Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Ma comptabilité, une série temporelle comme les autres - partie 3 - exécution distante
warp10 timeseries comptabilité remote execution rexec lmap templateSuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale (ce billet)
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512
- Partie 6 - Les FEC et le compte de résultat
A l’issue du précédent billet, depuis le WarpStudio et en stockant les données dans la sandbox, nous avons manipuler les données pour :
- refaire les précisions de juin à décembre 2020 à partir des données de 01/2017 à 05/2017
- comparer ses prévisions avec les résultats réels
- faire les prévisions pour 2021.
Cependant, cela n’est pas parfait :
- La durée de vie des données dans la sandbox est limitée à 2 semaines
- Il faut copier/coller ses requêtes dans le studio pour obtenir les graphiques
- Mais cela permet d’évaluer les extensions commerciales déployées sur la sandbox mais que vous n’avez pas forcément sur votre instance Warp 10 (au moins pour le moment)
Nous allons voir aujourd’hui comment rappatrier les données générées dans sa propre instance Warp 10.
Génération des prévisions
Pour commencer du bon pied et être sur que tout le monde est au même niveau, nous allons regénérer les prévisions et chaque prévision sera alors stockée dans une sériée dédiée. Cela nous permet d’avoir notre jeu de données de départ. On doit pouvoir sauver directement nos données dans une base distante, mais pour simplifier le tutoriel, nous allons le faire en deux étapes.
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des séries 2017 > 2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// Prévision sur les 12 prochains mois avec AUTO
// On n'a pas besoin d'afficher les données
// Donc plus besoin de les stocker sous forme de variable avec utilisation de la fonction STORE
// Par contre, on veut perstister les données en base
// ce qui se fait avec UPDATE et l'utilsation d'un token en écriture
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_result" RENAME
$writeToken UPDATE
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_revenue" RENAME
$writeToken UPDATE
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_expense" RENAME
$writeToken UPDATE
# Prévisions avec SAUTO
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_result" RENAME
$writeToken UPDATE
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_revenue" RENAME
$writeToken UPDATE
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_expense" RENAME
$writeToken UPDATE
Si nous vouulons vérifier que vos données sont bien en base, il faut utiliser FETCH :
// Ex de FETCH avec la série auto_revenue
'<read token>' 'readToken' STORE
[ $readToken 'auto_revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2022-01-01T00:00:00Z' ] FETCH
0 GET
Attaquons maintenant la grande traversée des données vers mon instance Warp 10.
Activation de l’exécution à distance
Alors on pourrait simplement migrer les données à coup de “curl in/curl out” mais l’idée ici est plus d’illustrer les interactions possibles entre des instances Warp 10.
Pour exécuter du warpscrip sur une instance distante, il faut utiliser la fonction REXEC
Cette exécution distante est désactivée par défaut, il faut donc activer cette extension:
Dans /path/to/warp10/etc/conf.d/70--extensions.conf, nous avons :
// REXEC
#warpscript.extension.rexec = io.warp10.script.ext.rexec.RexecWarpScriptExtension
#warpscript.rexec.endpoint.patterns = .*
// REXEC connect timeout in ms (default = 0, no timeout)
#warpscript.rexec.timeout.connect = 3600000
// REXEC read timeout in ms (default = 0, no timeout)
#warpscript.rexec.timeout.read = 3600000
Décommentons ces lignes et relançons warp 10.
Pour valider que REXEC est bien activé, depuis le studio, nous pouvons faire un test simple:
'2 2 +' 'https://warp10.url:port/api/v0/exec' REXEC
La réponse est 4.
Attention, il faut choisir votre instance comme endpoint dans la liste déroulante du studio. Si vous êtes sur le endpoint de la sandbox, vous auez le message d’erreur suivant :
https://sandbox.senx.io/api/v0/exec
line #2: Exception at ''2%202%20+' 'https://warp10.url:port/api/v0/exec' =>REXEC<=' in section [TOP] (REXEC encountered a forbidden URL 'http://warp10.url:port/api/v0/exec')
En effet, depuis la Sandbox, il n’est pas possible d’accéder à n’importe quelle machine par mesure de sécurité.
Requêtage simple à distance
Dans le studio, à partir de maintenant, il doit être configuré pour utliiser votre instance Warp 10 comme endpoint.
Le test simple étant fonctionnel, passons à un test un peu plus compliqué, à savoir recupérer nos données hébergées depuis la sandbox en lecture pour le moment.
// tokens pour la sandbox
'<sandboxReadToken>' 'sandboxReadToken' STORE
'<sandboxWriteToken>' 'sandoxWriteToken' STORE
// Url de la sandbox
'https://sandbox.senx.io/api/v0/exec' 'url' STORE
// On introduit ici la notion de template - comme on va vouloir récupérer plusieurs séries avec les mêmes paramètres
// Autant automatiser un peu et s'appuyer sur une boucle ! :-)
// On crée donc un TEMPLATE pour la fonction FETCH qui va récupérer un token en écriture
// et un nom de classe permettant de récupérer nos GTS.
// Rappel le <' ... '> permet de faire des strings en multi-lignes
// On stocke le template sous la forme d'une variable fetchTpl.
<'
{
'token' '{{ remoteReadToken }}'
'class' '{{ remoteClass }}'
'labels' {}
'start' '2016-12-01T00:00:00Z'
'end' '2022-01-31T00:00:00Z'
} FETCH
'>
'fetchTpl' STORE
// Avec la fonction TEMPLATE, on remplace les clés par leurs valeurs en fournissant le template
// et un dictionnaire à la fonction.
$fetchTpl
{ 'remoteReadToken' $sandboxReadToken 'remoteClass' 'revenue' } TEMPLATE
// Execution de la requête distante avec REXECZ
// La différence avec REXEC est qu'une compression est appliquée sur la réponse à la requête
$url REXECZ
// La liste de GTS issue de FETCH ne contient qu'une liste, on prend donc la première
0 GET
// Stockage sous la forme d'une variable
'revenueGTS' STORE
// Affichage de la série
$revenueGTS
Si vous allez dans l’onglet dataviz, vous pouvez constater que vos données issues de la sandbox mais qui ont transité via votre instance sont bien disponibles.
Transfert des données - 1 série
Si nous commençons par une seule série :
// tokens de l'instance
'<instanceReadToken>' 'instanceReadToken' STORE
'<instanceWriteToken>' 'instanceWriteToken' STORE
// tokens pour la sandbox
'<sandboxReadToken>' 'sandboxReadToken' STORE
'<sandboxWriteToken>' 'sandoxWriteToken' STORE
// Url de la sandbox
'https://sandbox.senx.io/api/v0/exec' 'url' STORE
// Template de code warpscript
<'
{
'token' '{{ remoteReadToken }}'
'class' '{{ remoteClass }}'
'labels' {}
'start' '2016-12-01T00:00:00Z'
'end' '2022-01-31T00:00:00Z'
} FETCH
'>
'fetchTpl' STORE
// Substitution des variables
$fetchTpl
{ 'remoteReadToken' $sandboxReadToken 'remoteClass' 'revenue' } TEMPLATE
// Exécution de la requête
$url REXECZ
// La liste de GTS issue de FETCH ne contient qu'une liste, on prend donc la première
0 GET
// Il faut renommer "localement" la série avant de pouvoir la stocker dans l'instance
// Peut éviter de mauvaises manipulations que l'on pourrait regretter :-)
"revenue" RENAME
// Persistance des données
$instanceWriteToken UPDATE
Il y a quelques occurences de “revenue” en dur dans le code, il va falloir améliorer cela.
Transfert des données - plusieurs séries
Et maintenant, traitons nos 9 series d’un coup
// tokens de l'instance
'<instanceReadToken>' 'instanceReadToken' STORE
'<instanceWriteToken>' 'instanceWriteToken' STORE
// tokens pour la sandbox
'<sandboxReadToken>' 'sandboxReadToken' STORE
'<sandboxWriteToken>' 'sandoxWriteToken' STORE
// Url de la sandbox
'https://sandbox.senx.io/api/v0/exec' 'url' STORE
// Template de code warpscript
<'
{
'token' '{{ remoteReadToken }}'
'class' '{{ remoteClass }}'
'labels' {}
'start' '2016-12-01T00:00:00Z'
'end' '2022-01-31T00:00:00Z'
} FETCH
'>
'fetchTpl' STORE
// Création d'une liste avec nos 9 séries
// C'est cette liste que nous allons passer ensuite dans une MACRO.
