Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Web, Ops, Data et Time Series - Octobre 2021
postgresql timeseries bi datatask dbt metabase singer timescale influxdb quasardb vector nomad clever-cloud yield pivot warp10 flows vscode kapacitor chronograf telegraf clickhouseBI
- Smart Data Analytics : Exploration des données comptables : pour changer des outils de séries temporelles, je me suis livré au même exercice d’ingestion et de traitement des FEC avec la Smart Data Analytics (SDA) de DataTask. Basée sur singer, dbt et metabase, la SDA permet via une Web UI de définir son flow d’ingestion et de transformation. Une fois ces transformations réalisées, il ne reste plus qu’à explorer les données avec Metabase et produire ses dashboards.
Code
- vscode.dev : l’ère de l’IDE dans le navigateur continue après gitpod ou githuab codspaces, c’est au tour de vscode.dev qui permet d’avoir une IDE dans son navigateur. Affaire à suivre…
Observabilité et monitoring
- Vector 0.17.0, Vector 0.17.1, Vector 0.17.2 & Vector 0.17.3 avec l’adaptive concurrency qui permet de gérer le “back pressure” pour les destinations accessibles via HTTP, et pour les sources une gestion simplifiée pour le décodage d’éléments et leur “framing”.
- Vector Remap Language : extension Vector pour VSCode
Orchestration & conteneurs
- damon, un dashboard pour nomad en ligne de commande.
- Announcing HashiCorp Nomad 1.2 Beta : ajout des “System Batch” qui sont des (petits) jobs globaux au cluster, des améliorations de l’interface et l’ajout des Nomad Pack, une sorte de catalogue d’applications prêtes à être déployées dans votre cluster.
SQL
- PostgreSQL 14 Released! ou en français PostgreSQL 14 ou un thread twitter pour découvrir les nouveautés de cette version : amélioration du support de JSONB, type multirange, fonctions autour des dates, etc.
Sécurité
- Popular NPM library hijacked to install password-stealers, miners : analyse de la librairie ua-parser-js compromise dans ses version 0.7.29, 0.8.0 et 1.0.0 avec l’ajout un mining de crypto et un voleur de mot de passes. Le passage en version 0.7.30 / 0.8.1 et 1.0.1 est à faire dans les plus brefs délais. Pour les dépendances indirectes, il est possible d’ajouter dans son fichier
package.json:"resolutions": { "ua-parser-js": "^0.7.30" }via Security issue: compromised npm packages of ua-parser-js (0.7.29, 0.8.0, 1.0.0) - Questions about deprecated npm package ua-parser-js
Time Series
Annonces & Produits :
- InfluxDB OSS 2.0.9
- InfluxDB OSS 1.8.10
- InfluxDB Entreprise 1.9.5 - avec des fixes sur l’utilisation mémoire et les index TSI :sourire_narquois:
- Telegraf 1.20.2 (avec un fix de memory leak sur le parser influx notamment)
- Kapacitor 1.6.2
- QuasarDB 3.10.0 Stable Released : Nouvelle version de la base QuasarDB avec son lot d’améliorations et de corrections ; pour une présentation de QuasarDB, voir Time Series France - Edition 2 - QuasarDB, les séries temporelles appliquées à la finance & aux transports.
- Announcing the new Timescale Cloud, and a new vision for the future of database services in the cloud et le thread twitter associé : Timescale partage sa vision de ce que doit être une base managée et de la developer experience qu’elle doit offrir. Timescale indique également avoir 3 millions de bases actives par mois (très loin devant les derniers chiffres d’InfluxData ; environ 6 fois mais faut-il encore s’accorder ce qu’est une base: une instance ? un schema ?). Timescale annonce les principes de Timescale Cloud (ex Timescale Forge) qui veut être simple, scalable, connu et flexible. Les deux premiers sont inspirés du monde serverless (découplage compute/storage, auto scalabilité, etc) et les deux derniers du monde de la base de données managiées (du SQL plutôt qu’une API et le fait de bénéficier de tout l’écosystème associé). 10 annonces sont prévues durant le mois d’octobre, quelques-une sont déjà en fin de billet.
- Announcing Time Series on Clever Cloud, with TARDIS, Clever Cloud lance son offre Time Series as a Service, basée sur Warp 10 et avec une compatiblité InfluxQL, PromQL, etc.
- FLoWS ♡ VS Code WarpScript extension 2.0.0 - SenX : nouvelle version de l’extension Warp 10 pour VSCode avec le support de FLoWS et Discovery.
- October 2021: Warp 10 release 2.9.0 : nouvelles capacités (CAPABILITY) autour de fetch & exec, GUARD doit éviter les fuites de données sensibles, ajout support de KML/GML en plus des habituels ajouts de fonctions, améliorations de fonctions et divers corrections de bugs
Articles & Vidéos :
- How NOT to Analyze Time Series : article sympathique sur les erreurs de jeunesse d’analyse de séries temporelles.
- Penser le monde en time series, la nouvelle solution à vos problèmes d’analyse (M.Herberts/Q.Adam) : conférence à DevoxxFR de Quentin et Mathias pour une introduction aux séries temporelles. Intéressant même si un peu au lance pierre sur la fin.
- Les TSDB ne sont pas toujours la bonne solution : approche db ou plateforme ? approche table ou séries ? faible ou forte profondeur d’analyse ? Revue de quelques critères pouvant impacter la façon dont vous manipulez vos séries temporelles.
- TL;DR InfluxDB Tech Tips: Multiple Aggregations with yield() in Flux :
yield()peut être très pratique pour débugguer son code flux mais permet aussi de récupérer le résultat de plusieurs requêtes pour faire des aggrégations - How to Pivot Your Data in Flux: Working with Columnar Data : InfluxDB, contrairement à une RDBMS, stocke ses valeurs via une approche colonne, qui peut dérouter dans un premier temps. Le billet montre comment utiliser
pivot()pour revenir à des manipulations en ligne. - Function pipelines: Building functional programming into PostgreSQL using custom operators : quand un Query Langage (ici SQL) ne suffit plus pour manipuler les séries temporelles, arrivent les fonctions et les opérateurs.
- What is ClickHouse, how does it compare to PostgreSQL and TimescaleDB, and how does it perform for time-series data? : un benchmark très complet pour se faire une opinion et même si ClickHouse n’est pas une TSDB.
Pour le retour sur les InfluxDays North America qui ont lieu cette semaine, ce sera pour un prochain billet ou édition du Time Series France Meetup
n8n & Warp 10 - Automatisez vos manipulations de séries temporelles
n8n automation warp10 timeseries workflowIl y a quelques temps et sachant que j’utilisais n8n pour automatiser la génération des brèves du BigData Hebdo, Mathias m’a demandé s’il était possible de faire la même chose entre n8n et Warp 10 qu’avec node-red et Warp 10.
La réponse est oui mais voyons comment faire cela.
