Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Vers de nouveaux horizons...
flovea cérénit timeseries bigdatahebdo iot CTO cio dsi iiotJe l’évoquais dans le billet “Bilan 2021 et perspectives 2022”, je peux en parler maintenant officiellement : j’ai été contacté par Flovea pour piloter le projet Flowbox Interactive et mettre en place l’équipe projet associée.
Après trois mois environ de mission permettant de faire connaissance, d’auditer la solution existante, de définir une roadmap et de mettre en place l’équipe projet, mon recrutement en tant que DSI/CIO de Flovéa est acté depuis début avril. J’ai le plaisir de rejoindre une belle équipe pour réaliser un beau projet tant d’un point de vue technique que d’un point de vue du sens et de son utilité. La seule ombre au tableau étant le contexte de pénurie de composants qui illustre bien la dimension “hard” d’un projet “hardware”.
L’activité de CérénIT va donc ralentir puis se mettre en mode minimal ; le temps pour moi de finir quelques activités de support pour un client et ne conserver ensuite que l’infogérance de Compta-Online et un autre projet avec Fabrice Heuvrard à destination des experts comptables.
L’animation du meetup Time Series France sera moins régulière et surement de façon plus opportuniste que précédemment. Je continue à contribuer à BigData Hebdo même si mes contributions au podcast sont minimes depuis le début d’année.
Je remercie tous les clients et les personnes que j’ai pu accompagner pendant ces 6 ans ; j’ai appris énormément de choses grâce à eux et j’ai pu travailler sur des sujets et dans des entreprises sur/pour lesquel(le)s je n’aurais jamais pensé travailler. Je remercie plus particulièrement :
- Frédéric Rocci, j’aurai du rejoindre Compta Online début 2017, cela ne s’est pas fait mais cela m’a permis de devenir indépendant
- Vincent Heuschling : il était mon prestataire lorsque j’étais encore chez JCDecaux, il devient mon premier client en 2017 pour lancer les premières fondations de DataTask. On a remis ça en 2020/2021 mais les conditions sanitaires et économiques font que je ne peux pas rester sur le projet fin 2021. C’est grace à cette rencontre que je découvre le podcast BigData Hebdo puis rejoint l’équipe en 2019.
- Thomas Bosviel, prestataire également chez JCDecaux en 2016/17 et qui me met en contact en 2019 avec Frédéric Mefiant de la SAFT et pouvoir ainsi commencer mon activité “Time Series”.
- Denis Rampnoux pour la mission chez LesFurets.com et Youen Chéné pour la mission chez Saagie.
Ces années ont été très riches et passionnantes mais j’aspirai à aller vers d’autres choses ; le projet et la rencontre avec Flovéa semblent être la réponse que j’attendais. Il est donc temps de tourner la page et de découvrir ces nouveaux horizons.
Bilan 2021 et perspectives 2022
bilan perspective cérénit timeseries bigdatahebdo influxace iotRoutine habituelle de début d’année pour la clôture de ce 5ème exercice (déjà !).
Bilan 2021
Au global, une année mitigée qui se termine un peu sur le fil du rasoir au niveau comptable. Pour la partie positive, j’ai l’impression que cette année a été “l’année des possibles” où les efforts commencés les années précédentes commencent à payer. Des premiers projets en Go, des missions Time Series intéressantes et ambitieuses par certains aspects et un projet annexe en Python/Django sur la fin d’année qui consolide différents éléments permettant de gagner en confiance et de réduire un peu ce cher syndrome de l’imposteur avec lequel j’apprends à composer et à dépasser parfois.
CérénIT
D’un point de vue comptable, cela donne :
| 2021 | 2020 | 2019 | 2018 | 2017 | Variation n/n-1 | |
|---|---|---|---|---|---|---|
| Chiffre d’affaires | ~130 K€ | ~138 K€ | ~150 K€ | ~132 K€ | ~100 K€ | -6% |
| Résultat après impôts | ~1K€ | ~10 K€ | ~13.5 K€ | ~10 K€ | ~20 K€ | -90% 😱 |
| Jours facturés | 164 | 175 | 197 | 178 | 160 | -6% |
| TJM | 793€ | 789€ | 761€ | 742€ | 625€ | +0.5% |
Les années précédentes, les missions annexes (missions courtes d’audit/expertise principalement) venaient apporter le bénéfice annuel et la mission principale couvrait les charges. Cette année, avec une réduction de mes missions principales en fin d’année, les missions annexes ont permis de couvrir les charges mais sans permettre de dégager de bénéfices. Un TJM plus élevé sur ces missions annexes permet d’amortir et de compenser la baisse d’activité.
