Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Exporter les métriques Traefik dans InfluxDB dans un contexte Kubernetes
kubernetes traefik influxdb métrique timeseriesTraefik, depuis sa version V1, permet d’envoyer des métriques vers différents backends (StatsD, Prometheus, InfluxDB et Datadog). J’ai enfin pris le temps d’activer cette fonctionnalité et de creuser un peu le sujet étant donné que le dashboard de Traefik V2 n’affiche plus certaines de ses statistiques.
La documentation de Traefik sur le sujet :
Commençons par créer une base traefik dans InfluxDB (version 1.7.8)
influx
Connected to http://localhost:8086 version 1.7.8
InfluxDB shell version: 1.7.9
> auth
username: XXX
password: XXX
> CREATE DATABASE traefik
> CREATE USER traefik WITH PASSWORD '<password>'
> GRANT ALL ON traefik to traefik
> SHOW GRANTS FOR traefik
database privilege
-------- ---------
traefik ALL PRIVILEGES
> quit
Dans mon cas, l’accès à InfluxDB se fait en https au travers d’une (autre) instance Traefik. J’utilise donc la connexion en http plutôt qu’en udp.
Cela donne les instructions suivantes en mode CLI :
--metrics=true
--metrics.influxdb=true
--metrics.influxdb.address=https://influxdb.domain.tld:443
--metrics.influxdb.protocol=http
--metrics.influxdb.database=traefik
--metrics.influxdb.username=traefik
--metrics.influxdb.password=<password>
J’ai gardé les valeurs par défaut pour addEntryPointsLabels (true), addServicesLabels (true) et pushInterval (10s).
Cela donne le Deployment suivant :
apiVersion: apps/v1
kind: Deployment
metadata:
name: traefik2-ingress-controller
labels:
k8s-app: traefik2-ingress-lb
spec:
replicas: 2
selector:
matchLabels:
k8s-app: traefik2-ingress-lb
template:
metadata:
labels:
k8s-app: traefik2-ingress-lb
name: traefik2-ingress-lb
spec:
serviceAccountName: traefik2-ingress-controller
terminationGracePeriodSeconds: 60
