Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Web, Ops & Data - Décembre 2020
docker runc rootless swarm cgroups kubernetes cri dockershim vector aws timestream warp10 dashboard ptsm timescale centos rhel podman influxdb timeseriesContainers et orchestration
- Electro Monkeys #37 – Podman, l’alternative de Redhat à Docker avec Benjamin Vouillaume : je me demandais si podman permettait un management de containers à distance et l’étendue de son écosystème. Le podcast permet de compléter le tour du propriétaire et de se faire une bonne idée de son positionnement.
- How to deploy on remote Docker hosts with docker-compose : dans la même quête, je me demandais s’il était possible de piloter un noeud docker à distance quand je me suis rappelé qu’il était possible de le faire au travers d’une connexion ssh. En creusant un peu plus, j’ai découvert la notion de contexte qui permet ainsi de cibler un noeud docker, docker swarm ou kubernetes.
- Don’t Panic: Kubernetes and Docker et Dockershim Deprecation FAQ : A partir de kubernetes 1.20 (fin 2020) et définitivement à partir de la version 1.23 (fin 2021), le retrait du binaire docker comme CRI de Kubernetes est annoncé. Cela ne devrait pas changer grand chose et c’est essentiellement de la plomberie interne. Plutôt que de passer par Dockershim qui implémentait l’interface CRI et qui discutait ensuite avec Docker pour lancer les conteneurs via containerd, l’appel sera directement fait à containerd. Il n’y a que ceux qui montent la socket docker dans les pods qui vont avoir un souci. Si c’est pour builder des images, il y a des alternatives comme
img,kaniko, etc. Pour les autres cas, il faudra peut être passer par l’API kubernetes ou trouver les alternatives qui vont bien. - What developers need to know about Docker, Docker Engine, and Kubernetes v1.20 et Mirantis to take over support of Kubernetes dockershim : Mirantis et Docker Inc vont assurer le support de cette interface
dockershimpour permettre à ceux qui ont en besoin de pouvoir continuer à l’utliiser. La limite étant que si vous êtes sur du service managé et que votre provider ne le fournit pas, vous ne pourrez pas l’utiliser… - Kubernetes 1.20: The Raddest Release : voilà, la version 1.20 est sortie et apporte son lot de nouveautés et de stabilisation.
- Announcing General Availability of HashiCorp Nomad 1.0 : Nomad 1.0 est également disponible.
- Introducing Docker Engine 20.10 - Docker Blog : Docker 20.10 arrive avec des profondes nouveautés comme le support des cgroupsv2 et un mode rootless,
docker logsfonctionne avec tous les drivers de log et non unqiement json & journald et plein d’autres améliorations/harmonisations au niveau de la CLI. Pour ceux sous Fedora qui avaient bidouillé avec firewalld précédemment pour faire fonctionner docker et qui ont un problème lié à l’interface docker0 au démarrage du service docker, allez voir par ici. - Docker Engine Release Notes - Version 20.10 : En plus des points précédents, il y a l’arrivée des jobs dans swarm - depuis le temps que je l’attendais 🤩 (même si on peut se toujours se poser la question de la pérénnité de swarm depuis qu’il a été racheté par Mirantis)
- New features in Docker 20.10 (Yes, it’s alive) : un billet décrivant plus en détail certaines feautres de docker 20.10 comme support Fedora/CentOS, le rootless mode, l’option
-mount, les jpbs swarm et une synthèse de l’actualité de l’écosystème docker. - Podman Release 2.2.0 : ajout des commandes
network (dis)connect, support des alias avec des noms courts, amélioration des commandesplay|generate kubeet capacité de monter une image OCI dans un container.
Observabilité
- Vector - Collect, transform, & route all observability data with one simple tool. (via) : vector est un outil en rust qui permet de collecter et manipuler des métriques/logs/événements et de les envoyer vers différentes destinations. De quoi remplacer filebeat/journalbeat voire même telegraf ? ;-)
- Our new partnership with AWS gives Grafana users more options : AWS vient d’annoncer un service managé pour Prometheus basé sur Cortex et pour Grafana (version Entrepsise). Grafana et Cortex étant des projets édités par Grafana Labs sous licence OSS (et des déclinaisons Cloud et Entreprise). AWS changerait-il sa façon de travailler avec les projets OSS lorsqu’il souhaite en faire des services managés et prendre ainsi une attitude plus positive vis à vis de la communauté OSS ?
