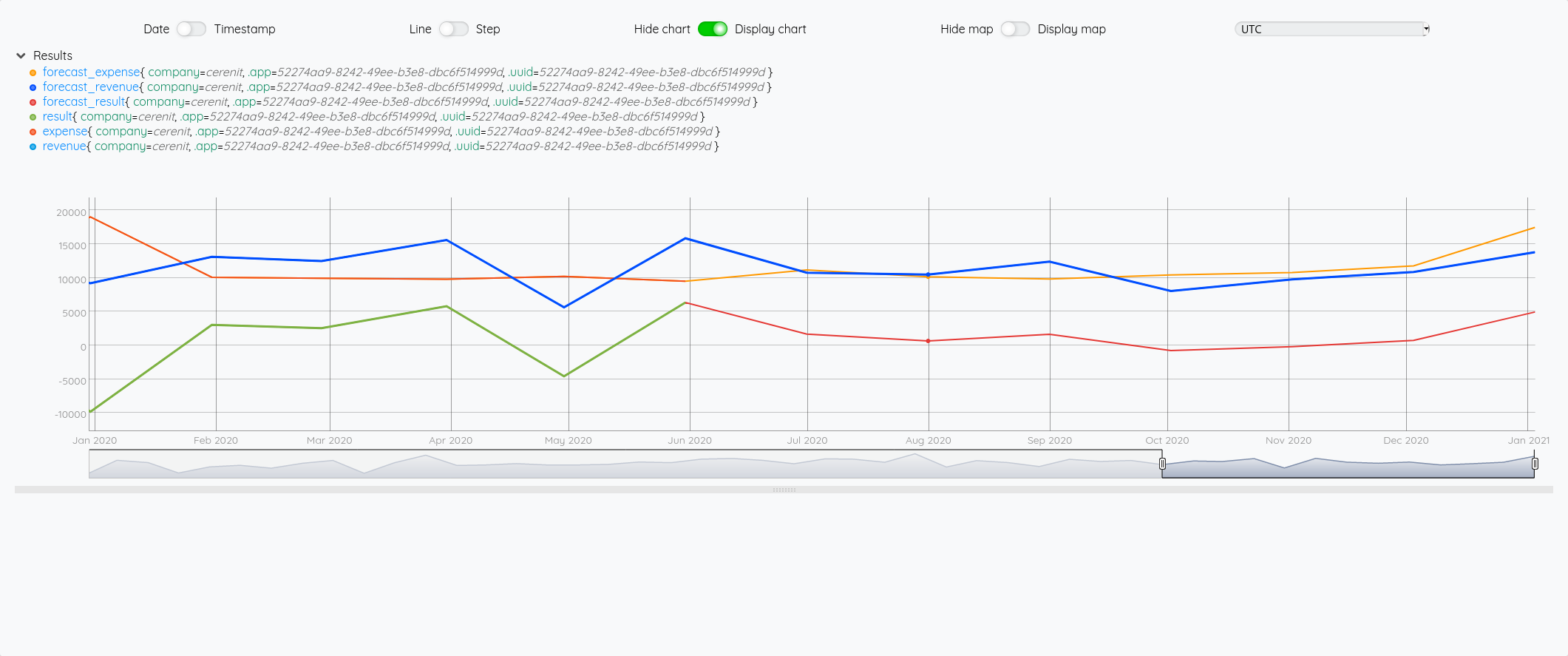
Essayons d’analyser tout ça (il faut regarder les fins de mois - les points sont en date du dernier jour du mois) :
- Pour Juin/Juillet, la prévision est plutôt bonne.
- Pour Aout : l’écart vient du fait que j’ai pris mes vacances en aout et pas à cheval sur juillet/aout comme les autres années
- Pour Septembre, c’est correct
- Pour Octobre, il faut voir que j’ai tardé à éditer mes factures - elles ont donc été pris en compte sur Novembre - si on divise le montant de Novembre en deux, on retombe à peu près sur nos points
- Pour décembre, un effet vacances également.
La pertinence est prévisions est donc plutôt correct au global et les écarts sont expliquables.
Consolidation annuelle
Et au niveau annuel ? Est-ce que les prévisions de chiffres d’affaires / dépenses / résultats sont bonnes si on ne tient plus compte des petits écarts de temps ci-dessus ?
Voyons celà :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des différentes séries comme précédemment
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_result' STORE
// Calcul des prévisions comme précédemment
// Petit ajout, on stocke le résultat sous la forme d'une variable pour être réutilisé ultérieurement
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_result" RENAME
'auto_result' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_revenue" RENAME
'auto_revenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_expense" RENAME
'auto_expense' STORE
// Aggrégation annuelle
// Utilisation de BUCKETIZE.CALENDAR et de la macro BUCKETIZE.byyear qui s'appuie dessus et qui permet de faire une aggrégation annuelle sur des données
// bucketizer.sum permet d'appliquer une somme sur les données regroupées par année
// UNBUCKETIZE.CALENDAR permet de retransformer l'indice issue de BUCKETIZE.CALENDAR en timestamp
[ $real_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $real_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $real_exp bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $auto_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $auto_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $auto_expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
// Meme chose pour SAUTO
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_result" RENAME
'sauto_result' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_revenue" RENAME
'sauto_revenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_expense" RENAME
'sauto_expense' STORE
[ $sauto_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $sauto_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $sauto_expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
Pour expliciter un peu au dessus :
On veut obtenir un résultat annuel couvant la période du 01/01 au 31/12 d’une année. Il faut donc prendre tous les points de l’année en question et en fait la somme.
