Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Web, Ops, Data et Time Series - Juin 2021
grafana postgresql terraform vector warp10 quasardb influxdb k6 telegraf warpstudio consul chronograf traefik lensAutomatisation
- Announcing HashiCorp Terraform 1.0 General Availability : Terraform 1.0 est (enfin) GA.
- Announcing Consul 1.10 GA : des améliorations surtout sur la partie “Service Mesh” aka Consul Connect, ainsi que coté UI.
Conteneurs et orchestration
- Lens 5 Released - Release Notes : le “Kubernetes IDE” passe en version 5 avec diverses améliorations dont notamment du collaboratif avec du partage de contexte kubernetes.
- Traefik 2.5, quoi de neuf ? : actuellement en RC2, la version 2.5.0 de Traefik devrait apporter un support expérimental d’HTTP/3, le support des plugins privés, la mise à jour des CRD Kubernetes et les métriques par routeur (désactivé par défaut)
Monitoring & Observabilité
- Grafana 8.0: Unified Grafana and Prometheus alerts, live streaming, new visualizations, and more! : Grafana dans sa version 8.0 avec son lots d’amélioration.
- GrafanaCONline 2021: Your guide to the newest announcements from Grafana Labs : Résumé de la 1ère journée de GrafanaCon avec Grafan 8, Tempo 1.0, etc.
- What’s new in Grafana v8.0 : une version plus détaillée des apports de la version 8.0 de Grafana
- Vector v0.14.0 Release Notes : Vector permet maintenant d’exécuter des scripts externes via la source
exec. - Release Announcement: Telegraf 1.19.0 : version incrémentale avec son lot d’améliorations et de corrections.
- Grafana Labs Brings Modern Open Source Load Testing to Observability with Acquisition of k6 : Grafana Labs étend son offre d’observabilité avec l’acquisition de k6, un outil de test de charge et de performance.
Postgresql
- PostgreSQL as a Microservice : on pense souvent qu’une base de données permet la persistence des données. Ce n’est pas le principal enjeu d’une base de données mais la gestion de la concurrence.
Time Series
- Release Announcement: InfluxDB OSS 2.0.7 : version de maintenance avec des correctifs et la mise à jour de Flux.
- Release Announcement: Chronograf 1.9.0 : Version 1.9 de Chronograf, l’outil de dasboard et exploration des données d’InfluxData pour InfluxDB 1.x et 2.x. Cette version apporte un meilleur support de Flux (template variable, etc), le support au niveau UI du support TickScript & Flux de Kapacitor 1.6 (release à venir), un mode HA et pleins d’autres améliorations. Une version qui peut être utile dans le cadre d’une migration progressive d’InfluxDB 1.x vers 2.x
- influxdata/influxdb-stack-manager : pour gérer plus efficacement vos “stacks” InfluxdB (dashboard, tasks, etc). Requiert la cli influx.
- TSFR Edition #11 - Récapitulatif InfluxDays EMEA 2021 : Edition un peu particulière du meetup - n’ayant pas pu l’organiser dans les temps mais l’ayant préparé, voici sous forme vidéo le résumé des annonces produits d’InfluxData dans le cadre des InfluxDays EMEA 2021.
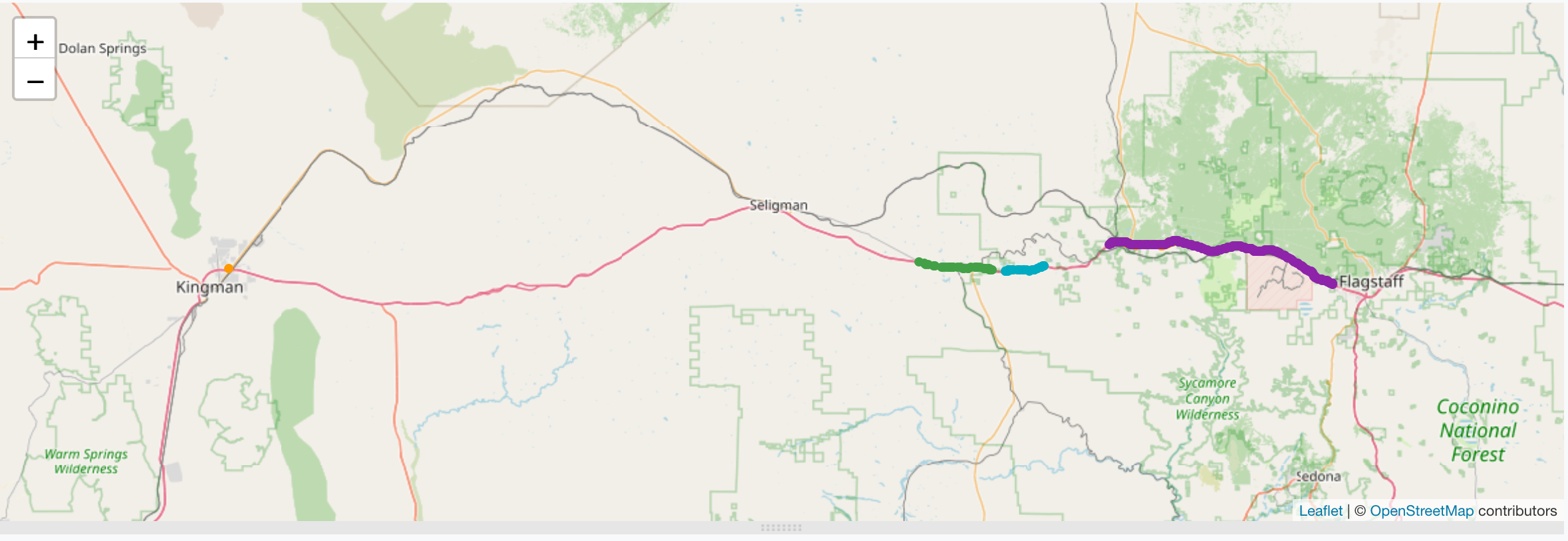
- TSFR Edition #12 - Le Bateau Qui Vole - Exploiter des données de navigation pour remporter les courses au large : un retour pragmatique et assez complet sur la mise en place d’un process de collecte / traitement / analyse des données d’un trimaran et des problématiques rencontrées.
