Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Web, Ops, Data et Time Series - Novembre 2021
postgresql timeseries timecale warp10 warpstudio influxdbContainers & Orchestration
- Announcing General Availability of HashiCorp Nomad 1.2 : Arrivée des “system batchs jobs” prévu pour gérer des jobs à destination du cluster nomad en lui même (purge, backup, etc) et non des clients. Cette version apporte également des améliorations au niveau de l’interface, ainsi que les “nomad pack”, format de distribution de vos applications à destination de nomad.
IoT
- Sortie de Raspberry Pi OS Bullseye et Raspberry Pi 4 à 1,8GHz : Première version de Raspberry Pi OS basée sur Debian 11 et possible overclocking du CPU des RPi4 à 1.8 Ghz (au lieu de 1.5 Ghz)
Monitoring & Observabilité
- Vector v0.18.0 release notes : une version avec beaucoup de changements - je vous laisse aller voir les release notes.
Time Series
Annonces & Produits :
- Timescale 2.5.0 : support de Postgresql 14, continuous aggregates for distributed hypertables (la fonction fonctionne donc maintenant en multi-nodes) et support des timezone pour la fonction time_bucket_ng
- Warp Studio 2.0.6 : version mineure du studio pour la gesion de CORS-RFC1918 ; c’est pour utiliser le studio avec vos instances locales depuis Chrome 92 (et bientôt les autres navigateurs) du fait des restrictrions d’accès mises en place dans les navigateurs.
- Release Announcement: InfluxDB OSS 2.1.0 | InfluxData : Arrivée des annotations et des notebooks, le client influx n’est plus distribué avec le serveur (sauf dans l’image Docker), améliorations de flux, amélioration de l’API et de la CLI et mise à jour de l’extension VSCode.
- Announcing PyCaret’s New Time Series Module :la librairie “low code” de machine learning PyCaret se dote d’un module de gestion de séries temporelles comprenant 30+ modèles (ARIMA, SARIMA, FBProphet, etc) et fonctions.
Articles :
- Intelligence Artificielle et Data Quality : comment corriger des données historiques impactées par la Covid 19 pour améliorer la qualité des prévisions ? : RETEX sur les appels à un call center : comment prendre en compte (ou pas) les variations liées au confinement sur les appels à un call center. L’article présente quatre stratégies et leurs résultats.
- Data replication with Warp 10 : présentation du fonctionnement de datalog, le module de réplication des données dans Warp 10.
- n8n & Warp 10 - Automate your time series manipulations : la version anglaise hébergée sur le blog de Senx de mon billet sur n8n & Warp 10
Ma comptabilité, une série temporelle comme les autres - partie 6 - Les FEC et le compte de résultat
warp10 timeseries comptabilité résultat fec dashboard discoverySuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512
- Partie 6 - Les FEC et le compte de résultat (ce billet)
Dans ce sixième et dernier billet pour cette série, nous continuons avec les Fichier d’Ecritures Comptables (FEC) pour produire le compte de résultat et déterminer ainsi le bénéfice de l’exercice en cours. Il faut donc prendre toutes les opérations en classe 6 (charges) et 7 (produits). Pour chaque classe de compte, il peut y avoir des crédits ou des débits (ex pour un compte de classe 7 : un avoir sur une facture émise). C’est donc un chouilla plus compliqué que le compte de trésorerie.
Depuis le dernier billet, j’ai légèrement fait évoluer le modèle de données :
- Initialement, j’avais :
<société>.<bilan ou resultat>.<classe de compte>.<type d'opération: credit ou debit> - Cela a évolué vers :
<société>.<bilan ou resultat>.<classe de compte>; le type d’opération est maintenant un label
Pour un crédit de 100€ avec une référence de pièce à 1234 pour le compte 706, on passe donc de :
<Timestamp de l'écriture comptable>// cerenit.resultat.706.credit{PieceRef=1234} 100
à :
<Timestamp de l'écriture comptable>// cerenit.resultat.706{PieceRef=1234, operation=credit} 100
Compte de résultat
"<readToken>" "readToken" STORE
// Récupération de toutes les opérations de crédit pour les comptes charges (classe 6xx)
// Le SORT permet d'être sur d'avoir toutes les opérations triées par date
// Stockage du résultat dans une variable
[ $readToken '~comptabilite.resultat.6.*' { "operation" "credit" } '2020-01-01T00:00:00Z' '2020-12-31T23:59:59Z' ] FETCH
MERGE
SORT
'charges_credit' RENAME
'charges_credit' STORE
// Récupération de toutes les opérations de débit pour les comptes charges (classe 6xx)
// Le SORT permet d'être sur d'avoir toutes les opérations triées par date
// Stockage du résultat dans une variable
[ $readToken '~comptabilite.resultat.6.*' { "operation" "debit" } '2020-01-01T00:00:00Z' '2020-12-31T23:59:59Z' ] FETCH
MERGE
SORT
'charges_debit' RENAME
'charges_debit' STORE
// Fusion des deux listes de séries en une liste qui va avoir l'ensemble des opérations
// Les opérations de débit sont mis en valeur négative du calcul du solde
// Le SORT permet d'être sur d'avoir toutes les opérations triées par date
// Stockage du résultat dans une variable qui contient l'ensemble des opérations
[
$charges_debit -1 *
$charges_credit
] MERGE
SORT
'charges_flux' RENAME
'charges_flux' STORE
// Même opération pour les comptes de produit (7xx)
[ $readToken '~comptabilite.resultat.7.*' { "operation" "credit" } '2020-01-01T00:00:00Z' '2020-12-31T23:59:59Z' ] FETCH
MERGE
SORT
'produits_credit' RENAME
'produits_credit' STORE
[ $readToken '~comptabilite.resultat.7.*' { "operation" "debit" } '2020-01-01T00:00:00Z' '2020-12-31T23:59:59Z' ] FETCH
MERGE
SORT
'produits_debit' RENAME
'produits_debit' STORE
[
$produits_debit -1 *
$produits_credit
] MERGE
SORT
'produits_flux' RENAME
'produits_flux' STORE
// Fusion des 2 flux d'opérations (charges et produits) pour avoir une vision temporelle de ces opérations
// Le SORT permet d'être sur d'avoir toutes les opérations triées par date
// Renommage de la série en "compte_resultat" qu'elle va permettre de batir
// Somme cumulée de l'ensemble des opérations pour avoir un solde à date
// Stockage sous la forme d'une variable
// Affichage de la variable
[
$produits_flux
$charges_flux
] MERGE
SORT
'compte_resultat' RENAME
[ SWAP mapper.sum MAXLONG 0 0 ] MAP
'compte_resultat' STORE
$compte_resultat
Ce qui nous donne dans le Studio :
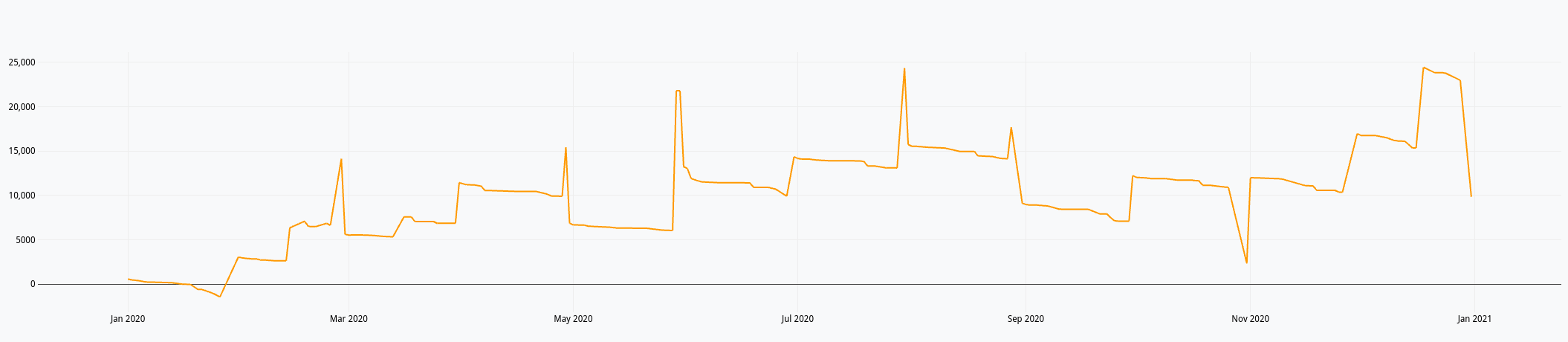
Du précédent billet et ce celui-ci, nous avons donc :
- Un compte de résultat annuel
- Un compte de trésorerie annuel
Tout ce qu’il faut donc pour faire un dashboard avec Discovery. Il faut dire que le billet Covid Tracker built with Warp 10 and Discovery et dans une moindre mesure Server monitoring with Warp 10 and Telegraf donnent accès à plein d’options pour réaliser ses dashboards.
