Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
InfluxDB, shard, shard duration et retention policies
influxdb timeseries influxdata shard shard duration retention policy shard groupCérénIT a été contacté pour mener l’audit d’une instance InfluxDB 1.8 OSS utilisée dans un projet IoT lié à l’énergie. L’audit avait plusieurs objectifs :
- Comprendre la consommation mémoire de l’instance (48Go / 64Go de la VM)
- Faire un état de santé de la plateforme et estimer sa capacité à stocker et procésser des données supplémentaires dans le cadre de l’ouverture d’une application métier
- Expliquer la raison des problèmes observés par le passé et évaluer les solutions apportées
- Etablir des recommendations et éventuellement les implémenter.
De l’audit, on notera que :
- L’instance contient ~35.000 shards / ~36.000 tsm files pour environ 200 bases permanentes et des dizaines de bases éphémères permettant de calculer des indicateurs ou de recalculer des historiques de données suite à des changements de paramètres de l’application métier (plusieurs dizaines de milliers de bases temporaires par semaine, avec des profondeurs de données variables)
- Les recommendations pour InfluxDB Enterprise sont d’avoir 30/40 bases par data nodes et 1.000 shards par data node
Avant d’aller plus loin, précisons un peu cette notion de shard et les notions liées pour bien appréhender le sujet :
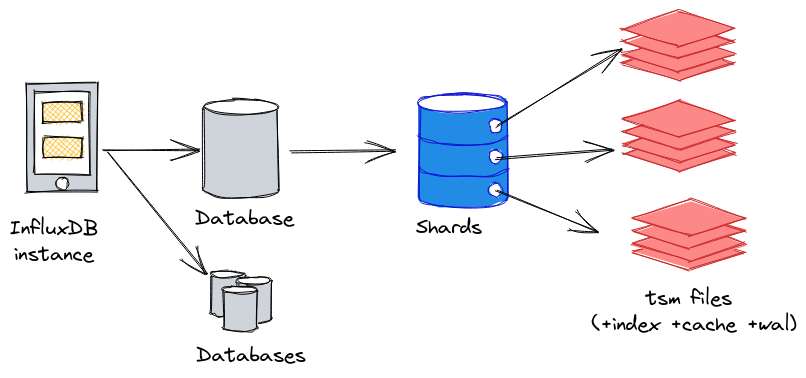
- Une instance InfluxDB peut contenir 1 à n bases de données (database),
- A chaque base de données InfluxDB, on peut définir une “retention policy” qui est la période maximale de conservation des données. Avec une retention policy de 7 jours par ex, seules les données des 7 derniers jours sont conservées. Les données les plus vieilles seront alors supprimées au fur et à mesure que les nouvelles données arriveront via un mécanisme de compaction.
- Les données d’une base de donneés InfluxDB sont réparties au sein de shards au niveau stockage ; chaque shard comprend les données sur une période de temps donnée. Si une base de données a une retention policy d’une semaine, alors chaque shard contiendra 1 jour de données. Nous aurons donc 7 shards pour cette base de données. Ce délai est appelé shard duration.
- Au sein de chaque shard, nous allons retrouver les données sous la forme d’un ou plusieurs fichiers TSM, le fichier d’index pour le shard, ainsi que le fichier de WAL et de cache.
Nous pouvons représenter la logique instance > database > shard(s) > tsm files de la façon suivante :
Par défaut, InfluxDB applique les shard duration suivantes en fonction des retention policy :
| Retention policy | Default shard duration |
|---|---|
| <= 2 days | 1 hour |
| <= 6 months | 1 day |
| > 6 months | 7 days |
Source : InfluxData - Shard group duration
Dès lors, une base de données avec une retention policy infinie aura une shard duration de 7 jours. Ainsi, si cette base contient 10 ans d’hisorique (soit 10 * 52 semaines = 520 semaines), elle contiendra 520 shards.
Du coup, InfluxData recommande les valeurs suivantes (au moins en 1.x ; on peut supposer que cela reste valable en 2.x):
| Retention policy | Default shard duration |
|---|---|
| <= 1 day | 6 hour |
| <= 7 days | 1 day |
| <= 3 months | 7 days |
| > 3 months | 30 days |
| infinite | >= 52 weeks |
Source : Shard group duration recommendations
Selon cette perspective, la base de données avec 10 ans d’historique ne contiendra plus 520 shards mais 10 shards en prenant une shard duration de 52 semaines. L’écart entre la valeur par défaut et la valeur recommandée est plus que significatif.