| 2021 | 2020 | 2019 | Variation n/n-1 | |
|---|---|---|---|---|
| Chiffre d’affaires Total | ~130 K€ | ~138 K€ | ~150 K€ | -6% |
| Chiffre d’affaires Time Series | ~25K€ | ~5 K€ | ~2 K€ | +400% 💪 |
Une des grandes satisfactions de l’année est incontestablement l’essor de l’activité Time Series. Etre référencé comme InfluxAce m’a apporté une mission chez Axens sur les Shard Duration & Retention Policies et quelques contacts/prospects qui n’ont pas pu aboutir durant cette année. C’est aussi la poursuite de mon accompagnement des équipes de la SAFT pour la 3ème année consécutive et la mise à jour d’InfluxDB OSS v1.x vers v2.x avec un sujet de migration des alertes Kapacitor vers des Tasks en Flux.
Autres activités
Pour le reste, j’ai eu le plaisir de :
- contribuer au podcast BigData Hebo avec une participation à 17 épisodes et la publication de 44 brèves,
- continuer à animer le Meetup Time Series France avec 5 éditions et en parvenant à lui donner une dimension autour des usages,
- continuer à approfondir mes connaissances autour de Warp 10 avec notamment la publication d’un billet sur le blog de SenX sur n8n & Warp 10 ou le fait de gagner le challenge sur les GeoShapes 🥇,
- finalement parvenir à commencer à jouer avec des ESP32 en toute fin d’année en faisant des détecteurs de CO2.
Pas de contribution de ma société à un quelconque projet comme en 2020 avec une contribution financière au projet Makair suite à la question du rôle social d’une entreprise dans notre société en temps de COVID. Petite déception à ce niveau-là.
Perspectives 2022
2021 s’est terminée avec une certaine forme de lassitude autour de l’activité de freelance (et de la solitude du freelance, même si j’ai toujours cherché à gommer cet aspect dans mes missions) et des activités autour de l’automatisation/industrialisation comme une fin en soit. J’éprouvais le besoin de créer un commun avec des personnes et je voulais accélérer la bascule vers l’IoT industriel mais ne sachant pas par quel bout attaquer le sujet. Une mission “DevOps AWS pour déployer un outil de CI/CD” sans autre finalité ne m’intéressait pas/plus (🤢).
Et là, de nulle part surgit une prise de contact sur LinkedIn par une recruteuse pour rejoindre une entreprise dans l’IoT industriel, avec une dimension environnementale qui cherchait un profil de responsable technique DevOps/IoT. Les astres ne pouvant pas être plus alignés, les cases du job idéal / de la mission idéale étant toutes cochées, je ne pouvais pas laisser passer cette opportunité. Depuis mi-janvier, j’ai donc commencé une mission pour cette entreprise pour qu’on fasse connaissance et pour avancer rapidement sur le sujet le temps que d’autres points soient traités de leur côté. De jolies choses semblent se dessiner et devraient aboutir prochainement… 🤩
Affaire à suivre comme on dit, 2022 semble pleine de promesses, de défis et de changements ! 😎
Flovea
timeseries iot CTO audit cio pilotage gestion produitContexte
Flovéa travaille depuis plusieurs années sur une solution de plomberie connectée. Elle souhaite maintenant passer à une échelle industrielle en terme de fabrication et de déploiement, commercialiser son service Predictive FLOWBOX et l’enrichir de fonctionnalités liées à du marchine learning. Sa solution doit permettre de contrôler à distance un circuit d’eau, de suivre sa consommation et d’identifier des consommations anormales, ainsi que de détecter des fuites.
Flovéa souhaite se doter des compétences techniques en interne pour concevoir, piloter et réaliser le projet. Elle cherche donc à recruter le responsable du projet. C’est dans ce contexte que CérénIT a été contacté. Après 3 mois de missions, l’embauche de Nicolas Steinmetz en tant que DSI/CIO de Flovea est actée.