Si on fait:
[ $real_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear
On obtient :
[{"c":"revenue","l":{"company":"cerenit",".app":"52274aa9-8242-49ee-b3e8-dbc6f514999d",".uuid":"52274aa9-8242-49ee-b3e8-dbc6f514999d"},"a":{".buckettimezone":"UTC",".bucketduration":"P1Y",".bucketoffset":"0"},"la":1612528364518,"v":[[47,100850],[48,132473],[49,151714],[50,139146]]}]
Les valeus obtenues sont :
[[47,100850],[48,132473],[49,151714],[50,139146]]
Les indices 47, 48, 49, 50 sont en fait un delta par rapport au 01/01/70. En effet, 2020 = 1970 + 50
En appliquant UNBUCKETIZE.CALENDAR, on retransforme ce 50 par ex en son équivalent sous la forme d’un timestamp : 1609459199999999.
On peut aussi utiliser TIMESHIFT de la façon suivante :
[ $real_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
Pour obtenir pour la partie valeur :
[[2017,100850],[2018,132473],[2019,151714],[2020,139146]]
Pour en savoir plus sur BUCKETIZE.CALENDAR et ses utilisations : Aggregate by calendar duration in WarpScript
Une fois qu’on reprend toutes ses données, on peut essayer de mesurer les écarts entre le réél et les prévisions des deux modèles :
| AUTO | SAUTO | Réel | AUTO vs Réel | SAUTO vs Réel | |
|---|---|---|---|---|---|
| Chiffre d’affaires | 144.029 | 125.128 | 139.146 | -3,39% | +11,20% |
| Dépénses | 117.701 | 113.765 | 129.464 | +9,99% | +13,80% |
| Résultat | 14.754 | 16.893 | 9.682 | -34,38% | -42,69% |
| Résultat corrigé | 26.328 | 11.363 | 9.682 | -63,23% | -14,79% |
Intéressant, la prévision de résultat n’est pas égale à la différence entre la prévision de chiffre d’affaires et la prévision des dépenses ! C’est la raison de la ligne “Résultat corrigé”.
A ce stade, il ne me semble pas possible de privilégier un modèle plus qu’un autre - même si du fait de la récurrence des vacances, on peut supposer que le modèle avec saisonnalité pourrait être plus pertinent.
Prévisions pour 2021
Pour aller au bout de cet exerice, il ne reste plus qu’à voir ce que nos algoritmes prévoient pour 2021 :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des séries 2017 > 2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// Prévision sur les 12 prochains mois
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_result" RENAME
'auto_result' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_revenue" RENAME
'auto_revenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_expense" RENAME
'auto_expense' STORE
// Consolidation annuelle avec AUTO
[ $auto_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $auto_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $auto_expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
// Prévisions avec SAUTO
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_result" RENAME
'sauto_result' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_revenue" RENAME
'sauto_revenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_expense" RENAME
'sauto_expense' STORE
// Consolidation annuelle avec SAUTO
[ $sauto_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $sauto_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $sauto_expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
On passe tout ça dans le shaker et on obtient :
| Prévu avec AUTO | Prévu avec SAUTO | |
|---|---|---|
| Chiffre d’affaires | 78.230 | 129.465 |
| Dépénses | 118.383 | 110.434 |
| Résultat prévu | 5.730 | 4.049 |
| Résultat corrigé | -40.153 | 19.031 |
Rendez-vous à la fin de l’année pour voir ce qu’il en est… et on peut espérer que la réalité sera proche du modèle avec saisonnalité !
Pour le moment, on travalle toujours dans le WarpStudio et on voudrait bien avoir des (jolis) dashboards qui font tout ça pour nous plutôt que de copier/coller du Warpscript. Ce sera le sujet de la partie 3.
Web, Ops & Data - Janvier 2021
timeseries prometheus promql ovhcloud iot openhab timescaledb ptsm anomalie label machine learning iac ansible libssh vector log warp10 influxdb openssh gpg podman docker-compose sudoCloud
- Traefik Proxy 2.4 Adds Advanced mTLS, Kubernetes Service APIs, and More : Support du Proxy Protocol pour les services TCP, support avancé pour mTLS (et possible intégration Consul Connect) et support initial de la nouvelle API Service de Kubernetes pour les principales avancées. Le programme pour la 2.5 semble aussi alléchant : support HTTP/3, migration vers networking/v1 de Kubernetes et une nouvelle documentation (encore ?!).
- OVHcloud obtient le Visa de sécurité ANSSI pour sa qualification SecNumCloud : OVHCloud obtient la certification SecNumCloud de l’ANSSI pour sa solution “Hosted Private Cloud”.
Code
- GitLab release feature report : le code qui permet de générer le rapport ce qui a changé entre les versions de Gitlab.
- SSH is the new GPG : les dernières versions d’OpenSSH permettent de signer un fichier. Une solution intermédiaire entre de la signature de fichiers à base de MD5 & co qui donnent des informations de conformité mais sans indiquer qui a signé le fichier et une solution GPG plus complexe à mettre en oeuvre ?
Container et orchestration
- Using Podman and Docker Compose : podman, le “daemonless container engine” va permettre d’être utilisé avec docker-compose dans le cadre de la version 3.0. De quoi favoriser l’adoption de podman ?