// Cette MACRO va être exécutée sur chaque élément de la liste via l'utilisation de la fonction LMAP
// https://www.warp10.io/doc/LMAP
[ 'revenue' 'exp' 'result' 'auto_revenue' 'auto_result' 'auto_expense' 'sauto_revenue' 'sauto_result' 'sauto_expense' ]
// Début de la MACRO
<%
// On récupère la valeur de la liste que l'on stocke sous la forme d'une variable
'remoteClass' STORE
// Substitution des valeurs de template
$fetchTpl
{ 'remoteReadToken' $sandboxReadToken 'remoteClass' $remoteClass } TEMPLATE
// Exécution distante de la requête
$url REXECZ
// On récupère ici une liste de GTS - plutôt que d'en extraire la GTS comme précédemment
// on va garder une liste de GTS à 1 élément, mais ce qui permet à nouveau d'utiliser la fonction LMAP
// Sur chaque entrée de la liste, une seconde macro est appliquée
// Le contenu de notre macro consiste à utliser la fonction RENAME
// '+' RENAME, cela revient à renommer la GTS en prenant le même nom que celui qui est fourni
// '+x' RENAME aurait ajouté un x au nom de la série
// Il reste l'index de la liste à traiter - soit on le supprime avec DROP
//<% DROP '+' RENAME %> LMAP
// Soit on passe F comme 3ème argument à LMAP - cela permet d'ignorer cet index
// <% '+' RENAME %> F LMAP
// Prenons la seconde forme :
<% '+' RENAME %> F LMAP
// Toutes nos séries ont été correctement renommées !
// On persiste la GTS dans la base locale
$instanceWriteToken UPDATE
%>
// Fin de la MACRO
// Application de la fonction LMAP pour que notre macro soit exécutée sur chaque élément de la liste.
// Comme on ne veut que les valeurs de la liste et pas les index, on positionne aussi F
// comme 3ème argument à LMAP
F LMAP
Et voilà, nos données ont été récupérées de la Sandbox et stockées dans notre instance locale.
Bonus
Une version alternative - dans mes données, je peux tricher et ne filtrer que sur le label company avec pour valeur cerenit:
// tokens de l'instance
'<instanceReadToken>' 'instanceReadToken' STORE
'<instanceWriteToken>' 'instanceWriteToken' STORE
// tokens pour la sandbox
'<sandboxReadToken>' 'sandboxReadToken' STORE
'<sandboxWriteToken>' 'sandoxWriteToken' STORE
// Url de la sandbox
'https://sandbox.senx.io/api/v0/exec' 'url' STORE
// Warpscript template
<'
{
'token' '{{ remoteReadToken }}'
'class' '~.*'
'labels' { 'company' 'cerenit' }
'start' '2016-12-01T00:00:00Z'
'end' '2022-01-31T00:00:00Z'
} FETCH
'>
'fetchTpl' STORE
// Substitution dans le template