containers:
- image: traefik:2.0.6
name: traefik2-ingress-lb
ports:
- name: web
containerPort: 80
- name: admin
containerPort: 8080
- name: secure
containerPort: 443
readinessProbe:
httpGet:
path: /ping
port: admin
failureThreshold: 1
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 2
livenessProbe:
httpGet:
path: /ping
port: admin
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 2
args:
- --entryPoints.web.address=:80
- --entryPoints.secure.address=:443
- --entryPoints.traefik.address=:8080
- --api.dashboard=true
- --api.insecure=true
- --ping=true
- --providers.kubernetescrd
- --providers.kubernetesingress
- --log.level=ERROR
- --metrics=true
- --metrics.influxdb=true
- --metrics.influxdb.address=https://influxdb.domain.tld:443
- --metrics.influxdb.protocol=http
- --metrics.influxdb.database=traefik
- --metrics.influxdb.username=traefik
- --metrics.influxdb.password=<password>
Appliquer le contenu du fichier dans votre cluster Kubernetes
kubectl apply -f deployment.yml -n <namespace>
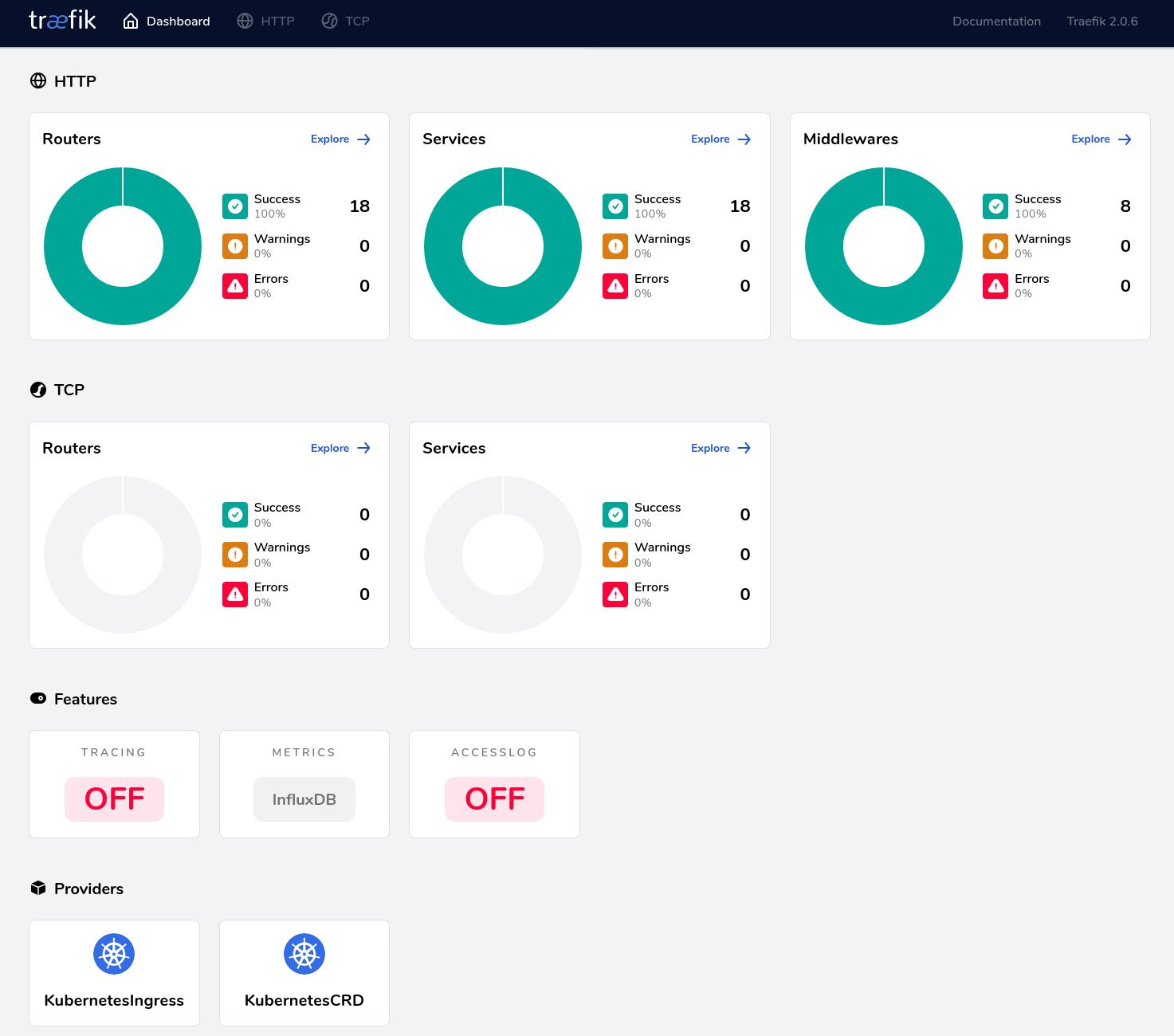
Sur le dashboard Traefik, dans la section “Features”, la boite “Metrics” doit afficher “InfluxDB”, comme ci-dessous :
Vous pouvez alors vous connecter à votre instance InfluxDB pour valider que des données sont bien insérées :
influx
Connected to http://localhost:8086 version 1.7.8
InfluxDB shell version: 1.7.9
> auth
username: traefik
password:
> use traefik
Using database traefik
> show measurements
name: measurements
name
----
traefik.config.reload.lastSuccessTimestamp
traefik.config.reload.total
traefik.entrypoint.connections.open
traefik.entrypoint.request.duration
traefik.entrypoint.requests.total
traefik.service.connections.open
traefik.service.request.duration
traefik.service.requests.total
Il ne vous reste plus qu’à utiliser Chronograf ou Grafana pour visualiser vos données et définir des alertes.