- Interacting with Git repositories from Warp 10 : dans le cadre de la version 2.8 de Warp 10, des nouvelles capacités autour de l’interaction avec des dépots git sont disponibles. L’article présente des interactions de base mais j’ai encore du mal à voir les cas d’usage auxquels cela semble vouloire répondre.
- Protecting your Macros and Functions with Capabilities : Avec Warp 10 2.8, il est désormais possible de définir des “capacités” et de contrôler plus finement les actions des utilisateurs au travers de ces capacités.
- WarpStudio v2: What’s new in our Web IDE? : nouvelle version du WarpStudio de SenX, l’IDE Web prévue pour Warp 10 : support de FLoWS, documentation intégrée, intégration git, support de Disocvery (Dashboard as code), snippets, etc.
- Ma comptabilité, une série temporelle comme les autres - partie 5 - Les FEC et le compte 512 : si vous l’avez raté, nouvelle partie sur la comptaiblité, une série temporelle comme les autres avec cette fois-ci l’ingestion des fichiers d’écritures comptables (FEC) et l’analyse du compte 512 (banque)
- Don’t write your own persistence layer: why we chose RocksDB : retour d’exéprience de QuasarDB sur le choix de la couche de persistence entre batir sa propre solution (spoiler : mauvaise isée), utiliser LevelDB (comme Warp 10) ou faire le choix de RocksDB.
- Meet Kats — a one-stop shop for time series analysis - facebookresearch/Kats - Kats - One stop shop for time series analysis in Python : Facebook vient de sortir une librairie en python qui veut fournir un “tout en un” de la manipulation de séries temporelles. On y retrouve notamment Prophet pur la partie prédiction.
Ma comptabilité, une série temporelle comme les autres - partie 5 - Les FEC et le compte 512
warp10 timeseries comptabilité trésorerie banque fecSuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512 (ce billet)
- Partie 6 - Les FEC et le compte de résultat
Dans ce cinquième billet, nous allons parler de Fichier d’Ecritures Comptables (FEC) et d’un compte simple à analyser : le compte 512 qui correspond à votre compte en banque.
Le Fichier des Ecritures Comptables (FEC)
Le Fichier des Ecritures Comptables (FEC) est un format de fichier normalisé. Sa spécification est disponible et grosso modo, ce qu’il faut en savoir à ce stade :
- C’est un fichier TSV (un CSV avec les champs séparés par des tabulations)
- Il contient 18 champs permettant de décrire les différentes écritures comptables :
- JournalCode
- JournalLib
- EcritureNum
- EcritureDate
- CompteNum
- CompteLib
- CompAuxNum
- CompAuxLib
- PieceRef
- PieceDate
- EcritureLib
- Debit
- Credit
- EcritureLet
- DateLet
- ValidDate
- Montantdevise
- Idevise
En partant de ces informations et après quelques précisions fournies par mon expert-comptable Fabrice Heuvrard sur le fichier, nous avons convenu de commencer par l’analyse du compte 512 correspondant aux opérations bancaires. Facile à calculer (somme des crédits - somme des débits) et facile à vérifier, il me suffit de regarder mon compte en banque et/ou mon bilan en fin d’année.
Continuant à utiliser Warp 10 pour y stocker mes séries temporelles, j’ai réalisé un script en Go qui prend le fichier FEC en entrée et envoie les données dans Warp 10 avec le formalisme suivant : <société>.<bilan ou resultat>.<classe de compte>.<type d'opération: credit ou debit> :
<société>est juste le début de l’arborescence<bilan ou résultat>: le Plan Comptable Général Francais défini que si les comptes de classe 1 à 5 sont des classes de bilan et les classes 6 et 7 sont des classes de compte de résultat. Je suis donc le même principe de séparation des comptes et défiinr la valeurbilanetresultat. Le compte 512 que nous allons étudier commençant par 5, c’est un compte de bilan. Il sera donc dans la sériecerenit.bilan.*<classe de compte>: le plan comptable général est normalisé sur ces trois premiers chiffres. Les trois suivants sont à la discrétion du comptable. Du coup, pour ne pas avoir une série par code comptable, je retrouve par classe du plan de compte. Ainsi, toutes les opérations ayant le code512xxxse retrouvera dans la sériecerenit.bilan.512.*<type d'opération: crédit ou débit> : suivant si l’opération est un débit ou crédit, cela prend la valeur adéquat. Ainsi, toutes les opérations ayant le code512xxxse retrouvera dans la sériecerenit.bilan.512.creditou ``cerenit.bilan.512.debit`- Le montant de l’écriture comptable sera la valeur associée à mon point dans la série.
- Les autres informations seront mises sous la forme de labels (ie meta données de mon point) pour d’éventuelles analyses ultérieures. Il s’agit de couple clé/valeurs.
Ainsi, un crédit de 100€ avec une référence de pièce à 1234 sera représenté sous la forme :
<Timestamp de l'écriture comptable>// cerenit.bilan.512.credit{PieceRef=1234} 100
La modélisation est peut être un peu naive à ce stade, il sera toujours temps de la faire évoluer dans un second temps mais a priori :
- J’ai ma séparation bilan / compte de résultat
- J’ai ma séparation par classe de compte
- J"ai ma séparation débit / crédit
- au pire via les labels, j’ai des axes complémentaires de recherche / sélection.
Contrôle des données
Avant de commencer la moindre analyse, j’ai voulu vérifier l’intégrité de mes données.