Macros
Je pourrais mettre le code de mes requêtes directement dans les dashboards mais j’aime pas trop quand des tokens se balladent dans les pages web. Du coup, je vais déporter le code dans des macros. J’ai églément rendu les macro dynamiques dans le sens où elles prennent une année en paramètre pour afficher les données de l’année en question.
On a déjà vu le fonctionnement des macros précédemment, je ne reviendrais donc pas dessus.
La macro du compte de résultat à titre d’exemple :
<%
{
'name' 'cerenit/accountancy/compte-resultat'
'desc' 'Function to calculate the cumulative benefit (or loss) of the company'
'sig' [ [ [ [ 'year:LONG' ] ] [ 'result:GTS' ] ] ]
'params' {
'year' 'Year, YYYY'
'result' 'GTS'
}
'examples' [
<'
2020 @cerenit/accountancy/compte-resultat
'>
]
} INFO
// Actual code
SAVE 'context' STORE
TOLONG // When called from dashboard, it's a string - so convert paramter to LONG first
'year' STORE // Save parameter as year
// Compute 1st Jan of given year
[ $year 01 01 ] TSELEMENTS-> ISO8601
'start' STORE
// Compute 31 Dec of given year
[ $year 12 31 23 59 59 ] TSELEMENTS-> ISO8601
'end' STORE
"<readToken>" "readToken" STORE
[ $readToken '~comptabilite.resultat.6.*' { "operation" "credit" } $start $end ] FETCH
MERGE
SORT
'charges_credit' RENAME
'charges_credit' STORE
[ $readToken '~comptabilite.resultat.6.*' { "operation" "debit" } $start $end ] FETCH
MERGE
SORT
'charges_debit' RENAME
'charges_debit' STORE
[
$charges_debit -1 *
$charges_credit
] MERGE
SORT
{ NULL NULL } RELABEL
'charges_flux' RENAME
'charges_flux' STORE
[ $readToken '~comptabilite.resultat.7.*' { "operation" "credit" } $start $end ] FETCH
MERGE
SORT
'produits_credit' RENAME
'produits_credit' STORE
[ $readToken '~comptabilite.resultat.7.*' { "operation" "debit" } $start $end ] FETCH
MERGE
SORT
'produits_debit' RENAME
'produits_debit' STORE
[
$produits_debit -1 *
$produits_credit
] MERGE
SORT
{ NULL NULL } RELABEL
'produits_flux' RENAME
'produits_flux' STORE
[
$produits_flux
$charges_flux
] MERGE
SORT
'compte_resultat' RENAME
[ SWAP mapper.sum MAXLONG 0 0 ] MAP
'compte_resultat' STORE
$compte_resultat
$context RESTORE
%>
'macro' STORE
$macro
Comme le décrit l’exemple, si on veut le compte de résultat de l’année 2020, on utilisera le code suivant :
2020 @cerenit/accountancy/compte-resultat
J’ai profité de ce billet pour utiliser Warpfleet Synchronizer & Warpfleet Resolver pour simplifier le déploiement des macros ; cela explique que les signatures pour appeler les macros changent par la suite dans le dashboard.
Dashboards
Ci-après le code du dashboard :
<%
{
'title' 'Comptabilité CérénIT'
'description' 'Trésorerie et compte de résultat'
'vars' {
'myYear' 2020
}
'tiles' [
{
'title' 'Informations'
'type' 'display'
'w' 11 'h' 1 'x' 0 'y' 0
'data' {
'data' 'Résultat de la série <a href="https://www.cerenit.fr/blog/premiers-pas-avec-warp10-comptabilite-et-previsions/">Ma comptabilité, une série temporelle comme les autres</a> et de l'ingestion des Fichiers d'écritures comptables.'
'globalParams' { 'timeMode' 'custom' }
}
}
{
'title' 'Année'
'type' 'input:list'
'w' 1 'h' 1 'x' 11 'y' 0
'data' {
'data' [ '2017' '2018' '2019' '2020' ]
'events' [ { 'type' 'variable' 'tags' 'year' 'selector' 'myYear' } ]
'globalParams' { 'input' { 'value' '2020' } }
}
}
{
'title' 'Trésorerie (annuel)'
'type' 'line'
'w' 6 'h' 2 'x' 0 'y' 1
'macro' <% $myYear @cerenit/macros/treso %>
'options' { 'eventHandler' 'type=(variable),tag=year' }
}
{
'title' 'Compte de résultat (annuel)'
'type' 'line'
'w' 6 'h' 2 'x' 6 'y' 1
'macro' <% $myYear @cerenit/macros/compteresultat %>
'options' { 'eventHandler' 'type=(variable),tag=year' }
}
{
'title' 'Trésorerie (pluri-annuelle)'
'type' 'line'
'w' 12 'h' 2 'x' 0 'y' 3
'macro' <% [ 2017 $myYear ] @cerenit/macros/treso_multi %>
'options' { 'eventHandler' 'type=(variable),tag=year' }
}
]
}
{ 'url' 'https://w.ts.cerenit.fr/api/v0/exec' }
@senx/discovery2/render
%>
et son rendu :
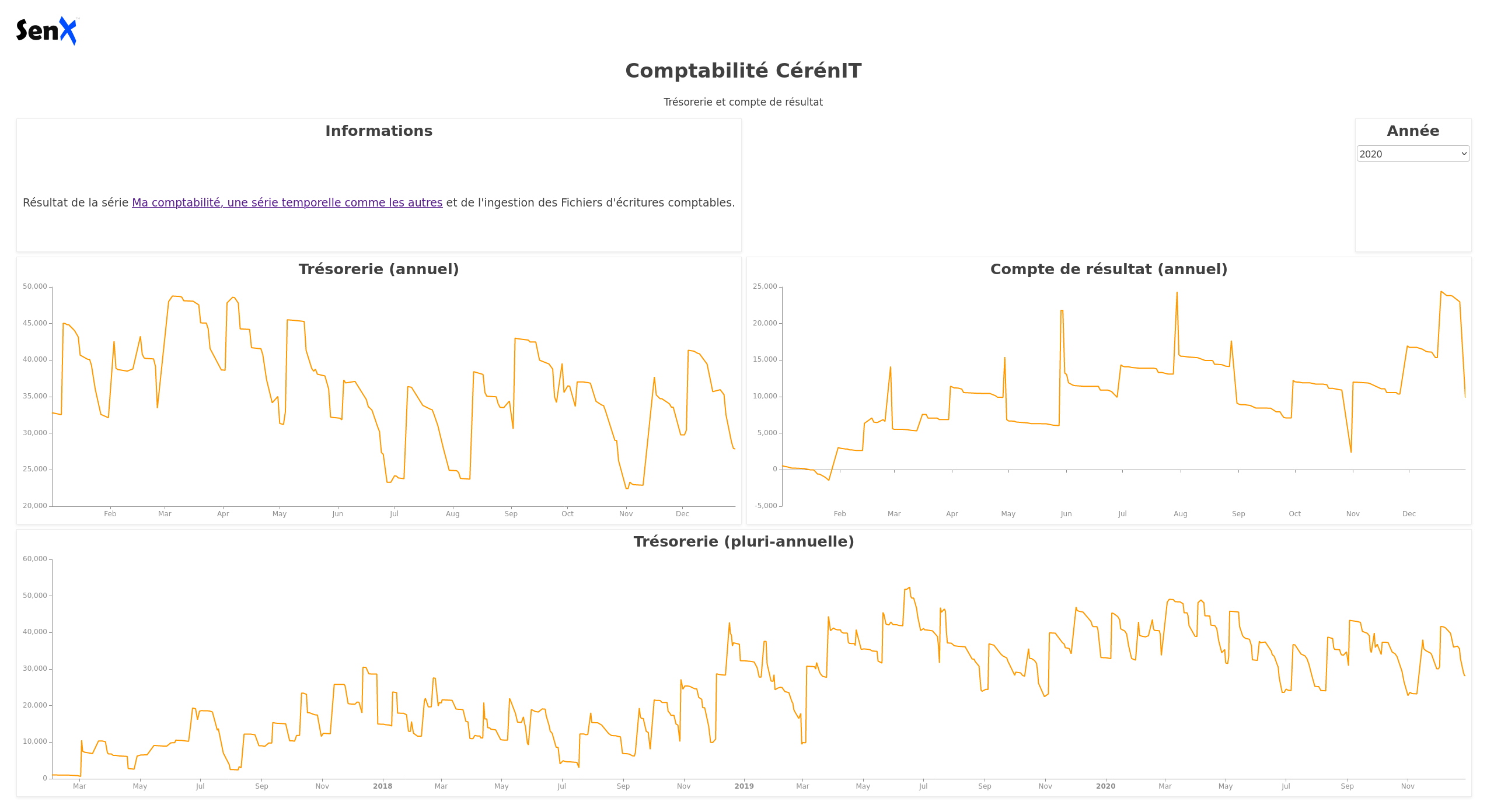
Dans le bloc global du dashboard, on définir une variable myYear, initialisée à 2020. Cette variable est mise à jour dynamiquement lorsque l’on choisit une valeur dans la liste déroulante du bloc “Année”.
<%
{
'title' 'Comptabilité CérénIT'
'description' 'Trésorerie et compte de résultat'
'vars' {
'myYear' 2020
}
...
Le bloc Année justement :
{
'title' 'Année'
'type' 'input:list'
'w' 1 'h' 1 'x' 11 'y' 0
'data' {
'data' [ '2017' '2018' '2019' '2020' ]
'events' [ { 'type' 'variable' 'tags' 'year' 'selector' 'myYear' } ]
'globalParams' { 'input' { 'value' '2020' } }
}
}
C’est une liste déroulante (type: input:list) avec pour valeurs les années 2017 à 2020. Par défaut, elle est initialisée à 2020. Via le mécanisme des “events”, lorsqu’une valeur est choisie, celle-ci est émise sous la forme d’une variable, nommée myYear et ayant pour tag la valeur year.