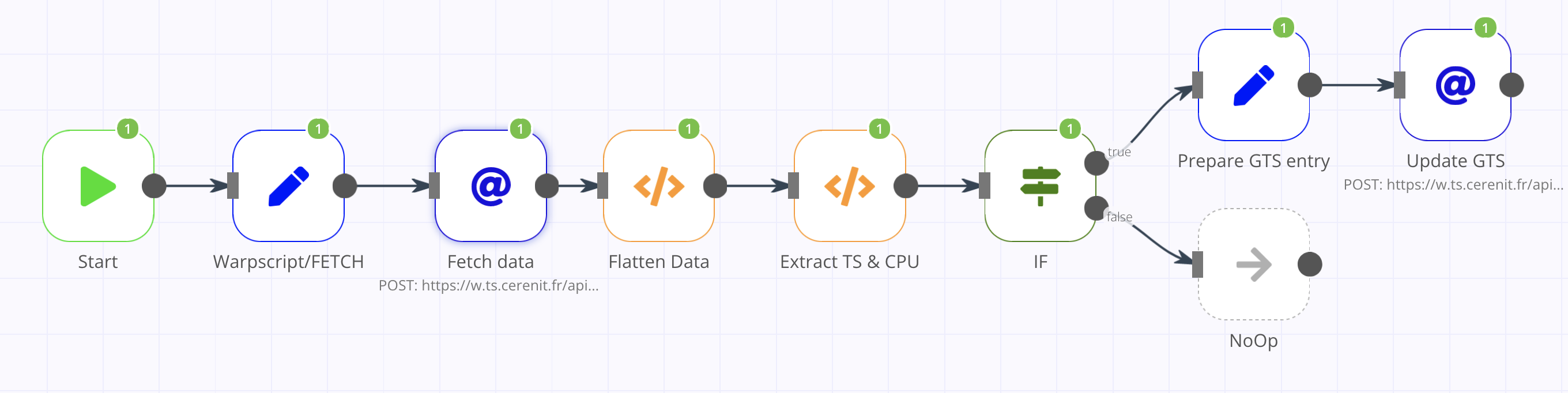
Pour ceux qui ne connaissent pas n8n, c’est un clone open source (sous licence fair-code) à des services comme Zapier ou IFTTT. Il permet d’automatiser des processus via la création de workflows. Ces workflows sont composés d’étapes et d’actions. n8n dispose d’un grand nombre de connecteurs vers les différents services existants, des opérateurs génériques (faire un appel http, appliquer une fonction), des opérateurs logiques (si, etc), des opérateurs de transformation de données, etc. Chacun de ces éléments est implémenté via une node. A chaque étape du workflow, une node est instanciée puis paramétrée. Les nodes peuvent être reliées entre-elles et la sortie d’une node peut alimenter la suivante.
Le workflow se veut basique et va être le suivant :
- Récupération d’une entrée de monitoring CPU dans Warp 10
- Si la valeur est supérieure ou égale à 90%, alors création d’une entrée dans une série dédiée à cet effet.
Ce n’est pas le workflow le plus passionnant du monde, mais cela permet de faire deux appels à l’API HTTP de Warp 10 :
- Le premier permet de tester l’exécution de code WarpScript via l’API
/api/v0/exec; vu le code, j’aurais pu passer par/api/V0/fetchmais cela me permet de tester l’exécution de code WarpScript. - Le second utilisera l’API
/api/v0/updatepour insérer une donnée dans une série. Cela permet de tester le passage du token d’authentification via un header.
Pour commencer le workflow, la donnée de départ est la valeur en pourcentage du métrique “CPU Idle” d’un de mes serveurs.
En WarpScript, cela donne:
'<readToken>' 'readToken' STORE
[ $readToken 'crnt-ovh.cpu.usage_idle' { "host" "crnt-d10-gitlab" "cpu" "cpu-total" } NOW -1 ] FETCH
Et la réponse :
[
[{
"c": "crnt-ovh.cpu.usage_idle",
"l": {
"host": "crnt-d10-gitlab",
"cpu": "cpu-total",
"source": "telegraf",
".app": "io.warp10.bootstrap"
},
"a": {},
"la": 0,
"v": [
[1634505650000000, 91.675025]
]
}]
]
n8n dispose d’une node HTTP Request, qui comme son nom l’indique permet de faire des requêtes HTTP vers un serveur distant. Toutefois, il n’est pas possible de passer notre code WarpScript directement dans l’appel HTTP. Il faut créer un objet avec le code WarpScript et passer ensuite l’objet créé et le nom de la propriété contenant le code WarpScript à la node HTTP Request.
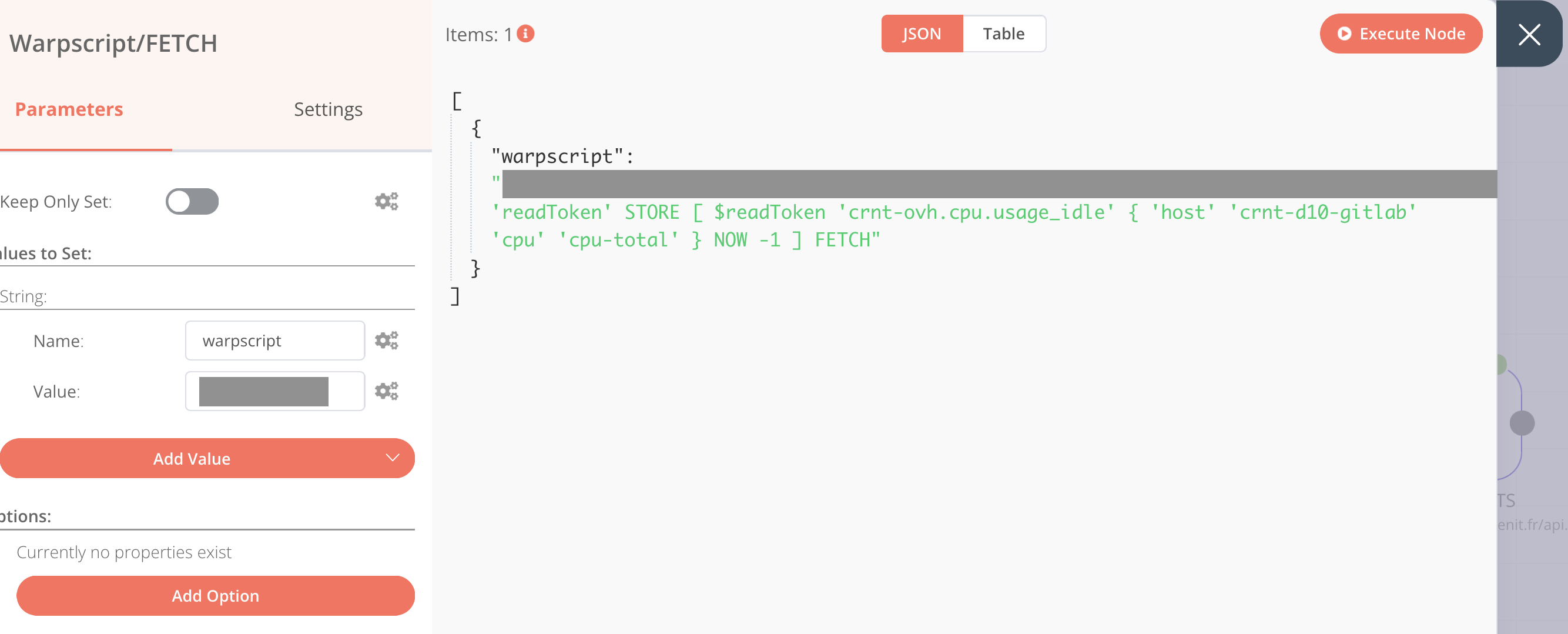
Pour stocker le code WarpScript dans un objet, il faut utiliser la node Set. Une fois la node Set ajoutée dans le workflow, aller dans Parameters > Add Value > Type: String
Saisir:
- Name: warpscript
- Value: le code WarpScript ci-dessus
En cliquant sur “Execute Node”, on peut valider la variable (la partie grisée étant mon token) :
On peut maintenant ajouter une node HTTP Request dans le workflow et la relier à la node Set nouvellement créée. Ainsi, la node HTTP Request aura directement accès au résultat de la node Set.