OSS
- Death of an Open Source Business Model : Analyse du passage de Mapbox GL JS v2 sous licence propriétaire, le modèle de l’open core et les menaces des top cloud providers sur le reste de l’économie du logiciel. On peut étendre cela aussi “VC funded OSS company”.
Système
- CentOS Project shifts focus to CentOS Stream, CentOS Stream: Building an innovative future for enterprise Linux et la FAQ associée : Historiquement CentOS Linux était batie sur les sources de Red Hat Entreprise Linux un fois celle-ci disponible. CentOS Stream renverse un peu la tendance avec un cycle d’intégration plutôt Fedora -> CentOS Stream -> RHEL. L’initiative CentOS Stream avait été annoncée en septembre 2019 et ce changement permet donc aux équipes CentOS de se focoaliser sur une seule version (CentOS Stream) et non plus deux versions (CentOS Stream et CentOS Linux). CentOS Linux 7 sera maintenue jusqu’à la fin du support de RHEL 7 et et CentOS 8 jusqu’à fin 2021 (et non pas 2029 comme prévu). Il n’y aura pas de version 9 de CentOS Linux. A tester pour voir si CentOS Stream est plus stable que Fedora mais moins conservateur que RHEL et pourrait alors s’avérer être un bon compromis.
- Before You Get Mad About The CentOS Stream Change, Think About… : un billet assez long d’un employé de Red Hat qui exprime son opinion et cherche à remettre les choses en perspective en dépassionnant le débat.
Time Series
- PTSM Edition #8 - Amazon TimeStream 101 : Edition du Paris time Series Meetup sur AWS Timestream
- TimescaleDB vs. Amazon Timestream: 6000x higher inserts, 5-175x faster queries, 150x-220x cheaper : avec toutes les réserves habitudelles sur les benchmarks, Timescale a comparé son produit avec AWS Timestream et la conclusion semble clairement en faveur de Timescaledb. A noter que l’update des données est arrivé dans AWS Timestream entre temps.
- Truly Dynamic Dashboards as Code : les équipes de SenX ont implémenté leur vision du “Dashboards as Code” sous le nom Discovery. Discovery veut aller plus loin que la simple description d’un dashboard comme on peut le voir dans Grafana ou InfluxDB 2.0 en apportant une touche de dynamisme et de génération dynamique des dashboards en fonction des élements obtenus (ex si valeur X > Y alors afficher la procédure AAA de résolution d’incident). J’ai commencé à jouer avec, un billet de blog sur ce sujet devrait bientôt arriver.
- NeuralProphet : un modèle neuronal orienté série temporelles, inspiré de Facebook Prophet et développé avce PyTorch.
- Release Notes InfluxDB 2.0.3 et Release Announcement: InfluxDB OSS 2.0.3 : build arm64 en preview, un petit conflit de packaging entre
influxdbetinfluxdb2à passer pour ceux qui étaient déjà en 2.0 et ceci afin d’éviter que des gens en 1.x passent involontairement en 2.x, le “delete with predicate” a été réactivé, améliorations sur le process d’upgrade, des commandes autour des actions en mode V1, mise à jour de flux, et plein d’autres corrections/améliorations.
Web
- Web Almanac 2020 - Rapport annuel de HTTP Archive sur l’état du Web : une synthèse de l’état du web d’après HTTP Archive sur une base de 7.5 millions de sites testés, soit 31.3 To de données traitées. De quoi relativisez un peu les biais de notre bulle technologique : non tout le monde ne fait pas du React/Angular/Vue.js par ex mais plutôt du JQuery ! Suivant vos usages, plein d’enseignements et de choses intéressantes à tirer de cette synthèse.
Il ne me reste plus qu’à vous souhaiter de bonnes fêtes de fin d’année et on se retrouve l’année prochaine !
Web, Ops & Data - Novembre 2020
vitess mysql kubernetes helm mesos influxdb arrow parquet scp sftp gke gcp observability monitoring dig dns dog rust ovhcloud gitCe soir, il y a la 8ème édition du Paris Time Series Meetup sur AWS TimeStream.