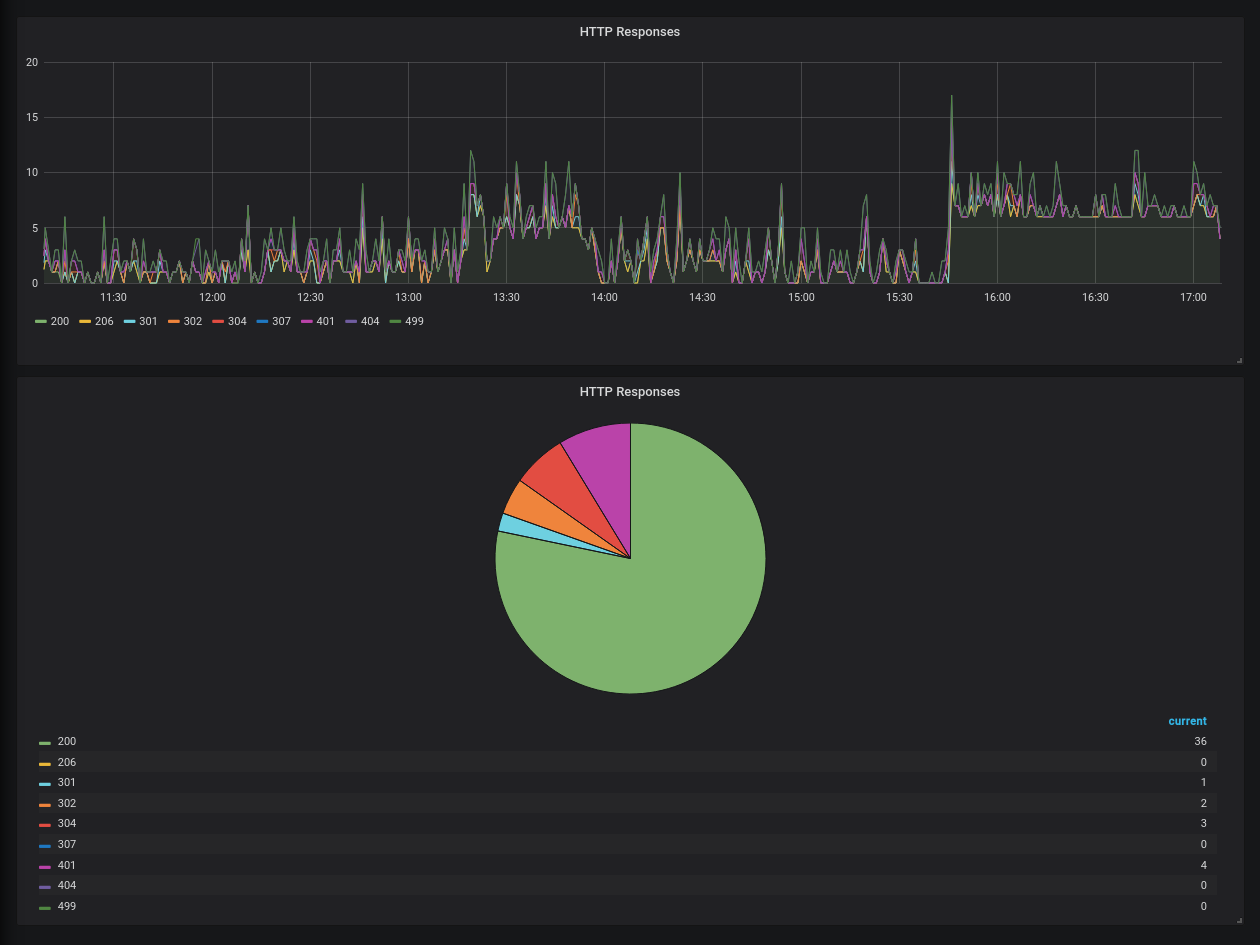
Un exemple rapide avec la répartition des codes HTTP dans Grafana :
Web, Ops & Data - Aout 2019
gitlab ci cd continous integration continous deployment git diff docker rpi traefik kubernetes ovh helm postgres percona aws partiql redis timeseries influxdb kafka prometheusSurveillez le Time Series Paris Meetup, car la première édition du Meetup sera annoncée mardi avec une présentation des usages avancées des séries temporelles avec Warp10 (comprendre au-delà du monitoring classique) et une présentation par les équipes OVH sur du monitoring de datacenter aidé par du machine learning et leur offre Préscience.