$fetchTpl
{ 'remoteReadToken' $sandboxReadToken } TEMPLATE
// Execution de la requête
$url REXECZ
// Renommage des séries
<% '+' RENAME %> F LMAP
// Presistence des données
$instanceWriteToken UPDATE
Bravo si vous m’avez suivi jusqu’ici, nous avons pu voir l’utilisation de :
- Comment permettre un requêtage à distance d’une instance Warp 10 avec les fonctions
REXECetREXECZ - Comment traiter dynamiquement notre liste de GTS avec
LMAPet uneMACRO - Comment faire un template warpscript et de la substitution de variables avec
TEMPLATE
Nous verrons dans un prochain épisode :
- Comment utiliser Discovery pour faire nos premiers dashboards
- Pourquoi/comment utiliser des macros coté server (spoiler: pour éviter que vos tokens se retrouvent dans votre navigateur à l’exécution des dashboards)
Ma comptabilité, une série temporelle comme les autres - partie 2 - actualisation des données et des prévisions
warp10 timeseries comptabilité prévision forecastSuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021 (ce billet)
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512
- Partie 6 - Les FEC et le compte de résultat
L’année dernière, nous avions travaillé sur Warp 10 et mes données de comptabilité et jouer un peu avec les algo de prévision.
Les données comptables ayant été un peu ajustées entre temps et la librairie de prévision ayant aussi évolué coté SenX, les résultats ne sont plus tout à fait les mêmes. Nous allons donc reprendre tout ça.
Rappel des fais et prévisions à fin 2020
En septembre dernier, nous avions ce code pour avoir les données jusqu’au mois de Mai 2020 et une prévision jusqu’à la fin d’année:
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de dépenses / chiffre d'affaires / résult pour la période du 01/01/2017 -> 31/05/2020
// Chaque série est stockée dans une variable
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// On affiche les trois courbes
$revenue
$exp
$result
// On génère et affiche les prévisions - on renomme les séries pour mieux les différencier ensuite au niveau dataviz
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_expense" RENAME
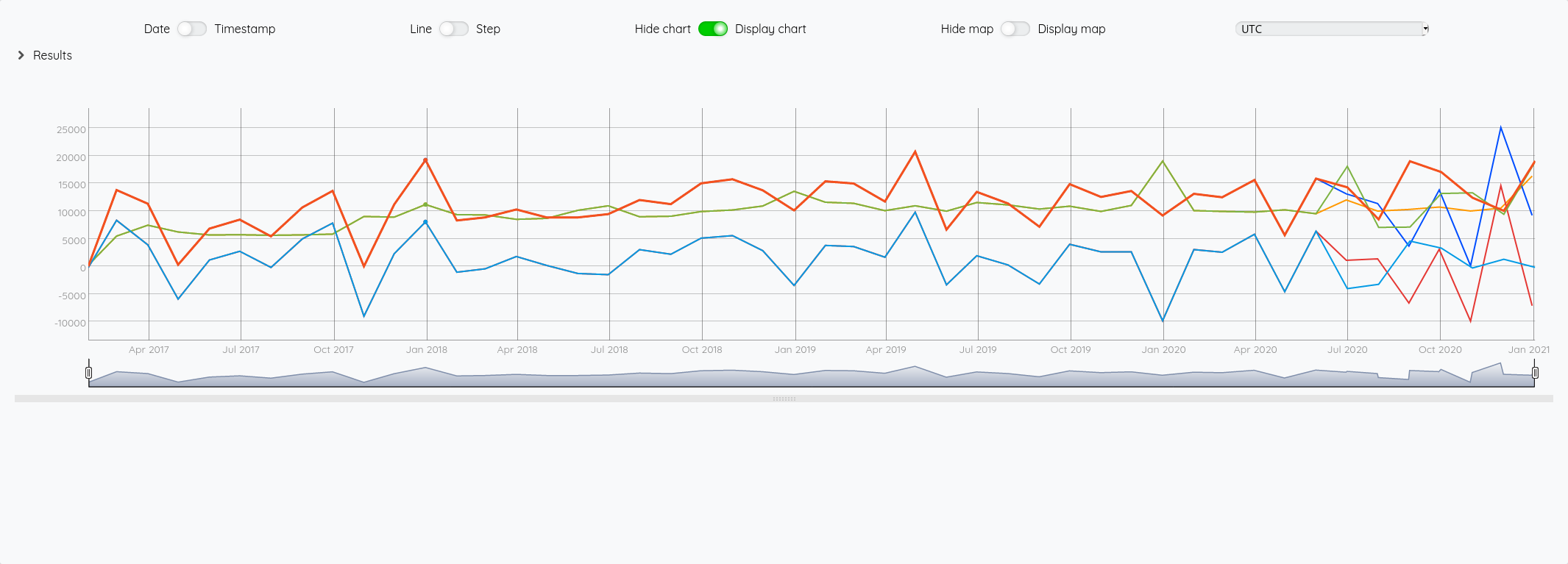
Au global :
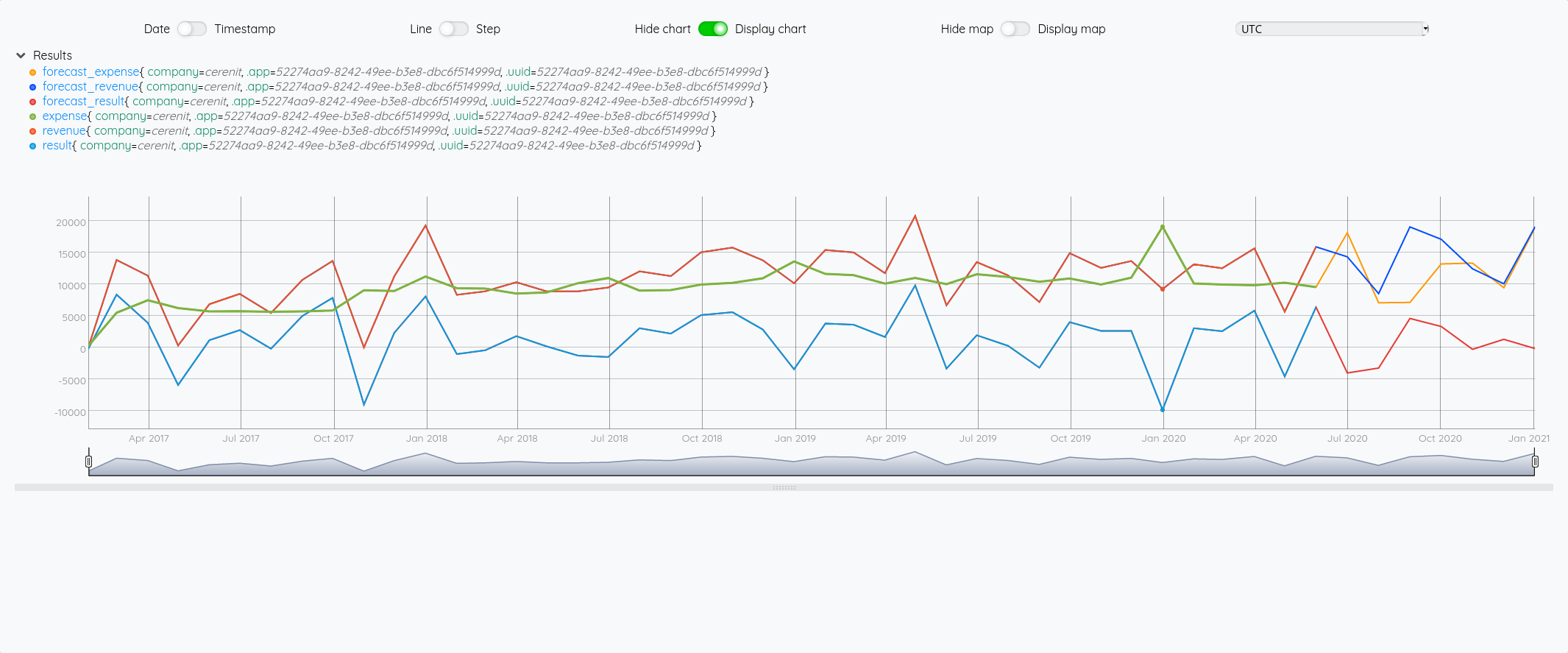
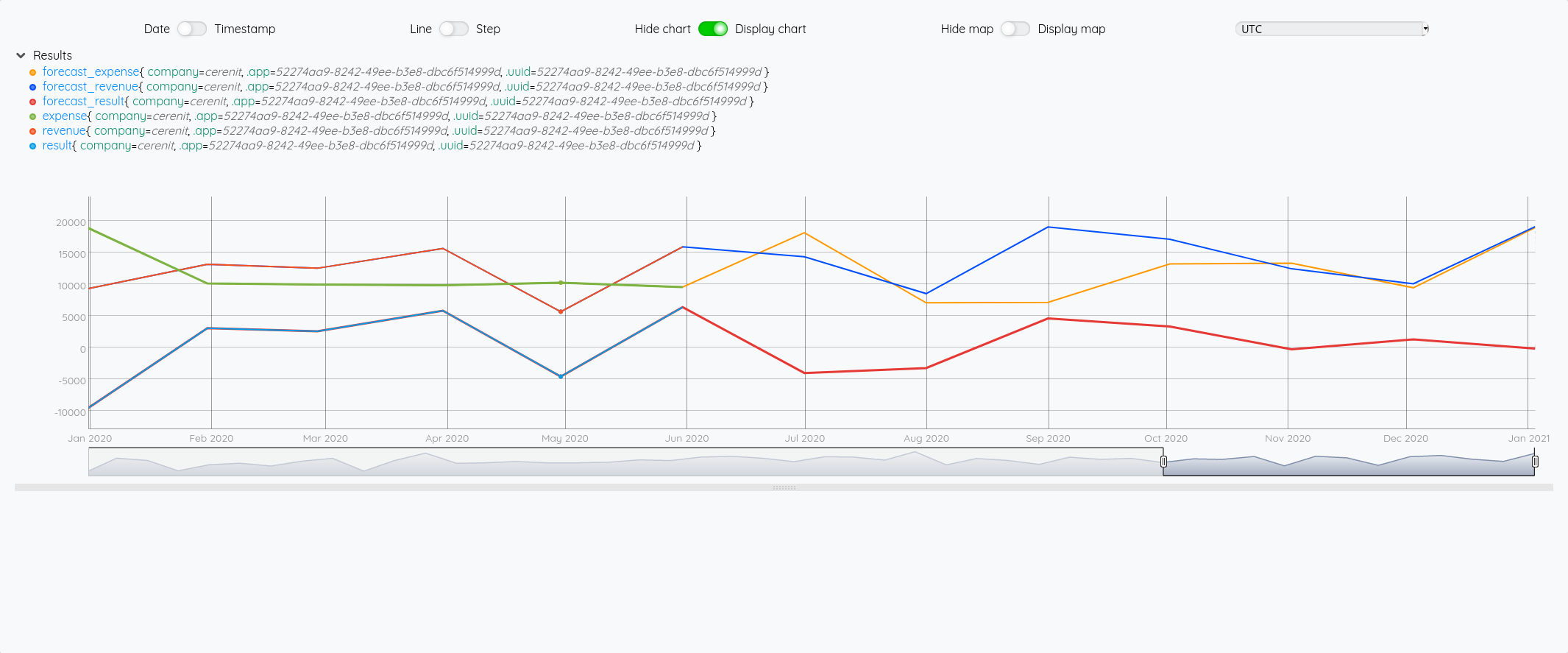
Focus 2020 avec la partie prévision à partir de juin :
Si on fait la même chose en prenant un algo incluant un effet de saisonnalité :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de dépenses / chiffre d'affaires / résult pour la période du 01/01/2017 -> 31/05/2020