Ainsi, si je sélectionne 2017 dans la liste, la variable myYear prendra cette valeur. Maintenant que la valeur est définie suite à mon choix et émise vers le reste du dashboard, il faut que les autres tiles récupèrent l’information.
Regardons le tile Trésorerie :
{
'title' 'Trésorerie (annuel)'
'type' 'line'
'w' 6 'h' 2 'x' 0 'y' 1
'macro' <% $myYear @cerenit/macros/treso %>
'options' { 'eventHandler' 'type=(variable),tag=year' }
}
La récupération de la variable se fait via la proriété options et la récupération de l’eventHandler associé et défini précédemment.
Une fois récupérée, la variable myYear peut être utilisée dans le bloc macro et le tile est mis à jour dynamiquement.
En conséquence :
- Les deux premiers tiles afficheront le solde de trésorerie et le compte de résultat de l’année sélectionnée
- Le dernier tile affichera la trésorerie depuis début 2017 jusqu’à la fin d’année sélectionnée. Donc au minimum 2017 et au maximum 2017 > 2020.
Ainsi s’achève cette série sur les données comptable et les séries temporelles. Des analyses complémentaires pourraient être menées (analyse de stocks, réparition d’activité, etc) mais mes données comptables sont insuffisantes pour en valoir l’intérêt. J’espère néanmoins que cela aura sucité votre intérêt et ouvert des horizons.
Cette série fut aussi l’occasion de faire un tour de la solution Warp 10 et de voir :
- l’ingestion de données,
- la manipulation et l’analyse des données,
- la mise en place de dashboards,
- la projection de données avec les algorythmes de machine learning.
Si vous souhaitez poursuivre l’aventure et le sujet, n’hésitez pas à me contacter.
Web, Ops, Data et Time Series - Octobre 2021
postgresql timeseries bi datatask dbt metabase singer timescale influxdb quasardb vector nomad clever-cloud yield pivot warp10 flows vscode kapacitor chronograf telegraf clickhouseBI
- Smart Data Analytics : Exploration des données comptables : pour changer des outils de séries temporelles, je me suis livré au même exercice d’ingestion et de traitement des FEC avec la Smart Data Analytics (SDA) de DataTask. Basée sur singer, dbt et metabase, la SDA permet via une Web UI de définir son flow d’ingestion et de transformation. Une fois ces transformations réalisées, il ne reste plus qu’à explorer les données avec Metabase et produire ses dashboards.
Code
- vscode.dev : l’ère de l’IDE dans le navigateur continue après gitpod ou githuab codspaces, c’est au tour de vscode.dev qui permet d’avoir une IDE dans son navigateur. Affaire à suivre…
Observabilité et monitoring
- Vector 0.17.0, Vector 0.17.1, Vector 0.17.2 & Vector 0.17.3 avec l’adaptive concurrency qui permet de gérer le “back pressure” pour les destinations accessibles via HTTP, et pour les sources une gestion simplifiée pour le décodage d’éléments et leur “framing”.
- Vector Remap Language : extension Vector pour VSCode
Orchestration & conteneurs
- damon, un dashboard pour nomad en ligne de commande.
- Announcing HashiCorp Nomad 1.2 Beta : ajout des “System Batch” qui sont des (petits) jobs globaux au cluster, des améliorations de l’interface et l’ajout des Nomad Pack, une sorte de catalogue d’applications prêtes à être déployées dans votre cluster.
SQL
- PostgreSQL 14 Released! ou en français PostgreSQL 14 ou un thread twitter pour découvrir les nouveautés de cette version : amélioration du support de JSONB, type multirange, fonctions autour des dates, etc.
Sécurité
- Popular NPM library hijacked to install password-stealers, miners : analyse de la librairie ua-parser-js compromise dans ses version 0.7.29, 0.8.0 et 1.0.0 avec l’ajout un mining de crypto et un voleur de mot de passes. Le passage en version 0.7.30 / 0.8.1 et 1.0.1 est à faire dans les plus brefs délais. Pour les dépendances indirectes, il est possible d’ajouter dans son fichier
package.json:"resolutions": { "ua-parser-js": "^0.7.30" }via Security issue: compromised npm packages of ua-parser-js (0.7.29, 0.8.0, 1.0.0) - Questions about deprecated npm package ua-parser-js
Time Series
Annonces & Produits :
- InfluxDB OSS 2.0.9
- InfluxDB OSS 1.8.10
- InfluxDB Entreprise 1.9.5 - avec des fixes sur l’utilisation mémoire et les index TSI :sourire_narquois:
- Telegraf 1.20.2 (avec un fix de memory leak sur le parser influx notamment)
- Kapacitor 1.6.2
- QuasarDB 3.10.0 Stable Released : Nouvelle version de la base QuasarDB avec son lot d’améliorations et de corrections ; pour une présentation de QuasarDB, voir Time Series France - Edition 2 - QuasarDB, les séries temporelles appliquées à la finance & aux transports.