CI/CD
- How to trigger multiple pipelines using GitLab CI/CD : depuis une pipeline d’un dépôt gitlab, il va être possible d’appeler les pipelines des autres projets gitlab. Une fonctionnalité intéressante et qui pourrait lever la dépendance à Jenkins lorsque l’on a des pipelines un peu complexes et inter-projets.
- New up and coming GitLab CI/CD Features : bilan et perspectives par le responsable produit de gitlab sur les fonctionnalités CI/CD qui ont été rajoutées cette année et celles à venir.
Code
- Highlights from Git 2.23 : Tentative de remplacement de
git checkoutpargit switchetgit restorepour mieux encadrer les usages - Create Git diffs with proper function context : améliorer vos diff git avec une meilleure prise en compte du langage avec lequel vous travaillez.
Conteneurs & orchestration
- Releasing HypriotOS 1.11.0: Docker 19.03.0 CE from Raspberry Pi Zero to 4 B : la distribution HypriotOS, pour raspberry pi, sort une nouvelle version avec les dernières versions de docker, docker-compose, etc.
- OVH 1.15 Certified : Le service managé kubernetes d’OVH passe en version 1.15
- Traefik Release: v2.0.0-beta1 & Traefik Release: v2.0.0-rc1 : Traefik 2.0 commence à pointer le bout de son nez et les connecteurs docker / kubernetes notamment sont prêts, ainsi que plein d’autres choses.
- Helm 3.0.0-beta.1 : Helm 3.0 émerge doucement et on commence à se rendre compte des petits changements qui vont arriver…
SQL
- Percona Distribution for PostgreSQL 11 (Beta) Is Now Available : Percona est connu pour son expertise autour de MySQL, de leur serveur et des outils qu’ils ont créés autour. Ils semblent vouloir faire la même chose avec Postgres. Cela semble prometteur !
- Announcing PartiQL: One query language for all your data : AWS lance un langage visant à être un requêteur universel de données structurées et non structurées en SQL. C’est en open source et pour le moment cela traite surtout les données des services AWS, ainsi que Couchbase.
time series
- RedisTimeSeries GA – Making the 4th dimension truly immersive : RedisLabs met à disposition un module permettant d’améliorer l’expérience utilisateur des développeurs manipulant des séries temporelles dans Redis. Ce module n’a a priori pas pour vocation à ce stade d’intégrer le coeur du produit.
- How Hulu Uses InfluxDB and Kafka to Scale to Over 1 Million Metrics a Second : retour d’expérience sur l’utilisation d’influxdb et kafka chez Hulu pour ingérer et apporter de la résilience à leurs données temporelles.
- How to use Prometheus for anomaly detection in GitLab : retour d’expérience de gitlab sur l’utilisation de Prometheus dans un contexte de détection d’anomalies.
InfluxDays London 2019
influxdays influxdb influxcloud timeseries tick influxdata influxaceLa cinquième édition des InfluxDays (et la seconde édition en Europe) s’est tenue à Londres les 13 et 14 juin 2019. Les InfluxDays sont organisés par la société InfluxData, éditrice des produits Telegraf, InfluxDB, Chronograf et Kapacitor, connu aussi sous le nom de la stack TICK. Il s’agit d’une plateforme de gestion des données temporelles, depuis leur ingestion jusqu’à leur visualisation et leur traitement en passant par leur stockage. Durant ces deux jours, des présentations portent sur les produits, leurs évolutions, des retours d’expériences clients et plus généralement sur l’écosystème.
Sur InfluxData, quelques chiffres :
- 230.000 installations d’InfluxDB dans le monde
- 200+ plugins telegraf (agent de collecte)
- 600+ clients InfluxData
- 140+ employés
Avant de rentrer dans la synthèse, il faut que vous sachiez que j’ai été nominé “InfluxAce” pour la France. Ce titre permet à InfluxData de reconnaitre et promouvoir les experts de la stack TICK et de les remercier pour leur contribution à la communauté et à l’évangélisation de leurs produits. Deux autres personnes en Belgique et au Luxembourg ont été nominées également.