"<readToken>" "readToken" STORE
// Récupération des données de 2020 pour le compte 512
[ $readToken 'cerenit.bilan.512.credit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
// Fusion de l'ensemble des séries temporelles en une seule série
MERGE
// Calcul de la somme de l'ensemle des valeurs de la séries -
// MAXLONG permet de tout récupérer sans calculer la taille exacte de la liste (pour peu que votre liste soit plus petite que la valeur de MAXLONG)
// 1 permet de ne sortir qu'une valeur en sortie
[ SWAP mapper.sum MAXLONG MAXLONG 1 ] MAP
// C'est une liste avec une liste à 1 élément, on "applatit" tout ça
MERGE
VALUES
0 GET
// On stocke la valeur finale dans totalCredit
'totalCredit' STORE
// Même opération sur les débits
[ $readToken 'cerenit.bilan.512.debit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
[ SWAP mapper.sum MAXLONG MAXLONG 1 ] MAP
MERGE
VALUES
0 GET
'totalDebit' STORE
// Calcul du solde
$totalCredit $totalDebit -
Cela me donne : 27746.830000000075
Exploration de la trésorerie
"<readToken>" "readToken" STORE
// Récupération des données de 2020 pour le compte 512
[ $readToken 'cerenit.bilan.512.credit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
// Fusion de l'ensemble des séries temporelles en une seule série
MERGE
// Tri des points par date
SORT
// Renommage de la série
'credit' RENAME
// Suppression des labels
{ NULL NULL } RELABEL
// Stockage dans une variable
'credit' STORE
// Même opération sur les débits
[ $readToken 'cerenit.bilan.512.debit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
SORT
'debit' RENAME
{ NULL NULL } RELABEL
'debit' STORE
// Affichage des deux séries
$credit
$debit
// Création de la série de mouvements
$credit $debit -
'mouvements' RENAME
Cela nous donne ces courbes:
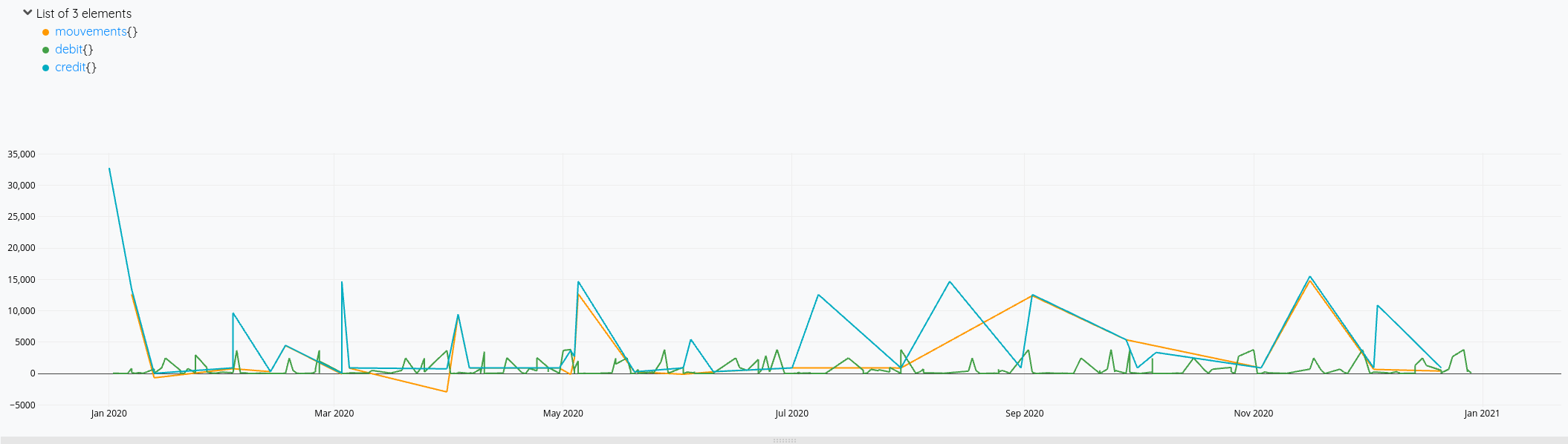
Mais on voit bien à fin décembre qu’il y a des opérations de débit qui ne sont pas prises en compte dans le solde (la ligne orange s’arrête avant la verte).
En cherchant un peu, je me dis qu’il faudrait que je calcule une nouvelle série avec tous les éléments de crédit et débit et faire l’addition de tout cela. Je vois également que FLATTEN (doc)permet de fusionner plusieurs listes en une seule. Mais finalement, seul MERGE sera nécessaire.
Cela me donne la piste suivante :
"<readToken>" "readToken" STORE
// Récupération des données de 2020 pour le compte 512
[ $readToken 'cerenit.bilan.512.credit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
SORT
'credit' RENAME
{ NULL NULL } RELABEL
'credit' STORE
// Même opération sur les débits
[ $readToken 'cerenit.bilan.512.debit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
SORT
'debit' RENAME
{ NULL NULL } RELABEL
// Je multiplie les debits par -1 pour pouvoir faire l'opération de solde ensuite
[ SWAP -1 mapper.mul 0 0 0 ] MAP
'debit' STORE
// Je fusionne les deux séries avec MERGE
[
$credit
$debit
] MERGE
// Je trie les éléments par date
SORT
'mouvements' RENAME
Cette fois-ci, mon solde prend bien en compte toutes les opérations de l’année.