Pour bien dimensionner vos shard duration, InfluxData recommande :
- La durée doit être égale à 2 fois la période d’analyse la plus longue et la plus fréquente ; si vos analyses les plus fréquentes portent sur 6 mois de données maximum, alors votre shard duration est d’un an
- Chaque shard doit contenir au moins 100.000 points
- Chaque shard doit contenir au moins 1.000 points par série (combinaison de measurement (~table) + combinaison des tags + clés des fields)
Pourquoi nous en arrivons là ? C’est assez simple :
- InfluxDB au lancement va découvrir l’ensemble de ses shards et les périodes qu’ils recouvrent
- InfluxDB cherche à mettre un maximum de données en mémoire par souci d’efficience et de performance
- Une requête sur des périodes longues va nécessiter de monter en mémoire tous les shards correspondants à la période
Dès lors, un nombre important de shards va augmenter d’autant plus la consommation mémoire et le nombre de fichiers ouverts pour manipuler les données associées.
Si on recoupe ces données avec les recommendations pour InfluxDB Entreprise, à savoir 30/40 bases par data nodes et 1.000 shards par node, le bon réglage des retention policy et des shard durations n’est pas à négliger pour la bonne santé de votre instance.
En outre, s’il est possible de mettre à jour la retention policy et la shard duration en 1.x, cela ne s’appliquera que pour les nouveaux shards. Les anciens shards ne seront pas “restructurés” en fonction des nouvelles valeurs.
Pour mettre à jour les shards existants, il faut :
- Arrêter les mécanismes d’ingestion de données
- Exporter les données sous la forme de points au format InfluxDB Line Protocol via influxd inspect export
- Supprimer les measurements (voir la base de données si vous voulez aller plus vite)
- Modifier la retention policy et la shard duration de la base de données (ou créer une nouvelle base de données avec les bonnes valeurs pour la retention policy et la shard duration)
- Importer les données par batch de 5000 à 10.000 points.
- Valider le bon fonctionnement de l’instance et l’intégrité des données
- Relancer les mécanismes d’ingestion et gérer le rattrapage.
Ultime question, la version 2.x OSS change-t-elle la donne sur le sujet :
- InfluxDB 2.x OSS recommande 20 buckets actifs (databases) par instancce
- Définir la shard duration n’est possible que via l’API ou via la CLI. Rien via l’UI
- Les outils d’analyse et d’inspection comme influx_inspect en 1.x n’étaient pas à niveau en 2.0 OSS mais le sont presque en 2.1 OSS. Manque encore les commandes
reportetreport-disk. - Les templates de monitoring InfluxDB2 OSS Metrics et InfluxDB 2 Operational Monitoring requiert d’envoyer les données dans une instance InfluxCloud pour avoir les données.
- La fonction influxdb.cardinality() n’est disponible en OSS que depuis la 2.0.9
En conclusion, ce qu’il faut retenir :
- La retention policy et la shard duration de vos bases InfluxDB ne sont pas à négliger et les valeurs par défaut ne sont surement pas adaptées à votre cas d’usage
- Il est possible de mettre à jour ses valeurs mais elles ne s’appliqueront qu’aux nouveaux shards - pour les anciens shards, il faut exporter les données sous la forme de points et les réimporter
- Il faut trouver la bonne taille de shard duration adaptée à votre cas d’usage ; trop de shards ou des shards trop gros ont chacun leur limites et auront des effets différents sur la consommation CPU/RAM/IOPS
- Pour InfluxDB (Entreprise), il est recommandé d’avoir maximum 1.000 shards et 30/40 bases par node.
- La version 2.x OSS n’apporte pas grand chose de plus sur le sujet - la version 2.1 permet d’être à peu près au niveau de la 1.x.
Mise à jour : le client reporte les gains suivants post restructuration des bases pour le serveur de recette et production :
- Les dashboards simples sont entre 15% et 30% plus rapides pour leur affichage
- Les dashboards complexes sont entre 3 et 10 fois plus rapides pour leur affichage
- La consommation mémoire reste stable autour de 6/8 Go
- Des changements sur la shard duration de certaines bases ont permis de descendre jusqu’à 600 shards environ.