Notre réponse
- Audit de la solution existante pour définir ses forces et faiblesses en vue des déploiements prévus
- Rédaction du cahier des charges pour définir les attendus du service
- Définition de l’architecture et des composants
- Mise en place de l’équipe projet (recrutement)
- Définition d’une roadmap
- Estimation et Suivi budgétaire
- Cadrage des travaux de la Data Scientiste (mise en place des bonnes pratiques de développement, etc)
- Mise en place des outils (Gitlab, MLFlow, Kestra, Warp 10, etc) et des pratiques de développement (gestion des tickets & milestones, définition of done, environnement de développement, environnement de recette, etc)
- Vulgarisation et montée en compétences des profils non IT.
Depuis l’embauche :
- Pilotage de l’activité
- Gestion d’équipe
- Gestion de produit et de projet (roadmap)
- Gestion budgétaire
- Gestion des partenaires et fournisseurs
- Support commercial et support client (documentation, suivi des demandes, etc)
- Développement de fonctionnalités et maintenance de la plateforme
Bénéfices pour le client
- Expériences en gestion de projets IT
- Expériences dans le domaine des applications web, (big) data et time series.
Bénéfices pour CérénIT
- Opportunité de travavailler sur un projet IoT industriel
- Membre du comité de direction
Web, Ops, Data et Time Series - Novembre 2021
postgresql timeseries timecale warp10 warpstudio influxdbContainers & Orchestration
- Announcing General Availability of HashiCorp Nomad 1.2 : Arrivée des “system batchs jobs” prévu pour gérer des jobs à destination du cluster nomad en lui même (purge, backup, etc) et non des clients. Cette version apporte également des améliorations au niveau de l’interface, ainsi que les “nomad pack”, format de distribution de vos applications à destination de nomad.
IoT
- Sortie de Raspberry Pi OS Bullseye et Raspberry Pi 4 à 1,8GHz : Première version de Raspberry Pi OS basée sur Debian 11 et possible overclocking du CPU des RPi4 à 1.8 Ghz (au lieu de 1.5 Ghz)
Monitoring & Observabilité
- Vector v0.18.0 release notes : une version avec beaucoup de changements - je vous laisse aller voir les release notes.
Time Series
Annonces & Produits :
- Timescale 2.5.0 : support de Postgresql 14, continuous aggregates for distributed hypertables (la fonction fonctionne donc maintenant en multi-nodes) et support des timezone pour la fonction time_bucket_ng
- Warp Studio 2.0.6 : version mineure du studio pour la gesion de CORS-RFC1918 ; c’est pour utiliser le studio avec vos instances locales depuis Chrome 92 (et bientôt les autres navigateurs) du fait des restrictrions d’accès mises en place dans les navigateurs.
- Release Announcement: InfluxDB OSS 2.1.0 | InfluxData : Arrivée des annotations et des notebooks, le client influx n’est plus distribué avec le serveur (sauf dans l’image Docker), améliorations de flux, amélioration de l’API et de la CLI et mise à jour de l’extension VSCode.
- Announcing PyCaret’s New Time Series Module :la librairie “low code” de machine learning PyCaret se dote d’un module de gestion de séries temporelles comprenant 30+ modèles (ARIMA, SARIMA, FBProphet, etc) et fonctions.
Articles :
- Intelligence Artificielle et Data Quality : comment corriger des données historiques impactées par la Covid 19 pour améliorer la qualité des prévisions ? : RETEX sur les appels à un call center : comment prendre en compte (ou pas) les variations liées au confinement sur les appels à un call center. L’article présente quatre stratégies et leurs résultats.
- Data replication with Warp 10 : présentation du fonctionnement de datalog, le module de réplication des données dans Warp 10.
- n8n & Warp 10 - Automate your time series manipulations : la version anglaise hébergée sur le blog de Senx de mon billet sur n8n & Warp 10
Ma comptabilité, une série temporelle comme les autres - partie 6 - Les FEC et le compte de résultat
warp10 timeseries comptabilité résultat fec dashboard discoverySuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512
- Partie 6 - Les FEC et le compte de résultat (ce billet)
Dans ce sixième et dernier billet pour cette série, nous continuons avec les Fichier d’Ecritures Comptables (FEC) pour produire le compte de résultat et déterminer ainsi le bénéfice de l’exercice en cours. Il faut donc prendre toutes les opérations en classe 6 (charges) et 7 (produits). Pour chaque classe de compte, il peut y avoir des crédits ou des débits (ex pour un compte de classe 7 : un avoir sur une facture émise). C’est donc un chouilla plus compliqué que le compte de trésorerie.
