Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Web, Ops & Data - Novembre 2020
vitess mysql kubernetes helm mesos influxdb arrow parquet scp sftp gke gcp observability monitoring dig dns dog rust ovhcloud gitCe soir, il y a la 8ème édition du Paris Time Series Meetup sur AWS TimeStream.
Cloud
- OVHcloud et Google Cloud annoncent un partenariat stratégique pour co-construire une solution de confiance en Europe : Les service Anthos de Google seront disponibles dans les infrastructures et hébergés par les équipes OVHCloud. Cela peut être intéressant pour ceux qui ont envie d’utiliser les services Google (sous réserve qu’ils soient disponible dans une version Anthos) tout en gardant les données à l’abri du cloud act (à vérifier en détail - notamment ce qu’il se gère ou pas au travers de la console cloud google). Une initiative intéressante pour le moins.
- New Clever Cloud Zones on top of OVHcloud in APAC and EMEA : Clever Cloud profite de son partenariat avec OVHCloud pour se déployer également dans de nouvelles zones (Roubaix, Sidney, Sinagpour, et Varsovie).
- Terraform 0.14 Adds the Ability to Redact Sensitive Values in Console Output : Terraform 0.14 (beta) n’affichera plus les informations marquées comme sensibles dans les informations qu’il affiche.
- Terraform 0.14 Adds a New Concise Diff Format to Terraform Plans : Terraform 0.14 (beta) proposera aussi un diff plus compact permettant de mieux appréhender les différences d’un plan à l’autre.
Code
- git-filter-repo : si vous avez besoin de manipuler votre dépot git, comme par ex le fait de déplacer un projet git dans un autre en gardant l’historique, alors git-filter-repo permet de le faire assez facilement.
Container et orchestration
- New Location For Stable and Incubator Charts : le 13/11, les dépots stable et incubator de helm auront migrés. Les versions 2.17.0+ et 3.4.0+ de Helm feront la redirection entre les anciennes et nouvelles urls. Pour des clients plus vieux, il faudra redéclarer les urls de stable et incubator. L’image de tiller bouge également.
- D2iQ Takes the Next Step Forward : D2iQ annonce la fin de son investissement sur DC/OS et sa concentration sur son offre kubernetes (et la transition DC/OS vers kubernetes pour ses clients).
- Setting up Cloud Operations for GKE et Troubleshooting services on GKE : une bonne raison de plus d’avoir un clustr 1.15+ chez GKE. Cloud Operations permet d’avoir un dashboard assez sympathique pour visualiser et diagnostique l’état d’un cluster GKE. Reste ensuite la partie alerting à ajuster à vos besoins.
- Announcing k0s, the Smallest, Simplest Kubernetes Distribution : Mirantis, en plus de Lens, ajoute à son arc une nouvelle distribution kubernetes nommée “k0s”. Multi-usages (Cloud, IoT, Edge, Bare Metal, etc), elle vise à simplifier le dépoiement d’un cluster kubernetes avec un binaire unique contenant tout les éléments nécessaires pour piloter votre cluster.
- OVHcloud Managed Kubernetes certified Kubernetes 1.19 : OVHCloud propose maintenant kubernetes 1.19 (et la version 1.14 ne sera plus disponible à partir de janvier 2021)
SQL
- Announcing Vitess 8 : Vitess, la base distribuée prévue pour un déploiement sur kubernetes et avec une compatibilité MySQL arrive en version 8 et améliore son support de MySQL et des principales librairies et frameworks dans différents langages.
Système
- Deprecating scp : qui n’a pas fait un
scp file destination:/path/to/file? La commande scp est victime de nombreuses failles. Du coup, elle va être dépréciée. Néanmoins une initiative vise à maintenir uen commandescpmais se fondant sursftpet son modèle de sécurité. - ogham/dog : dog est une réécriture de dig en rust avec coloration syntaxique et différentes fonctionnalités comme le support de DoH, DoT, etc.