Pour les ajustements à faire :
- Parameters :
- Request Method : POST
- URL :
http://url.de.votre.instance.warp.10/api/v0/exec - Activer la case JSON/RAW Parameters
- Options :
- Add Option > Mime Type : text/plain
- Add Option > Body Content Type : RAW/Custom
- Body Parameters > Add Expression > Current Node > Input Data > JSON > warpscript (les colonnes de droites doivent se remplir avec la clé en haut et la valeur en dessous ; cliquer sur la croix pour revenir à l’écran précédent)
En cliquant sur “Execute Node”, le résultat de la requête est visible (la partie grisée étant un bout de mon token) :
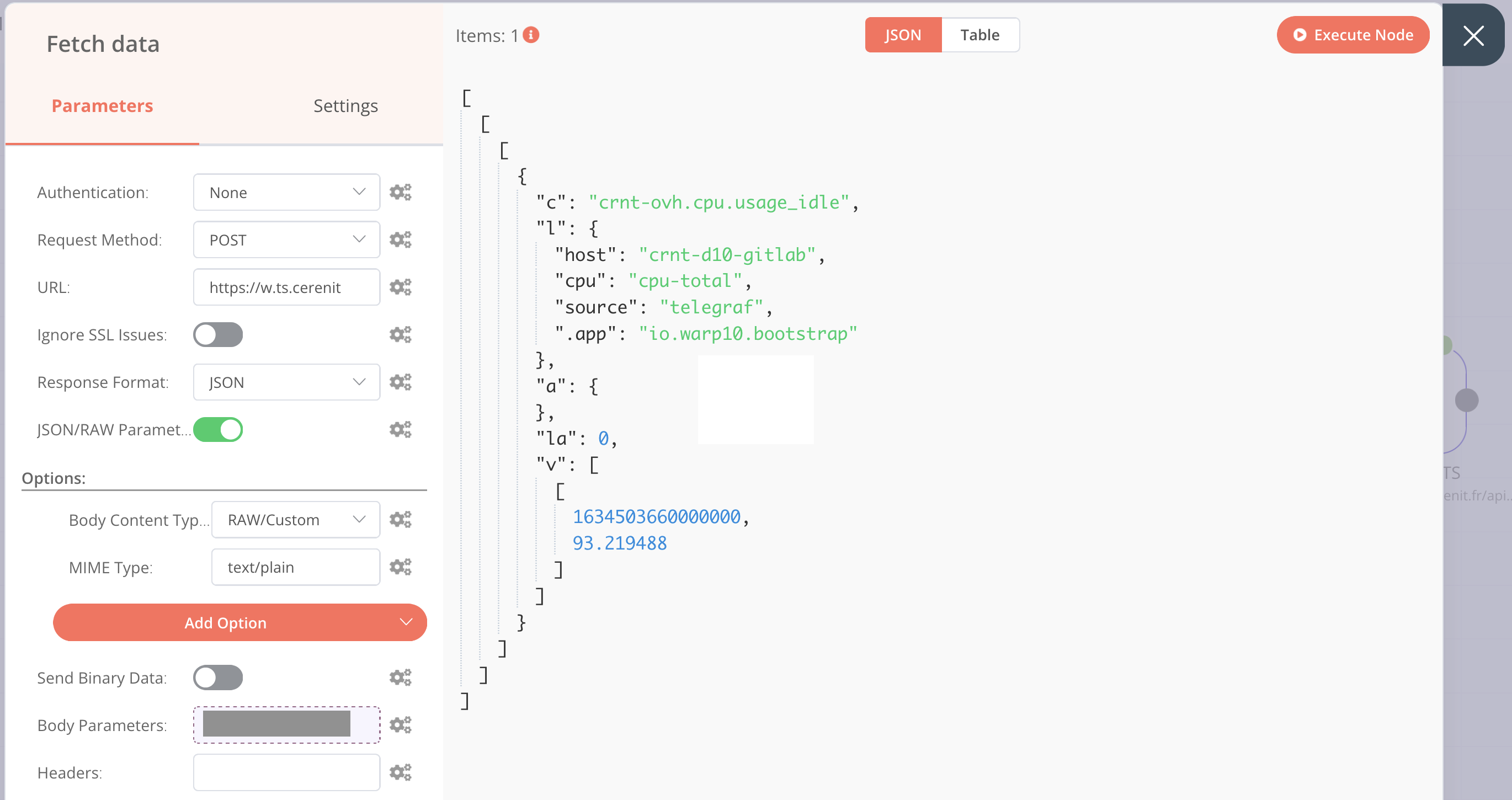
On retrouve notre objet JSON mais il est imbriqué dans des Array Javascript, on va applanir tout ça et extraire le timestamp et la valeur du cpu via l’ajout de deux nodes Function que l’on relie à la node HTTP Request. La node Function permet d’exécuter du code javascript sur les données et de réaliser des transformations que l’on ne peut pas forcément faire avec les autres nodes. Cela n’étant pas le coeur du sujet, cela ne sera pas détaillé.
A l’issue des deux exécutions, les données sont réduites à ce qui suit :
[{
"ts": 1634503660000000,
"cpu": 93.219488
}]
La node IF ne sera pas détaillée non plus ; elle sert juste à introduire un semblant de logique dans le workflow. En l’occurence, si la valeur de “cpu” >= 90, alors le test est considéré comme vrai et faux sinon. Dans le cas où c’est faux, une node noOp a été ajoutée pour matérialiser la fin du workflow.
Dans le cas où le test est vrai (valeur de “cpu” >= 90), on veut alors insérer le timestamp et la valeur dans une autre série sur une instance Warp 10. Comme précédemment, cela va se faire en deux fois:
- Préparation de la donnée au format GTS Input Format et mise à disposition sous la forme d’une propriété
- Exécution de l’appel HTTP.