// Chaque série est stockée dans une variable
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// On affiche les trois courbes
$revenue
$exp
$result
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_expense" RENAME
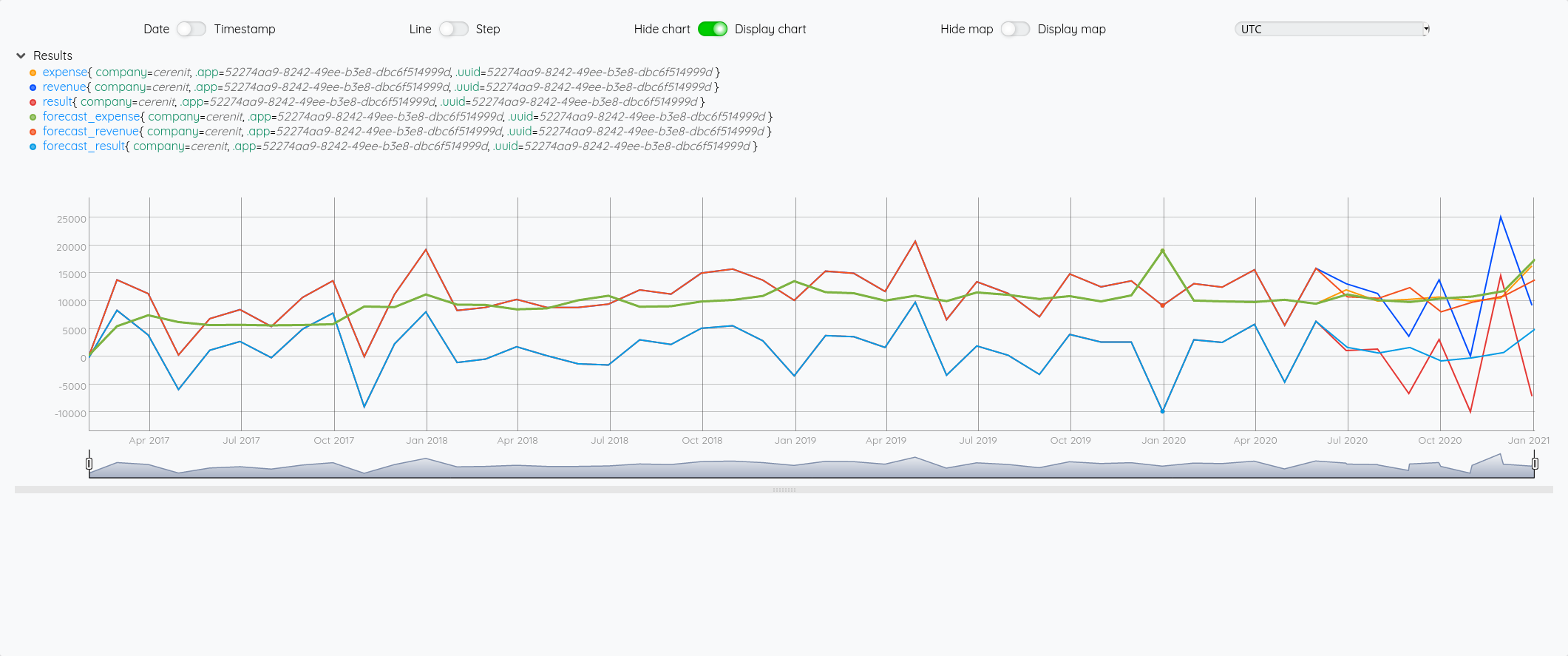
Au global :
Focus 2020 avec la partie prévision à partir de juin :
On a bien un petit écart de comportement sur la prévision entre les deux modèles (focus sur 2020 avec les différentes prévisions à partir de juin) :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de dépenses / chiffre d'affaires / résult pour la période du 01/01/2017 -> 31/05/2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_expense" RENAME
// On génère et affiche les prévisions - on renomme les séries pour mieux les différencier ensuite au niveau dataviz
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_expense" RENAME
Prévisions vs réalité
Comparons maintenant les prévisions à la réalité - je vais rajouter les requêtes pour avoir la vue complète des données - pour éviter de trop surcharger le graphique, comme les séries forecast_* reprennent les données sources et y ajoutent la prévision, je ne vais afficher que ces séries et les séries réelles :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de base qui serviront ensuite pour la prévision
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// Récupération des données réelles de la période 01/01/2017 > 31/12/2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_result' STORE
// Génération des prévisions
// Pour SAUTO, il faut définir en plus un cycle, ici 12 mois
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_expense" RENAME
$real_result
$real_revenue
$real_exp
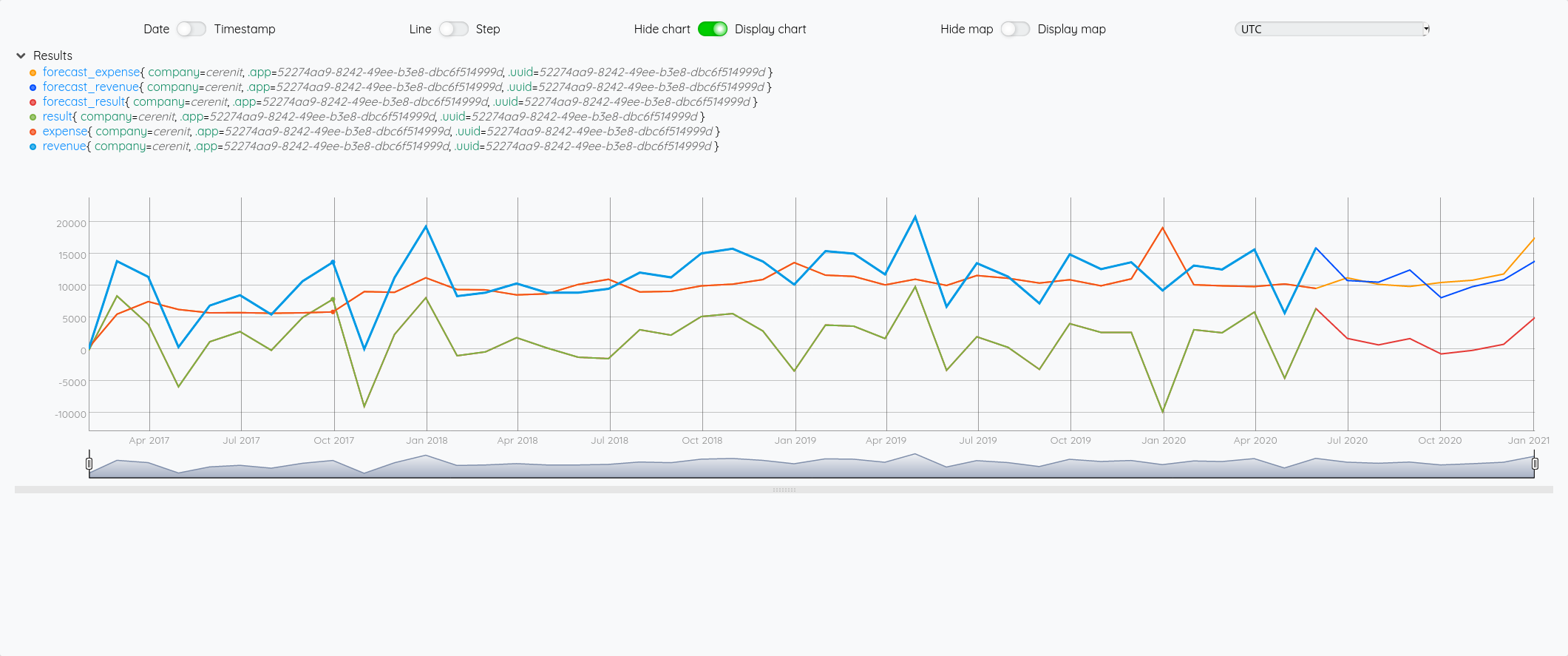
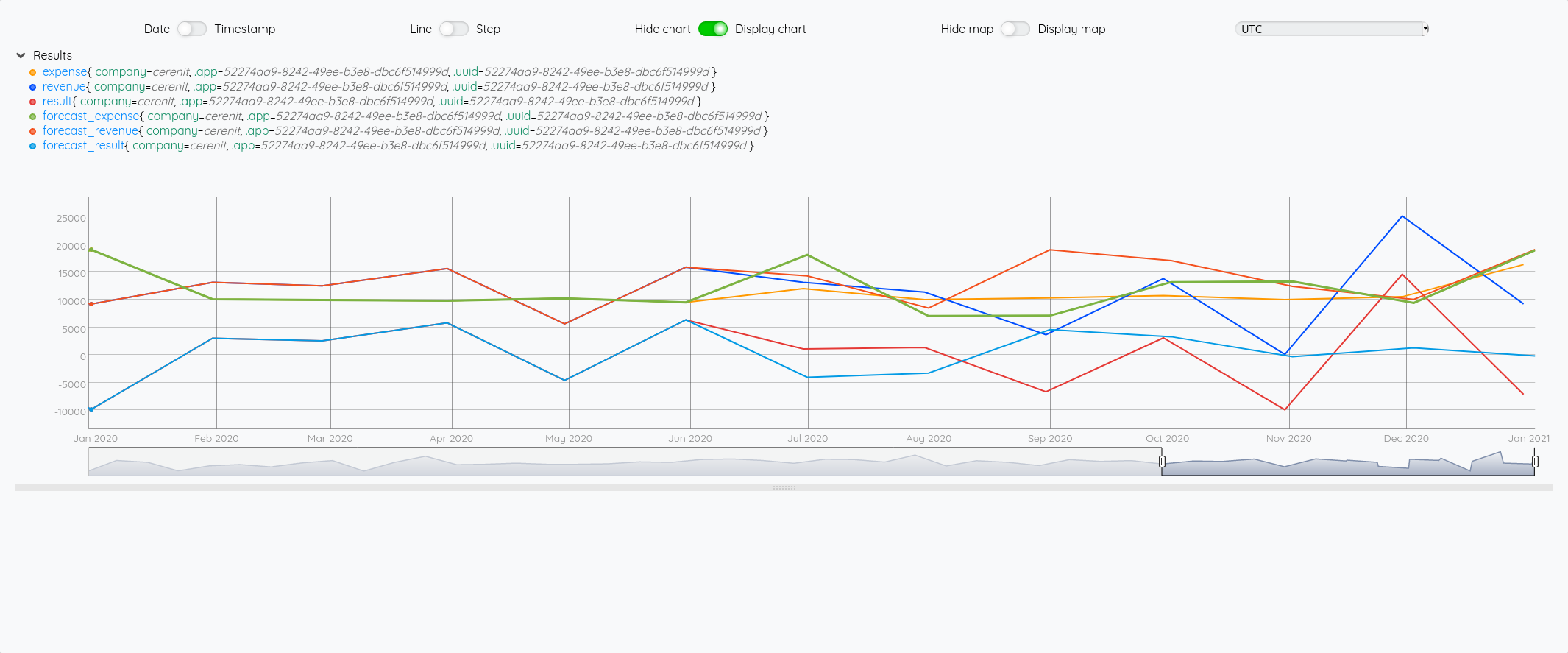
Ce qui nous donne au global :
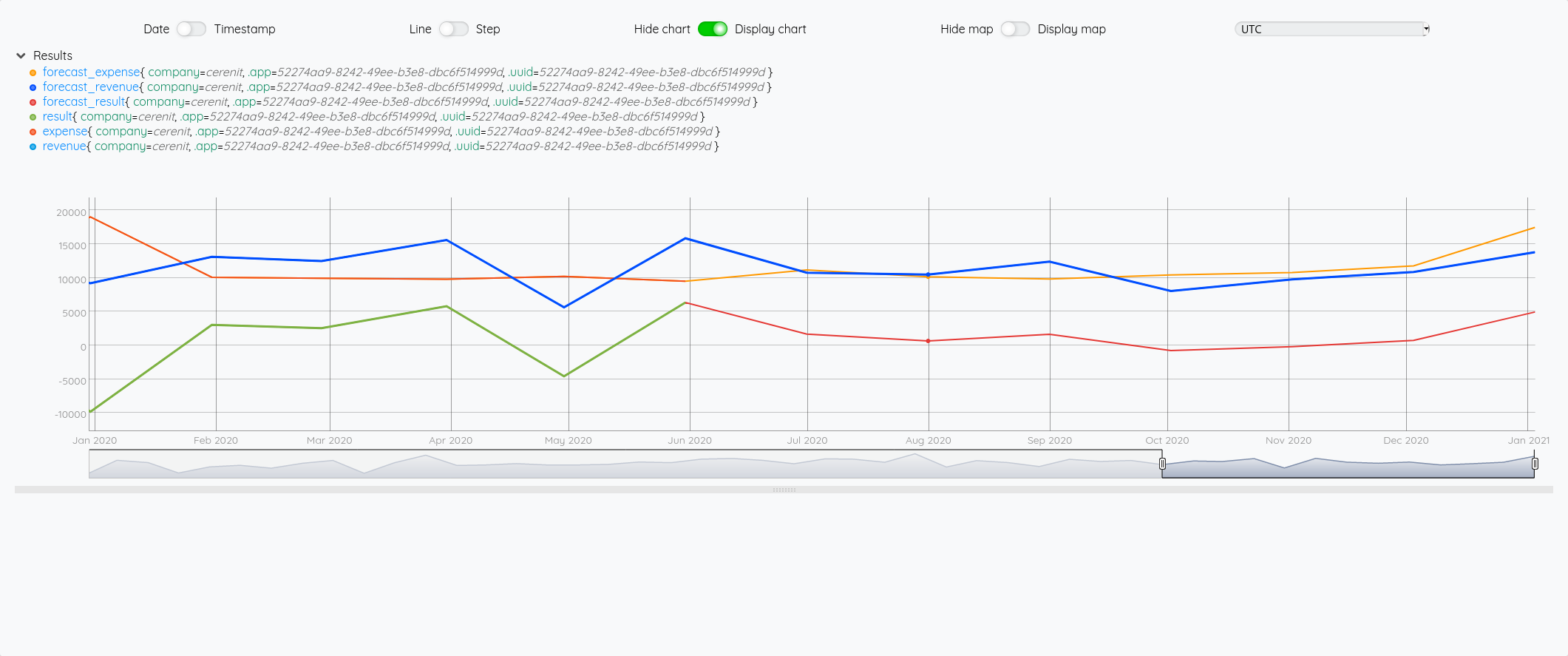
et avec le focus 2020 :
Si on fait la même chose avec SAUTO
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de base qui serviront ensuite pour la prévision
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// Récupération des données réelles de la période 01/01/2017 > 31/12/2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_result' STORE
// Génération des prévisions
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_expense" RENAME
$real_result
$real_revenue
$real_exp