Si vous voulez un résumé assez détaillé, je vous invite à lire celui d’Antoine Solnichkin (en anglais) qui n’est autre que notre InfluxAce luxembourgeois.
Les principaux enseignements pour moi d’InfluxDays :
- Influx 2.0 : de la stack TICK à une plateforme unifiée : en réintégrant les fonctionnalités de visualisation et de traitement des données dans la base elle-même, les composants “ICK” deviennent un produit unifié et plus intégré. L’idée est de pouvoir manipuler ses données très rapidement sans avoir à installer et paramétrer plusieurs composants. Telegraf n’est pas en reste car la configuration pourra être générée depuis Influx 2.x et Telegraf pourra même récupérer sa configuration via l’API.
- Influx 2.0 : une plateforme composable et extensible : en adoptant une approche API first (en plus d’avoir été unifiée et rendue plus cohérente entre les produits), InfluxData permet des intégrations plus aisées et met aussi une CLI ou un REPL plus riches à disposition de ses utilisateurs. InfluxData travaille aussi sur l’extensibilité de sa solution via des “packages” pour Flux et Telegraf notamment. Ces packages permetteront d’apporter sa propre logique dans la plateforme (plugins telegraf pour la collecte des données, fonctions flux pour le traitement des données, modèles de dashboards, modèles de tâches, etc).
- Influx 2.0, une plateforme “… as Code” : la solution étant extensible et une API permettant d’interagir avec elle, il sera donc possible de versionner de versionner le code des différents éléments et de les déployer via l’API proposée par Influx. Des mécanismes de templates vont aussi permettre aux utilisateurs de ne pas démarrer avec l’angoisse de la feuille vide mais au contraire d’avoir des bonnes pratiques ou des règles de gouvernance sur la façon de gérer les données.
- Influx 2.0, un hub pour vos données temporelles : Flux, le nouveau langage pour interagir avec les données, se veut être en mesure de résoudre les limites d’InfluxQL sur la manipulation des données temporelles mais aussi de pouvoir aller requêter des sources de données tierces dans le cadre de l’enrichissement / le nettoyage des données. Des réflexions sur la gestion de datasources plus traditionnelles est en cours. Flux va également être en mesure de s’interfacer avec d’autres sources de données comme Prometheus (dont une démonstration du transpiler a été faite). Cette capacité de transpilation peut ainsi permettre de connecter Grafana à Influx 2.x via une datasource Prometheus et de continuer à avoir des requêtes PromQL. De la même façon, Flux pourrait être utilisé pour permettre la migration Influx 1.x vers Influx 2.x par ex sous Grafana sans avoir à toucher aux requêtes de ses dashboards.
- Influx (2.0), c’est en fait trois produits avec du code partagé entre eux : InfluxDB OSS, InfluxDB Entreprise et InfluxCloud. La version cloud devrait passer en production cet été, Influx 2.x OSS devrait passer en bêta cet été et finir en GA fin 2019 / début 2020 et Influx 2.x Entreprise arrivera en 2020. InfluxCloud se déploie sur Kubernetes et chaque composant est modulaire et scalable et s’appuie aussi sur Kafka quand InfluxDB OSS 2.x restera un binaire unique en Go.
D’autres présentations ont permis de mieux comprendre le moteur de stockage d’InfluxDB, comment faire un plugin Telegraf ou bien d’avoir des retours clients intéressants.
Au final, et indépendamment de ma nomination, ce fut deux jours très intéressants pour mieux appréhender la plateforme, son fonctionnement interne, les évolutions à venir et voir différents cas d’utilisation. Ce fut enfin l’occasion de rencontrer les équipes InfluxData avec qui j’ai passé un très bon moment et il est toujours agréable de pouvoir poser ses questions au CTO et CEO d’InfluxData sur le produit ou le marché des données temporelles. Ce fut également très intéressant de discuter avec différents membres de la communauté.
Vous devriez pouvoir accéder aux vidéos et slides de l’événement via le site de l’événement d’ici quelques jours.