- Announcing the new Timescale Cloud, and a new vision for the future of database services in the cloud et le thread twitter associé : Timescale partage sa vision de ce que doit être une base managée et de la developer experience qu’elle doit offrir. Timescale indique également avoir 3 millions de bases actives par mois (très loin devant les derniers chiffres d’InfluxData ; environ 6 fois mais faut-il encore s’accorder ce qu’est une base: une instance ? un schema ?). Timescale annonce les principes de Timescale Cloud (ex Timescale Forge) qui veut être simple, scalable, connu et flexible. Les deux premiers sont inspirés du monde serverless (découplage compute/storage, auto scalabilité, etc) et les deux derniers du monde de la base de données managiées (du SQL plutôt qu’une API et le fait de bénéficier de tout l’écosystème associé). 10 annonces sont prévues durant le mois d’octobre, quelques-une sont déjà en fin de billet.
- Announcing Time Series on Clever Cloud, with TARDIS, Clever Cloud lance son offre Time Series as a Service, basée sur Warp 10 et avec une compatiblité InfluxQL, PromQL, etc.
- FLoWS ♡ VS Code WarpScript extension 2.0.0 - SenX : nouvelle version de l’extension Warp 10 pour VSCode avec le support de FLoWS et Discovery.
- October 2021: Warp 10 release 2.9.0 : nouvelles capacités (CAPABILITY) autour de fetch & exec, GUARD doit éviter les fuites de données sensibles, ajout support de KML/GML en plus des habituels ajouts de fonctions, améliorations de fonctions et divers corrections de bugs
Articles & Vidéos :
- How NOT to Analyze Time Series : article sympathique sur les erreurs de jeunesse d’analyse de séries temporelles.
- Penser le monde en time series, la nouvelle solution à vos problèmes d’analyse (M.Herberts/Q.Adam) : conférence à DevoxxFR de Quentin et Mathias pour une introduction aux séries temporelles. Intéressant même si un peu au lance pierre sur la fin.
- Les TSDB ne sont pas toujours la bonne solution : approche db ou plateforme ? approche table ou séries ? faible ou forte profondeur d’analyse ? Revue de quelques critères pouvant impacter la façon dont vous manipulez vos séries temporelles.
- TL;DR InfluxDB Tech Tips: Multiple Aggregations with yield() in Flux :
yield()peut être très pratique pour débugguer son code flux mais permet aussi de récupérer le résultat de plusieurs requêtes pour faire des aggrégations - How to Pivot Your Data in Flux: Working with Columnar Data : InfluxDB, contrairement à une RDBMS, stocke ses valeurs via une approche colonne, qui peut dérouter dans un premier temps. Le billet montre comment utiliser
pivot()pour revenir à des manipulations en ligne. - Function pipelines: Building functional programming into PostgreSQL using custom operators : quand un Query Langage (ici SQL) ne suffit plus pour manipuler les séries temporelles, arrivent les fonctions et les opérateurs.
- What is ClickHouse, how does it compare to PostgreSQL and TimescaleDB, and how does it perform for time-series data? : un benchmark très complet pour se faire une opinion et même si ClickHouse n’est pas une TSDB.
Pour le retour sur les InfluxDays North America qui ont lieu cette semaine, ce sera pour un prochain billet ou édition du Time Series France Meetup
n8n & Warp 10 - Automatisez vos manipulations de séries temporelles
n8n automation warp10 timeseries workflowIl y a quelques temps et sachant que j’utilisais n8n pour automatiser la génération des brèves du BigData Hebdo, Mathias m’a demandé s’il était possible de faire la même chose entre n8n et Warp 10 qu’avec node-red et Warp 10.
La réponse est oui mais voyons comment faire cela.
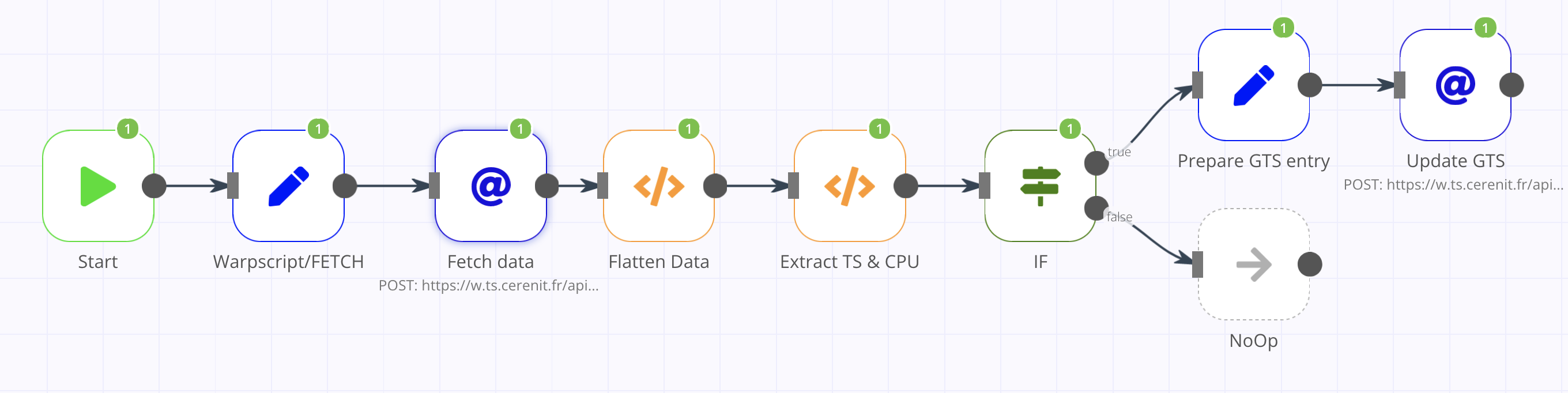
Pour ceux qui ne connaissent pas n8n, c’est un clone open source (sous licence fair-code) à des services comme Zapier ou IFTTT. Il permet d’automatiser des processus via la création de workflows. Ces workflows sont composés d’étapes et d’actions. n8n dispose d’un grand nombre de connecteurs vers les différents services existants, des opérateurs génériques (faire un appel http, appliquer une fonction), des opérateurs logiques (si, etc), des opérateurs de transformation de données, etc. Chacun de ces éléments est implémenté via une node. A chaque étape du workflow, une node est instanciée puis paramétrée. Les nodes peuvent être reliées entre-elles et la sortie d’une node peut alimenter la suivante.
Le workflow se veut basique et va être le suivant :
- Récupération d’une entrée de monitoring CPU dans Warp 10
- Si la valeur est supérieure ou égale à 90%, alors création d’une entrée dans une série dédiée à cet effet.
Ce n’est pas le workflow le plus passionnant du monde, mais cela permet de faire deux appels à l’API HTTP de Warp 10 :
- Le premier permet de tester l’exécution de code WarpScript via l’API
/api/v0/exec; vu le code, j’aurais pu passer par/api/V0/fetchmais cela me permet de tester l’exécution de code WarpScript. - Le second utilisera l’API
/api/v0/updatepour insérer une donnée dans une série. Cela permet de tester le passage du token d’authentification via un header.
Pour commencer le workflow, la donnée de départ est la valeur en pourcentage du métrique “CPU Idle” d’un de mes serveurs.