- k6 : k6 est un outil de test de performance avec lequel on peut définir des scénarios plus ou moins élaborés suivant ses besoins ; je l’avais recommandé à un client pour faire des tests de performance d’API; la version 0.29 vient de sortir.
Timeseries
- InfluxData advances possibilities of time series data with general availability of InfluxDB 2.0 : InfluxDB 2.0 OSS est (enfin) là et un guide de mise à jour 1.x vers 2.x 0SS est disponible
- Announcing InfluxDB IOx – The Future Core of InfluxDB Built with Rust and Arrow : Paul Dix a annoncé le nouveau projet phare autour d’InfluxDB avec une réécriture d’une partie du coeur d’InfluxDB pour traiter les soucis de cardinalité et aller plus loin dans la partie analytique (avec un support de SQL). Cela sera basé sur les projets Apache Arrow, le format de fichier Parquet et ce sera écrit en Rust. A suivre !
- InfluxDays North America 2020 : les supports et vidéo de cette édition sont en ligne. Vous y retrouvez notamment des détails sur le projet IOx par Paul Dix, la roadmap produit par Tim Hall ou encore la mise à jour Influx DB OSS 1.x vers 2.x. Sans oublier les sessions pour se mettre à Flux ou encore l’intégration Flux/Grafana et bien d’autres choses encore.
Astuce du mois
Pour ceux sous Fedora et utilisant podman en alternative au binaire docker, pour se connecter à la registry google (via):
gcloud auth print-access-token | podman login -u oauth2accesstoken --password-stdin gcr.io
Web, Ops & Data - Octobre 2020
kubernetes ingress yaml pipeline gitlab traefik rootless mesh yq jq devops data maturité mariadb s3 flows warp10 timeseries influxdb pulsar amqp mqtt kafka python git vscode arm nvidiaDes nouvelles du Paris Time Series Meetup : l’éditions 6 sur TimescaleDB et l’édition 7 sur QuestDB
CI/CD
- 3 YAML tips for better pipelines : la troisième est certainement la plus intéressante - il est possible d’avoir des mécanismes de “composabilité” / “héritage” avec YAML et Gitlab. Si les
includeetextendssont déjà sympathiques, lesanchorsont l’air de faire des choses intéressantes aussi !
Code
- What’s New In Python 3.9 et un thread twitter qui donne des exemples des principales nouveautés : au programme nouvelle syntaxe pour la fuston des dictionnaires, des méthides pour supprimer des suffixes/préfixes sur les strings, du typage et plein d’autres améliorations et corrections.
- Fortunately, I don’t squash my commits : s’il peut être tentant sur une MR/PR de faire un squash des commits, l’article vous confortera dans l’idée que ce n’est pas une bonne idée. En écrasant l’historique des commits, on y perd sur nos capacités de debug. Par ailleurs, il est conseillé de faire des petits commits pour capturer un ensemble de changements traduisant un moment précis du développement.
Container et orchestration
- Kubernetes Ingress Goes GA : l’apparition de IngressClassName dans k8s 1.19 va plus loin qu’un simple renommage de champ comme je l’avais compris initialement. C’est une vraie ressource et cela ouvre aussi des possibilités. Avant de l’utiliser, vérifiez aussi que vos ingress controller le supporte (en plus d’attendre d’être en 1.19)
- Houston, we have Plugins! Traefik 2.3 Announcement : la version 2.3 dont on a déjà parlé ici, est arrivé en version stable avec son support des plugins, son intégration avec Traefik Pilot, le support d’Amazone ECS et le support de la ressource IngressClassName. Au passage, Containous, la société éditrice de Traefik s’appelle maintenant Traefik Labs.
- Introducing Traefik Pilot 1.0: the Traefik Control Center : Version 1.0 de ce nouveau “Control Plane” de Traefik qui permet d’avoir une vision globale sur ses instances traefik, d’utiliser les plugins et d’avoir un monitoring et des alertes autour de la disponibilité, des performances et de la sécurité.