Cloud
- OVHcloud et Google Cloud annoncent un partenariat stratégique pour co-construire une solution de confiance en Europe : Les service Anthos de Google seront disponibles dans les infrastructures et hébergés par les équipes OVHCloud. Cela peut être intéressant pour ceux qui ont envie d’utiliser les services Google (sous réserve qu’ils soient disponible dans une version Anthos) tout en gardant les données à l’abri du cloud act (à vérifier en détail - notamment ce qu’il se gère ou pas au travers de la console cloud google). Une initiative intéressante pour le moins.
- New Clever Cloud Zones on top of OVHcloud in APAC and EMEA : Clever Cloud profite de son partenariat avec OVHCloud pour se déployer également dans de nouvelles zones (Roubaix, Sidney, Sinagpour, et Varsovie).
- Terraform 0.14 Adds the Ability to Redact Sensitive Values in Console Output : Terraform 0.14 (beta) n’affichera plus les informations marquées comme sensibles dans les informations qu’il affiche.
- Terraform 0.14 Adds a New Concise Diff Format to Terraform Plans : Terraform 0.14 (beta) proposera aussi un diff plus compact permettant de mieux appréhender les différences d’un plan à l’autre.
Code
- git-filter-repo : si vous avez besoin de manipuler votre dépot git, comme par ex le fait de déplacer un projet git dans un autre en gardant l’historique, alors git-filter-repo permet de le faire assez facilement.
Container et orchestration
- New Location For Stable and Incubator Charts : le 13/11, les dépots stable et incubator de helm auront migrés. Les versions 2.17.0+ et 3.4.0+ de Helm feront la redirection entre les anciennes et nouvelles urls. Pour des clients plus vieux, il faudra redéclarer les urls de stable et incubator. L’image de tiller bouge également.
- D2iQ Takes the Next Step Forward : D2iQ annonce la fin de son investissement sur DC/OS et sa concentration sur son offre kubernetes (et la transition DC/OS vers kubernetes pour ses clients).
- Setting up Cloud Operations for GKE et Troubleshooting services on GKE : une bonne raison de plus d’avoir un clustr 1.15+ chez GKE. Cloud Operations permet d’avoir un dashboard assez sympathique pour visualiser et diagnostique l’état d’un cluster GKE. Reste ensuite la partie alerting à ajuster à vos besoins.
- Announcing k0s, the Smallest, Simplest Kubernetes Distribution : Mirantis, en plus de Lens, ajoute à son arc une nouvelle distribution kubernetes nommée “k0s”. Multi-usages (Cloud, IoT, Edge, Bare Metal, etc), elle vise à simplifier le dépoiement d’un cluster kubernetes avec un binaire unique contenant tout les éléments nécessaires pour piloter votre cluster.
- OVHcloud Managed Kubernetes certified Kubernetes 1.19 : OVHCloud propose maintenant kubernetes 1.19 (et la version 1.14 ne sera plus disponible à partir de janvier 2021)
SQL
- Announcing Vitess 8 : Vitess, la base distribuée prévue pour un déploiement sur kubernetes et avec une compatibilité MySQL arrive en version 8 et améliore son support de MySQL et des principales librairies et frameworks dans différents langages.
Système
- Deprecating scp : qui n’a pas fait un
scp file destination:/path/to/file? La commande scp est victime de nombreuses failles. Du coup, elle va être dépréciée. Néanmoins une initiative vise à maintenir uen commandescpmais se fondant sursftpet son modèle de sécurité. - ogham/dog : dog est une réécriture de dig en rust avec coloration syntaxique et différentes fonctionnalités comme le support de DoH, DoT, etc.
- k6 : k6 est un outil de test de performance avec lequel on peut définir des scénarios plus ou moins élaborés suivant ses besoins ; je l’avais recommandé à un client pour faire des tests de performance d’API; la version 0.29 vient de sortir.
Timeseries
- InfluxData advances possibilities of time series data with general availability of InfluxDB 2.0 : InfluxDB 2.0 OSS est (enfin) là et un guide de mise à jour 1.x vers 2.x 0SS est disponible
- Announcing InfluxDB IOx – The Future Core of InfluxDB Built with Rust and Arrow : Paul Dix a annoncé le nouveau projet phare autour d’InfluxDB avec une réécriture d’une partie du coeur d’InfluxDB pour traiter les soucis de cardinalité et aller plus loin dans la partie analytique (avec un support de SQL). Cela sera basé sur les projets Apache Arrow, le format de fichier Parquet et ce sera écrit en Rust. A suivre !