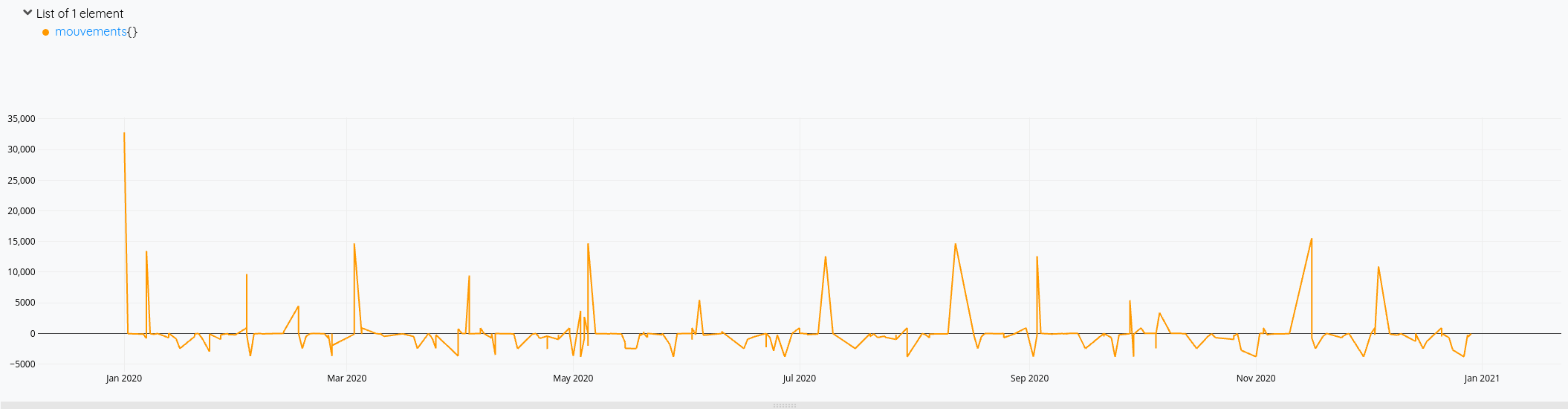
Pour la version consolidée avec le solde du compte :
// Récupération des données de 2020 pour le compte 512
[ $readToken 'cerenit.bilan.512.credit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
SORT
'credit' RENAME
{ NULL NULL } RELABEL
'credit' STORE
// Récupération des données de 2020 pour le compte 512
[ $readToken 'cerenit.bilan.512.debit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
SORT
'debit' RENAME
{ NULL NULL } RELABEL
-1 *
'debit' STORE
// Fusion des débits/crédits comme vu précédemment
[
$credit
$debit
] MERGE
SORT
'mouvements' RENAME
// On applique mapper.sum sur l'ensemble des points précédents le point qui est considéré
// Le premier point ne va donc prendre que lui même
// Le 2nd point va prendre sa valeur et ajouter celle du précédédent
// Le 3ème point va prendre sa valeur et la somme des points précédents
// Et ainsi de quiste
[ SWAP mapper.sum MAXLONG 0 0 ] MAP
Et le résultat en images :
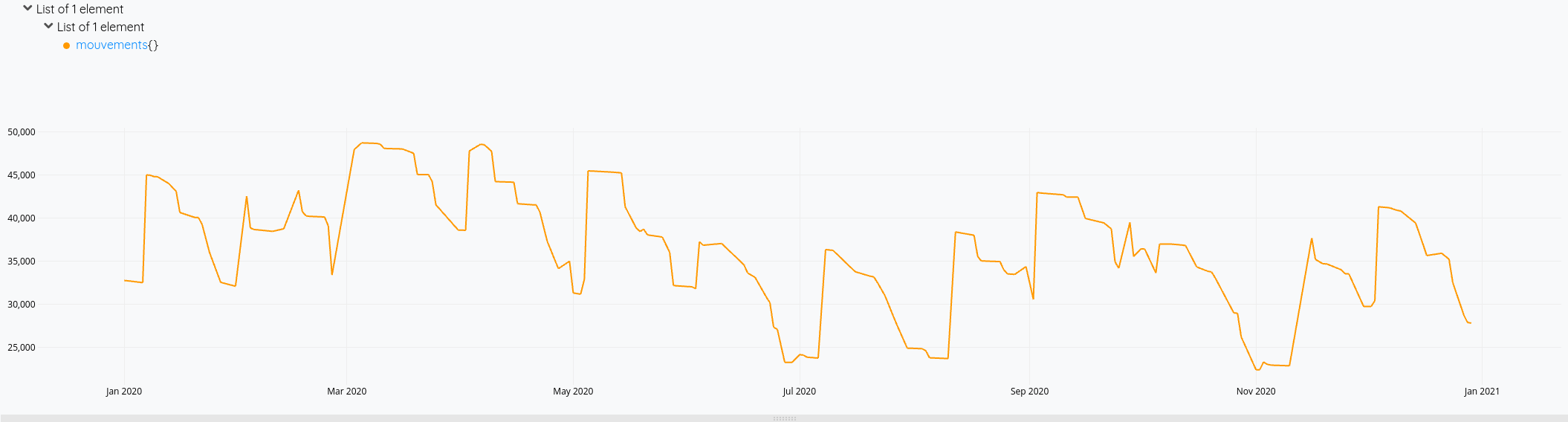
Et voilà !
Il ne me reste plus qu’à :
- ingérer les FEC des autres années pour envisager des comparaisons entre les différents exercices comptables, voire du prédictif pour l’exercice en cours et à venir,
- étendre ces analyses à d’autres comptes maintenant,
- et à créer les dashboards adéquats avec Discovery.
Web, Ops, Data et Time Series - Mai 2021
hashicorp nomad ovh time leap second gitlab-ci python dbt metabase datatask warp10 monitoring wasm sécurité spectre timescale sql cli readme bootstrap influxdata kapacitor chronografCI
- GitLab CI Python Library : une librairie en python pour créer des pipelines Gitlab-CI plutôt qu’en YAML.
Cloud
Conteneur et orchestration
- Announcing General Availability of HashiCorp Nomad 1.1 : 10 nouvelles fonctionnalités au programme (7 en OSS, 3 en entreprise) : surallocation de mémoire (soft et hard limit), les CPU peuvent être réservés en tant que tel (et non plus uniquement via une fraction), amélioration d’UI, amélioration coté support CSI, distinction entre les “readyness checks” et “liveness checks” au niveau des health checks, exécution distante sur AWS Lambda et AWS ECS (tech preview). Pour la version entreprise : supper des namespaces consul, chargement automatique des licences lors du déploiement de nouveaux noeuds, amélioration de l’autoscaling.