Au global :
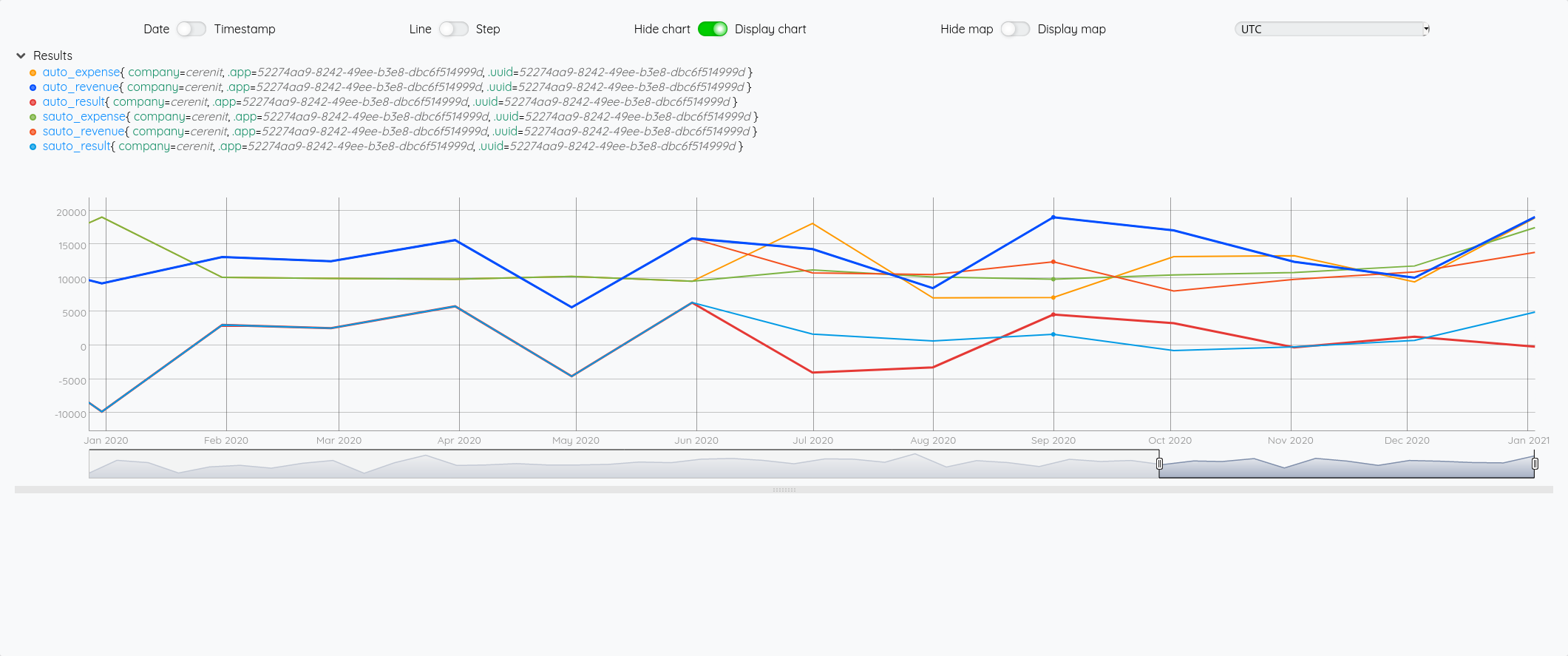
Focus 2020 avec la partie prévision à partir de juin :
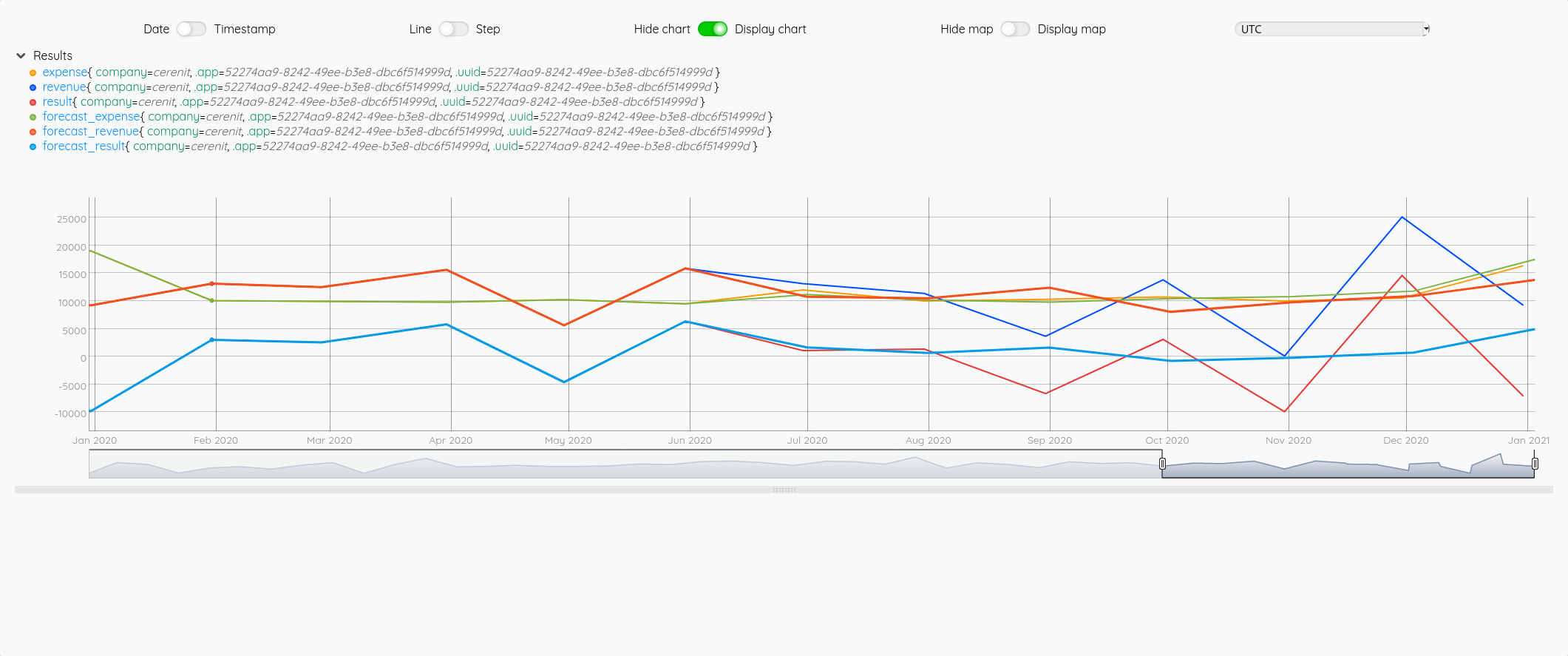
Essayons d’analyser tout ça (il faut regarder les fins de mois - les points sont en date du dernier jour du mois) :
- Pour Juin/Juillet, la prévision est plutôt bonne.
- Pour Aout : l’écart vient du fait que j’ai pris mes vacances en aout et pas à cheval sur juillet/aout comme les autres années
- Pour Septembre, c’est correct
- Pour Octobre, il faut voir que j’ai tardé à éditer mes factures - elles ont donc été pris en compte sur Novembre - si on divise le montant de Novembre en deux, on retombe à peu près sur nos points
- Pour décembre, un effet vacances également.
La pertinence est prévisions est donc plutôt correct au global et les écarts sont expliquables.
Consolidation annuelle
Et au niveau annuel ? Est-ce que les prévisions de chiffres d’affaires / dépenses / résultats sont bonnes si on ne tient plus compte des petits écarts de temps ci-dessus ?
Voyons celà :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des différentes séries comme précédemment
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_result' STORE
// Calcul des prévisions comme précédemment
// Petit ajout, on stocke le résultat sous la forme d'une variable pour être réutilisé ultérieurement
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_result" RENAME
'auto_result' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_revenue" RENAME
'auto_revenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_expense" RENAME
'auto_expense' STORE
// Aggrégation annuelle
// Utilisation de BUCKETIZE.CALENDAR et de la macro BUCKETIZE.byyear qui s'appuie dessus et qui permet de faire une aggrégation annuelle sur des données
// bucketizer.sum permet d'appliquer une somme sur les données regroupées par année
// UNBUCKETIZE.CALENDAR permet de retransformer l'indice issue de BUCKETIZE.CALENDAR en timestamp
[ $real_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $real_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $real_exp bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $auto_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $auto_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $auto_expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
// Meme chose pour SAUTO
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_result" RENAME