- Rootless mode : A voir si cela pourra être inclus dans la version 1.20 mais le rootless mode est clairement une tendance de fond dans kubernetes et les conteneurs en général. Si vous ne vous y êtes pas déjà mis, ne tardez pas !
- Announcing Traefik Mesh 1.4 - New Name, New Features : nouvelle version du service mesh par Traefik Labs et qui s’appelle maintenant Traefik Mesh (et non uniquement Maesh). Le reste des améliorations semble porter sur le filtrage des headers et des paths.
- yq : A command line tool that will help you handle your YAML resources better : vous voulez faire des opératoins sur des fichiers YAML sans faire un chart helm ou sortir kustomize, vous pouvez faire des choses minimalistes avec yq (le pendant yaml de jq).
- Bridge to Kubernetes GA, “bridge to kubernetes” est une extension pour vscode permettant de connecter une application tournant en local avec d’autres applications situées dans un ckuster kubernetes et faciliter ainsi l’expérience des développeurs.
Culture DevOps
- La culture de la résilience à travers le DevOps, DevPO, et DevQA : article intéressant de Paul Leclerq sur la résilience et la collaboration au sein d’une équipe.
Data
- How to Measure Your Organization’s Data Maturity : les différents stade de maturité de votre organisation concernant la gestion et l’exploitation des données.
- Announcing MQTT-on-Pulsar: Bringing Native MQTT Protocol Support to Apache Pulsar: Apache Pulsar, la plateforme de message distribué et de streaming, se dote d’un plugin “MQTT On Pulsar” (MoP) permettant ainsi de migrer vos applications MQTT sur Apache Pulsar. Après le plugin Kafka (KoP) il y a quelques mois en partenariat avec OVHCloud, Pulsar ajoute une corde à son arc pour devenir la plateforme universelle. Le protocole AMQP est déjà aussi supporté depuis plusieurs mois.
- Building An Event-Driven Orchestration Engine : retour d’expérience sur les raisons de la migration à Apache Pulsar e la simplificaiton apportée en ayant une platforme riche et complète (streaming + queue + fonctions + data tiering sur S3 + …)
Hardware
- NVidia’s Planned Acquisition of Arm Portends Radical Data Center Changes : une analyse assez en profondeur sur le rachat d’arm par nvidia et les autres acteurs du marché comme AMD.
IaC
- Announcing HashiCorp Terraform 0.14 Beta: la capacité à marquer des variables comme sensibles pour éviter que leur valeur soit visible dans les logs/diff/…, un diff plus concis, un lock sur les providers et des binaires disponibles pour arm64.
Monitoring
- Long-term store for Prometheus, with the combined power of SQL and PromQL : Timescale s’ajoute à la liste des solutions permettant un stockage long terme à vos données Prometheus. En plus de ce stockage long terme, elle fournit une couche d’analytics. Un connecteur récupère les données dans Prometheus et les injecte dans TimescaleDB. On en parle dans l’édition 6 du PTSM.
Pratique
- endoflife.date : recense les dates de fin de support de vos langages et technologies préférées. Tout n’est pas complètement à jour mais cela permet de récupérer rapidement les informations.
SQL
- Exciting and New Features in MariaDB 10.5 : évoqué au mois d’aout, le support de S3 dans MariaDB est disponible en version GA dans la version 10.5. D’autres améliorations existent comme le support du type INET6, des améliorations sur ColumnStore, la gestion des privilèges, le cluster Galera supporte complètement le GTID, du refactoring au niveau d’InnoDB et enfin les binaires mariadb vont enfin s’appeler mariadb et non plus mysql (avec une couche de compatibilité via des liens symboliques)
Time Series
- Introducing FLoWS, a functional language for Time Series Analytics : FLoWS est arrivé - il vous faudra utiliser une version 2.7.1+ de Warp10 pour profiter de cette approche fonctionnelle en alternative à Warpscript.