- InfluxDays North America 2020 : les supports et vidéo de cette édition sont en ligne. Vous y retrouvez notamment des détails sur le projet IOx par Paul Dix, la roadmap produit par Tim Hall ou encore la mise à jour Influx DB OSS 1.x vers 2.x. Sans oublier les sessions pour se mettre à Flux ou encore l’intégration Flux/Grafana et bien d’autres choses encore.
Astuce du mois
Pour ceux sous Fedora et utilisant podman en alternative au binaire docker, pour se connecter à la registry google (via):
gcloud auth print-access-token | podman login -u oauth2accesstoken --password-stdin gcr.io
InfluxDB 2.0 OSS - Notes de mise à jour
timeseries influxdb flux grafana telegrafInfluxDB 0SS 2.0 étant sortie, j’ai testé la mise à jour d’une instance 1.8.3 vers 2.0.1 sur une VM Debian 10 à jour.
Mise à jour
La documentation pour une mise à jour 1.x vers 2.x est disponible. La vidéo “Path to InfluxDB 2.0: Seamlessly Migrate 1.x Data” reprend cela et va plus loin en présentant bien tous les points à prendre en compte (y compris pour Telegraf, Chronograf et Kapacitor). Je ne rajouterai donc que mes remarques.
Concernant la commande influxd upgrade :
- Il est fort probable qu’il faille rajouter la commande
sudopour ne pas avoir de problèmes de permisisons. - Par défaut, les données migrées vont être mises dans
~/.influxdbV2. Or je doute que vous vouliez que vos données soient à cet endroit. Je vous invite donc à regarder la documentation deinfluxd upgradepour définir les propriétés--engine-pathet--bolt-path
Exemple:
mkdir -p /srv/influxdb/influxdb2
influxd upgrade --engine-path /srv/influxdb/influxdb2/engine --bolt-path /srv/influxdb/influxdb2/influxd.bolt
- A l’issue de la migration, un fichier
config.tomlest généré dans/etc/influxdb/. Il contient quelques valeurs issues de la migration et des valeurs par défaut. Je l’ai personnalisé de la façon suivante pour tenir compte de mes valeurs :
bolt-path = "/srv/influx/influxdb2/influxd.bolt"
engine-path = "/srv/influx/influxdb2/engine"
http-bind-address = "127.0.0.1:8086"
storage-series-id-set-cache-size = 100
- Post-migration, le service
influxdcherchait à initialiser ses fichiers dans/var/lib/influxdb/.influxdbv2. Ayant noté que le service InfluxDB prennait/etc/default/influxdbcomme fichier d’environnement, j’ai ajouté dans ce fichier :
# /etc/default/influxdb
INFLUXD_CONFIG_PATH=/etc/influxdb/config.toml
Dès lors, /etc/influxdb/config.toml était bien pris en compte et InfluxDB démarrait bien avec mes données.
Une fois InfluxDB 2 démarré, j’ai pu noter avec plaisir :
- que l’ingestion via telegraf continuait à se faire sans interruption,
- que mes dashboards Grafana continuaient à fonctionner.
Je n’ai donc pas d’urgence à migrer la configuration et le paramétrage de ces derniers. Je vais pouvoir le faire progressivement ces prochains jours.
N’utilisant pas Chronograf et Kapacitor, je n’ai pas eu de données à migrer ou d’ajustements à faire à ce niveau là. La vidéo reprend bien les points d’attention et les éventuelles limitations à prendre en compte dans le cadre de la migration.
Finalement, c’est pas mal qu’ils aient réintégrer les endpoints 1.x dans la version 2.0 à ce niveau là ;-)
La 2.0.2 étant sortie pendant ma mise à jour, j’ai poursuivi la mise à jour. Je suis tombé sur ce bug rendant l’écriture de données impossibles. Cela a mis en évidence un bug sur la migration des “retention policies” et sur le fait que j’avais aussi des très vieilles bases InfluxDB. Je n’aurai a priori pas eu ce bug en faisant la migration 1.8.3 vers 2.0.2. En tous cas, une 2.0.3 devrait donc arriver prochainement avec une amélioration du processus de migration faisant suite à ma séance de troubleshooting.