'sauto_result' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_revenue" RENAME
'sauto_revenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_expense" RENAME
'sauto_expense' STORE
[ $sauto_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $sauto_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $sauto_expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
Pour expliciter un peu au dessus :
On veut obtenir un résultat annuel couvant la période du 01/01 au 31/12 d’une année. Il faut donc prendre tous les points de l’année en question et en fait la somme.
Si on fait:
[ $real_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear
On obtient :
[{"c":"revenue","l":{"company":"cerenit",".app":"52274aa9-8242-49ee-b3e8-dbc6f514999d",".uuid":"52274aa9-8242-49ee-b3e8-dbc6f514999d"},"a":{".buckettimezone":"UTC",".bucketduration":"P1Y",".bucketoffset":"0"},"la":1612528364518,"v":[[47,100850],[48,132473],[49,151714],[50,139146]]}]
Les valeus obtenues sont :
[[47,100850],[48,132473],[49,151714],[50,139146]]
Les indices 47, 48, 49, 50 sont en fait un delta par rapport au 01/01/70. En effet, 2020 = 1970 + 50
En appliquant UNBUCKETIZE.CALENDAR, on retransforme ce 50 par ex en son équivalent sous la forme d’un timestamp : 1609459199999999.
On peut aussi utiliser TIMESHIFT de la façon suivante :
[ $real_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
Pour obtenir pour la partie valeur :
[[2017,100850],[2018,132473],[2019,151714],[2020,139146]]
Pour en savoir plus sur BUCKETIZE.CALENDAR et ses utilisations : Aggregate by calendar duration in WarpScript
Une fois qu’on reprend toutes ses données, on peut essayer de mesurer les écarts entre le réél et les prévisions des deux modèles :
| AUTO | SAUTO | Réel | AUTO vs Réel | SAUTO vs Réel | |
|---|---|---|---|---|---|
| Chiffre d’affaires | 144.029 | 125.128 | 139.146 | -3,39% | +11,20% |
| Dépénses | 117.701 | 113.765 | 129.464 | +9,99% | +13,80% |
| Résultat | 14.754 | 16.893 | 9.682 | -34,38% | -42,69% |
| Résultat corrigé | 26.328 | 11.363 | 9.682 | -63,23% | -14,79% |
Intéressant, la prévision de résultat n’est pas égale à la différence entre la prévision de chiffre d’affaires et la prévision des dépenses ! C’est la raison de la ligne “Résultat corrigé”.
A ce stade, il ne me semble pas possible de privilégier un modèle plus qu’un autre - même si du fait de la récurrence des vacances, on peut supposer que le modèle avec saisonnalité pourrait être plus pertinent.