On ajoute une node Set, ensuite dans Parameters > Add Value > Type: String
Saisir:
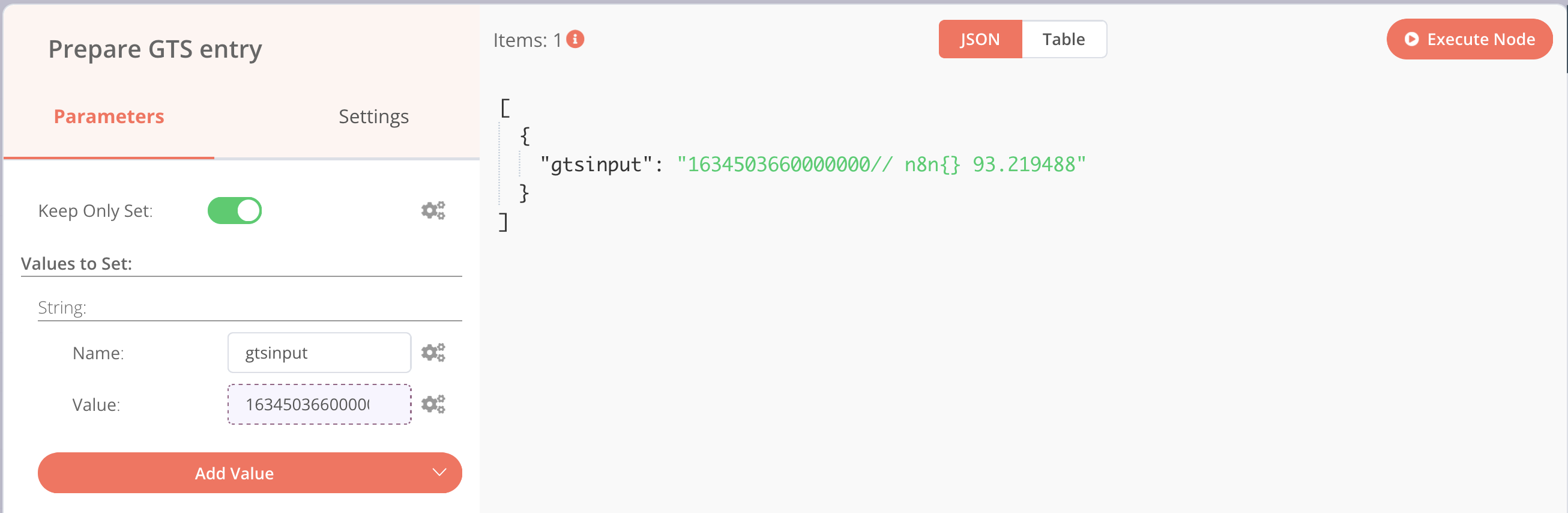
- Name: gtsinput
- Value > Add Expression et dans la partie expression, on met:
{{$json["ts"]}}// n8n{} {{$json["cpu"]}}
Ce qui nous donne l’écran suivant :
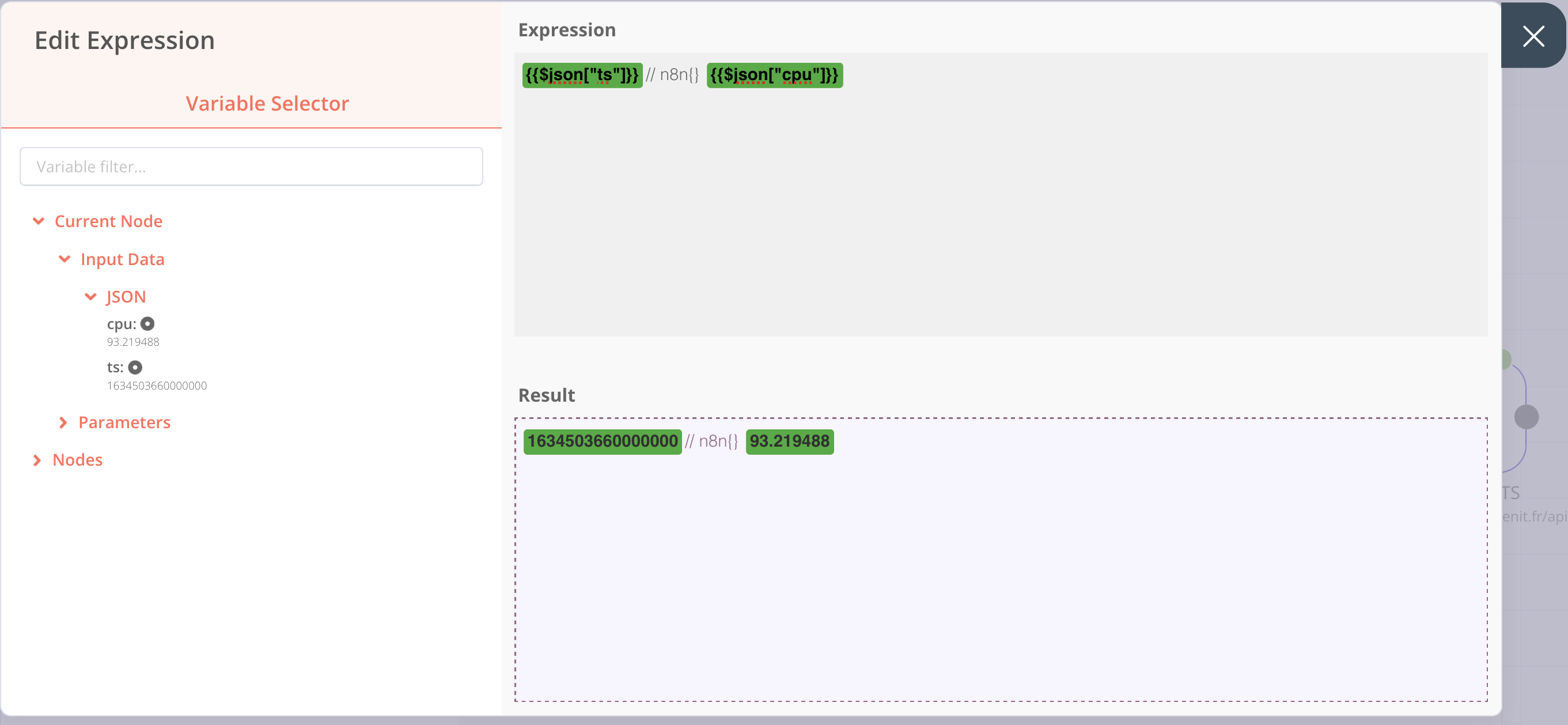
On revient à l’écran précédent en cliquant sur la croix à droite et en exécutant la node, on obtient :
Ensuite, il faut ajouter une nouvelle node HTTP Request avec le paramétrage suivant :
- Parameters :
- Authentication > Header Auth
- Request Method : POST
- URL :
http://url.de.votre.instance.warp.10/api/v0/update - Activer la case JSON/RAW Parameters
- Options :
- Add Option > Mime Type : text/plain
- Add Option > Body Content Type : RAW/Custom
- Add Option > Full Response et activer là pour voir la réponse complète de votre instance Warp 10
- Body Parameters > Add Expression > Current Node > Input Data > JSON > gtsinput (les colonnes de droites doivent se remplir avec la clé en haut et la valeur en dessous ; cliquer sur la croix pour revenir à l’écran précédent)
En haut du menu de gauche, une section “Credentials” est apparue ; dans la liste déroulante, cliquer sur “Create new” et remplissez le formulaire de la façon suivante:
- Name: X-Warp10-Token
- Value : votre token Warp 10 avec des droits d’écriture
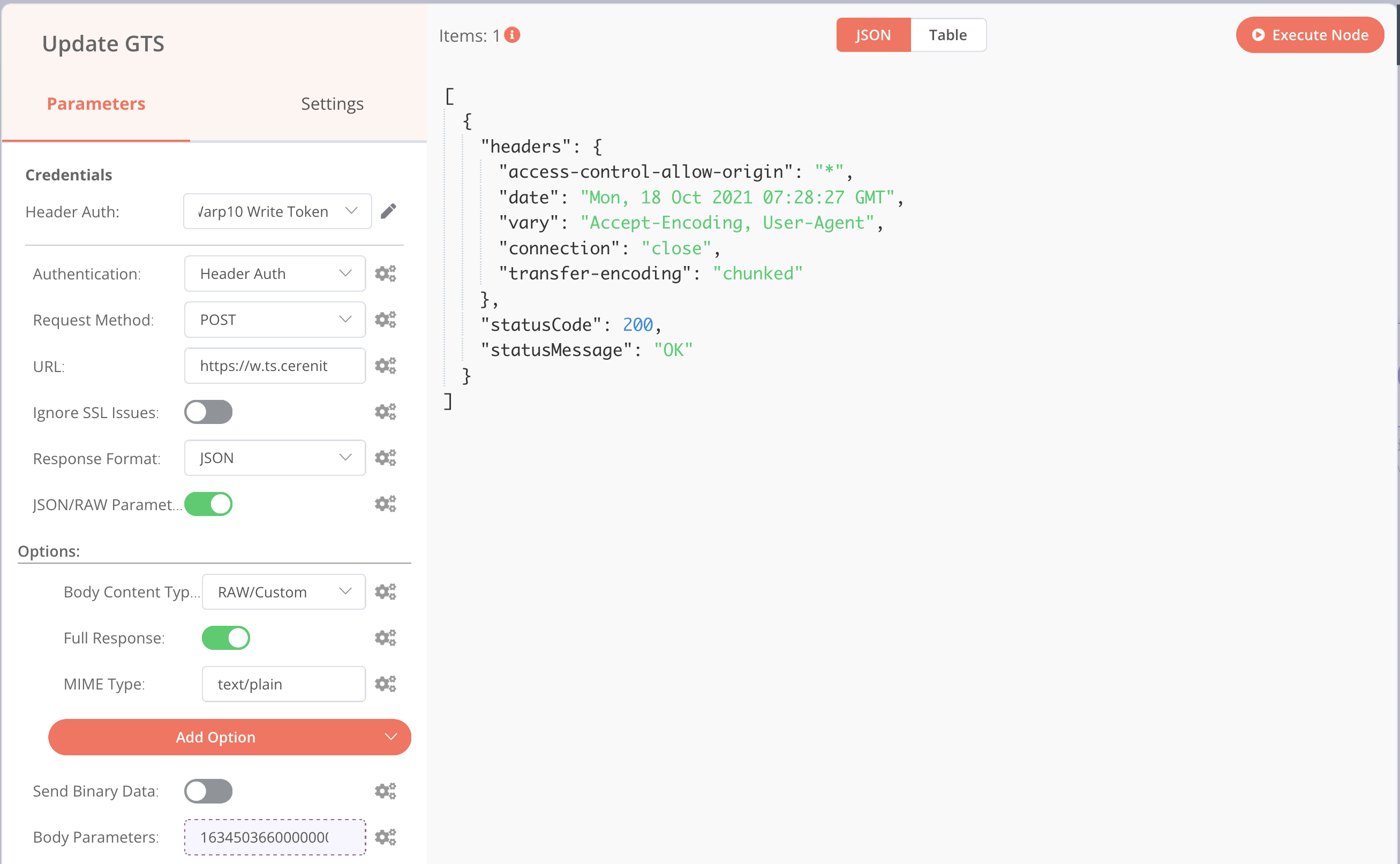
Revener ensuite dans votre node HTTP Request dont on peut lancer l’exécution et on obtient :
Si je vais ensuite voir le contenu de ma série n8n :
'<readToken>' 'readToken' STORE
[ $readToken 'n8n' {} NOW -100 ] FETCH
J’obtiens comme réponse :
[
[{
"c": "n8n",
"l": {
".app": "io.warp10.bootstrap"
},
"a": {},
"la": 0,
"v": [
[1634503660000000, 93.219488],
[1634502790000000, 94.808468],
[1634501690000000, 93.7751],
[1634501550000000, 91.741742],
[1634478300000000, 92.774711]
]
}]
]
Avec une entrée pour chaque exécution du workflow sous réserve d’avoir un “CPU idle” >= 90%.
En conclusion, nous pouvons retenir que :
- Il est facile d’intégrer Warp 10 dans un workflow n8n grâce à l’API HTTP de Warp 10 et la node HTTP Request de n8n
- Pour interagir avec Warp 10, il faut d’abord créer un objet portant le code WarpScript ou les donées au format GTS Input pour l’envoyer ensuite à Warp 10 via la node HTTP Request
- Même si cela n’a pas été détaillé, il est possible de manipuler les données issues de Warp 10 ou de préparer des données à destination de Warp 10.
Le workflow était très basique pour permettre de montrer rapidement cette intégration. Des workflows plus complexes et riches sont laissés à votre imagination :