Un meetup “timeseries” va être organisé en France entre septembre et la fin d’année par votre serviteur et avec le support d’InfluxData.. Si vous êtes intéressés, inscrivez-vous au meetup “Paris Time Series Meetup”. Il se veut ouvert à tout l’écosystème des séries temporelles et si vous avez des idées/envies/…, n’hésitez pas à me contacter ou via le Meetup ou encore twitter.
SAFT
audit faisabilité timeseries influxdb sécuritéContexte
La SAFT, filiale du groupe Total, a lancé un prototype pour le suivi d’équipements connectés. Elle se pose des questions sur l’opportunité d’utiliser une base de données pour les séries temporelles et sur le niveau de sécurité de son application web. Pour répondre à ces questions, un audit de trois jours a été réalisé.
Notre réponse
Sur la partie base de données temporelles :
- Présentation de la plateforme TICK (Telegraf, InfluxDB, Chronograf et Kapacitor)
- Evaluation sur la structure, le nombre et la fréquence des messages
- Evaluation de l’intégration de la plateforme TICK au sein du projet
- Installation des composants de la plateforme TICK pour permettre une évaluation plus complète
Sur la partie sécurité :
- Revue de l’écosystème de l’application et identification des principales sources de vulnérabilités,
- Analyse du serveur et de sa procédure d’installation et d’exploitation,
- Analyse rapide de l’application pour identifier d’éventuelles erreurs en matière de sécurité (gestion des droits, gestion de la visibilité des contenus, etc),
- Point sur la gestion des identifiants et de la gestion d’un poste de développement en général,
- Partage des bonnes pratiques en matière de développement, en vue du déploiement et de l’expoitaiton de l’application.
Bénéfices
- Expertise sur la plateforme TICK (Telegraf, InfluxDB, Chronograf et Kapacitor)
- Expertise sur les plateformes web (conception, développement, déploiement, sécurité)
Web, Ops & Data - Avril 2019
influxdb timescaledb traefik kubernetes ssh-agent postgres recherche docker log google cloud next serverless apm glowroot docker registryDeux petites annonces pour démarrer cette édition :
- Je serai à KubeCon EU du 20 au 23 Mai à Barcelone. Si vous y allez aussi, dites le moi, ce sera une occasion de se rencontrer.
- Le BigData Hebdo a ouvert son slack - Vous pouvez nous rejoindre par vous même via ce lien
APM
- Glowroot : Pour ceux qui s’intéressent au sujet de l’APM et qui ne veulent pas aller chez AppDynamics, Dynatrace ou Elastic, j’ai assisté à une démo intéressante sur Glowroot - il est forcément moins riche que ces concurrents mais il a l’air de faire l’essentiel de ce que l’on peut attendre d’un APM. Il ne marche qu’avec la JVM.
Cloud
- Big Data Hebdo - Episode 71 : Google Cloud Next 19 : Vincent et Jérome passent en revue les annonces de Google Cloud Next 2019, en plus de nous faire un analyse fine de MS Excel vs Google Sheets ;-) - Personnellement, je retiens surtout Anthos (le kubernetes distribué multi-cloud et on-premise), Cloud Run (la capacité à exécuter des conteneurs dans une logique serverless et basé sur knative - il me fait penser à OpenFaaS) et Cloud Code (extension pour l’IDE VSCode et prochainement IntelliJ pour gérer plus facilement des déploiements Kubernetes). Vous retrouvrez les 122 annonces sur le blog de Google Cloud et les vidéos sont sur la chaine Youtube associée
Container et Orchestration
- Kubernetes 1.14: Production-level support for Windows Nodes, Kubectl Updates, Persistent Local Volumes GA : les noeuds Windows et les conteneurs Windows sont supportés officiellement, kubectl se voit améliorer et bénéficie d’un nouveau site de documentation et se dote d’une intégration de kustomize. Les volumes locaux persistant passent en bêta et plein d’autres choses encore.