En WarpScript, cela donne:
'<readToken>' 'readToken' STORE
[ $readToken 'crnt-ovh.cpu.usage_idle' { "host" "crnt-d10-gitlab" "cpu" "cpu-total" } NOW -1 ] FETCH
Et la réponse :
[
[{
"c": "crnt-ovh.cpu.usage_idle",
"l": {
"host": "crnt-d10-gitlab",
"cpu": "cpu-total",
"source": "telegraf",
".app": "io.warp10.bootstrap"
},
"a": {},
"la": 0,
"v": [
[1634505650000000, 91.675025]
]
}]
]
n8n dispose d’une node HTTP Request, qui comme son nom l’indique permet de faire des requêtes HTTP vers un serveur distant. Toutefois, il n’est pas possible de passer notre code WarpScript directement dans l’appel HTTP. Il faut créer un objet avec le code WarpScript et passer ensuite l’objet créé et le nom de la propriété contenant le code WarpScript à la node HTTP Request.
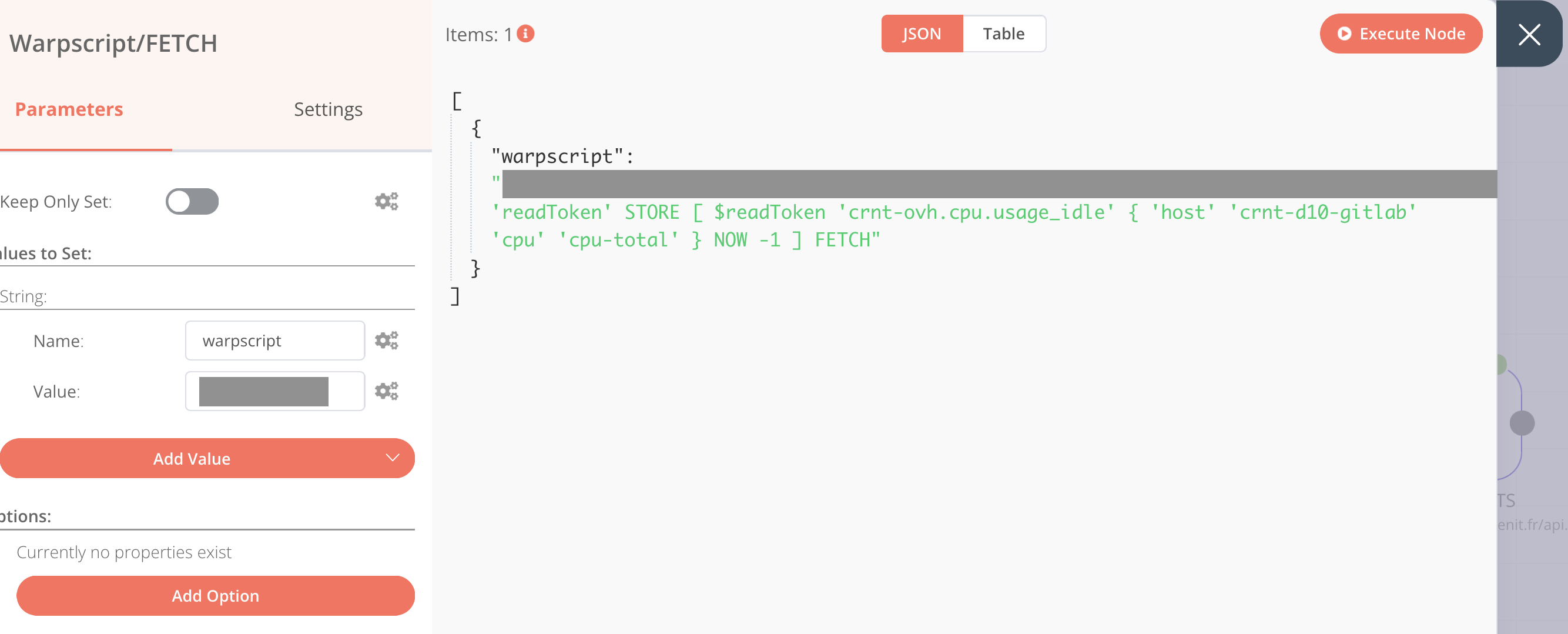
Pour stocker le code WarpScript dans un objet, il faut utiliser la node Set. Une fois la node Set ajoutée dans le workflow, aller dans Parameters > Add Value > Type: String
Saisir:
- Name: warpscript
- Value: le code WarpScript ci-dessus
En cliquant sur “Execute Node”, on peut valider la variable (la partie grisée étant mon token) :
On peut maintenant ajouter une node HTTP Request dans le workflow et la relier à la node Set nouvellement créée. Ainsi, la node HTTP Request aura directement accès au résultat de la node Set.
Pour les ajustements à faire :
- Parameters :
- Request Method : POST
- URL :
http://url.de.votre.instance.warp.10/api/v0/exec - Activer la case JSON/RAW Parameters
- Options :
- Add Option > Mime Type : text/plain
- Add Option > Body Content Type : RAW/Custom
- Body Parameters > Add Expression > Current Node > Input Data > JSON > warpscript (les colonnes de droites doivent se remplir avec la clé en haut et la valeur en dessous ; cliquer sur la croix pour revenir à l’écran précédent)
En cliquant sur “Execute Node”, le résultat de la requête est visible (la partie grisée étant un bout de mon token) :
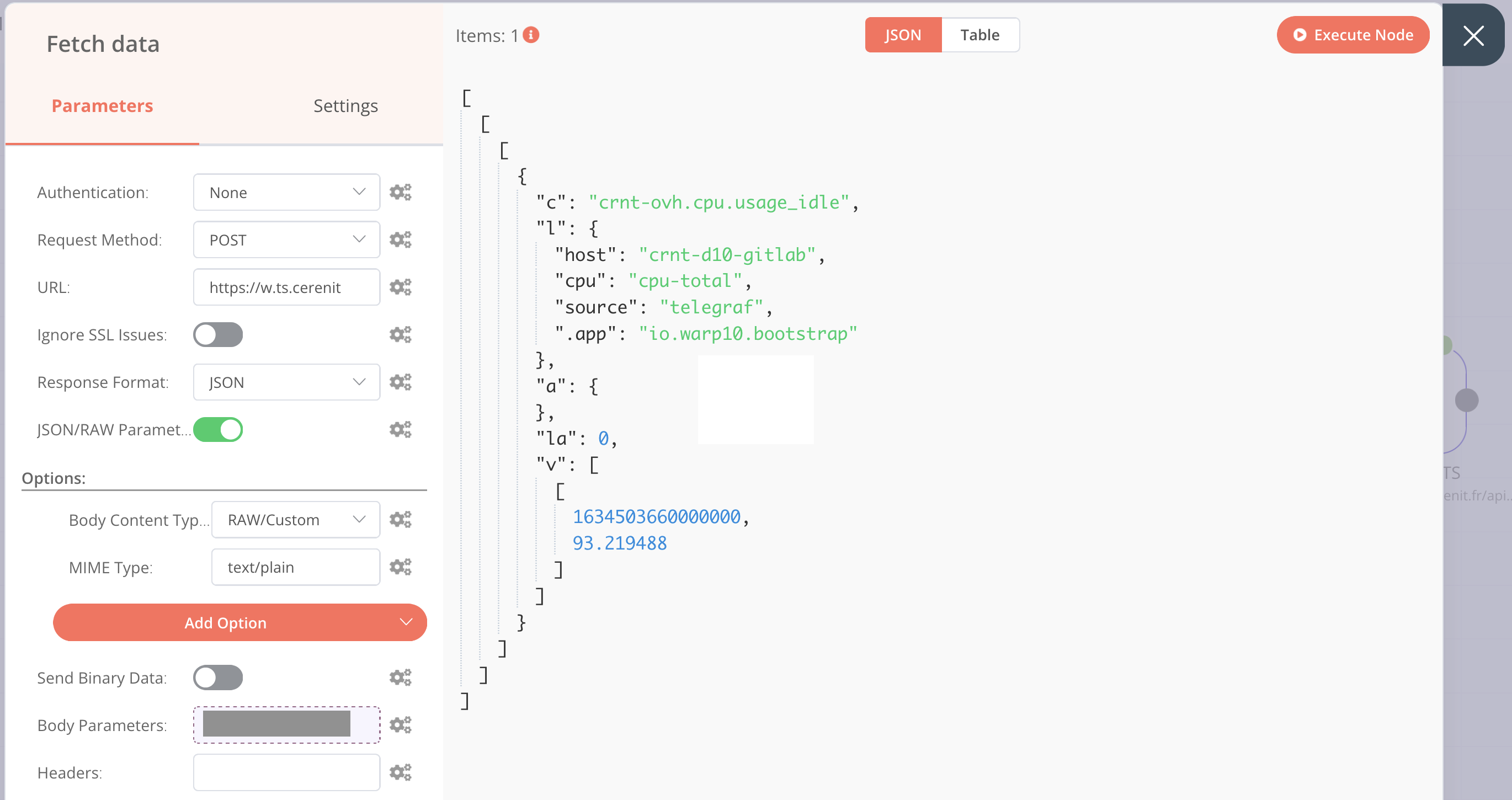
On retrouve notre objet JSON mais il est imbriqué dans des Array Javascript, on va applanir tout ça et extraire le timestamp et la valeur du cpu via l’ajout de deux nodes Function que l’on relie à la node HTTP Request. La node Function permet d’exécuter du code javascript sur les données et de réaliser des transformations que l’on ne peut pas forcément faire avec les autres nodes. Cela n’étant pas le coeur du sujet, cela ne sera pas détaillé.