- sur la base d’un événement avec la node Webhook : insertion de données ou lancement d’une analyse suite à un événement, etc.
- sur la base d’une tache planifiée avec la node Cron : analyse de données, etc
- ou depuis Warp 10, on peut appeler n8n en utilisant HTTP, URLFETCH ou WEBCALL pour lancer l’exécution d’un workflow ou récupérer le résultat d’un workflow.
InfluxDB et les alertes : Tasks, Checks et Notifications
influxdb timeseries influxdata task flux check notifications kapacitor alertesCérénIT vient de finaliser la migration pour un de ses clients d’un socle InfluxDB/Chronograf/Kapacitor vers InfluxDB2. Ce billet est l’occasion de revenir sur la partie alerting et de la migration de Kapacitor vers des alertes dans InfluxDB2.
Dans le cadre du socle InfluxDB/Chronograf/Kapacitor, le fonctionnement était le suivant :
- Les utilisateurs créent une alerte via l’application métier en définissant un à plusieurs critères d’alertes ; ex: est-ce que l’unité est opérationnelle et est-ce que l’humidité est supérieure à tel taux ou la température supérieure à telle valeur.
- L’application métier traduisait l’alerte en TickScript et enregistrait l’alerte auprès de Kapacitor via son API HTTP
- Kapacitor, en mode streaming, évalue si l’alerte doit être levée ou pas au fur et à mesure de l’arrivée des données
- En cas de seuil franchi, Kapacitor envoie un message à l’application métier via l’API HTTP de cette dernière.
- L’application métier envoie ensuite un mail et/ou un SMS à l’auteur de l’alerte.
Avant d’envisager la migration InfluxDB2, un point de vocabulaire :
- une alerte est globalement composée d’un “check”, d’un endpoint de notiifcation et d’une règle de notification.
- un check est une task simplifiée. Elle permet de définir une requête mono critère, les niveaux de seuils associés (ok, crit, warn, etc) et sa fréquence d’exécution.
- une task est codée flux
- un endpoint de notification : service vers lequel sera envoyé l’alerte: slack, http, etc.
- une règle de notification : les conditions de notifications (ex je passe à un état critique), le check associé, la fréquence d’exécution, le message de notification et le endpoint de notification à utiliser.
Avec la migration InfluxDB2, nous avons voulu maintenir le même mécanisme. Toutefois :
- Les tasks en Flux ne fonctionnent pas en mode streaming, mais uniquement en mode batch et avec une certaine fréquence
- Les checks sont mono-critères et pas multi-critères
Heureusement, la documentation mentionne la possibilité de faire des “custom checks” et un billet très détaillé intitulé “InfluxDB’s Checks and Notifications System” permet de mieux comprendre ce qu’il est possible de faire et donne quelques exemples de code.