Data
- Hosting SQLite databases on Github Pages : avec une petite pointe de WASM, exemple de pouvoir utiliser une base sqlite en lecture hébergé en statique et un peu de javascript. Intéressant pour mettre à disposition des applications en “lecture seule” et leur scalabilité.
- DataTask pour construire une self-service BI, Revue des principaux concepts de dbt et création d’un premier modèle dans DataTask, DBT : Workflows, Matérialisations et Documentation, Metabase : Les concepts de question, visualisation et dashboard, DBT et la gouvernance des données : tests de validité/qualité et documentation : S&rie de billets sur la mise en place d’une solution de BI avec dbt et Metabase et l’intégration au sein de la plateforme DataTask
- xo/usql (via MACI #42) : une CLI universelle pour des bases SQL comme MySQL, Postgres, SQLite mais aussi des solutions SaaS comme Snowflake, Spanner et même SAP Hana.
Docs
- readme.so (via MACI #42) : Vous ne savez pas quoi mettre dans votre README ? Ce site est fait pour vous et peut aussi vous aider à réorganiser vos fichiers.
Europe
- Souveraineté et cloud, quel rapport ? : remise en perspective du cloud souverain et implications des décisions européenes. La remise en cause du Privacy Shield et les clauses contractuelles font qu’au final : “tout transfert de données personnelles sous juridiction américaine est illégal.”. La reglementation européene, centré sur le respect des droits des personnes permettrait de fiare un protectionnisme reglementaire dans l’idée de développer un écosystème numérique européen et conforme aux valeurs européennes. A lire et méditer !
License
- Third Party Dependencies that have been Relicensed to AGPL : la position de la CNCF sur les projets passant sous licence AGPL et leur éventuelle intégration dans des projets CNCF. Plutôt mal parti…
Système
- negative leap second news! : une seconde est intercallée de temps à autre pour se resynchroniser avec la rotation terrestre. En général, on ajoutait une seconde. Là, on va retirer une seconde - c’est apparemment la première fois que cela se passe.
Sécurité
- Defenseless: UVA Engineering Computer Scientists Discover Vulnerability Affecting Computers Globally : Vous pensiez en avoir fini avec SPECTRE ? Les correctifs arrivaient assez tard dans la chaine de traitement, des chercheurs ont réussi à intervenir avant pour récupérer des informations. Publications à compter du mois de juin.
- Everything Old is New Again: Binary Security of WebAssembly : si certains pensaient être sauvés par WebAssembley, c’est raté. La VM WebAssembly peut avoir ses propres failles d’une part et d’autre part, un code source vulnérable en WebAssembly présenterait les mêmes failles une fois compilé.
Time Series
- $40 million to help developers measure everything that matters : Timescale annonce une levée en série B de 40 Millions de dollars - environ 2 millions d’instances actives et une dizaine de sorties produits pour le mois de Mai.
- How we made DISTINCT queries up to 8000x faster on PostgreSQL : dans le cadre de la sortie de TimescaleDB 2.2.1, l’arrivée de “Skip Scan” permet d’accélérer les
SELECT DISTINCTentre 28x et 8000x. Cela est valable tant pour les données Timescale que les données natives Postgres. Une contribution upstream est prévue. - TimescaleDB 2.3: Improving columnar compression for time-series on PostgreSQL : Après le rajout des ALTER/RENAME des colonnes compressées en 2.1 - le rajout des INSERT avec une compression en deux temps (compression de l’insert en lui même puis recompaction des données au niveau du chunk)
- QuestDB 6.0 : implémentation de la gestion du Out Of Order, amélioration sur le InfluxDB Inline Protocol ainsi que sur l’UI et la couche SQL.
- How we achieved write speeds of 1.4 million rows per second : retour plus détaillé sur la gestion du Out Of Order dans QuestDB.
- InfluxDB OSS and Enterprise Roadmap Update from InfluxDays EMEA : InfluxData juge qu’à partir de la version 2.0.6, la mise à jour depuis une version 1.8 est stable. La version 1.8 sera donc maintenue jusqu’à la fin d’année. Au-delà de cette date, les correctifs ajoutés seront dans la branche master mais il n’y aura plus de packaging de la version 1.8 OSS. Seule la version 1.8 Entreprise aura de nouveaux binaires. Abandon des binaires en 32 bits pour InfluxDB 2.x. Concernant la version Entreprise, InfluxDB 1.9 va apporter des améliorations notamment concernant le support de Flux. Par ailleurs Chronograf 1.9 et Kapacitor 1.6 vont sortir en juin avec diverses améliorations. Ces deux produits seront compatibles avec InfluxDB 2.x pour aider à la montée de version vers InfluxDB 2.x. Enfin, InfluxDB 0SS 2.1 va sortir aussi en juin avec notamment l’ajout des notebooks, les annotations sur les dashboards et des améliorations de Flux.
- Release Announcement: InfluxDB OSS and InfluxDB Enterprise 1.8.6 : version de maintenance avec une faille de sécurité pour la version Entreprise.
- Monitorer son infra avec Warp 10 - Partie 1, Partie 2, Partie 3 : Mise en oeuvre des outils de la plateforme Warp 10 pour monitorer son infrastructure. Cela couvre l’installation, la collecte des métriques, l’exploration des données et calcul des premiers métriques, et pour finir la création des dashboards.
- Mon Linky dans Warp 10 avec un joli dashboard : Ingestion des données issues du Linky dans Warp 10 et présentation de ces données dans un Dashboard Discovery.