Infra as code
- New LibSSH Connection Plugin for Ansible Network Replaces Paramiko, Adds FIPS Mode Enablement : Ansible change de librairie pour les connexions ssh en remplaçant paramiko par libssh. Elle se veut plus performante et peut être requis dans un contexte demandant du FIPS. Pensez à installer le paquet
libssh-dev(el)suivant votre distribution pour pouvoir installeransible-pylibssh. Mes premiers essais ne notent pas une amélioration sensible des performances… à voir sur d’autres machines et dans la durée…
IoT
- openHAB 3.0 Release et Release Notes : OpenHAB est une plateforme open source de gestion de périphétiques IoT et d’automatisation autour de ces périphériques. Elle est développée en Java, support 2000 “Things” (objets, équipements, protocoles). La version 3.0 apporte une refonte et l’unification de l’UI et des composants, le passage à Java 11 et plein d’autres choses. La migration depuis une version 2.x se fait assez simplement. Avec le nouveau moteur de règle, j’ai pu supprimer mon code spécifique. Reste encore la partie “Pages” à appréhender… J’avais préféré OpenHAB à Jeedom et Home Assistant
- Meet Raspberry Silicon: Raspberry Pi Pico now on sale at $4 : la fondation Raspberry Pi se lance dans les micro-controlleurs avec le Pico au prix de 4$.
- Raspberry Pi PICO la carte Microcontrôleur de la Fondation : un article très détaillé sur la prise en main du pico.
Observabilité
- Métriques, monitoring, push vs pull, Riemann, Vector : Panorama sur le push/pull dans le monde du monitoring et tour d’horizon des solutions existantes pour arriver à Vector dont je vous parlais le mois dernier.
- Une introduction à Vector : Tout est dans le titre, mise en place de quelques outils remontant des métriques et des logs et ingestion des métriques dans InfluxDB via Vector.
- OVHCloud > Logs Data Platform > Using Elasticsearch API to send your logs - Use Case: Vector : Si vous utilisez l’offre Logs Data Platform d’OVHCloud pour vos logs, vous pouvez utiliser le sink elasticsearch de Vector pour envoyer vos logs vers Logs Data Platform.
- First-class Kubernetes Integration for Vector : Dans le cadre de la release 0.11, Vector a annoncé un support de Kubernetes avec une phase de collecte et d’enrichissement des logs. Cela mériterait d’être creusé…
Système
- CVE-2021-3156: Heap-Based Buffer Overflow in Sudo (Baron Samedit) & Buffer overflow in command line unescaping: il est temps de patcher vos systèmes linux utilisant sudo - l’attaque permet de faire une élévation de privilèges si le fichier
sudoersest présent sur le système (en général:/etc/sudoers). Les versions 1.8.2 à 1.8.31 et 1.9.0 à 1.9.5-p1 sont impactées, il faut passer en version 1.9.5-p2.
Time Series
- Erlenmeyer and PromQL compatibility : OVHCloud, dans le cadre de leur offre OVH Metrics, a développé Erlenmeyer, un proxy qui permet de convertir différents format de séries temporelles (Promql, Influxql, OpenTSDB, etc) au format Warp 10 qui est utilisé pour stocker ces métriques. Le billet porte sur leur retour d’expérience sur l’utilisation du “PromQL compliance tester” pour valider qu’Erlenmyer supportait bien les requêtes PromQL.
- TimescaleDB 2.0 GA : User Defined Functions, Multi-Nodes, les fonctionnalités de la version Entreprise dans la version Communautaire et plein d’autres améliorations/corrections/optimisations. Cf TimescaleDB 2.0: A multi-node, petabyte-scale, completely free relational database for time-series
- Paris Time Series #9 : Comment gérer la labellisation des séries-temporelles et la détection d’anomalies grâce à InfluxDB ? : Présentation de Julien Muller d’ezako sur la labellisation de séries temporelles et de la détection d’aonomalies en s’appuyant sur InfluxDB pour le stockage de ces données temporelles.
- InfluxData closes 2020 with exponential cloud growth, expanding user base, and big new customers : bilan 2020 pour InfluxData avec quelques chiffres sur la croissance de leur offre cloud (x13), utilisateurs du free tier InfluxCloud (x5), Répartition des (nouveaux ?) cllients (OInfluxCloud) 55% USA et 45% Europe, 450K instances OSS actives, quelques grosses références et un développement à venir en Asie/Pacifique.
- Telegraf 1.17 : version pour laquelle je découvre le processeur Starlark. Ce processeur permet de définir une fonction sur les métriques permettant par exemple de ne remonter une valeur que si elle est différente de la précédente. Cela peut économiser des données dans des systèmes contraints.
- Infographic: What happened in 2020 for SenX? : retour de SenX sur l’actualité autour de Warp 10 (mais pas que)
- Parution des premiers tutoriels FLoWS : FLoWS Basic et FLoWS vs WarpScript
- Warp 10 2.7.2 : version de maintenance.
- Alerts are real time series : et si les alertes étaient elles-mêmes des séries temporelles ? S’il était assez évident de dissocier la partie génération de l’alerte (traitement) de la partie notification, on peut aller encore plus loin en matérialisant ces données d’alertes sous la forme d’une série temporelle. Une approche intéressante qui ouvre des possiblités de traitement et d’analyses complémentaires alors que les logiciels actuels ne persistent pas souvent/longtemps cette information.
- Utilisation des séries temporelles dans le cadre du Vendéee Globe : Vitesse et amures pour le bateau de Boris Herrmann - Seaexplorer Yacht Club de Monaco avec Warp 10 et l’ensemble des données du même bateau mise à disposition : Live data from Seaexplorer - Yacht Club de Monaco. Il y a des séries temporelles plus intéressantes que d’autres ! 😉
- High Performance Sailing Monitoring for the Vendée Globe : le making-off du tweet ci-dessus et bien plus encore !
AIM45
timeseries warp10 influxdbContexte
La société AIM45 est éditrice de la plateforme web M2 pour la course au large. Elle utilise la solution Warp 10 pour stocker ses séries temporelles. Pour étoffer son offre, elle doit intégrer les données d’un partenaire qui utilise quant à lui la solution InfluxDB. AIM45 nous a sollicité pour les accompagner dans cette intégration.