Dès lors, il s’agit de :
- développer une tâche “tout en un”, contenant l’ensemble de la logique de l’alerte,
- de conserver un historique des alertes pour permettre d’assurer un suivi des alertes pour l’équipe en charge du projet depuis InfluxDB
- d’être en mesure de notifier l’application métier via son API HTTP
Pour se faire, nous allons nous appuyer sur les mécanismes mis à disposition par Influxdata, à savoir les fonctions monitor.check(), monitor.from() et monitor.notify() et les mécanismes induits.
C’est ce que nous allons voir maintenant :
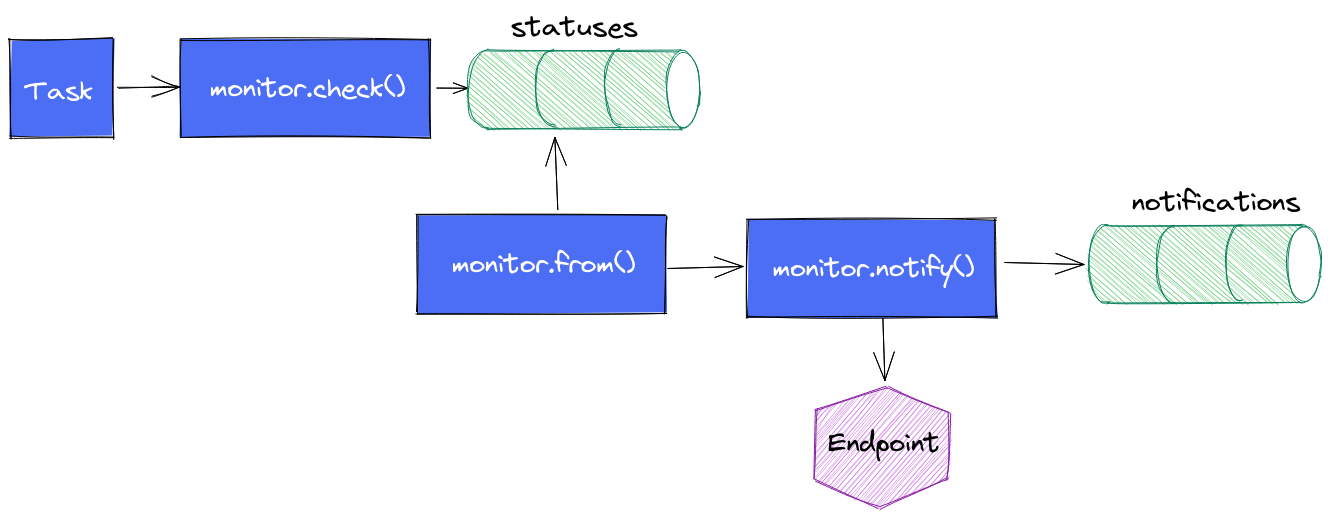
Le cycle de vie d’une alerte est le suivant :
- La task contient une requête en flux plus ou moins complexe en fonction de votre besoin ; ex: quelle est la valeur de la temperature du boitier X depuis la dernière exécution ?
- On appelle
monitor.check()en définissant les informations d’identification du check, le type de check que l’on utilise (threshold, deadman, custom), les différents seuils dont on a besoin, le message à envoyer au endpoint, les données issues de la requête flux. monitor.check()va alors stocker l’ensemble de ces données dans un measurementstatusesdans le bucket_monitoringet il s’arrête là.monitor.from()prend le relais, regarde s’il y a de nouveaux status depuis sa dernière exécution et en fonction des règles de notifications qui ont été définies, il va passer le relaismonitor.notify().monitor.notify()enverra une notification si la règle est validée et il insérera une entrée dans le measurementnotificationsdu bucket_monitoring
Une première version des alertes ont été implémentées sur cette logique. Des dashboards ont été réalisés pour suivre les status et les notifications. Cela fonctionne, pas de soucis ou presque.
Il se peut qu’il y ait un délai entre le moment où l’insertion issue du monitor.check() se fait et le moment où le monitor.from() s’exécute. Si monitor.from() fait sa requête avant l’insertion de données, alors l’alerte ne sera pas immédiatement levée. Elle sera levée à la prochaine exécution de la task, ce qui peut être problématique dans certains cas. Pour une tâche qui s’exécute toutes les minutes, cela ne se voit pas ou presque. Pour une tâche toutes les 5 minutes, ça commence à se voir.
Une version intermédiare de la task est alors née : une fois le monitor.check() exécuté, nous faisons appel à monitor.notify() pour envoyer le message vers le endpoint.
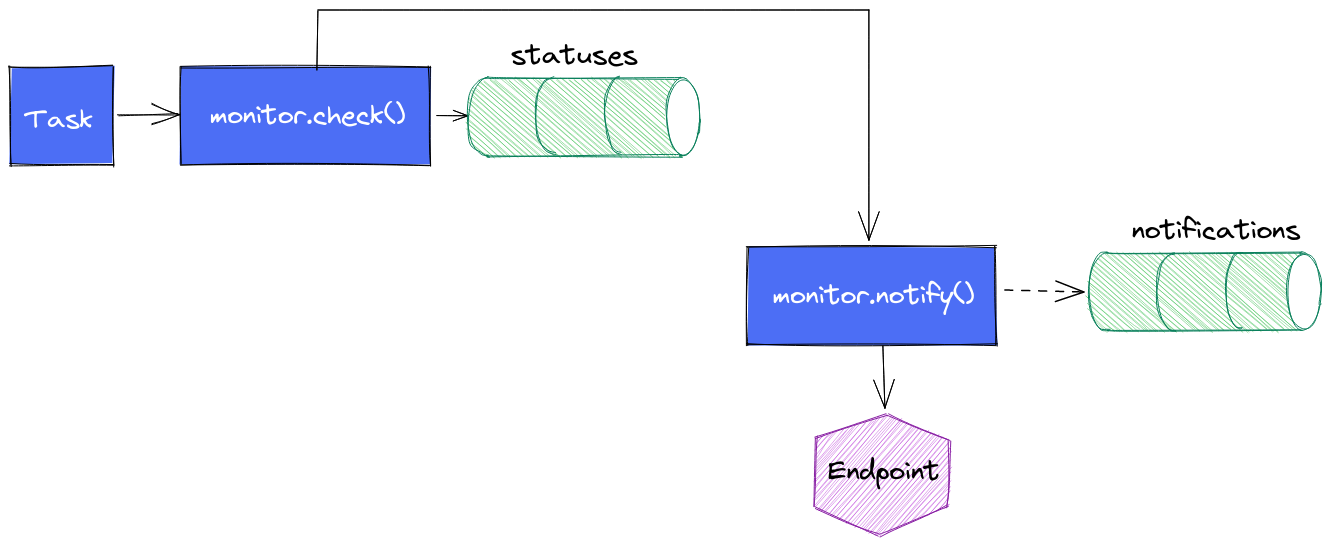
Avantage :
- la notification se déclenche sans délais
Inconvénients :
- cela ne remplit pas le measurement
notificationsde la même façon que précédemment (d’où les pointillés) vu que les données insérées dans le measurementstatusesn’existent pas encore. On perd la visibilité sur les notifications envoyées (mais on a toujours le suivi des statuts ; nous supposons que si on a le statut, alors on sait si la notification a été envoyée) - cela aboutit à un peu de duplication de code sur la gestion des seuils et des messages.