Depuis le dernier billet, j’ai légèrement fait évoluer le modèle de données :
- Initialement, j’avais :
<société>.<bilan ou resultat>.<classe de compte>.<type d'opération: credit ou debit> - Cela a évolué vers :
<société>.<bilan ou resultat>.<classe de compte>; le type d’opération est maintenant un label
Pour un crédit de 100€ avec une référence de pièce à 1234 pour le compte 706, on passe donc de :
<Timestamp de l'écriture comptable>// cerenit.resultat.706.credit{PieceRef=1234} 100
à :
<Timestamp de l'écriture comptable>// cerenit.resultat.706{PieceRef=1234, operation=credit} 100
Compte de résultat
"<readToken>" "readToken" STORE
// Récupération de toutes les opérations de crédit pour les comptes charges (classe 6xx)
// Le SORT permet d'être sur d'avoir toutes les opérations triées par date
// Stockage du résultat dans une variable
[ $readToken '~comptabilite.resultat.6.*' { "operation" "credit" } '2020-01-01T00:00:00Z' '2020-12-31T23:59:59Z' ] FETCH
MERGE
SORT
'charges_credit' RENAME
'charges_credit' STORE
// Récupération de toutes les opérations de débit pour les comptes charges (classe 6xx)
// Le SORT permet d'être sur d'avoir toutes les opérations triées par date
// Stockage du résultat dans une variable
[ $readToken '~comptabilite.resultat.6.*' { "operation" "debit" } '2020-01-01T00:00:00Z' '2020-12-31T23:59:59Z' ] FETCH
MERGE
SORT
'charges_debit' RENAME
'charges_debit' STORE
// Fusion des deux listes de séries en une liste qui va avoir l'ensemble des opérations
// Les opérations de débit sont mis en valeur négative du calcul du solde
// Le SORT permet d'être sur d'avoir toutes les opérations triées par date
// Stockage du résultat dans une variable qui contient l'ensemble des opérations
[
$charges_debit -1 *
$charges_credit
] MERGE
SORT
'charges_flux' RENAME
'charges_flux' STORE
// Même opération pour les comptes de produit (7xx)
[ $readToken '~comptabilite.resultat.7.*' { "operation" "credit" } '2020-01-01T00:00:00Z' '2020-12-31T23:59:59Z' ] FETCH
MERGE
SORT
'produits_credit' RENAME
'produits_credit' STORE
[ $readToken '~comptabilite.resultat.7.*' { "operation" "debit" } '2020-01-01T00:00:00Z' '2020-12-31T23:59:59Z' ] FETCH
MERGE
SORT
'produits_debit' RENAME
'produits_debit' STORE
[
$produits_debit -1 *
$produits_credit
] MERGE
SORT
'produits_flux' RENAME
'produits_flux' STORE
// Fusion des 2 flux d'opérations (charges et produits) pour avoir une vision temporelle de ces opérations
// Le SORT permet d'être sur d'avoir toutes les opérations triées par date
// Renommage de la série en "compte_resultat" qu'elle va permettre de batir
// Somme cumulée de l'ensemble des opérations pour avoir un solde à date
// Stockage sous la forme d'une variable
// Affichage de la variable
[
$produits_flux
$charges_flux
] MERGE
SORT
'compte_resultat' RENAME
[ SWAP mapper.sum MAXLONG 0 0 ] MAP
'compte_resultat' STORE
$compte_resultat
Ce qui nous donne dans le Studio :
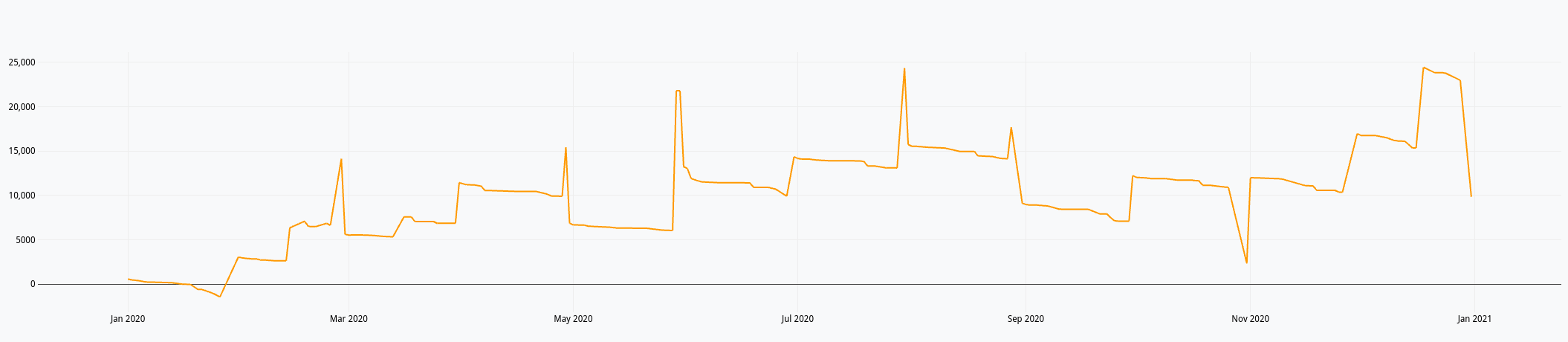
Du précédent billet et ce celui-ci, nous avons donc :
- Un compte de résultat annuel
- Un compte de trésorerie annuel
Tout ce qu’il faut donc pour faire un dashboard avec Discovery. Il faut dire que le billet Covid Tracker built with Warp 10 and Discovery et dans une moindre mesure Server monitoring with Warp 10 and Telegraf donnent accès à plein d’options pour réaliser ses dashboards.