- Kubernetes 1.14: Local Persistent Volumes GA : les volumes locaux persistants sont intéressants car ils vont permettre de déployer un conteneur sur un même noeud de façon assurée dès lors que ce volume est défini. Cela n’est certes pas très résilient, mais cela peut réponre à un certain nombre de besoins. Les cas d’usages sont très bien décrits dans ce billet et peuvent donner des idées.
- Announcing General Availability of Traefik Enterprise Edition : la version Entreprise de Traefik est disponible officiellement. Elle adresse principalement le cas d’un déploiement haute disponibilité de Traefik avec la mise en place d’un data plane et d’un controle plane pour gérer tout ça.
- CNCF to Host CRI-O : le runtime de conteneurs développé par Red Hat et Google rejoint la fondation CNCF au stade de l’incubation.
- Introducing Kraken, an Open Source Peer-to-Peer Docker Registry : Uber vient de mettre à disposition Kraken, une “registry docker” pair à pair. Le nombre d’acteurs intéressés par ce genre de projet doit être assez faible mais sait-on jamais…
DevOps
- JSON as configuration files: please don’t : Si certains pensaient utiliser JSON pour décrire des fichiers de configurations, l’article rappelle que JSON n’est qu’un format d’échange de données et surtout pas de fichiers de configuration. On peut comprendre la tentation mais on a déjà bien assez à faire avec YAML, INI voire XML. Aucun n’est parfait certes mais pas la peine d’en rajouter.
- In Defense of YAML : L’auteur critique l’abus autour de YAML pour l’utiliser pour tout et n’importe quoi. Comme format de données, il est utilisable mais nous voyons des détournements où du yaml devient du pseudo code. L’auteur cite la CI Gitlab ou encore Tekton. On ne peut que lui donner raison. Il serait plus simpe d’avoir un vrai langage de programmation plutôt que de tout “YAMLiser”.
Licences
- Deprecation Notice: MIT and BSD (via Les Cast Codeurs) : Intéressant, les licences BSD/MIT serait à considérer comme dépréciée. L’auteur travaille pour le Blue Oak Council qui publie la licence du même nom. On peut éventuellement lui reprocher un certain biais mais il indique quand même que des licences modernes (comme ASL 2.0) seraient plus judicieuses que de rester sur du MIT/BSD.
Sécurité
- Les serveurs de Matrix.org ont été compromis - l’équipe a joué la transaprence et donne les informations laissées par l’attaquant sur les failles existantes et les bonnes pratiques qu’il faut en déduire. C’est l’occasion de revoir notamment les options de ssh-agent pour éviter de telles mésaventures.
SQL
- La recherche plein texte avec Postgresql : Présentation des tsvector et tsquery, deux fonctions postgres pour faire de la recherche plein texte.
Timeseries
- Introducing Outflux: a smart way out of InfluxDB : l’équipe de TimescaleDB, l’extension Postgres qui permet de manipuler des données temporelles, sort son outil de migration des données d’InfluxDB vers TimescaleDB.
Astuce du mois : gestion de la rotation des logs d’un container docker
Dans les bonnes pratiques Docker, il est dit d’utliser stdout/stderr pour avoir les logs de votre conteneur via docker logs. Toutefois, cette pratique va alimenter un fichier de log /var/lib/docker/containers/<container id>/<conteiner id>-json.log. Ce fichier peut donc saturer votre disque et aller jusqu’à corrompre vos conteneurs. L’autre bonne pratique étant que tout fichier de log doit avoir une politique de rotation du fichier associée pour éviter toute saturation de disque ou d’avoir des trop gros fichiers de logs.
Docker permet de configurer le driver de logs au niveau du démon (via /etc/docker/daemon.json), en argument lors d’un docker run ou dans docker-compose.yml.
Si l’on reste sur le driver json-file et que l’on veut piloter la rotation des logs au niveau de docker-compose.yml, cela donne par ex (version simplifiée) :
version: '3'
services:
service_xxx:
image: docker_image_xxx
[...]
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "10"
Vous pouvez alors définir une stratégie de rotation des logs par container si vous le souhaitez. Ainsi, vous gérer la taille maximale de logs qui vont être générés et êtes ainsi assurés de ne pas avoir de mauvaises surprises à ce niveau là.