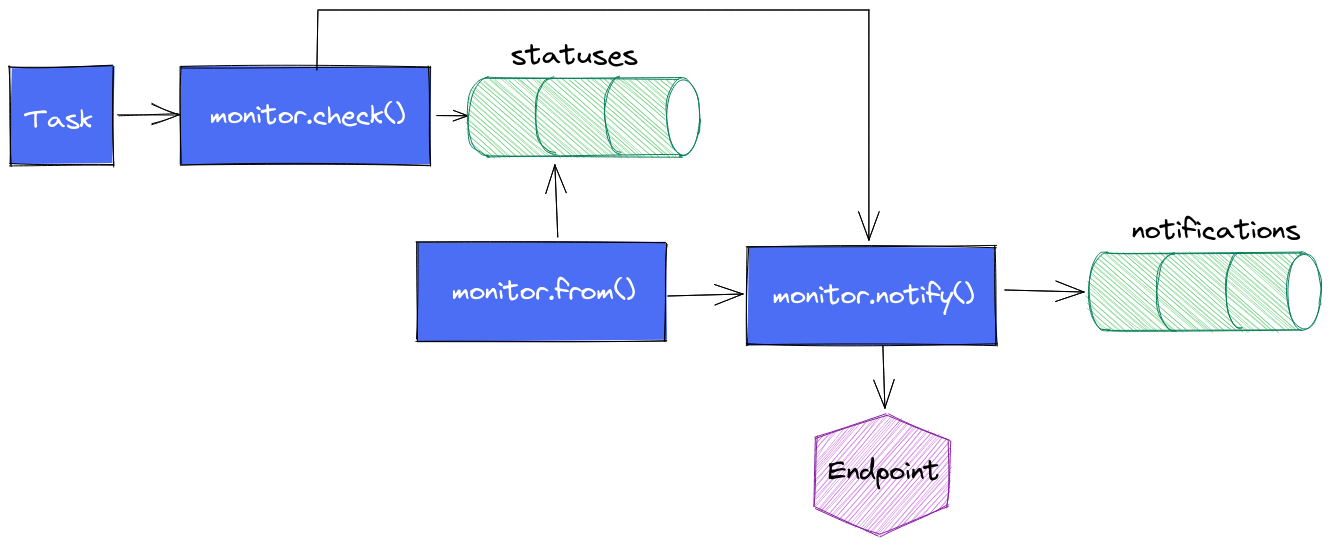
Une variante non essayée à ce stade : elle consiste à faire cette notification au plus tôt mais de conserver le mécanisme de monitor.from() + monitor.notify() pour avoir le measurement notifications correctement mise à jour. A voir si les alertes ne sont pas perturbées par ce double appel à monitor.notify(). Dans le cas présent, c’est l’application métier qui envoie les alertes après que la task InfluxDB ait appelé son API HTTP. Si chaque monitor.notify() en vient à lever une alerte, cela est sans impact pour l’utilisateur. En effet, une fois qu’une alerte est levée, elle est considérée comme levée tant qu’elle n’est pas acquittée. Donc même si la task provoque 2 appels, seul le premier lévera l’alerte et la seconde ne fera rien de plus.
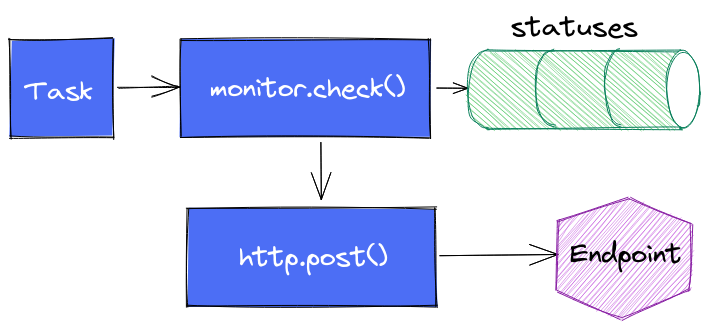
Enfin dernière variante (testée) : s’affranchir complètement de monitor.notify() pour faire directement appel à http.endpoint() et http.post() et faire complètement l’impasse sur le suivi dans notifications.
Tout est une histoire de compromis.
En conclusion, nous pouvons retenir que :
- Une alerte est composée d’un check, d’un endpoint de notification et d’une règle de notification
- En 2.0, le principe est que les alertes sont des séries temporelles via le bucket
_monitoringet les measurementsstatusesetnotifications. - Toute personne s’intéressant au sujet doit lire au préalable InfluxDB’s Checks and Notifications System pour bien comprendre les concepts et les rouages.
- Via la UI, les alertes (checks) sont assez basiques (requête monocritère)
- Il est possible de faire des “custom checks” via des tasks en flux
- Les fonctions du package monitor permettent de gérer des alertes
- Les exécutions dans la même task (ou dans des tasks concomittentes) de
monitor.check()etmonitor.from()peuvent conduire à des décalages de levées d’alertes
InfluxDB, shard, shard duration et retention policies
influxdb timeseries influxdata shard shard duration retention policy shard groupCérénIT a été contacté pour mener l’audit d’une instance InfluxDB 1.8 OSS utilisée dans un projet IoT lié à l’énergie. L’audit avait plusieurs objectifs :
- Comprendre la consommation mémoire de l’instance (48Go / 64Go de la VM)
- Faire un état de santé de la plateforme et estimer sa capacité à stocker et procésser des données supplémentaires dans le cadre de l’ouverture d’une application métier
- Expliquer la raison des problèmes observés par le passé et évaluer les solutions apportées
- Etablir des recommendations et éventuellement les implémenter.
De l’audit, on notera que :
- L’instance contient ~35.000 shards / ~36.000 tsm files pour environ 200 bases permanentes et des dizaines de bases éphémères permettant de calculer des indicateurs ou de recalculer des historiques de données suite à des changements de paramètres de l’application métier (plusieurs dizaines de milliers de bases temporaires par semaine, avec des profondeurs de données variables)
- Les recommendations pour InfluxDB Enterprise sont d’avoir 30/40 bases par data nodes et 1.000 shards par data node
Avant d’aller plus loin, précisons un peu cette notion de shard et les notions liées pour bien appréhender le sujet :
- Une instance InfluxDB peut contenir 1 à n bases de données (database),
- A chaque base de données InfluxDB, on peut définir une “retention policy” qui est la période maximale de conservation des données. Avec une retention policy de 7 jours par ex, seules les données des 7 derniers jours sont conservées. Les données les plus vieilles seront alors supprimées au fur et à mesure que les nouvelles données arriveront via un mécanisme de compaction.
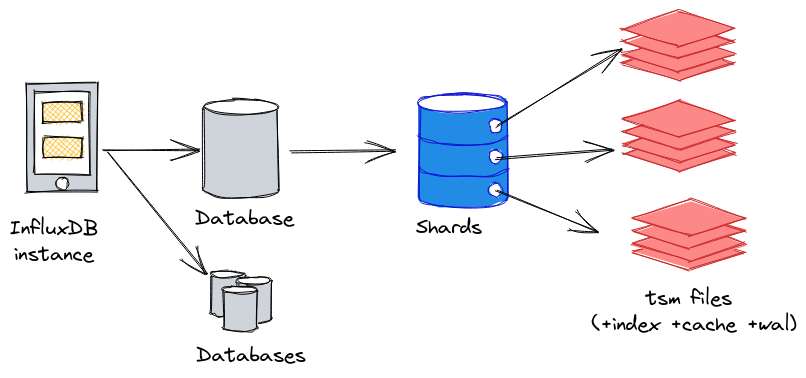
- Les données d’une base de donneés InfluxDB sont réparties au sein de shards au niveau stockage ; chaque shard comprend les données sur une période de temps donnée. Si une base de données a une retention policy d’une semaine, alors chaque shard contiendra 1 jour de données. Nous aurons donc 7 shards pour cette base de données. Ce délai est appelé shard duration.