- How can you tell which Time Series Database is suited to your needs? : un petit rappel sur les critères à prendre en compte pour choisir une base de données séries temporelles ; j’avais déjà parlé du guide de Senx sur le sujet - il est disponible en fin de billet.
- InfluxDB 2.0 Release Candidate Now Available : la première Relese Candidate (RC0) pour InfluxDB 2.0 OSS avec le retour du moteur de stockage de la V1 - qui contrairement à ce que j’ai pu dire le mois dernier ne concernerait que la façon dont les données sont stockées sur disque et pas le reste d’une part et sera maintenu et amélioré par Influxdata d’autre part. Quelques changements sur le port (retour au port 8086). Pour ceux qui étaient en version alpha/beta, il faudra suivre une procédure de migration. La migration depuis une version 1.x n’est pas encore disponible, cela devrait être dans une prochaine RC. Vous pourrez tester néanmoins les API 1.x, les templates, une version récente de Flux ou encore les améliorations de la CLI.
- Release Announcement: InfluxDB 2.0.0 RC 1 : cette version apporte essentiellement l’upgrade des données 1.x vers 2.x et une mise à jour de Flux.
- Store and Access Time Series Data at Any Scale with Amazon Timestream – Now Generally Available - Getting Started with Amazon Timestream - AWS Releases Amazon Timestream into General Availability : AWS sort enfin son produit orienté time series après l’avoir annoncé il y a deux ans.
Sur la base des informations disponibles pour le moment :
- vous définissez une période de rétention en mémoire (entre 1h et 1 an) et une période de rétention sur stockage magnétique (1 jour à 200 ans),
- le requêtage des données se fait en SQL (via Presto ?),
- les données à requêter communément sont à mettre dans la même table,
- le join est limité à la même table,
- des mesures simples (pas de multi mesures pour un même enregistrement),
- une intégration avec l’écosystème comme telegraf, grafana, etc en plus de l’intégration avec différents composants AWS
Pour les moins bons côtés :
- pas d’UPDATE/DELETE sur vos données ; en cas de doublons, c’est le premier arrivé qui gagne
- pas de bulk import de vos données, donc pas de reprise de vos données existantes. En effet, il n’est pas possible d’ingérer des données plus vieille que la période en mémoire,
- dans la même veine, si un incident de production dépasse votre période de rétention, vous ne pourrez pas réinjecter vos données
- il ne semble pas possible de mettre à jour ses durées de rétention - donc pas de ménage possible ou d’ajustements en cours de route
Une solution a priori très orienté pour du monitoring et qui semble souffir des mêmes travers qu’InfluxDB avec InfluxQL et pourtant en passe d’être résolus avec Flux.
On devrait en parler plus en détail dans une prochaine édition du Paris Time Series Meetup avec des personnes de chez AWS ;-)
Work
- Virtual First Toolkit : toolkit proposé par Dropbox dans le cadre de leur passage non pas à Remote first mais à virtual first.
DataTask
python go gcp docker terraform kubernetes data pipelineContexte
Editeur d’une plateforme data, la société cherche à se faire accompagner et confier le role de Lead Platform à une personne en mesure d’industrialier et d’automatiser la plateforme, son déploiement et son exploitation mais aussi d’améliorer les pratiques de développement de l’équipe. Une contribution directe au produit est également envisagé.
Notre réponse
En tant que Lead Platform :
- Passage d’un logique “Build/Ship” à une logique “Build/Ship/Run”
- Mise en place de Gitlab et Gitlab-CI pour le suivi du code et l’automatisation des tâches,
- Migration des outils de déploiement sous Terraform et Ansile en fonction des cas,
- Mise à jour des composants de la plateforme et de l’outillage autour de la plateforme,
- Amélioration des pratiques de développement et recette : amélioration du process de revue de code et de validation d’un développement, mise en place des “Architectural Design Review” pour cadrer les initiatives, etc.