- May 2021: Warp 10 releases 2.8.0 and 2.8.1 - SenX : En résumé (liste non exhaustive, va falloir qqs billets plus détaillés pour comprendre toutes les nouveautés) : Gestion plus fine des “capabilities” au niveau des tokens, Utilisation de FLoWS simplifié, Intégration avec la blockchain Ethereum, Des fonctions de crypto / signature / …, Des améliorations sur la manipulation de JSON, Une fonction HTTP pour permettre des appels distants, Ajout de mapper.geo.fence pour voir si un point est dans/en dehors d’une zone, Des choses autours des MACRO et plein d’autres améliorations/corrections.
- Working with GEOSHAPEs: code contest results : le corrigé du concours lancé par SenX autour des GEOSHAPEs dans Warp 10. Concours que j’ai remporté et voici mes réponses : partie 1 & partie 2
- Wikipedia / Warp 10 : Warp 10 dispose de sa page Wikipedia
- « Le bateau qui vole » : l’analytique en temps réel au service d’un skipper : de l’utilité des séries temporelles dans le monde de la course au large pour une meilleure appréhension du fonctionnement du bateau et de ses performances. Ce retour d’expérience sera le thème d’une prochaine édition du Time Series France !
Web
- Bootstrap 5 : nouvelle version majeure du framework Boostrap avec la suppression de la dépendance à JQuery et la fin de support de plein de vieux navigateurs notamment.
Ma solution pour le Warp 10 Code Contest - partie 2
timeseries warp10 geospatial challengeSuite et fin de ma réponse au code contest après la première partie. Dans ce billet, nous allons voir comment calculer les émissions de CO2 pour la partie de trajet sur la route 66.
// Define points from the car journey on the US66 road
[
// Here is the gts of the car datalogger
@senx/dataset/route66_vehicle_gts
// Here is the route 66 geoshape (+/- 20meters)
@senx/dataset/route66_geoshape
mapper.geo.within 0 0 0
] MAP
"onTheRoad" STORE
$onTheRoad
{
'timesplit' 60 s
}
MOTIONSPLIT
0 GET
'sectionOnTheRoad' STORE
// Compute speed - result in m/s
[ $sectionOnTheRoad mapper.hspeed 1 0 0 ] MAP
// Convert in km/h so x3600 /1000 = 3.6 - mapper.mul expects a constant
[ SWAP 3.6 mapper.mul 0 0 0 ] MAP
'speedFrames' STORE
// Get distance between each points in km (first in meters, then in km)
[ $sectionOnTheRoad mapper.hdist 0 1 0 ] MAP
[ SWAP 0.001 mapper.mul 0 0 0 ] MAP
'distFrames' STORE
// fuel consumption approximation is (8 liters/100km) × (speed (km/h) / 80) +1
// So it's Speed * 8 / 80 / 100 + 1 = V/10 + 1
// F = False => does not return the index
$speedFrames
<%
0.1 *
1.0 +
%> F LMAP
'hundredKmFuelConsumption' STORE
[ ] 'instantConsumption' STORE
<%
'i' STORE // store index
// Get each list and compute one by another
// So we compute consumption for 100 km at given speed (computed previously)
// with related distance
// then we divide by 100 as first value is for 100 km
$distFrames $i GET
$hundredKmFuelConsumption $i GET
*
100 /
'r' STORE
$instantConsumption $r +!
%>
'C' STORE
0 7 $C FOR
CLEAR
// For each GTS, compute fuel consumption as 1 point
[
$instantConsumption
mapper.sum
MAXLONG
MAXLONG
1
] MAP
// Sum all points to get total consumption
0 SWAP <% VALUES 0 GET + %> FOREACH
// 1L = 2392g CO2
2392 *
// Enjoy !
Le premier et le second bloc sont les mêmes que dans la premièr partie. Je vous y renvoie donc si besoin.
A ce stade, nous avons une liste de 8 séries correspondant à chaque section passée sur la route 66. Chaque série comporte un liste de timestamps et de points géospatiaux (lattitude, longitude, élévation).
Concernant le troisième bloc :
- il s’agit de calculer la vitesse en m/s entre chaque point de la série (ce qui explique le
1 0 0pour prendre le point précédent, aucun point suivant et appliquer cette opération sur l’ensemble de la liste - voir la tips 3 de 12 tips to apply sliding window algorithms like an expert). Pour cela, on utilisemapper.hspeed(doc) qui consomme une série et calcule la vitesse en m/s en tenant compte de la longitude/lattitude/élévation. - Ce résultat, on le convertit en km/h dans la foulée en utilisant
mapper.mul(doc) en notant au passage qu’il lui faut une constante (on ne peut pas mettre3600 * 1000 /mais3.6) - On a donc une liste de 8 séries temporelles avec chacune un timestamp, les données géospatiales et une vitesse entre chaque point. C’est stocké dans la variable
speedFrames.
Concernant le 4ème bloc :
- Sur le même modèle que pour la vitesse, on calcul la distance entre chaque point des 8 séries via
mapper.hdistque l’on a vu dans le premier billet. Cette fois-ci, plutôt que de calculer la distance totale, on la distance entre le point et le point suivant et on le fait pout tout les points de la liste, d’où le0 1 0 - La distance étant en mètres, on la divisie par 1000 pour avoir des kilomètres. Mais comme il n’y a pas de mapper de division, alors on utilise
mapper.mulet la valeur0.001 - On a donc une liste de 8 séries temporelles avec chacune un timestamp, les données géospatiales et une distance entre chaque point. C’est stocké dans la variable
distanceFrames.