- Au sein de chaque shard, nous allons retrouver les données sous la forme d’un ou plusieurs fichiers TSM, le fichier d’index pour le shard, ainsi que le fichier de WAL et de cache.
Nous pouvons représenter la logique instance > database > shard(s) > tsm files de la façon suivante :
Par défaut, InfluxDB applique les shard duration suivantes en fonction des retention policy :
| Retention policy | Default shard duration |
|---|---|
| <= 2 days | 1 hour |
| <= 6 months | 1 day |
| > 6 months | 7 days |
Source : InfluxData - Shard group duration
Dès lors, une base de données avec une retention policy infinie aura une shard duration de 7 jours. Ainsi, si cette base contient 10 ans d’hisorique (soit 10 * 52 semaines = 520 semaines), elle contiendra 520 shards.
Du coup, InfluxData recommande les valeurs suivantes (au moins en 1.x ; on peut supposer que cela reste valable en 2.x):
| Retention policy | Default shard duration |
|---|---|
| <= 1 day | 6 hour |
| <= 7 days | 1 day |
| <= 3 months | 7 days |
| > 3 months | 30 days |
| infinite | >= 52 weeks |
Source : Shard group duration recommendations
Selon cette perspective, la base de données avec 10 ans d’historique ne contiendra plus 520 shards mais 10 shards en prenant une shard duration de 52 semaines. L’écart entre la valeur par défaut et la valeur recommandée est plus que significatif.
Pour bien dimensionner vos shard duration, InfluxData recommande :
- La durée doit être égale à 2 fois la période d’analyse la plus longue et la plus fréquente ; si vos analyses les plus fréquentes portent sur 6 mois de données maximum, alors votre shard duration est d’un an
- Chaque shard doit contenir au moins 100.000 points
- Chaque shard doit contenir au moins 1.000 points par série (combinaison de measurement (~table) + combinaison des tags + clés des fields)
Pourquoi nous en arrivons là ? C’est assez simple :
- InfluxDB au lancement va découvrir l’ensemble de ses shards et les périodes qu’ils recouvrent
- InfluxDB cherche à mettre un maximum de données en mémoire par souci d’efficience et de performance
- Une requête sur des périodes longues va nécessiter de monter en mémoire tous les shards correspondants à la période
Dès lors, un nombre important de shards va augmenter d’autant plus la consommation mémoire et le nombre de fichiers ouverts pour manipuler les données associées.
Si on recoupe ces données avec les recommendations pour InfluxDB Entreprise, à savoir 30/40 bases par data nodes et 1.000 shards par node, le bon réglage des retention policy et des shard durations n’est pas à négliger pour la bonne santé de votre instance.
En outre, s’il est possible de mettre à jour la retention policy et la shard duration en 1.x, cela ne s’appliquera que pour les nouveaux shards. Les anciens shards ne seront pas “restructurés” en fonction des nouvelles valeurs.
Pour mettre à jour les shards existants, il faut :
- Arrêter les mécanismes d’ingestion de données
- Exporter les données sous la forme de points au format InfluxDB Line Protocol via influxd inspect export
- Supprimer les measurements (voir la base de données si vous voulez aller plus vite)
- Modifier la retention policy et la shard duration de la base de données (ou créer une nouvelle base de données avec les bonnes valeurs pour la retention policy et la shard duration)
- Importer les données par batch de 5000 à 10.000 points.
- Valider le bon fonctionnement de l’instance et l’intégrité des données
- Relancer les mécanismes d’ingestion et gérer le rattrapage.
Ultime question, la version 2.x OSS change-t-elle la donne sur le sujet :
- InfluxDB 2.x OSS recommande 20 buckets actifs (databases) par instancce
- Définir la shard duration n’est possible que via l’API ou via la CLI. Rien via l’UI
- Les outils d’analyse et d’inspection comme influx_inspect en 1.x n’étaient pas à niveau en 2.0 OSS mais le sont presque en 2.1 OSS. Manque encore les commandes
reportetreport-disk. - Les templates de monitoring InfluxDB2 OSS Metrics et InfluxDB 2 Operational Monitoring requiert d’envoyer les données dans une instance InfluxCloud pour avoir les données.
- La fonction influxdb.cardinality() n’est disponible en OSS que depuis la 2.0.9
En conclusion, ce qu’il faut retenir :
- La retention policy et la shard duration de vos bases InfluxDB ne sont pas à négliger et les valeurs par défaut ne sont surement pas adaptées à votre cas d’usage
- Il est possible de mettre à jour ses valeurs mais elles ne s’appliqueront qu’aux nouveaux shards - pour les anciens shards, il faut exporter les données sous la forme de points et les réimporter
- Il faut trouver la bonne taille de shard duration adaptée à votre cas d’usage ; trop de shards ou des shards trop gros ont chacun leur limites et auront des effets différents sur la consommation CPU/RAM/IOPS
- Pour InfluxDB (Entreprise), il est recommandé d’avoir maximum 1.000 shards et 30/40 bases par node.
- La version 2.x OSS n’apporte pas grand chose de plus sur le sujet - la version 2.1 permet d’être à peu près au niveau de la 1.x.
Mise à jour : le client reporte les gains suivants post restructuration des bases pour le serveur de recette et production :
- Les dashboards simples sont entre 15% et 30% plus rapides pour leur affichage
- Les dashboards complexes sont entre 3 et 10 fois plus rapides pour leur affichage
- La consommation mémoire reste stable autour de 6/8 Go
- Des changements sur la shard duration de certaines bases ont permis de descendre jusqu’à 600 shards environ.
Axens
timeseries influxdb audit optimisation performanceContexte
Axens, filiale de l’IFPEN, a développé le projet Connect’In qui récupère les données de ces équipements, les enrichis et les mets à disposition de ses clients. Dans le cadre du déploiement de la V3 du produit, des problèmes de performance et de stabilité de la plateforme ont été rencontrés. Axens a contacté CérénIT pour faire un audit de la plateforme et idenfifier les axes d’améliorations avant de pouvoir ouvrir l’application à ses utilisateurs. Suite à l’audit, il a été demandé à CérénIT d’accompagner Axens dans l’implémentation de ces recommendations.
Notre réponse
- Audit de l’instance InfluxDB OSS 1.x
- Audit de la VM hôte de l’instance InfluxDB
- Recommendations et définition d’un plan d’action
- Implémentation et suivi du plan d’action.
Bénéfices pour le client
- Expertise sur InfluxDB
- Résultats constatés :
- Les dashboards simples sont entre 15% et 30% plus rapides pour leur affichage
- Les dashboards complexes sont entre 3 et 10 fois plus rapides pour leur affichage
- La consommation mémoire reste stable autour de 6/8 Go
- Des changements sur la shard duration de certaines bases ont permis de descendre jusqu’à 600 shards environ. (recomendation éditeur en version Entreprise d’avoir 1.000 shards maximum par node)
Bénéfices pour CérénIT
- Expérience appronfondie sur le moteur de stockage InfluxDB