Macros
Je pourrais mettre le code de mes requêtes directement dans les dashboards mais j’aime pas trop quand des tokens se balladent dans les pages web. Du coup, je vais déporter le code dans des macros. J’ai églément rendu les macro dynamiques dans le sens où elles prennent une année en paramètre pour afficher les données de l’année en question.
On a déjà vu le fonctionnement des macros précédemment, je ne reviendrais donc pas dessus.
La macro du compte de résultat à titre d’exemple :
<%
{
'name' 'cerenit/accountancy/compte-resultat'
'desc' 'Function to calculate the cumulative benefit (or loss) of the company'
'sig' [ [ [ [ 'year:LONG' ] ] [ 'result:GTS' ] ] ]
'params' {
'year' 'Year, YYYY'
'result' 'GTS'
}
'examples' [
<'
2020 @cerenit/accountancy/compte-resultat
'>
]
} INFO
// Actual code
SAVE 'context' STORE
TOLONG // When called from dashboard, it's a string - so convert paramter to LONG first
'year' STORE // Save parameter as year
// Compute 1st Jan of given year
[ $year 01 01 ] TSELEMENTS-> ISO8601
'start' STORE
// Compute 31 Dec of given year
[ $year 12 31 23 59 59 ] TSELEMENTS-> ISO8601
'end' STORE
"<readToken>" "readToken" STORE
[ $readToken '~comptabilite.resultat.6.*' { "operation" "credit" } $start $end ] FETCH
MERGE
SORT
'charges_credit' RENAME
'charges_credit' STORE
[ $readToken '~comptabilite.resultat.6.*' { "operation" "debit" } $start $end ] FETCH
MERGE
SORT
'charges_debit' RENAME
'charges_debit' STORE
[
$charges_debit -1 *
$charges_credit
] MERGE
SORT
{ NULL NULL } RELABEL
'charges_flux' RENAME
'charges_flux' STORE
[ $readToken '~comptabilite.resultat.7.*' { "operation" "credit" } $start $end ] FETCH
MERGE
SORT
'produits_credit' RENAME
'produits_credit' STORE
[ $readToken '~comptabilite.resultat.7.*' { "operation" "debit" } $start $end ] FETCH
MERGE
SORT
'produits_debit' RENAME
'produits_debit' STORE
[
$produits_debit -1 *
$produits_credit
] MERGE
SORT
{ NULL NULL } RELABEL
'produits_flux' RENAME
'produits_flux' STORE
[
$produits_flux
$charges_flux
] MERGE
SORT
'compte_resultat' RENAME
[ SWAP mapper.sum MAXLONG 0 0 ] MAP
'compte_resultat' STORE
$compte_resultat
$context RESTORE
%>
'macro' STORE
$macro
Comme le décrit l’exemple, si on veut le compte de résultat de l’année 2020, on utilisera le code suivant :
2020 @cerenit/accountancy/compte-resultat
J’ai profité de ce billet pour utiliser Warpfleet Synchronizer & Warpfleet Resolver pour simplifier le déploiement des macros ; cela explique que les signatures pour appeler les macros changent par la suite dans le dashboard.