Notre réponse
- Expertise sur la plateforme InfluxDB
- Bonne connaissance de la plateforem Warp 10
- Accompagnement des équipes internes dans la définition des scénarios d’intégration avec le partenaire
- Accompagnement des équipes internes pour maitriser les concepts et les différences entre les produits Warp 10 et InfluxDB pour une meilleure appréhension du sujet
- Participation aux réunions avec le partenaire pour faciliter les échanges entre les équipes, expliciter les différences entre les produits et contribuer aux échanges sur la définition de la solution finale.
- Accompagnement à la carte en fonction des besoins des équipes AIM45.
Bénéfices pour l’éditeur
- Expertise sur les solutions de séries temporelles Warp 10 et InfluxDB
- Prise en main facilitée et accélérée pour les équipes internes sur InfluxDB
- Facilitation pour les échanges avec le partenaire.
- Expertise en termes d’architure système et applicative.
Bénéfices pour CérénIT
- Poursuite des projets sur les séries temporelles avec un nouvel usage : la série temporelle dans le monde de la course au large
Web, Ops & Data - Décembre 2020
docker runc rootless swarm cgroups kubernetes cri dockershim vector aws timestream warp10 dashboard ptsm timescale centos rhel podman influxdb timeseriesContainers et orchestration
- Electro Monkeys #37 – Podman, l’alternative de Redhat à Docker avec Benjamin Vouillaume : je me demandais si podman permettait un management de containers à distance et l’étendue de son écosystème. Le podcast permet de compléter le tour du propriétaire et de se faire une bonne idée de son positionnement.
- How to deploy on remote Docker hosts with docker-compose : dans la même quête, je me demandais s’il était possible de piloter un noeud docker à distance quand je me suis rappelé qu’il était possible de le faire au travers d’une connexion ssh. En creusant un peu plus, j’ai découvert la notion de contexte qui permet ainsi de cibler un noeud docker, docker swarm ou kubernetes.
- Don’t Panic: Kubernetes and Docker et Dockershim Deprecation FAQ : A partir de kubernetes 1.20 (fin 2020) et définitivement à partir de la version 1.23 (fin 2021), le retrait du binaire docker comme CRI de Kubernetes est annoncé. Cela ne devrait pas changer grand chose et c’est essentiellement de la plomberie interne. Plutôt que de passer par Dockershim qui implémentait l’interface CRI et qui discutait ensuite avec Docker pour lancer les conteneurs via containerd, l’appel sera directement fait à containerd. Il n’y a que ceux qui montent la socket docker dans les pods qui vont avoir un souci. Si c’est pour builder des images, il y a des alternatives comme
img,kaniko, etc. Pour les autres cas, il faudra peut être passer par l’API kubernetes ou trouver les alternatives qui vont bien. - What developers need to know about Docker, Docker Engine, and Kubernetes v1.20 et Mirantis to take over support of Kubernetes dockershim : Mirantis et Docker Inc vont assurer le support de cette interface
dockershimpour permettre à ceux qui ont en besoin de pouvoir continuer à l’utliiser. La limite étant que si vous êtes sur du service managé et que votre provider ne le fournit pas, vous ne pourrez pas l’utiliser… - Kubernetes 1.20: The Raddest Release : voilà, la version 1.20 est sortie et apporte son lot de nouveautés et de stabilisation.
- Announcing General Availability of HashiCorp Nomad 1.0 : Nomad 1.0 est également disponible.
- Introducing Docker Engine 20.10 - Docker Blog : Docker 20.10 arrive avec des profondes nouveautés comme le support des cgroupsv2 et un mode rootless,
docker logsfonctionne avec tous les drivers de log et non unqiement json & journald et plein d’autres améliorations/harmonisations au niveau de la CLI. Pour ceux sous Fedora qui avaient bidouillé avec firewalld précédemment pour faire fonctionner docker et qui ont un problème lié à l’interface docker0 au démarrage du service docker, allez voir par ici. - Docker Engine Release Notes - Version 20.10 : En plus des points précédents, il y a l’arrivée des jobs dans swarm - depuis le temps que je l’attendais 🤩 (même si on peut se toujours se poser la question de la pérénnité de swarm depuis qu’il a été racheté par Mirantis)
- New features in Docker 20.10 (Yes, it’s alive) : un billet décrivant plus en détail certaines feautres de docker 20.10 comme support Fedora/CentOS, le rootless mode, l’option
-mount, les jpbs swarm et une synthèse de l’actualité de l’écosystème docker. - Podman Release 2.2.0 : ajout des commandes
network (dis)connect, support des alias avec des noms courts, amélioration des commandesplay|generate kubeet capacité de monter une image OCI dans un container.
Observabilité
- Vector - Collect, transform, & route all observability data with one simple tool. (via) : vector est un outil en rust qui permet de collecter et manipuler des métriques/logs/événements et de les envoyer vers différentes destinations. De quoi remplacer filebeat/journalbeat voire même telegraf ? ;-)
- Our new partnership with AWS gives Grafana users more options : AWS vient d’annoncer un service managé pour Prometheus basé sur Cortex et pour Grafana (version Entrepsise). Grafana et Cortex étant des projets édités par Grafana Labs sous licence OSS (et des déclinaisons Cloud et Entreprise). AWS changerait-il sa façon de travailler avec les projets OSS lorsqu’il souhaite en faire des services managés et prendre ainsi une attitude plus positive vis à vis de la communauté OSS ?