A l’issue des deux exécutions, les données sont réduites à ce qui suit :
[{
"ts": 1634503660000000,
"cpu": 93.219488
}]
La node IF ne sera pas détaillée non plus ; elle sert juste à introduire un semblant de logique dans le workflow. En l’occurence, si la valeur de “cpu” >= 90, alors le test est considéré comme vrai et faux sinon. Dans le cas où c’est faux, une node noOp a été ajoutée pour matérialiser la fin du workflow.
Dans le cas où le test est vrai (valeur de “cpu” >= 90), on veut alors insérer le timestamp et la valeur dans une autre série sur une instance Warp 10. Comme précédemment, cela va se faire en deux fois:
- Préparation de la donnée au format GTS Input Format et mise à disposition sous la forme d’une propriété
- Exécution de l’appel HTTP.
On ajoute une node Set, ensuite dans Parameters > Add Value > Type: String
Saisir:
- Name: gtsinput
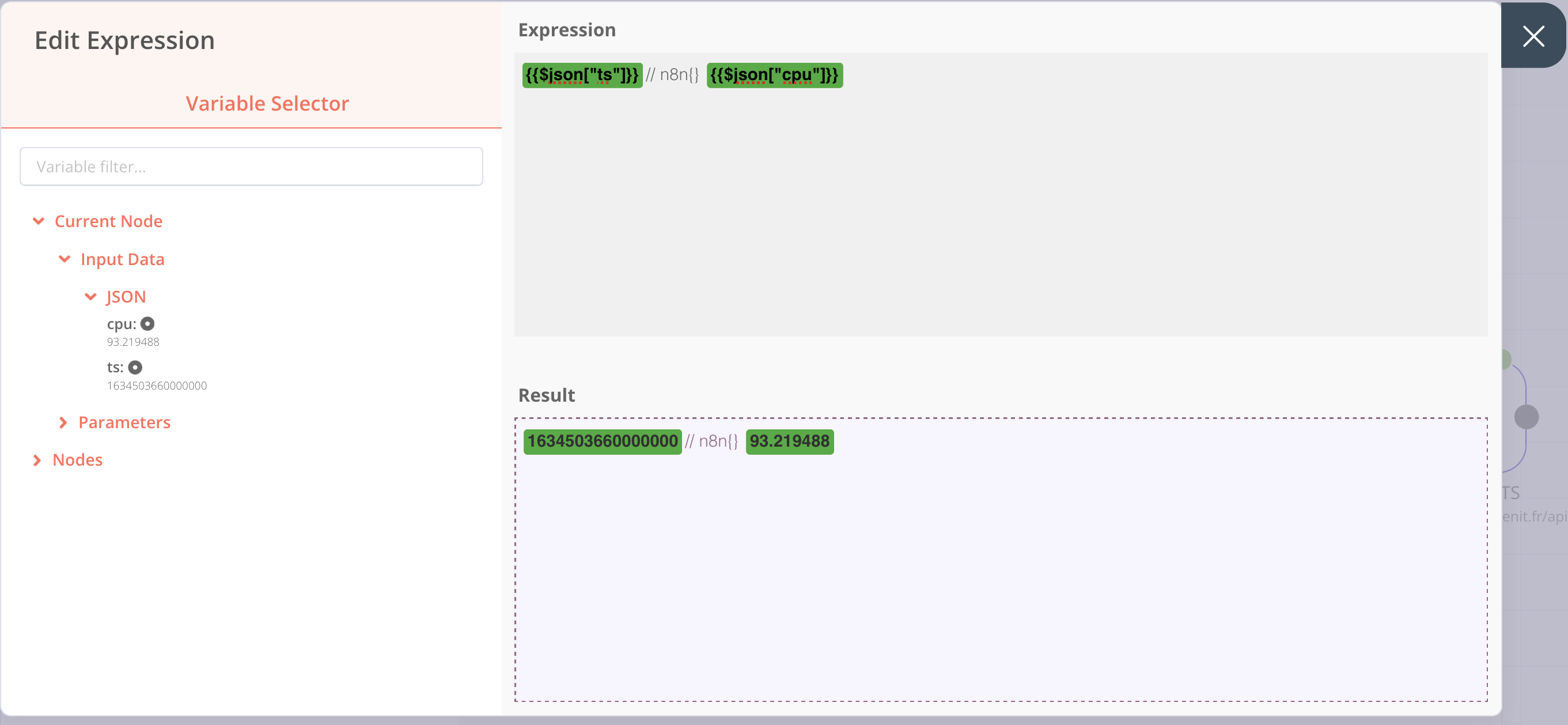
- Value > Add Expression et dans la partie expression, on met:
{{$json["ts"]}}// n8n{} {{$json["cpu"]}}
Ce qui nous donne l’écran suivant :
On revient à l’écran précédent en cliquant sur la croix à droite et en exécutant la node, on obtient :
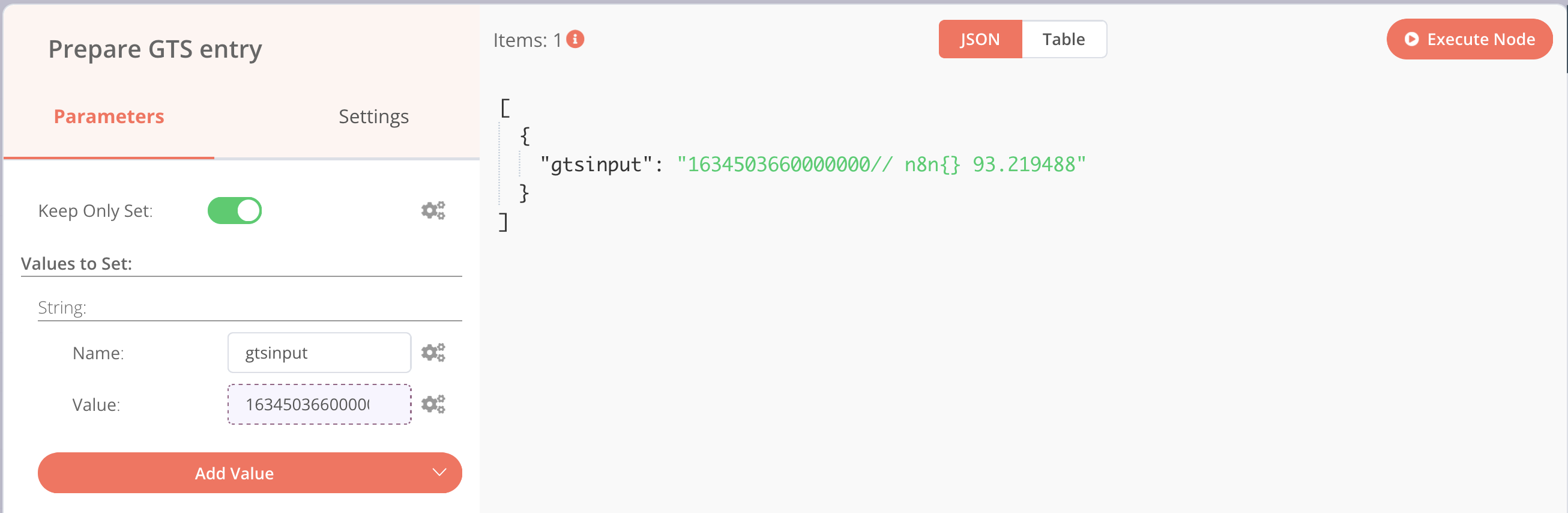
Ensuite, il faut ajouter une nouvelle node HTTP Request avec le paramétrage suivant :
- Parameters :
- Authentication > Header Auth
- Request Method : POST
- URL :
http://url.de.votre.instance.warp.10/api/v0/update - Activer la case JSON/RAW Parameters
- Options :
- Add Option > Mime Type : text/plain
- Add Option > Body Content Type : RAW/Custom
- Add Option > Full Response et activer là pour voir la réponse complète de votre instance Warp 10
- Body Parameters > Add Expression > Current Node > Input Data > JSON > gtsinput (les colonnes de droites doivent se remplir avec la clé en haut et la valeur en dessous ; cliquer sur la croix pour revenir à l’écran précédent)