- Amélioration des pratiques de monitoring et d’exploitation des plateformes
- POC Nomad/Consul/Terraform comme alternative à Kubernetes pour des déploiements plus légers,
- Déploiement du logiciel chez différents cloud proviers (GCP, AWS, Scaleway, etc)
- Etc.
Bénéfices pour l’éditeur
- Expertise sur les pratiques d’automatisation et d’industrialisation des process de développement et de déploiement
- Réduction de la dette technique et remise au carré des outils et des plateformes
- Adoption des outils considérés comme à l’état de l’art
- Fiabilisation des processus de développement et de déploiement
Bénéfices pour CérénIT
- Premier projet professionel en Go
- Premer POC avec Nomad, Consul et Vault
- Travail sur la transimission des pratiques et de la culture de l’automatisation & industrialisation
Web, Ops & Data - Juin 2020
terraform telegraf kubernetes operator rancher longhorn raspberrypi prometheus victoria-metrics monitoring influxdb warp10 forecastJe ne peux résister à mentionner la sortie de l’épisode 100 du BigDataHebdo, podcast où j’ai le plaisir de contribuer. Pour ce numéro spécial (épisode 100 et 6 ans du podcast), nous avons fait appel aux membres de la communauté pour partager avec nous leur base de données favorite, la technologie qui les a le plus impressionée durant ces 6 dernières années et celle qu’ils voient comme majeure pour les 6 prochaines années. Allez l’écouter !
Cloud
- Announcing the Terraform Visual Studio Code Extension v2.0.0 : Hashicorp prend en main le support de l’extension Terraform pour VSCode, en sort une nouvelle version et apporte différentes améliorations comme un meilleur support de Terraform 0.12 et l’utilisation du Terraform Language Server.
Container et orchestration
- Introducing the Telegraf Operator: Kubernetes Sidecars Made Simple : Présentation de l’operator kubernetes pour telegraf qui permet de déployer un agent telegraf sous la forme d’un sidecar dans un pod et de récupérer les métriques associés.
- Kubernetes 1.18.x officiellement disponible chez OVHCloud
- Longhorn Simplifies Distributed Block Storage in Kubernetes : Rancher vient de sortir la version 1.0 de Longhorn. C’est une solution de stockage pour Kubernetes que l’on peut utiliser avec ou sans Rancher. Il faut la voir comme une solution de stockage légère et simple à mettre en oeuvre. Un système de réplication permet d’éviter les pertes de données et d’amélioer la durabilité des données. Des fonctionnalités de backup/restore existent également. Elle semble plus simple à mettre en oeuvre que Rook/Ceph par ex mais sera moins complète que ce dernier.
- Understanding Kubernetes & Understanding Istio : Aurélie Vache réalise des sketchnotes pour vulgariser Kubernetes et Istio. Un joli travail de vulgarisation.
IoT
- 8GB Raspberry Pi 4 on sale now at $75 : Le Raspberry Pi 4 arrive en version 8Go de RAM, Raspberry PI OS arrive en 64 bits, le support du boot sur usb arrive aussi (adieu la SDCard) et plein d’autres choses. Le tout au prix de 75$.
Ops
- Sismology: Iguana Solutions’ Monitoring System : retour d’expérience sur une plateforme de monitoring initiée sur Prometheus et qui évolue vers VictoriaMetrics en prenant les aspects de stockage à long terme, le multi-tenant et la haute disponibilité de la plateforme.
Time Series
- Release Announcement: InfluxDB 2.0.0 Beta 12 : une beta de plus avec l’ajout notamment d’
influx stackspour faire du CRUD sur des groupes de ressources InfluxDB (dashboard, labels, tasks, etc). - Warp 10, The Most Advanced Time Series Platform, now provides multi-architecture docker images. : vous pouvez donc déployer des images docker warp10 sur des plateformes amd64/armv7/arm64.
- May 2020: Warp 10 release 2.6.0 : Pleins d’améliorations et de correctifs et notamment la capacité de dialoguer directement avec Warp10 via le protocole Protobuf ou via Arrow.