Dashboards
Ci-après le code du dashboard :
<%
{
'title' 'Comptabilité CérénIT'
'description' 'Trésorerie et compte de résultat'
'vars' {
'myYear' 2020
}
'tiles' [
{
'title' 'Informations'
'type' 'display'
'w' 11 'h' 1 'x' 0 'y' 0
'data' {
'data' 'Résultat de la série <a href="https://www.cerenit.fr/blog/premiers-pas-avec-warp10-comptabilite-et-previsions/">Ma comptabilité, une série temporelle comme les autres</a> et de l'ingestion des Fichiers d'écritures comptables.'
'globalParams' { 'timeMode' 'custom' }
}
}
{
'title' 'Année'
'type' 'input:list'
'w' 1 'h' 1 'x' 11 'y' 0
'data' {
'data' [ '2017' '2018' '2019' '2020' ]
'events' [ { 'type' 'variable' 'tags' 'year' 'selector' 'myYear' } ]
'globalParams' { 'input' { 'value' '2020' } }
}
}
{
'title' 'Trésorerie (annuel)'
'type' 'line'
'w' 6 'h' 2 'x' 0 'y' 1
'macro' <% $myYear @cerenit/macros/treso %>
'options' { 'eventHandler' 'type=(variable),tag=year' }
}
{
'title' 'Compte de résultat (annuel)'
'type' 'line'
'w' 6 'h' 2 'x' 6 'y' 1
'macro' <% $myYear @cerenit/macros/compteresultat %>
'options' { 'eventHandler' 'type=(variable),tag=year' }
}
{
'title' 'Trésorerie (pluri-annuelle)'
'type' 'line'
'w' 12 'h' 2 'x' 0 'y' 3
'macro' <% [ 2017 $myYear ] @cerenit/macros/treso_multi %>
'options' { 'eventHandler' 'type=(variable),tag=year' }
}
]
}
{ 'url' 'https://w.ts.cerenit.fr/api/v0/exec' }
@senx/discovery2/render
%>
et son rendu :
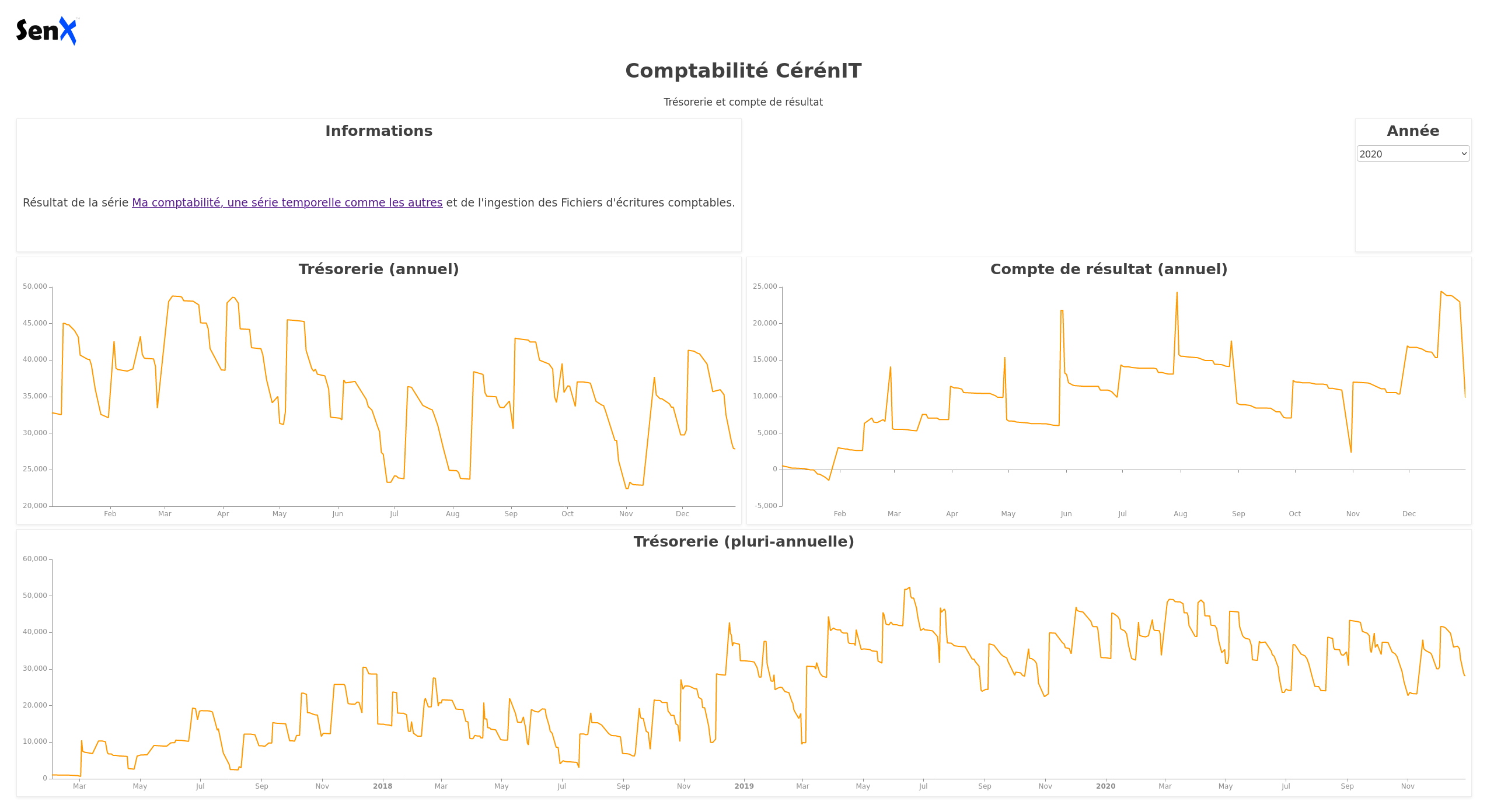
Dans le bloc global du dashboard, on définir une variable myYear, initialisée à 2020. Cette variable est mise à jour dynamiquement lorsque l’on choisit une valeur dans la liste déroulante du bloc “Année”.
<%
{
'title' 'Comptabilité CérénIT'
'description' 'Trésorerie et compte de résultat'
'vars' {
'myYear' 2020
}
...
Le bloc Année justement :
{
'title' 'Année'
'type' 'input:list'
'w' 1 'h' 1 'x' 11 'y' 0
'data' {
'data' [ '2017' '2018' '2019' '2020' ]
'events' [ { 'type' 'variable' 'tags' 'year' 'selector' 'myYear' } ]