Prévisions pour 2021
Pour aller au bout de cet exerice, il ne reste plus qu’à voir ce que nos algoritmes prévoient pour 2021 :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des séries 2017 > 2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// Prévision sur les 12 prochains mois
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_result" RENAME
'auto_result' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_revenue" RENAME
'auto_revenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_expense" RENAME
'auto_expense' STORE
// Consolidation annuelle avec AUTO
[ $auto_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $auto_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $auto_expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
// Prévisions avec SAUTO
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_result" RENAME
'sauto_result' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_revenue" RENAME
'sauto_revenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_expense" RENAME
'sauto_expense' STORE
// Consolidation annuelle avec SAUTO
[ $sauto_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $sauto_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $sauto_expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
On passe tout ça dans le shaker et on obtient :
| Prévu avec AUTO | Prévu avec SAUTO | |
|---|---|---|
| Chiffre d’affaires | 78.230 | 129.465 |
| Dépénses | 118.383 | 110.434 |
| Résultat prévu | 5.730 | 4.049 |
| Résultat corrigé | -40.153 | 19.031 |
Rendez-vous à la fin de l’année pour voir ce qu’il en est… et on peut espérer que la réalité sera proche du modèle avec saisonnalité !
Pour le moment, on travalle toujours dans le WarpStudio et on voudrait bien avoir des (jolis) dashboards qui font tout ça pour nous plutôt que de copier/coller du Warpscript. Ce sera le sujet de la partie 3.
Web, Ops & Data - Janvier 2021
timeseries prometheus promql ovhcloud IoT openhab timescaledb ptsm anomalie label machine-learning iac ansible libssh vector log warp10 influxdb openssh gpg podman docker compose sudoCloud
- Traefik Proxy 2.4 Adds Advanced mTLS, Kubernetes Service APIs, and More : Support du Proxy Protocol pour les services TCP, support avancé pour mTLS (et possible intégration Consul Connect) et support initial de la nouvelle API Service de Kubernetes pour les principales avancées. Le programme pour la 2.5 semble aussi alléchant : support HTTP/3, migration vers networking/v1 de Kubernetes et une nouvelle documentation (encore ?!).
- OVHcloud obtient le Visa de sécurité ANSSI pour sa qualification SecNumCloud : OVHCloud obtient la certification SecNumCloud de l’ANSSI pour sa solution “Hosted Private Cloud”.
Code
- GitLab release feature report : le code qui permet de générer le rapport ce qui a changé entre les versions de Gitlab.
- SSH is the new GPG : les dernières versions d’OpenSSH permettent de signer un fichier. Une solution intermédiaire entre de la signature de fichiers à base de MD5 & co qui donnent des informations de conformité mais sans indiquer qui a signé le fichier et une solution GPG plus complexe à mettre en oeuvre ?
Container et orchestration
- Using Podman and Docker Compose : podman, le “daemonless container engine” va permettre d’être utilisé avec docker-compose dans le cadre de la version 3.0. De quoi favoriser l’adoption de podman ?
Infra as code
- New LibSSH Connection Plugin for Ansible Network Replaces Paramiko, Adds FIPS Mode Enablement : Ansible change de librairie pour les connexions ssh en remplaçant paramiko par libssh. Elle se veut plus performante et peut être requis dans un contexte demandant du FIPS. Pensez à installer le paquet
libssh-dev(el)suivant votre distribution pour pouvoir installeransible-pylibssh. Mes premiers essais ne notent pas une amélioration sensible des performances… à voir sur d’autres machines et dans la durée…
IoT
- openHAB 3.0 Release et Release Notes : OpenHAB est une plateforme open source de gestion de périphétiques IoT et d’automatisation autour de ces périphériques. Elle est développée en Java, support 2000 “Things” (objets, équipements, protocoles). La version 3.0 apporte une refonte et l’unification de l’UI et des composants, le passage à Java 11 et plein d’autres choses. La migration depuis une version 2.x se fait assez simplement. Avec le nouveau moteur de règle, j’ai pu supprimer mon code spécifique. Reste encore la partie “Pages” à appréhender… J’avais préféré OpenHAB à Jeedom et Home Assistant
- Meet Raspberry Silicon: Raspberry Pi Pico now on sale at $4 : la fondation Raspberry Pi se lance dans les micro-controlleurs avec le Pico au prix de 4$.
- Raspberry Pi PICO la carte Microcontrôleur de la Fondation : un article très détaillé sur la prise en main du pico.
Observabilité
- Métriques, monitoring, push vs pull, Riemann, Vector : Panorama sur le push/pull dans le monde du monitoring et tour d’horizon des solutions existantes pour arriver à Vector dont je vous parlais le mois dernier.
- Une introduction à Vector : Tout est dans le titre, mise en place de quelques outils remontant des métriques et des logs et ingestion des métriques dans InfluxDB via Vector.
- OVHCloud > Logs Data Platform > Using Elasticsearch API to send your logs - Use Case: Vector : Si vous utilisez l’offre Logs Data Platform d’OVHCloud pour vos logs, vous pouvez utiliser le sink elasticsearch de Vector pour envoyer vos logs vers Logs Data Platform.
- First-class Kubernetes Integration for Vector : Dans le cadre de la release 0.11, Vector a annoncé un support de Kubernetes avec une phase de collecte et d’enrichissement des logs. Cela mériterait d’être creusé…
Système
- CVE-2021-3156: Heap-Based Buffer Overflow in Sudo (Baron Samedit) & Buffer overflow in command line unescaping: il est temps de patcher vos systèmes linux utilisant sudo - l’attaque permet de faire une élévation de privilèges si le fichier
sudoersest présent sur le système (en général:/etc/sudoers). Les versions 1.8.2 à 1.8.31 et 1.9.0 à 1.9.5-p1 sont impactées, il faut passer en version 1.9.5-p2.
Time Series
- Erlenmeyer and PromQL compatibility : OVHCloud, dans le cadre de leur offre OVH Metrics, a développé Erlenmeyer, un proxy qui permet de convertir différents format de séries temporelles (Promql, Influxql, OpenTSDB, etc) au format Warp 10 qui est utilisé pour stocker ces métriques. Le billet porte sur leur retour d’expérience sur l’utilisation du “PromQL compliance tester” pour valider qu’Erlenmyer supportait bien les requêtes PromQL.
- TimescaleDB 2.0 GA : User Defined Functions, Multi-Nodes, les fonctionnalités de la version Entreprise dans la version Communautaire et plein d’autres améliorations/corrections/optimisations. Cf TimescaleDB 2.0: A multi-node, petabyte-scale, completely free relational database for time-series
- Paris Time Series #9 : Comment gérer la labellisation des séries-temporelles et la détection d’anomalies grâce à InfluxDB ? : Présentation de Julien Muller d’ezako sur la labellisation de séries temporelles et de la détection d’aonomalies en s’appuyant sur InfluxDB pour le stockage de ces données temporelles.
- InfluxData closes 2020 with exponential cloud growth, expanding user base, and big new customers : bilan 2020 pour InfluxData avec quelques chiffres sur la croissance de leur offre cloud (x13), utilisateurs du free tier InfluxCloud (x5), Répartition des (nouveaux ?) cllients (OInfluxCloud) 55% USA et 45% Europe, 450K instances OSS actives, quelques grosses références et un développement à venir en Asie/Pacifique.
- Telegraf 1.17 : version pour laquelle je découvre le processeur Starlark. Ce processeur permet de définir une fonction sur les métriques permettant par exemple de ne remonter une valeur que si elle est différente de la précédente. Cela peut économiser des données dans des systèmes contraints.
- Infographic: What happened in 2020 for SenX? : retour de SenX sur l’actualité autour de Warp 10 (mais pas que)
- Parution des premiers tutoriels FLoWS : FLoWS Basic et FLoWS vs WarpScript
- Warp 10 2.7.2 : version de maintenance.
- Alerts are real time series : et si les alertes étaient elles-mêmes des séries temporelles ? S’il était assez évident de dissocier la partie génération de l’alerte (traitement) de la partie notification, on peut aller encore plus loin en matérialisant ces données d’alertes sous la forme d’une série temporelle. Une approche intéressante qui ouvre des possiblités de traitement et d’analyses complémentaires alors que les logiciels actuels ne persistent pas souvent/longtemps cette information.
- Utilisation des séries temporelles dans le cadre du Vendéee Globe : Vitesse et amures pour le bateau de Boris Herrmann - Seaexplorer Yacht Club de Monaco avec Warp 10 et l’ensemble des données du même bateau mise à disposition : Live data from Seaexplorer - Yacht Club de Monaco. Il y a des séries temporelles plus intéressantes que d’autres ! 😉
- High Performance Sailing Monitoring for the Vendée Globe : le making-off du tweet ci-dessus et bien plus encore !