OSS
- Death of an Open Source Business Model : Analyse du passage de Mapbox GL JS v2 sous licence propriétaire, le modèle de l’open core et les menaces des top cloud providers sur le reste de l’économie du logiciel. On peut étendre cela aussi “VC funded OSS company”.
Système
- CentOS Project shifts focus to CentOS Stream, CentOS Stream: Building an innovative future for enterprise Linux et la FAQ associée : Historiquement CentOS Linux était batie sur les sources de Red Hat Entreprise Linux un fois celle-ci disponible. CentOS Stream renverse un peu la tendance avec un cycle d’intégration plutôt Fedora -> CentOS Stream -> RHEL. L’initiative CentOS Stream avait été annoncée en septembre 2019 et ce changement permet donc aux équipes CentOS de se focoaliser sur une seule version (CentOS Stream) et non plus deux versions (CentOS Stream et CentOS Linux). CentOS Linux 7 sera maintenue jusqu’à la fin du support de RHEL 7 et et CentOS 8 jusqu’à fin 2021 (et non pas 2029 comme prévu). Il n’y aura pas de version 9 de CentOS Linux. A tester pour voir si CentOS Stream est plus stable que Fedora mais moins conservateur que RHEL et pourrait alors s’avérer être un bon compromis.
- Before You Get Mad About The CentOS Stream Change, Think About… : un billet assez long d’un employé de Red Hat qui exprime son opinion et cherche à remettre les choses en perspective en dépassionnant le débat.
Time Series
- PTSM Edition #8 - Amazon TimeStream 101 : Edition du Paris time Series Meetup sur AWS Timestream
- TimescaleDB vs. Amazon Timestream: 6000x higher inserts, 5-175x faster queries, 150x-220x cheaper : avec toutes les réserves habitudelles sur les benchmarks, Timescale a comparé son produit avec AWS Timestream et la conclusion semble clairement en faveur de Timescaledb. A noter que l’update des données est arrivé dans AWS Timestream entre temps.
- Truly Dynamic Dashboards as Code : les équipes de SenX ont implémenté leur vision du “Dashboards as Code” sous le nom Discovery. Discovery veut aller plus loin que la simple description d’un dashboard comme on peut le voir dans Grafana ou InfluxDB 2.0 en apportant une touche de dynamisme et de génération dynamique des dashboards en fonction des élements obtenus (ex si valeur X > Y alors afficher la procédure AAA de résolution d’incident). J’ai commencé à jouer avec, un billet de blog sur ce sujet devrait bientôt arriver.
- NeuralProphet : un modèle neuronal orienté série temporelles, inspiré de Facebook Prophet et développé avce PyTorch.
- Release Notes InfluxDB 2.0.3 et Release Announcement: InfluxDB OSS 2.0.3 : build arm64 en preview, un petit conflit de packaging entre
influxdbetinfluxdb2à passer pour ceux qui étaient déjà en 2.0 et ceci afin d’éviter que des gens en 1.x passent involontairement en 2.x, le “delete with predicate” a été réactivé, améliorations sur le process d’upgrade, des commandes autour des actions en mode V1, mise à jour de flux, et plein d’autres corrections/améliorations.
Web
- Web Almanac 2020 - Rapport annuel de HTTP Archive sur l’état du Web : une synthèse de l’état du web d’après HTTP Archive sur une base de 7.5 millions de sites testés, soit 31.3 To de données traitées. De quoi relativisez un peu les biais de notre bulle technologique : non tout le monde ne fait pas du React/Angular/Vue.js par ex mais plutôt du JQuery ! Suivant vos usages, plein d’enseignements et de choses intéressantes à tirer de cette synthèse.
Il ne me reste plus qu’à vous souhaiter de bonnes fêtes de fin d’année et on se retrouve l’année prochaine !
Calcul de la durée d'un état avec des timeseries
timeseries influxdb flux warp10 warpscript durationUn client m’a demandé la chose suivante : “Nicolas, je voudrais savoir la durée pendant laquelle mes équipements sont au delà d’un certain seuil ; je n’arrive pas à le faire simplement”.
Souvent, quand on manipule des séries temporelles, la requête est de la forme “Sur la période X, donne moi les valeurs de tel indicateur”. On a moins l’habitude de travailler dans le sens inverse, à savoir : “Donne moi les périodes de temps pour laquelle la valeur est comprise entre X et Y”.
C’est ce que nous allons chercher à trouver.
Influx 1.8 et InfluxQL
Avec l’arrivée imminente d’Influx 2.0, j’avoue ne pas avoir cherché la solution mais je ne pense pas que cela soit faisable purement en InfluxQL.
Influx 1.8 / 2.0 et Flux
Avec Flux, j’ai rapidement trouvé des fonctions comme duration et surtout stateDuration
L’exemple ci-dessous se fait avec une base InfluxDB 1.8.3 pour laquelle Flux a été activé. Le requêtage se fait depuis une instance Chronograf en version 1.8.5.