En haut du menu de gauche, une section “Credentials” est apparue ; dans la liste déroulante, cliquer sur “Create new” et remplissez le formulaire de la façon suivante:
- Name: X-Warp10-Token
- Value : votre token Warp 10 avec des droits d’écriture
Revener ensuite dans votre node HTTP Request dont on peut lancer l’exécution et on obtient :
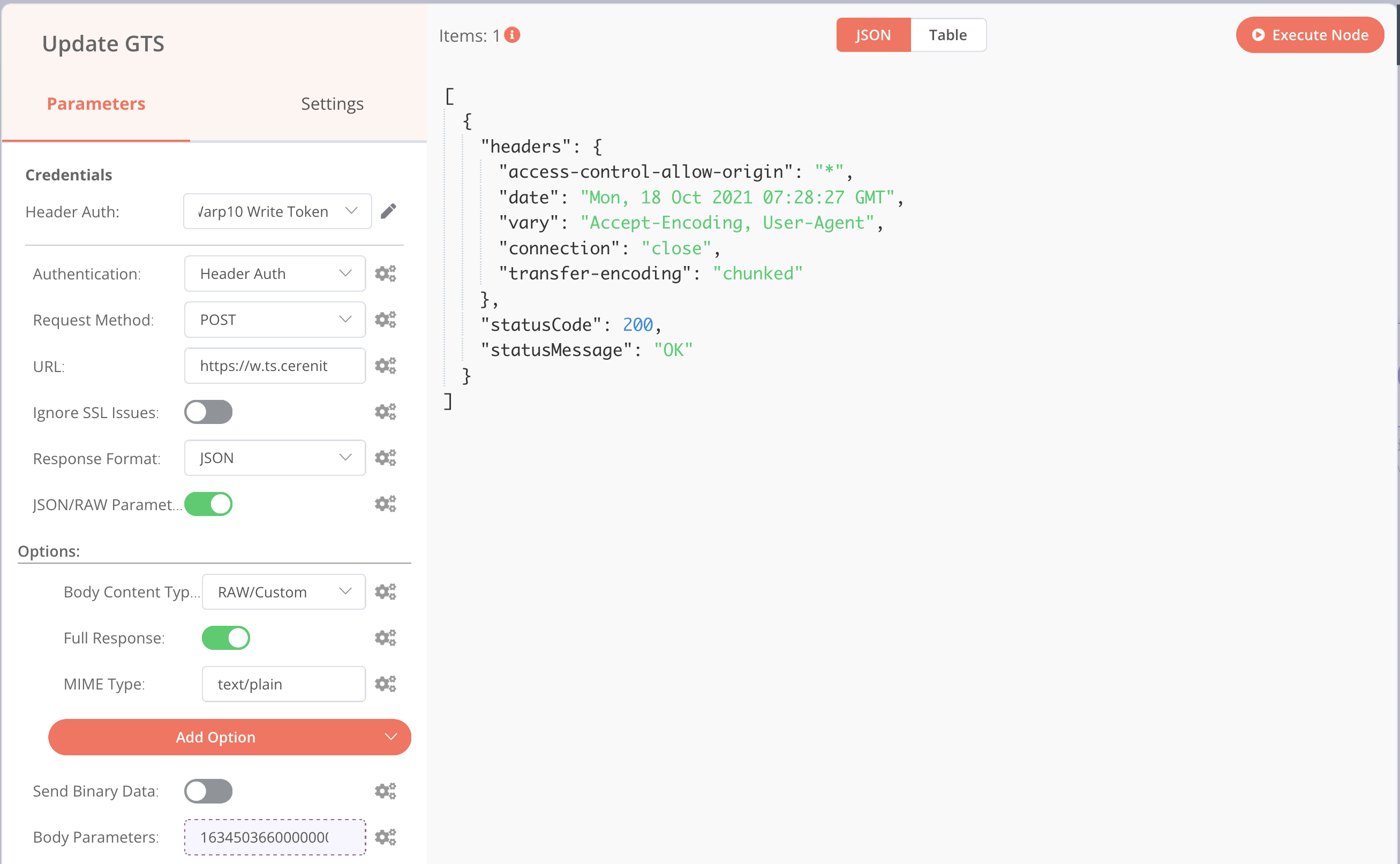
Si je vais ensuite voir le contenu de ma série n8n :
'<readToken>' 'readToken' STORE
[ $readToken 'n8n' {} NOW -100 ] FETCH
J’obtiens comme réponse :
[
[{
"c": "n8n",
"l": {
".app": "io.warp10.bootstrap"
},
"a": {},
"la": 0,
"v": [
[1634503660000000, 93.219488],
[1634502790000000, 94.808468],
[1634501690000000, 93.7751],
[1634501550000000, 91.741742],
[1634478300000000, 92.774711]
]
}]
]
Avec une entrée pour chaque exécution du workflow sous réserve d’avoir un “CPU idle” >= 90%.
En conclusion, nous pouvons retenir que :
- Il est facile d’intégrer Warp 10 dans un workflow n8n grâce à l’API HTTP de Warp 10 et la node HTTP Request de n8n
- Pour interagir avec Warp 10, il faut d’abord créer un objet portant le code WarpScript ou les donées au format GTS Input pour l’envoyer ensuite à Warp 10 via la node HTTP Request
- Même si cela n’a pas été détaillé, il est possible de manipuler les données issues de Warp 10 ou de préparer des données à destination de Warp 10.
Le workflow était très basique pour permettre de montrer rapidement cette intégration. Des workflows plus complexes et riches sont laissés à votre imagination :
- sur la base d’un événement avec la node Webhook : insertion de données ou lancement d’une analyse suite à un événement, etc.