- Time series forecasts in WarpScript : Présentation de l’extension Warpscript permettant d’appliquer des algorithmes de prévisions (ARIMA, SARIMA, HOLTWINTERS, etc) sur des séries temporelles. Précision: il s’agit d’une extension propriétaire mais vous pouvez l’évaluer sur la sandbox Warp10 mise à disposition par SenX.
Intégration Gitlab dans Kubernetes pour automatiser ses déploiements
gitlab kubernetes deployment service-account gitlab-ciDepuis que j’ai migré des sites sous kubernetes, j’avais perdu l’automatisation du déploiement de mes conteneurs. Pour ce site, je modifiais donc le site et une fois le git push realisé, j’attendais que Gitlab-CI crée mon conteneur. Je récupérai alors le tag du conteneur que je mettais dans le dépôt git où je stocke mes fichiers de configuration pour kubernetes. Une fois le tag mis à jour, je pouvais procéder au déploiement de mon conteneur. Il était temps d’améliorer ce workflow.
Gitlab propose depuis un moment une intégration avec kubernetes mais je lui trouve quelques inconvénients au regard de mes besoins :
- Il faut créer un compte avec un ClusterRole cluster-admin et je ne suis pas super à l’aise avec cette idée,
- Il est nécessaire de déployer Helm encore en version 2 alors que je suis passé en version 3 pour les rares projets où je l’utilise,
- L’ingress s’appuie sur nginx-ingress, alors que j’utilise Traefik,
- Je n’ai pas l’usage des autres fonctionnalités fournies par Gitlab dans mon contexte de “cluster de test” hébergeant quelques sites et applications web.
Mon besoin pourrait se résumer à pouvoir interagir avec mon cluster au travers de kubectl et de pouvoir y déployer la nouvelle version du conteneur que je viens de créer. Cela suppose alors d’avoir 3 choses :
- le binaire kubectl accessible sous la forme d’un conteneur ou directement en shell dans le runner,
- un fichier
kubeconfigpour m’authentifier auprès du cluster et interagir avec, - la référence de l’image docker fraichement crée par Gitlab-CI à appliquer sur un Deployment kubernetes.
Création d’un compte de service avec authentification par token
Utilisant le service managé d’OVH, je n’ai pas accès à tous les certificats du cluster permettant de créer de nouveaux comptes utilisateurs. Par ailleurs, pour les intégrations comme Gitlab, il est recommandé d’utiliser des Service Accounts. C’est ce que nous allons faire.
En plus du Service Account, il nous faut donner un rôle à notre compte pour qu’il puisse réaliser des actions sur le cluster. Par simplicité pour ce billet, je vais lui donner les droits d’admin au sein d’un namespace. Le compte de service pourra alors faire ce qu’il veut mais uniquement au sein du namespace en question. En cas de fuite du compte, les dégats potentiels sont donc moindres qu’avec un compter qui est admin global du cluster. Le rôle admin existe déjà sous kubernetes, il s’agit du ClusteRole admin mais qui est restreint à un namespace via le RoleBinding.
Créons le fichier gitlab-integtration.yml avec ces éléments :
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: gitlab-example
namespace: example
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: gitlab-admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: admin
subjects:
- kind: ServiceAccount
name: gitlab-example
namespace: example
Déployons notre configuration sur le cluster :
# Apply yml file on the cluster
kubectl apply -f gitlab-integration.yml
serviceaccount/gitlab-example created
rolebinding.rbac.authorization.k8s.io/gitlab-admin created
Pour alimenter notre fichier kubeconfig, il nous faut récupérer le token :
# Get secret's name from service account
SECRETNAME=`kubectl -n example get sa/gitlab-example -o jsonpath='{.secrets[0].name}'`
# Get token from secret, encoded in base64
TOKEN=`kubectl -n example get secret $SECRETNAME -o jsonpath='{.data.token}'`
# Decode token
CLEAR_TOKEN=`echo $TOKEN |base64 --decode`
En prenant votre fichier kubeconfig de référence, vous pouvez alors créer une copie sous le nom kubeconfig-gitlab-example.yml et l’éditer de la façon suivante :
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: <Existing certificate in a base64 format from your original kubeconfig file>
server: <url of your k8s http endpoint like https://localhost:6443/ >
name: kubernetes # adjust your cluster name
contexts:
- context:
cluster: kubernetes # adjust your cluster name
namespace: example # adjust your namespace
user: gitlab-example # adujust your user
name: kubernetes-ovh # adujust your context
current-context: kubernetes-ovh # adujust your context
kind: Config
preferences: {}
users:
- name: gitlab-example # adujust your user
user:
token: <Content of the CLEAR_TOKEN variable>
Vous pouvez tester son bon fonctionnement via :
# Fetch example resources if any:
kubectl --kubeconfig=./kubeconfig-gitlab-example.yml get all
...