'globalParams' { 'input' { 'value' '2020' } }
}
}
C’est une liste déroulante (type: input:list) avec pour valeurs les années 2017 à 2020. Par défaut, elle est initialisée à 2020. Via le mécanisme des “events”, lorsqu’une valeur est choisie, celle-ci est émise sous la forme d’une variable, nommée myYear et ayant pour tag la valeur year.
Ainsi, si je sélectionne 2017 dans la liste, la variable myYear prendra cette valeur. Maintenant que la valeur est définie suite à mon choix et émise vers le reste du dashboard, il faut que les autres tiles récupèrent l’information.
Regardons le tile Trésorerie :
{
'title' 'Trésorerie (annuel)'
'type' 'line'
'w' 6 'h' 2 'x' 0 'y' 1
'macro' <% $myYear @cerenit/macros/treso %>
'options' { 'eventHandler' 'type=(variable),tag=year' }
}
La récupération de la variable se fait via la proriété options et la récupération de l’eventHandler associé et défini précédemment.
Une fois récupérée, la variable myYear peut être utilisée dans le bloc macro et le tile est mis à jour dynamiquement.
En conséquence :
- Les deux premiers tiles afficheront le solde de trésorerie et le compte de résultat de l’année sélectionnée
- Le dernier tile affichera la trésorerie depuis début 2017 jusqu’à la fin d’année sélectionnée. Donc au minimum 2017 et au maximum 2017 > 2020.
Ainsi s’achève cette série sur les données comptable et les séries temporelles. Des analyses complémentaires pourraient être menées (analyse de stocks, réparition d’activité, etc) mais mes données comptables sont insuffisantes pour en valoir l’intérêt. J’espère néanmoins que cela aura sucité votre intérêt et ouvert des horizons.
Cette série fut aussi l’occasion de faire un tour de la solution Warp 10 et de voir :
- l’ingestion de données,
- la manipulation et l’analyse des données,
- la mise en place de dashboards,
- la projection de données avec les algorythmes de machine learning.
Si vous souhaitez poursuivre l’aventure et le sujet, n’hésitez pas à me contacter.