Pour approcher l’exemple de mon client, j’ai considéré le pourcentage d’inactivité des CPU d’un serveur que l’on obtient de la façon suivante:
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
Cela donne:

Ensuite, j’ai besoin d’une fonction qui va me rajouter une colonne avec mon état. Cet état est calculé en fonction de seuils - par souci de lisibilité, je vais extraire cette fonction de la façon suivante et appliquer la fonction à ma requête :
set_level = (tables=<-) =>
tables
|> map(fn: (r) => ({
r with
level:
if r._value >= 95 then "fully_idle"
else if r._value >= 90 and r._value <95 then "something_is_moving"
else if r._value >= 85 and r._value <90 then "oh_oh"
else if r._value >= 80 and r._value <85 then "hmm"
else if r._value < 80 then "i_have_to_work"
else "overloaded"
})
)
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
|> set_level()
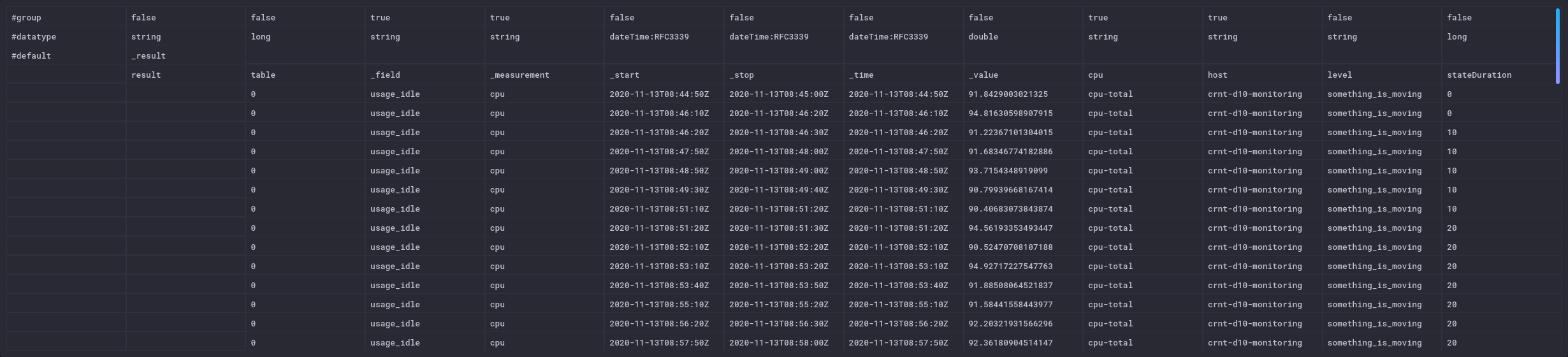
La colonne “level” n’est à ce stade pas persistée en base contrairement aux autres données issue de la base de données.
Cela donne ceci en mode “raw data” - tout à fait à droite

Maintenant que j’ai mon état, je peux application la fonction stateDuration() ; elle va calculer la périodes de temps où le seuil est “something_is_moving” par tranche de 1 seconde. Le résulat sera stocké dans une colonne “stateDuration”. Pour les autres états, la valeur est de -1. La valeur se remet à 0 à chaque fois que l’état est atteint puis la durée est comptée :
set_level = (tables=<-) =>
tables
|> map(fn: (r) => ({
r with
level:
if r._value >= 95 then "fully_idle"
else if r._value >= 90 and r._value <95 then "something_is_moving"
else if r._value >= 85 and r._value <90 then "oh_oh"
else if r._value >= 80 and r._value <85 then "hmm"
else if r._value < 80 then "i_have_to_work"
else "overloaded"
})
)
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
|> set_level()
|> stateDuration(fn: (r) => r.level == "something_is_moving", column: "stateDuration", unit: 1s)
On voit le rajout de la colonne stateDuration en mode “raw data” ; elle n’ont plus n’est pas persistée dans la base à ce stade :

et coté visualisation :

Maintenant que j’ai ces périodes, je vais vouloir savoir quelle est la durée totale de ces différentes périodes que nous avons identifée. On peut en effet imaginer un cas où on sait que l’équipement est à remplacer lorsqu’il a atteint un seuil donné pendant plus de X heures.
Pour cela, je vais:
- filtrer sur un état voulu,
- calculer le différentiel entre chaque valeur de stateDuration pour n’avoir que les écarts non plus la somme des durées en supprimant les valeurs négatives pour gérer les retours à la valeur 0
- et faire la somme de l’ensemble.
set_level = (tables=<-) =>
tables
|> map(fn: (r) => ({
r with
level:
if r._value >= 95 then "fully_idle"
else if r._value >= 90 and r._value <95 then "something_is_moving"
else if r._value >= 85 and r._value <90 then "oh_oh"
else if r._value >= 80 and r._value <85 then "hmm"
else if r._value < 80 then "i_have_to_work"
else "overloaded"
})
)
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
|> set_level()
|> stateDuration(fn: (r) => r.level == "something_is_moving", column: "stateDuration", unit: 1s)
|> filter(fn: (r) => r.level == "something_is_moving")
|> derivative(unit: 10s, nonNegative: true, columns: ["stateDuration"], timeColumn: "_time")
|> sum(column: "stateDuration")
Ce qui me donne un total de 2230 secondes pour l’heure (3600s) qui vient de s’écouler.

C’est un POC rapide pour démontrer la faisabilité de la chose. Le code est surement améliorable/perfectible.
Dans un contexte InfluxDB 2.0, il y a aussi la fonction events.duration qui semble intéressante. Ce billet “TL;DR InfluxDB Tech Tips – How to Monitor States with InfluxDB” montre aussi l’usage de la fonction monitor.stateChanges() qui peut compléter l’approche.