# Check you can't access other namespaces information, like kube-system:
kubectl --kubeconfig=./kubeconfig-gitlab-example.yml get all -n kube-system
Error from server (Forbidden): pods is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "pods" in API group "" in the namespace "kube-system"
Error from server (Forbidden): replicationcontrollers is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "replicationcontrollers" in API group "" in the namespace "kube-system"
Error from server (Forbidden): services is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "services" in API group "" in the namespace "kube-system"
Error from server (Forbidden): daemonsets.apps is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "daemonsets" in API group "apps" in the namespace "kube-system"
Error from server (Forbidden): deployments.apps is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "deployments" in API group "apps" in the namespace "kube-system"
Error from server (Forbidden): replicasets.apps is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "replicasets" in API group "apps" in the namespace "kube-system"
Error from server (Forbidden): statefulsets.apps is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "statefulsets" in API group "apps" in the namespace "kube-system"
Error from server (Forbidden): horizontalpodautoscalers.autoscaling is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "horizontalpodautoscalers" in API group "autoscaling" in the namespace "kube-system"
Error from server (Forbidden): jobs.batch is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "jobs" in API group "batch" in the namespace "kube-system"
Error from server (Forbidden): cronjobs.batch is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "cronjobs" in API group "batch" in the namespace "kube-system"
Integration Gitlab : stocker le kubeconfig
Gitlab permet de stocker des variables. Dans le cas d’un fichier kubeconfig, on va vouloir ne jamais afficher son contenu dans les logs ou autre. Pour cela il est possible de masquer vos variables en respectant quelques contraintes et notamment que la valeur de la variable tienne sur une seule ligne.
Nous allons donc encoder le fichier en base64 et rajouter un argument pour que tout soit sur une seule ligne (et non pas sur plusieurs lignes par défaut):
# create a one line base64 version of kubeconfig file
cat kubeconfig-gitlab-example.yml | base64 -w 0
Copier le contenu obtenu dans une variable que nous appelerons KUBECONFIG et dont on cochera bien la case “Mask variable”. Une fois la variable sauvée, vous avez ceci :
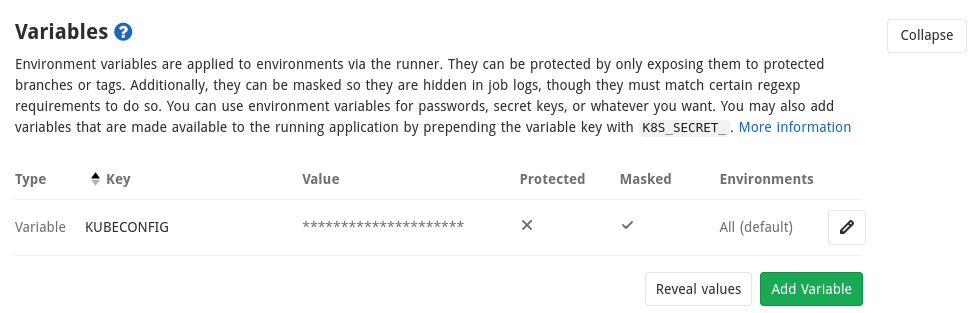
Intégration Gitlab : passer la référence de l’image au job de déploiement
Soit le fichier .gitlab-ci.yml suivant:
---
stages:
- publish
- image
- deploy
publish:
image: $CI_REGISTRY/nsteinmetz/hugo:latest
artifacts:
paths:
- public
expire_in: 1 day
only:
- master
- web
script:
- hugo
stage: publish
tags:
- go
docker:
stage: image
image: docker:stable
services:
- docker:dind
variables:
DOCKER_HOST: tcp://docker:2375
DOCKER_DRIVER: overlay2
RELEASE_IMAGE: $CI_REGISTRY_IMAGE:$CI_COMMIT_SHORT_SHA-$CI_PIPELINE_ID-$CI_JOB_ID
before_script:
- docker login -u gitlab-ci-token -p $CI_JOB_TOKEN $CI_REGISTRY
script:
- echo "IMAGE=${RELEASE_IMAGE}" >> docker.env
- docker build --pull -t $RELEASE_IMAGE .