Migration des configurations
Elle peut se faire très progressivement - si par ex vous utilisez telegraf pour envoyer vos données et Grafana pour la partie dashboarding :
- Vous pouvez mettre à jour votre configuration telegraf en passant de l’outputs
influxdbà l’outputinfluxdb_v2sans impacter grafana qui continuera à accéder à vos données en InfluxQL - Vous pouvez ensuite mettre à jour votre datasource InfluxDB ou plutôt en créer une nouvelle et migrer vos dashboards progressivement sans interruption de service
Créer un accès en InfluxQL à un nouveau bucket
Si vous devez rétablir un accès à vos données via les API 1.x à un bucket nouvellement créé (j’ai profité de la migration pour mettre des buckets clients dans des organisations représentant les clients en question).
# Créer le bucket
influx bucket create --name <BUCKET_NAME> --retention 0 --org <ORGANISATION>
# Récupérer l'ID de bucket via la liste des buckets
influx bucket list
# Créer une DBRP (DataBase Retention Policies) pour le bucket en question - les accès en 1.x se font en mode SELECT * FROM <db_name>.<retention_policies> ...
influx v1 dbrp create --bucket-id=<BUCKET_ID> --db=<BUCKET_NAME> --rp=autogen --default=true
# Créer un utilsateur sans mot de passe pour le moment
influx v1 auth create --username <USER> --read-bucket <BUCKET_ID> --write-bucket <BUCKET_ID> --org <ORGANISATION> --no-password
# Créer un mot de passe au format V1
influx v1 auth set-password --username <USER>
Les utilisateurs migrés depuis la version 1.x sont visibles via influx v1 auth list.
Intégration InfluxDB 2.0 / Flux et Grafana
Le support de Flux dans Grafan existe depuis la version 7.1 mais il n’est pas aussi aisé que celui dans InfluxDB 2.0 OSS. Il y a certes de la complétion au niveau du code ou le support des variables mais pas de capacité d’introspection sur la partie données.
Pour le moment, je procède donc de la façon suivante :
- Création de la Requête via le Query Builder dans InfluxDB 0SS
- Passage en mode “Script editor” pour dynamiser les variables ou ajuster certains comportements
- Copier/coller dans l’éditeur de Grafana
- Ajustement des variables pour les mettre au format attendu par Grafana.
Ex coté InfluxDB 2.0 OSS / Flux :
from(bucket: v.bucket)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "net")
|> filter(fn: (r) => r["_field"] == "bytes_recv" or r["_field"] == "bytes_sent")
|> filter(fn: (r) => r["host"] == v.host)
|> derivative(unit: v.windowPeriod, nonNegative: false)
|> yield(name: "derivative")
La version dans Grafana :
from(bucket: "${bucket}")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "net")
|> filter(fn: (r) => r["_field"] == "bytes_recv" or r["_field"] == "bytes_sent")
|> filter(fn: (r) => r["host"] == "${host}")
|> derivative(unit: v.windowPeriod, nonNegative: false)
|> yield(name: "derivative")
La différence portant sur la gestion des variables v.host vs "${host}" et v.bucket vs "${bucket}".
Autre bonne nouvelle, les variables sont supportées dans Grafana ; vous pouvez donc définir les variables comme celles vu juste au-dessus :
Variable bucket de type “Query” en prenant InfluxDB/Flux comme datasource :
buckets()
|> filter(fn: (r) => r.name !~ /^_/)
|> rename(columns: {name: "_value"})
|> keep(columns: ["_value"])
Variable host de type “Query” en prenant InfluxDB/Flux comme datasource :
# Provide list of hosts
import "influxdata/influxdb/schema"
schema.tagValues(bucket: v.bucket, tag: "host")
Si votre requête fonctionne dans un dashboard InfluxDB ou en mode explore mais qu’elle est tronquée dans Grafana, il vous faudra ajuster le “Max Data Points” pour récupérer plus de points pour cette requête (cf grafana/grafana#26484).