Influx 1.8 / Flux - variante pour les séries irrégulières
La fonction derivative impose d’avoir des durées régulières pour calculer le delta. Dans le cas d’une série irrégulière, cela peut coincer rapidement et fausser les calculs. On peut donc remplacer les deux dernières lignes par la fonction increase. Elle prend la différence entre deux valeurs consécutives (quelque soit leur timestamp) et réalise une somme cumulative. Les différences négatives sont ignorées de la même façon que nous le faisions précédemment.
set_level = (tables=<-) =>
tables
|> map(fn: (r) => ({
r with
level:
if r._value >= 95 then "fully_idle"
else if r._value >= 90 and r._value <95 then "something_is_moving"
else if r._value >= 85 and r._value <90 then "oh_oh"
else if r._value >= 80 and r._value <85 then "hmm"
else if r._value < 80 then "i_have_to_work"
else "overloaded"
})
)
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
|> set_level()
|> stateDuration(fn: (r) => r.level == "something_is_moving", column: "stateDuration", unit: 1s)
|> filter(fn: (r) => r.level == "something_is_moving")
|> increase(columns: ["stateDuration"])
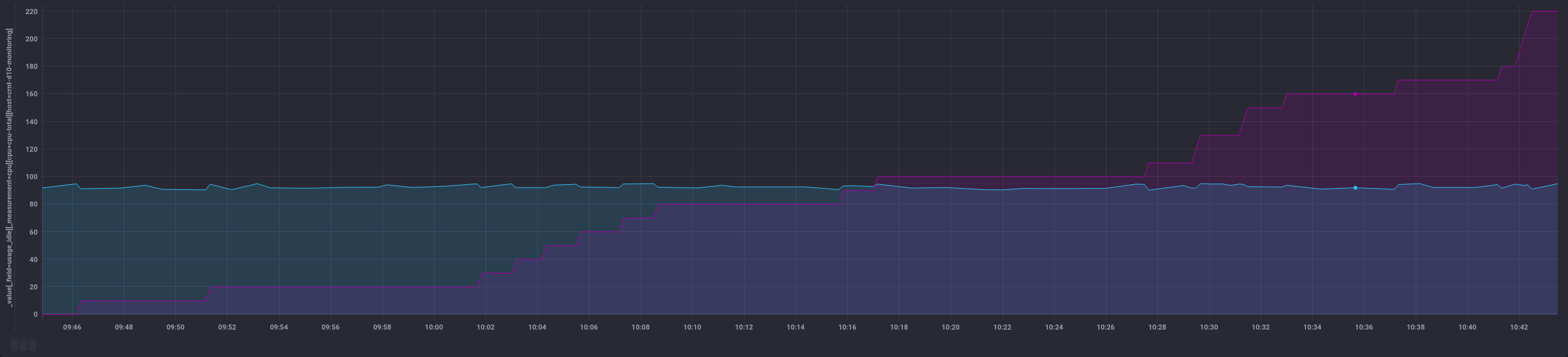
La sortie change un peu car au lieu d’un nombre unique, on a l’ensemble des points filtrés et leur somme au fur et à mesure (colonne de droite):
Cela donne des possiblités différentes au niveau dataviz :
Warp 10 / WarpScript
En la même chose en WarpScript avec Warp 10, cela donne quoi ? Regardons cela :
'<readToken>' 'readToken' STORE
// Récupération des données de cpu de type "usage_idle" en ne prenant que le label "cpu-total"
[ $readToken '~crntd10monitoring.cpu.usage_idle' { 'cpu' 'cpu-total' } NOW 1 h ] FETCH
0 GET // Fetch retourne une liste de GTS, on prend donc la première (et unique) GTS
'cpu' STORE // Stockage dans une variable cpu
// Utilisation de BUCKETIZE pour créer une série régulière de données séparées par 1 seconde
// Mes données étant espacées d'environ 10s, cela va donc créer 10 entrées de 1 seconde au final
// Pour chaque espace, on utliise la dernière valeur connue de l'espace en question pour garder les valeurs de la GTS de départ
[
$cpu
bucketizer.last
0
1 s
0
]
BUCKETIZE
// Les espaces insérés n'ont pas encore de valeurs associées
// On remplit les entrées sans valeurs avec les valeurs ci-dessus
// On utilise FILLPREVIOUS et FILLNEXT pour gérer aussi les premières et dernières valeurs
FILLPREVIOUS
FILLNEXT
// A ce stade, on a donc une GTS avec un point toute les secondes et la valeur associée. Cette valeur était la valeur que l'on avait toutes les 10s précédemment.
// On fait une copie de la GTS pour pouvoir comparer avec la version filtrée par ex
DUP
// On filtre sur les valeurs qui nous intéressent, ici on veut les valeurs >= 90 et < 95
[ SWAP 90.0 mapper.ge 0 0 0 ] MAP
[ SWAP 95.0 mapper.lt 0 0 0 ] MAP
// On renomme la liste (pratique si on affiche par ex l'ancienne et la nouvelle liste dans la partie dataviz - cf capture ci-dessous)