- docker push $RELEASE_IMAGE
when: on_success
tags:
- go
artifacts:
reports:
dotenv: docker.env
kube:
stage: deploy
script:
- echo $KUBECONFIG | base64 --decode > kubeconfig
- export KUBECONFIG=`pwd`/kubeconfig
- sed -i -e "s|IMAGE|${IMAGE}|g" deployment.yml
- kubectl apply -f deployment.yml
needs:
- job: docker
artifacts: true
when: on_success
tags:
- shell
Petite explication rapide :
- l’étape
publishva générer la version html du site et la stocker sous la forme d’un artefact qui sera passé aux jobs suivants, - l’étape
dockerva créer l’image en mettant l’artefact du job précédent dans un conteneur nginx et le publier dans la registry gitlab avec le nom suivantgitlab.registry/group/project:<short commit>-<pipeline id>-<job id> - l’étape
kubeva récupérer le contenu de la variableKUBECONFIG, le décoder et créer un fichierkubeconfig. On initialise la variable d’environnementKUBECONFIGpour que kubectl puisse l’utiliser. On met à jour la référence de l’image docker obtenue précédemment dans le fichierdeployment.ymlqui sert de modèle de déploiement. On applique le fichier obtenu sur le cluster kubernetes pour mettre à jour le déploiement.
Le point d’attention ici est que le passage de la variable RELEASE_IMAGE se fait via un dotenv qui est créé sous la forme d’un artefact à l’étape docker et est donc disponible à l’étape kube. Cela devrait être automatique mais j’ai ajouté une dépendance explicite via la directive needs. Lors de l’étape kube, le contenu du fichier docker.env est disponible sous la forme de variables d’environnement. On peut alors faire la substitution de notre placeholder par la valeur voulue dans deployment.yml.
Tout ce mécanisme est expliqué dnas la doc des variables gitlab et sur les variables d’environnement héritées. Attention, il vous faut Gitlab 13.0+ pour avoir cette fonctionnalité et en plus, il faut préalablement activer ce feature flag.
sudo gitlab-rails console
Feature.enable(:ci_dependency_variables)
En conclusion, nous avons vu comment :
- Créer un compte de service (Service Account) sous kubernetes avec un rôle d’administrateur de namespace,
- Stocker le fichier
kubeconfigutilisant notre service account dans Gitlab sous la forme d’une variable masquée, - Passer une référence d’un job à un autre via les dotenv au niveau du job amont et les variables d’environnement au niveau du job en aval,
- Récupérer le contenu de la variable kubeconfig pour créer une variable d’environnement et être en mesure d’utiliser kubectl.
Ainsi, toute mise à jour de master conduira à une mise à jour du déploiement associé au sein du cluster kubernetes et ne nécessitera plus d’interventions manuelles comme précédemment. Avec un service account lié à un namespace, on évite aussi de s’exposer inutilement en cas de fuite des identifiants.