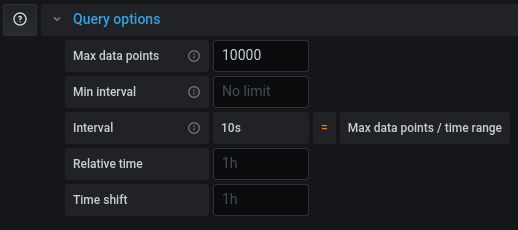
Calcul de la durée d'un état avec des timeseries
timeseries influxdb flux warp10 warpscript durationUn client m’a demandé la chose suivante : “Nicolas, je voudrais savoir la durée pendant laquelle mes équipements sont au delà d’un certain seuil ; je n’arrive pas à le faire simplement”.
Souvent, quand on manipule des séries temporelles, la requête est de la forme “Sur la période X, donne moi les valeurs de tel indicateur”. On a moins l’habitude de travailler dans le sens inverse, à savoir : “Donne moi les périodes de temps pour laquelle la valeur est comprise entre X et Y”.
C’est ce que nous allons chercher à trouver.
Influx 1.8 et InfluxQL
Avec l’arrivée imminente d’Influx 2.0, j’avoue ne pas avoir cherché la solution mais je ne pense pas que cela soit faisable purement en InfluxQL.
Influx 1.8 / 2.0 et Flux
Avec Flux, j’ai rapidement trouvé des fonctions comme duration et surtout stateDuration
L’exemple ci-dessous se fait avec une base InfluxDB 1.8.3 pour laquelle Flux a été activé. Le requêtage se fait depuis une instance Chronograf en version 1.8.5.
Pour approcher l’exemple de mon client, j’ai considéré le pourcentage d’inactivité des CPU d’un serveur que l’on obtient de la façon suivante:
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
Cela donne:

Ensuite, j’ai besoin d’une fonction qui va me rajouter une colonne avec mon état. Cet état est calculé en fonction de seuils - par souci de lisibilité, je vais extraire cette fonction de la façon suivante et appliquer la fonction à ma requête :
set_level = (tables=<-) =>
tables
|> map(fn: (r) => ({
r with
level:
if r._value >= 95 then "fully_idle"
else if r._value >= 90 and r._value <95 then "something_is_moving"
else if r._value >= 85 and r._value <90 then "oh_oh"
else if r._value >= 80 and r._value <85 then "hmm"
else if r._value < 80 then "i_have_to_work"
else "overloaded"
})
)
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
|> set_level()
La colonne “level” n’est à ce stade pas persistée en base contrairement aux autres données issue de la base de données.
Cela donne ceci en mode “raw data” - tout à fait à droite

Maintenant que j’ai mon état, je peux application la fonction stateDuration() ; elle va calculer la périodes de temps où le seuil est “something_is_moving” par tranche de 1 seconde. Le résulat sera stocké dans une colonne “stateDuration”. Pour les autres états, la valeur est de -1. La valeur se remet à 0 à chaque fois que l’état est atteint puis la durée est comptée :
set_level = (tables=<-) =>
tables
|> map(fn: (r) => ({
r with
level:
if r._value >= 95 then "fully_idle"
else if r._value >= 90 and r._value <95 then "something_is_moving"
else if r._value >= 85 and r._value <90 then "oh_oh"
else if r._value >= 80 and r._value <85 then "hmm"
else if r._value < 80 then "i_have_to_work"
else "overloaded"
})
)
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
|> set_level()
|> stateDuration(fn: (r) => r.level == "something_is_moving", column: "stateDuration", unit: 1s)
On voit le rajout de la colonne stateDuration en mode “raw data” ; elle n’ont plus n’est pas persistée dans la base à ce stade :

et coté visualisation :

Maintenant que j’ai ces périodes, je vais vouloir savoir quelle est la durée totale de ces différentes périodes que nous avons identifée. On peut en effet imaginer un cas où on sait que l’équipement est à remplacer lorsqu’il a atteint un seuil donné pendant plus de X heures.