Bilan 2020 et perspectives 2021
bilan perspective cérénit timeseries bigdatahebdo influxace IoTRoutine habituelle de début d’année pour la clôture de ce 4ème exercice (déjà !).
Bilan 2020
Au global, une bonne année au regard des conditions - les objectifs sont remplis.
D’un point de vue comptable, cela donne :
| 2020 | 2019 | 2018 | 2017 | Variation n/n-1 | |
|---|---|---|---|---|---|
| Chiffre d’affaires | ~138 K€ | ~150 K€ | ~132 K€ | ~100 K€ | -8% |
| Résultat après impôts | ~8 K€ | ~13.5 K€ | ~10 K€ | ~20 K€ | -41% |
| Jours facturés | 175 | 197 | 178 | 160 | -11% |
| TJM | 789€ | 761€ | 742€ | 625€ | +3.6% |
Contrairement aux autres années, les jours facturés ne prennent plus en compte des prestatations forfaitaires (comme l’infogérance, etc) pour lesquelles je faisais un équivalent jour. J’ai ajusté les valeurs de ce tableau mais je n’ai pas mis à jour les synthèses 2019, 2018 et 2017. Cela a pour conséquence d’améliorer sensiblement le TJM.
L’épisode COVID n’a pas eu d’impact direct sur mon activité et je fais un chiffre d’affaire conforme à ce que j’avais prévu en début d’année. Clairement, je mesure ma chance d’avoir passé cette année sans encombres professionnels. J’avais dit que je passerai à 4/5 sur l’année. Dès lors je ne pouvais envisager de factuer plus de 80% des jours ouvrés et et je parviens à en factuer 77% (toujours hors prestatations forfaitaires). En faisait un TJM de 700€ et 80% des jours ouvrés, cela me donnait un chiffre d’affaires à atteindre de 128 K€. J’atteins à peu près cet objectif avec les jours facturés et je le dépasse grâce aux prestations forfaitaires. Ces prestations forfaitaires ayant sensiblement augmenté en 2020 (passage de ~10K€ à ~13K€) et même si l’une d’entre elles a généré un investissement matériel important et qui sera compensé sur les prochaines années. Cela explique principalement la chute du résultat (si on prend 2018 comme année de comparaison, pour une chiffre d’affaire et un volume de jours facturés similaire, le résultat est 20% inférieur).
Comme chaque année, j’en profite pour remercier Fabrice pour son accompagnement en tant qu’expert-comptable. Je le dis et le répête, mais avoir confiance dans son expert comptable et pouvoir compter sur lui pour apporter de bons conseils aux bons moments et être serein sur la gestion de l’entreprise, c’est indispensable - surtout en cette période. Même si je n’en ai pas bénéficié directement, les informations transmises pendant cette période sur les aides et autres mécanismes mis en place ont été très utiles.
D’un point de vue activité, c’est une bonne année en termes de contenus de missions :
- Fin de ma mission chez Saagie autour de l’installeur de leur plateforme data dans un univers kubernetes et cloud,
- Second volet chez un acteur de l’énergie pour un audit et tunning de performance pour une application Web et une API REST avec des améliorations coté infrastructure et configuration des composants pour tenir la charge escomptée.
- Un peu d’infogérance autour de kubernetes et traefik pour une petite structure en cours de développement.
- Compta-Online qui continue son développement avec une infrastructure maitrisée et stable (même si on doit améliorer un peu les choses les jours de résultats d’examens nationaux)
- Un nouveau client pour un usage série temporelles dans le monde nautique pour interfacer un logiciel utilisant InfluxDB et un autre utlisant Warp 10 - mon investissement sur les séries temporelles et en particulier Warp 10 aura payé plus vite que prévu.
- Un projet démarré depuis septembre et dont on parlera plus tard…
- et pour finir l’obtention d’un agrément Crédit Impôt Innovation pour la période 2020-2024 en liaison avec le projet évoqué ci-dessus.
Pour le reste, j’ai le plaisir de :
- contribuer au podcast BigData Hebo avec une refonte du site en prime.
- de continuer mon rôle d’InfluxAces.
- de continuer à animer le Paris Time Series Meetup : après la “pause” du premier confirnement, 4 éditions ont pu être organisées entre juillet et novembre.
- de participer aux InfluxDays Virtual Experience London avec un retour sur l’utilisation de Telegraf dans le cadre d’un monitoring kubernetes
- voir mes efforts sur Warp 10 être récompensés par de nouvelles missions mais aussi par le cadeau envoyé par l’équipe de SenX pour parler de leur produit dans le BigData Hebo, sur le blog ou aux éditions #1 et #5 du Paris Time Series Meetup.
Petite déception toutefois sur la partie développement, où je n’ai pas pu me mettre sérieusement à Go ou Rust.
Enfin, je m’étais posé la question du rôle social d’une entreprise dans notre société en temps de COVID. Ma contribution a certes été modeste dans la limite de ce qui était autorisé par la loi d’une part et ne sachant pas trop comment se finirait l’année d’autre part. Je pense que je vais continuer dans cette voie et voir quel(s) projet(s) je pourrai soutenir en 2021. Content d’avoir contribué au projet Makair et de voir comment il évolue en tous cas.
Perspectives 2021
L’année commence bien avec la suite de la mission Warp 10/InfluxDB dans le monde nautique mentionnée précédemment. A celà s’ajoute une autre mission de conseil autour des usages de séries temporelles pour un autre acteur de l’énergie. J’ai du décliner un troisième appel d’offre sur un sujet similaire du fait de mes engagements actuels, mais j’espère qu’il y aura d’autres projets similaires.
Ayant aussi découvert le monde de l’impression 3D durant le premier confinement et plus récemment à jouer avec des cartes micro:bit (et peut être bientôt des ESP32), j’irais bien voir du coté de l’IoT et donner une dimension “plus industrielle” à mes usages de séries temporelles. Sortir des usages de monitoring serveur pour les séries temporelles et aller vers des usages plus industriels ou métiers est clairement intéressant. Osons le terme: direction l’industrie 4.0 !
Pour rebondir sur cette dimension usage, j’ambitionne pour le Paris Time Series Meetup d’avoir un focus usage plus important et avoir des retours d’expérience (et moins de présentation produit par des éditeurs).
Sur BigData Hebo, nous venons de lancer les brèves afin de mettre en avant les contributions des membres de la communauté. A suivre !
Pour le développement en Go et Rust, le premier devrait voir le jour dans l’année de façon assez certaine, c’est plus incertain pour le second.
Et enfin, pour le projet commencé en septembre et dont je ne peux pas encore parler, j’espère pouvoir lever le voile prochainement !
Si certains sujets vous interpellent ou si vous avez des contacts à me suggérer, n’hésitez pas à me contacter.
AIM45
timeseries warp10 influxdbContexte
La société AIM45 est éditrice de la plateforme web M2 pour la course au large. Elle utilise la solution Warp 10 pour stocker ses séries temporelles. Pour étoffer son offre, elle doit intégrer les données d’un partenaire qui utilise quant à lui la solution InfluxDB. AIM45 nous a sollicité pour les accompagner dans cette intégration.
Notre réponse
- Expertise sur la plateforme InfluxDB
- Bonne connaissance de la plateforem Warp 10
- Accompagnement des équipes internes dans la définition des scénarios d’intégration avec le partenaire
- Accompagnement des équipes internes pour maitriser les concepts et les différences entre les produits Warp 10 et InfluxDB pour une meilleure appréhension du sujet
- Participation aux réunions avec le partenaire pour faciliter les échanges entre les équipes, expliciter les différences entre les produits et contribuer aux échanges sur la définition de la solution finale.
- Accompagnement à la carte en fonction des besoins des équipes AIM45.
Bénéfices pour l’éditeur
- Expertise sur les solutions de séries temporelles Warp 10 et InfluxDB
- Prise en main facilitée et accélérée pour les équipes internes sur InfluxDB
- Facilitation pour les échanges avec le partenaire.
- Expertise en termes d’architure système et applicative.
Bénéfices pour CérénIT
- Poursuite des projets sur les séries temporelles avec un nouvel usage : la série temporelle dans le monde de la course au large