- sur la base d’une tache planifiée avec la node Cron : analyse de données, etc
- ou depuis Warp 10, on peut appeler n8n en utilisant HTTP, URLFETCH ou WEBCALL pour lancer l’exécution d’un workflow ou récupérer le résultat d’un workflow.
Web, Ops, Data et Time Series - Septembre 2021
automl telegraf anomalie python podman npm nodejs jvm adoptopenjdk questdb cloudflare aws s3 docker warp10 discovery tinygo circuitpython nrtsearch elasticsearch influxdbCloud
- LCC 262 - Interview Cloud de Confiance avec Quentin Adam : Interview posée, pédagogue et claire sur les enjeux du cloud de confiance / cloud souverain mais pas que. A écouter absolument.
- Announcing Cloudflare R2 Storage: Rapid and Reliable Object Storage, minus the egress fees : après son billet vindicatif vis à vis des couts de transferts AWS, Cloudflaire sort son système de fichiers distribué qui se veut une alternative à S3 et avec un cout de migration depuis AWS marginal/progressif puisque apparemment seuls les fichiers appelés seront sortis de leur bucket d’origine pour aller sur R2 et être servi depuis R2 ensuite
- The Compelling Economics of Cloudflare R2 : quelques exemples des économies réalisées entre R2 et S3 ou R2 en mode proxy devant S3.
Container et Orchestration
- Docker is Updating and Extending Our Product Subscriptions : TL;DR: Docker Desktop requiert un abonnement Pro/Team/Business si vous êtes une organisation de plus de 250 employés et 10 Millions de Chiffre d’affaires. L’abonnement commence à 5$/mois/utilisateur. Ce changement démarre au 31/08/2021 avec une période de grâce jusqu’au 31/01/2022. Si certains crient au scandale, il faut bien voir tout ce que Docker Desktop fourni et le travail d’intégration que cela représente. Il faut bien que la société Docker vive pour maintenir ses produits. Tout cela se retrouve dans The Magic Behind the Scenes of Docker Desktop.
- Podman Release v3.3.0 : cette version apporte “podman machine” qui devrait notamment permettre un meilleur support de podman sous OSX avec une couche de virtualisation intermédiaire dans la même veine que Docker Desktop dans le but de proposer une intégration native. Cela ne semble pas fonctionner sur un Apple M1 à cause de l’incompatibilité actuelle de Virtual Box avec ces puces. Si Podman peut certes être une alternative à Docker (Desktop), cela montre aussi le travail d’intégration réalisé par Docker Inc notamment pour le support des Apple M1.
- Podman on Macs Update : statut sur le support de Podman dans un context MacOS/Intel, Windows/Intel et le reste à faire pour MacOS/M1. En attendant,
podman machineest supporté nativement sur Linux et MacOS/Intel et en remote client sur Windows/Intel. - How Docker broke in half : restrospective sur Docker de ses origines à aujourd’hui et quelques pistes pour le futur…
- Docker Compose V2.0.0 : L’outil a été réécrit en go plutôt qu’en python et se veut accessible via la docker cli en tant que sous système (ie
docker compose xxx). Pour Windows & OSX, il est fourni avec Docker Desktop. - Accelerating New Features in Docker Desktop où l’on parle de l’arrivée prochaine d’un Docker Desktop For Linux !!
- No, we don’t use Kubernetes : un billet rafraichissant qui rappelle que Kubernetes n’est pas l’alpha et l’omega de l’infrasatructure.
IoT
- CircuitPython 7.0.0 Released! : version majeure de CircuitPython qui apporte son lot d’améliorations matérielles et logicielles depuis la version 6.3
- tinygo 0.20 : principalement l’ajout du support de Go 1.17 et de nouveaux controlleurs.
JVM
- Good-bye AdoptOpenJDK. Hello Adoptium! : le projet AdoptOpenJDK est repris sous le projet Eclipse Adoptium, qui vient de signer sa première release. Il faudra prévoir une migration vers leurs binaires et leurs dépots ultérieurement (date non définie à ce jour).
Recherche
- Nrtsearch: Yelp’s Fast, Scalable and Cost Effective Search Engine : nouvel entrant dans le monde de la recherche distribuée et opensource basée sur Lucene. Après ElasticSearch et OpenSearch, c’est au tour de Nrtsearch édité par Yelp qui a cherché à résoudre les problèmes qu’ils rencontraient avec ElasticSearch.
Sécurité
- GitHub security update: Vulnerabilities in tar and @npmcli/arborist : si vous utilisez le package
tarde NodeJS directement (ou indirectement), il est judicieux de mettre à jour votre version denpmetnodeet de vérifier vos dépendances. - Demon’s Cries vulnerability (some NETGEAR smart switches) : si vous avez des “smart switchs” de la marque Netgear, il est temps de patcher le firmware de votre équipement.
- Let’s Encrypt’s Root Certificate is expiring! : si vous avez de vieux équipements dans la nature et qu’ils utilisent ce certificat de Lets Encrypt, il y a des chances qie cela se passe mal à compter de demain…
Time Series
- Industrie du futur : les données sur le chemin critique, Industrie du futur : les données sur le chemin critique – Partie 2 et Industrie du futur : les données sur le chemin critique – Partie 3 : Suite d’un premier article “Les séries temporelle : le futur de la donnée qui continue à poser les enjeux de l’industrie du futur et les évolutions que cela va apporter pour permettre une maintenance analytique (version optimisée de la maintenance préventive et réactive/conditionelle), la data pour la création de nouveaux services et générateurs de revenus (directs ou indirects), les jumeaux numériques et sur un fond de synergies entre l’informatique technique et celle de gestion pour une optimisation des process.
- Server monitoring with Warp 10 and Telegraf : Premiers pas pour la mise en place d’une stack de monitoring avec Telegraf / Warp 10 et Discovery ; manque plus que la suite à Alerts are real time series pour avoir la partie alerting (et notifications ?).
- Discovery : la documentation de la solution de Dashboard as Code pour Warp 10 est (enfin) arrivée !
- winedarksea/AutoTS : tout est dans la description : “AutoML for forecasting with open-source time series implementations.” ; c’est en Python et cela embarque beaucoup de classes / modèles / transformations / …
- Anomaly Detection Toolkit (ADTK) : un framework de détéction d’anomalies en python.
- QuestDB 6.0.5 & QuestDB 6.0.5 September release, geospatial support : la géotimeseries devient tendance : après InfluxDB qui l’a introduit il y a un an environ, et bien longtemps après Warp 10, c’est au tour de QuestDB d’introduire le support des données géospatiales. La version apporte aussi des améliorations sur
first()etlast()ainsi que les nouvelles fonctionstimestamp_floor()ettimestamp_ceil()pour gérer les arrondis inférieurs/supérieurs. Enfin, l’API HTTP accepte des paramètres liés au “Out Of Order”. - QuestDB 6.0.6 : version de maintenance
- QuestDB 6.0.7 : la version 6.0.6 introduit un bug dans le cadre de la migration depuis une version antérieure. La version 6.0.7 apporte un correctif sur le sujet. Si vous êtes en en 6.0.6, mettre à jour * [en 6.0.7 - si vous êtes dans une version inférieure à 6.0.6, passez à la version 6.0.7 sans passer par la case 6.0.6
- QuestDB 6.0.7.1 : en espérant que cette version soit enfin la bonne pour les migrations.
- TimescaleDB 2.4.2 : version de maintenance
- InfluxDB’s Checks and Notifications System : un billet très détaillé sur le fonctionnement des checks et des notifications sous InfluxDB v2 pour mettre en place vos alertes.
- New in Grafana 8.1: Gradient mode for Time series visualizations and dynamic panel configuration : un mode gradient pour les time series qui permet d’appliquer des couleurs sur ses graphs en fonction de seuils.