Pour cela, je vais:
- filtrer sur un état voulu,
- calculer le différentiel entre chaque valeur de stateDuration pour n’avoir que les écarts non plus la somme des durées en supprimant les valeurs négatives pour gérer les retours à la valeur 0
- et faire la somme de l’ensemble.
set_level = (tables=<-) =>
tables
|> map(fn: (r) => ({
r with
level:
if r._value >= 95 then "fully_idle"
else if r._value >= 90 and r._value <95 then "something_is_moving"
else if r._value >= 85 and r._value <90 then "oh_oh"
else if r._value >= 80 and r._value <85 then "hmm"
else if r._value < 80 then "i_have_to_work"
else "overloaded"
})
)
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
|> set_level()
|> stateDuration(fn: (r) => r.level == "something_is_moving", column: "stateDuration", unit: 1s)
|> filter(fn: (r) => r.level == "something_is_moving")
|> derivative(unit: 10s, nonNegative: true, columns: ["stateDuration"], timeColumn: "_time")
|> sum(column: "stateDuration")
Ce qui me donne un total de 2230 secondes pour l’heure (3600s) qui vient de s’écouler.

C’est un POC rapide pour démontrer la faisabilité de la chose. Le code est surement améliorable/perfectible.
Dans un contexte InfluxDB 2.0, il y a aussi la fonction events.duration qui semble intéressante. Ce billet “TL;DR InfluxDB Tech Tips – How to Monitor States with InfluxDB” montre aussi l’usage de la fonction monitor.stateChanges() qui peut compléter l’approche.
Influx 1.8 / Flux - variante pour les séries irrégulières
La fonction derivative impose d’avoir des durées régulières pour calculer le delta. Dans le cas d’une série irrégulière, cela peut coincer rapidement et fausser les calculs. On peut donc remplacer les deux dernières lignes par la fonction increase. Elle prend la différence entre deux valeurs consécutives (quelque soit leur timestamp) et réalise une somme cumulative. Les différences négatives sont ignorées de la même façon que nous le faisions précédemment.
set_level = (tables=<-) =>
tables
|> map(fn: (r) => ({
r with
level:
if r._value >= 95 then "fully_idle"
else if r._value >= 90 and r._value <95 then "something_is_moving"
else if r._value >= 85 and r._value <90 then "oh_oh"
else if r._value >= 80 and r._value <85 then "hmm"
else if r._value < 80 then "i_have_to_work"
else "overloaded"
})
)
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
|> set_level()