Concernant le 5ème bloc :
- j’ai voulu calculer la consommation d’essence sur la base de la formule:
(8 liters/100km) × (speed (km/h) / 80) +1
- Cela se simplifie en
Speed/10 + 1. - Si on multiplie ce coefficient par les vitesses entre deux points obtenues précédemment (dans
speedFrames), on obtient une consommation pour 100km avec chaque vitesse. Il faudra dans un second temps le pondérer par la distance parcourue entre deux points (distanceFrames) pour avoir un instantané de consommation pour la vitesse et la distance parcourue. - Pour faire cette consommation au 100km non pondérée, on utilise
LMAP(doc)pour appliquer une MACRO à chaque élément de la liste. Cette macro contient le coefficient de consommation d’essence.LMAPretourne normalement l’index et la valeur associée. Or l’index ne nous sert à rien, on met donc l’argument concernant l’index àFalse(abrégéF) pour qu’il ne soit pas retourné. - On stocke le résultat dans
hundredKmFuelConsumptionet on a donc une liste de 8 series avec la consommation pour 100km à la vitesse donnée. Il nous faut maintenant pondérée cette liste par la distance pour avoir un instantané de consommation.
Concernant le 6ème bloc :
- On commence par créer une liste vide appelée
instantConsumption. - On sait que l’on a une liste de 8 éléments, donc on peut faire un boucle
FOR(doc) dessus avec un indice allant de 0 à 7.FORprend comme dernier argument une MACRO que j’ai nomméC - Dans la MACRO définie au dessus, je commence par stocker l’index de la boucle. Mes deux listes de 8 séries temporelles sont identiques en terme de points, avec l’une contenant les consommations pour 100km
hundredKmFuelConsumptionet la seconde les distances entre chaque pointdistFrames. L’idée est donc de multiplier chaque série dehundredKmFuelConsumptionpar la série équivalente dansdistFrameset de diviser par 100 pour finir notre proportionnalité. - On stocke cet consommation instantanée dans la variable
r. - On ajoute ce résultat
rdans la listeinstantConsumption, ce qui permet de reconstituer notre liste de 8 séries mais ayant pour valeur cette fois ci les instantanés de consommation entre chaque point de chaque série.
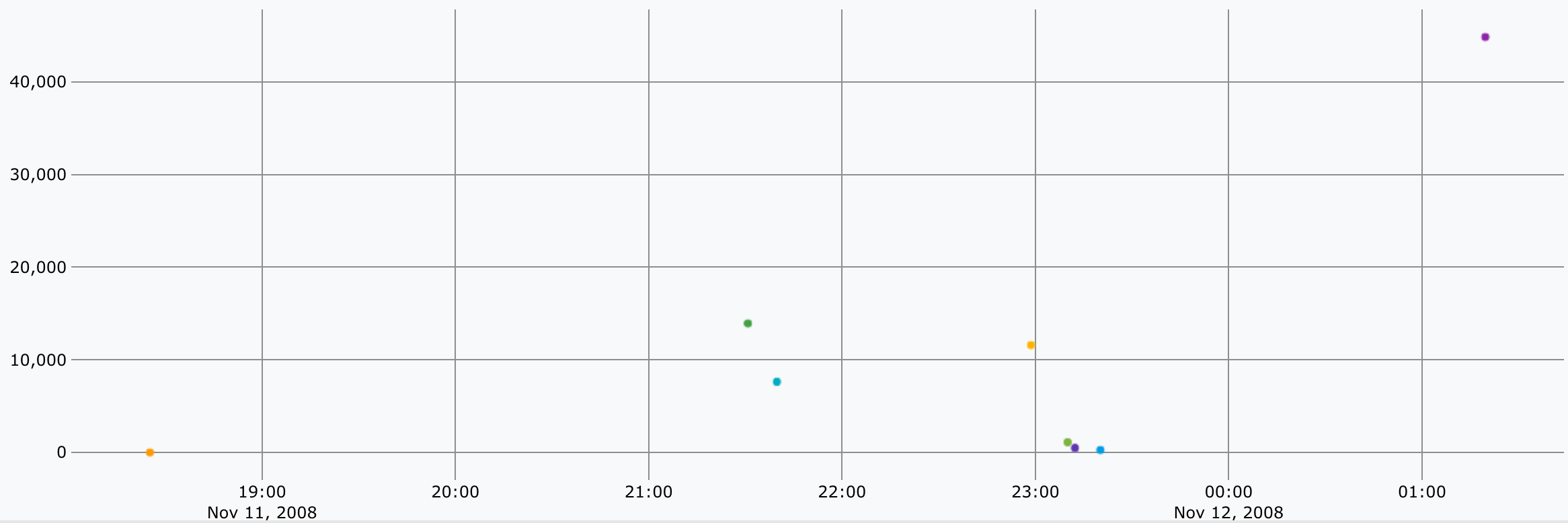
Un petit interlude visuel avant le dernier bloc :
Concernant le 7ème bloc :
- Le but est de faire la somme de chaque instantanné de consommation pour avoir la consommation totale.
- Comme dans la première partie, on utilise cette fois-ci
mapper.sum(doc) en prenant l’ensemble des données des listes capturées viaMAXLONGet on récupère1seule valeur qui s’avère être le total. On a donc la consommation totale de chaque série - Comme vu aussi en fin de première partie, on fait alors la somme de chaque liste pour avoir la consommation totale (
9.823366576601234) - On sait que 1L = 2392g CO2, il nous reste donc à faire cette multiplication.
- On obtient alors :
23497.492851230152ou23,497kg de CO2.
J’espère avoir été clair dans ces explications - si ce n’est pas le cas - dites le moi (via Twitter, Mail, LinkedIn, etc) et je préciserai les choses.
Bilan personnel de ce code contest :
- Opportunité de découvrir une partie des fonctionnalités géospatiales de Warp 10 que je n’avais pas encore utilisé
- Améliorer mon usage autour de
MAP, lesmapper, lesMACROetLMAPet plein de petites choses ici ou là. MAPs’applique sur des GTS mais aussi des listes de GTS sans rien avoir à faire. Pas besoin de se rajouter des boucles supplémentaires !MAXLONGutilisé dans lesMAPpermet de ne pas avoir à se soucier de la taille de l’élément sur laquelle on appliqueMAP. Cela ne fait pas non plus une erreur du styleindex out of range.- en bonus, obtenir quelques lots sympathiques 😎


J’espère néanmoins apprendre des choses du corrigé officiel : Working with GEOSHAPEs: code contest results.