'+:above90below95' RENAME
// On compte le nombre d'élément de la GTS qui est sous la forme d'une liste de GTS à l'issu du MAP
0 GET SIZE
// On multiplie le nombre d'entrées par 1 s
1 s *
// on garde une copie de la valeur en secondes
DUP
// On applique le filtre HUMANDURATION qui transforme ce volume de secondes en une durée compréhensible
HUMANDURATION
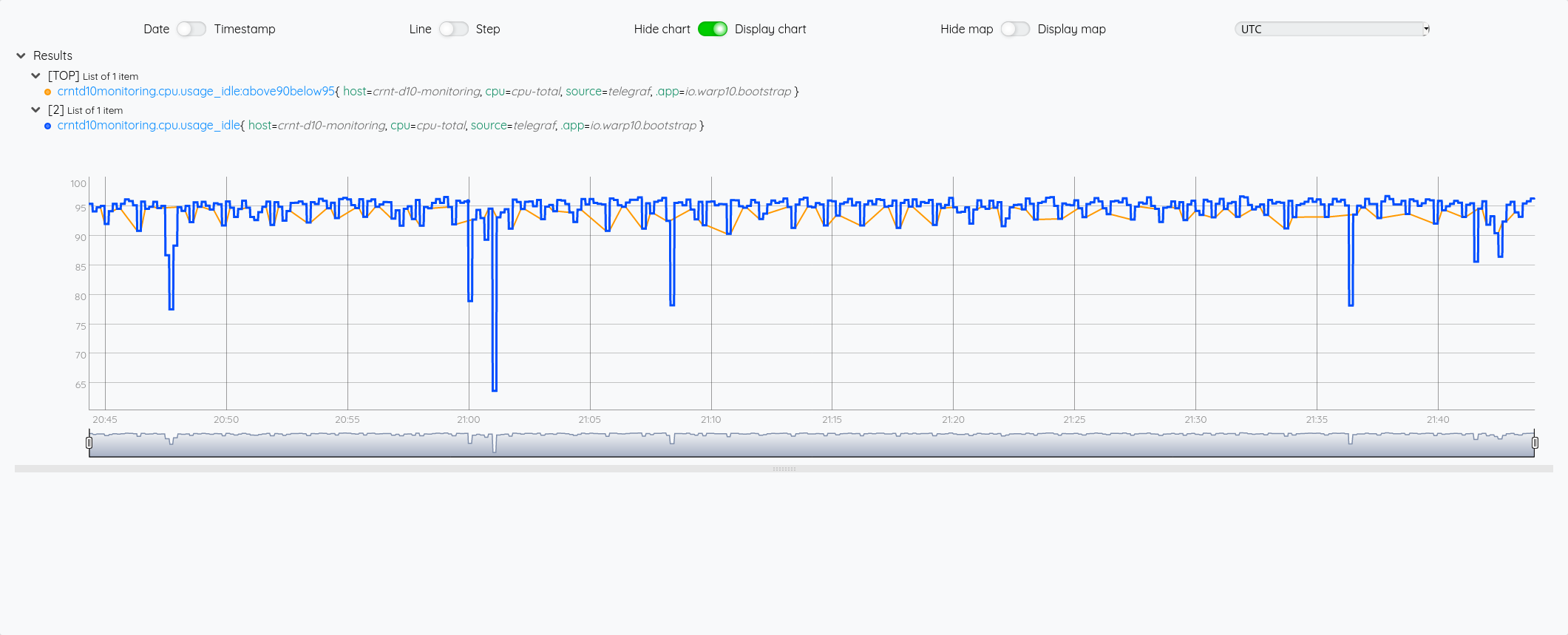
On voit ci-dessous l’usage de DUP avec la valeur humainement lisible, la valeur brute en seconde (puis le reste de la pile):

Si on ne veut pas de dataviz / ne pas conserver les valeurs intermédiaires et n’avoir que la valeur finale, on peut supprimer les lignes avec DUP et RENAME.
'<readToken>' 'readToken' STORE
[ $readToken '~crntd10monitoring.cpu.usage_idle' { 'cpu' 'cpu-total' } NOW 1 h ] FETCH
0 GET
'cpu' STORE
[
$cpu
bucketizer.last
0
1 s
0
]
BUCKETIZE
FILLPREVIOUS
FILLNEXT
[ SWAP 90.0 mapper.ge 0 0 0 ] MAP
[ SWAP 95.0 mapper.lt 0 0 0 ] MAP
0 GET SIZE
1 s *
HUMANDURATION
Et on obtient:
20m20.000000s
Un grand merci à Mathias Herberts pour sa disponiblité, sa patience et son aide face à toutes mes questions pour arriver à produire ce code.
Warp 10 / WarpScript - version agrégée
On peut aussi vouloir avoir une version agrégée de la donnée plutôt que de filter sur un état particulier. Ainsi, on peut avoir la répartition des valeurs que prend un équipement sur un indicateur donnée.
'<readToken>' 'readToken' STORE
// Récupération des métriques comme précédemment
[ $readToken '~crntd10monitoring.cpu.usage_idle' { 'cpu' 'cpu-total' } NOW 1 h ] FETCH
0 GET
'cpu' STORE
// Reformatage des données comme précédemment
[
$cpu
bucketizer.last
0
1 s
0
]
BUCKETIZE
FILLPREVIOUS
FILLNEXT
// Utilisation de QUANTIZE
// QUANTIZE a besoin que l'on définisse des sous-ensembles dans un ensemble
// Notre indicateur CPU étant un pourcentage, on prend par ex 10 sous ensemble compris entre 0 et 100
// QUANTIZE gère aussi les cas où l'on est plus petit que la première valeur et plus grand que la derinère valeur de l'ensemble
0 100 10 LBOUNDS
// On a donc 10+2 = 12 sous-ensembles : ]-infini,0],[1, 10],[11, 20],...,[90, 100],[101, inf+[
// Pour chaque valeur que nous allons passer à QUANTIZE, elle va retourer une valeur associée au sous ensemble dans laquelle la valeur va "tomber".
// Ainsi, un valeur de 95% va aller dans gt90.
// Liste des valeurs pour les 12 sous-ensembles :
[ 'neg' 'gt0' 'gt10' 'gt20' 'gt30' 'gt40' 'gt50' 'gt60' 'gt70' 'gt80' 'gt90' 'gt100' ]
QUANTIZE
// A ce stade, notre GTS de départ ne contient plus les valeurs de cpu mais les valeurs associées au tableau de QUANTIZE
// on passe donc de [<timestamp>, 95.45] à [<timestamp>, 'gt90']
// Utilisation de VALUEHISTOGRAM qui va compter le nombre d'occurences de chaque valeur d'une liste de GTS
VALUEHISTOGRAM
On obtient alors :
[{"gt90":3491,"gt80":40,"gt70":40,"gt60":10}]
Et voilà !