Ma solution pour le Warp 10 Code Contest - partie 1
timeseries warp10 geospatial challengeLa société SenX a proposé un code contest suite à la publication de son article sur les formes géospatiales. L’objet du concours porte sur le trajet d’un véhicule aux USA et il consiste à déterminer :
- la distance réalisée sur la fameuse route 66 durant ce trajet,
- de déterminer les émissions de CO2 réalisées durant ce trajet sur la route 66.
Maintenant que le gagnant a été annoncé (TL;DR: moi 😎🎉) et en attendant le corrigé officiel, voici ma proposition de solution.
Distance parcourue sur la route 66
Les données de départ sont :
@senx/dataset/route66_vehicle_gts: le trajet réalisé par le véhicule@senx/dataset/route66_geoshape: la route 66
// Define points from the car journey on the US66 road
[
// Here is the gts of the car datalogger
@senx/dataset/route66_vehicle_gts
// Here is the route 66 geoshape (+/- 20meters)
@senx/dataset/route66_geoshape
mapper.geo.within 0 0 0
] MAP
"onTheRoad" STORE
$onTheRoad
{
'timesplit' 60 s
}
MOTIONSPLIT
0 GET
'sectionOnTheRoad' STORE
// Compute distance for each GTS and output it as a single point
[ $sectionOnTheRoad mapper.hdist MAXLONG MAXLONG 1 ] MAP
// Sum all GTS
0 SWAP <% VALUES 0 GET + %> FOREACH
// Convert to km
1000 /
// Enjoy !
Explications :
- Le premier bloc utilise le mapper
mapper.geo.within(doc). Ce mapper compare deux zones géographiques et ne retient que les poits qui sont dans la zone voulue. Ici, je prends donc tous les points du trajet et les compare avec ceux de la route 66. Seuls les points sur la route 66 sont conservés. Le résultat est une aggrégation de points que l’on stocke dans la variableonTheRoad. - Pour le second bloc : dans le studio, lorsque l’on regarde la liste des points obtenus dans l’onglet “Tabular view”, on peut voir que les points sont espacés en général de minimum 10 secondes et jusqu’à une minute environ. Après avoir relu le billet “Use motion to automatically split GTS”, j’ai retenu ce seuil d’une minute et la fonction
MOTIONSPLIT(doc) pour calculer la distance entre deux points. Obtenant une liste de 1 élément contenant une liste, j’ai rajouté le0 GETpour supprimer la liste parente. On obtient alors une liste de 8 séries temporelles (GTS) correspondant à chaque tronçon sur la route. On stocke cela dans la variablesectionOnTheRoad.
- Pour le dernier bloc - partie 1 :
mapper.hdist(doc) permet de calculer la distance totale sur une fenêtre glissante de points. L’utilisation deMAXLONGpermet d’avoir une valeur suffisamment grande pour notre cas d’espèce pour prendre l’ensemble des données de chacune des 8 listes - il n’est pas nécessaire de connaitre la taille exacte de la liste pour travailler dessus et cela ne crée pas d’erreur non plus ; ça peut déstabiliser !. Le1permet de n’avoir qu’une valeur en sortie. On a donc en sortie la distance de chacune des 8 sections.
- Pour le dernier bloc - partie 2 : là, j’avoue la syntaxe est un peu cryptique 🤯. L’idée est donc de faire la somme de toutes les distances totales obtenues précédemment. Il faut donc faire
0(pour initialiser l’opération d’addition) et ajouter la première valeur de la liste et ainsi de suite. Une fois qu’on a la somme, on divise par 1000 pour avoir des kilomètres - La réponse est alors:
79.82147744769853
Pour comprendre la partie 2, on peut réécrire la chose de la façon suivante :
[ $sectionOnTheRoad mapper.hdist MAXLONG MAXLONG 1 ] MAP
'totalDistancePerSection' STORE
0 $totalDistancePerSection <% VALUES 0 GET + %> FOREACH
Non, toujours pas ? Vous me rassurez, j’ai du creuser plus loin aussi.
Commençons par :
$totalDistancePerSection <% VALUES 0 GET %> FOREACH
VALUES (doc) consomme une série temporelle et en sort les valeurs sous la forme d’une liste. Nous avons une liste initiale de 8 séries que nous avons ramené à 8 points. Avec FOREACH (doc), on applique donc la fonction VALUES sur chaque série contenant un seul point. Plutôt que d’avoir en sortie des listes à un seul point, le 0 GET permet d’avoir directement la valeur.
Pour faire une addition, en WarpScript, c’est :
1 1 +
ou :
1
1
+
Par celà, j’entends que pour appliquer +, il faut que les deux éléments soient définis dans la pile.
Notre boucle FOREACH emet dans la pile chaque valeur qu’il faut ajouter à la précédente. On peut donc rajouter le + dans la boucle FOREACH :
$totalDistancePerSection <% VALUES 0 GET + %> FOREACH
Mais si je cherche à exécuter cela, cela ne fonctionne pas - cela reviendrait à faire:
valeur1IssueDuForeach +
valeur2IssueDuForeach +
valeur3IssueDuForeach +
valeur4IssueDuForeach +
...
Si on part de la fin, la valeur 4 va pouvoir être additionnée à la valeur 3 car celle-ci existe dans la pile. MAIS la valeur 1 n’est additionnée à rien à ce stade et l’opération est invalide. D’où la nécessité de rajouter le 0 pour pouvoir avoir deux éléments pour notre première addition.
Ce qui nous donne bien :
0 $totalDistancePerSection <% VALUES 0 GET + %> FOREACH
Maintenant que la brume s’est éclaircie et que le 🤯 est passé à 😎 pour cette syntaxe de fin, je vous propose de nous retrouver dans un prochain billet pour la suite de ma solution au concours.