|> stateDuration(fn: (r) => r.level == "something_is_moving", column: "stateDuration", unit: 1s)
|> filter(fn: (r) => r.level == "something_is_moving")
|> increase(columns: ["stateDuration"])
La sortie change un peu car au lieu d’un nombre unique, on a l’ensemble des points filtrés et leur somme au fur et à mesure (colonne de droite):
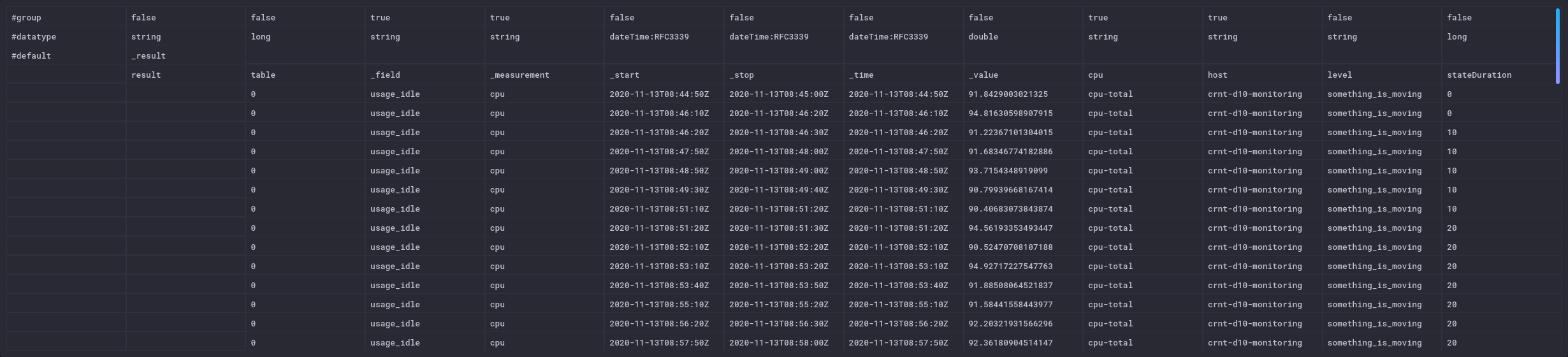
Cela donne des possiblités différentes au niveau dataviz :
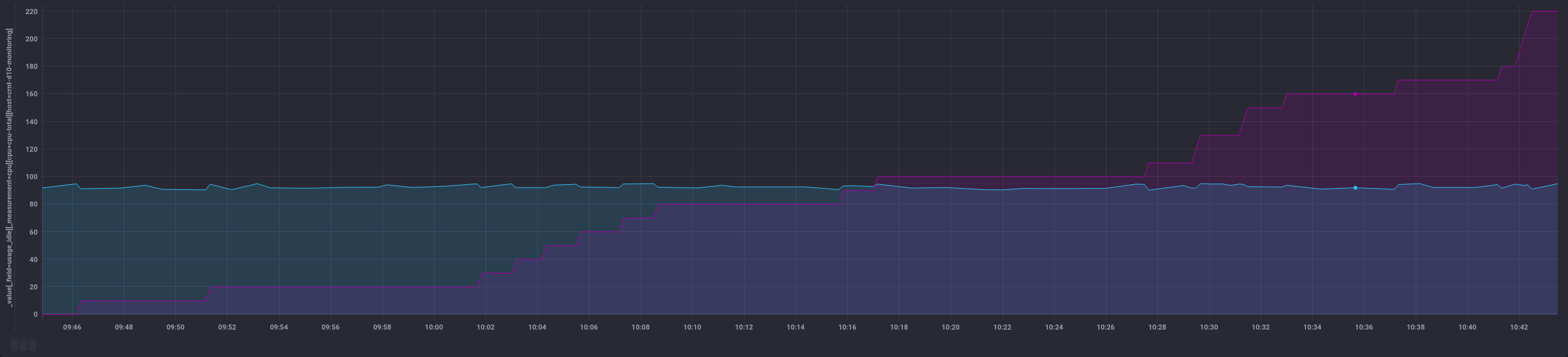
Warp 10 / WarpScript
En la même chose en WarpScript avec Warp 10, cela donne quoi ? Regardons cela :
'<readToken>' 'readToken' STORE
// Récupération des données de cpu de type "usage_idle" en ne prenant que le label "cpu-total"
[ $readToken '~crntd10monitoring.cpu.usage_idle' { 'cpu' 'cpu-total' } NOW 1 h ] FETCH
0 GET // Fetch retourne une liste de GTS, on prend donc la première (et unique) GTS
'cpu' STORE // Stockage dans une variable cpu
// Utilisation de BUCKETIZE pour créer une série régulière de données séparées par 1 seconde
// Mes données étant espacées d'environ 10s, cela va donc créer 10 entrées de 1 seconde au final
// Pour chaque espace, on utliise la dernière valeur connue de l'espace en question pour garder les valeurs de la GTS de départ
[
$cpu
bucketizer.last
0
1 s
0
]
BUCKETIZE
// Les espaces insérés n'ont pas encore de valeurs associées
// On remplit les entrées sans valeurs avec les valeurs ci-dessus
// On utilise FILLPREVIOUS et FILLNEXT pour gérer aussi les premières et dernières valeurs
FILLPREVIOUS
FILLNEXT
// A ce stade, on a donc une GTS avec un point toute les secondes et la valeur associée. Cette valeur était la valeur que l'on avait toutes les 10s précédemment.
// On fait une copie de la GTS pour pouvoir comparer avec la version filtrée par ex
DUP
// On filtre sur les valeurs qui nous intéressent, ici on veut les valeurs >= 90 et < 95
[ SWAP 90.0 mapper.ge 0 0 0 ] MAP
[ SWAP 95.0 mapper.lt 0 0 0 ] MAP
// On renomme la liste (pratique si on affiche par ex l'ancienne et la nouvelle liste dans la partie dataviz - cf capture ci-dessous)
'+:above90below95' RENAME
// On compte le nombre d'élément de la GTS qui est sous la forme d'une liste de GTS à l'issu du MAP
0 GET SIZE
// On multiplie le nombre d'entrées par 1 s
1 s *
// on garde une copie de la valeur en secondes
DUP
// On applique le filtre HUMANDURATION qui transforme ce volume de secondes en une durée compréhensible
HUMANDURATION
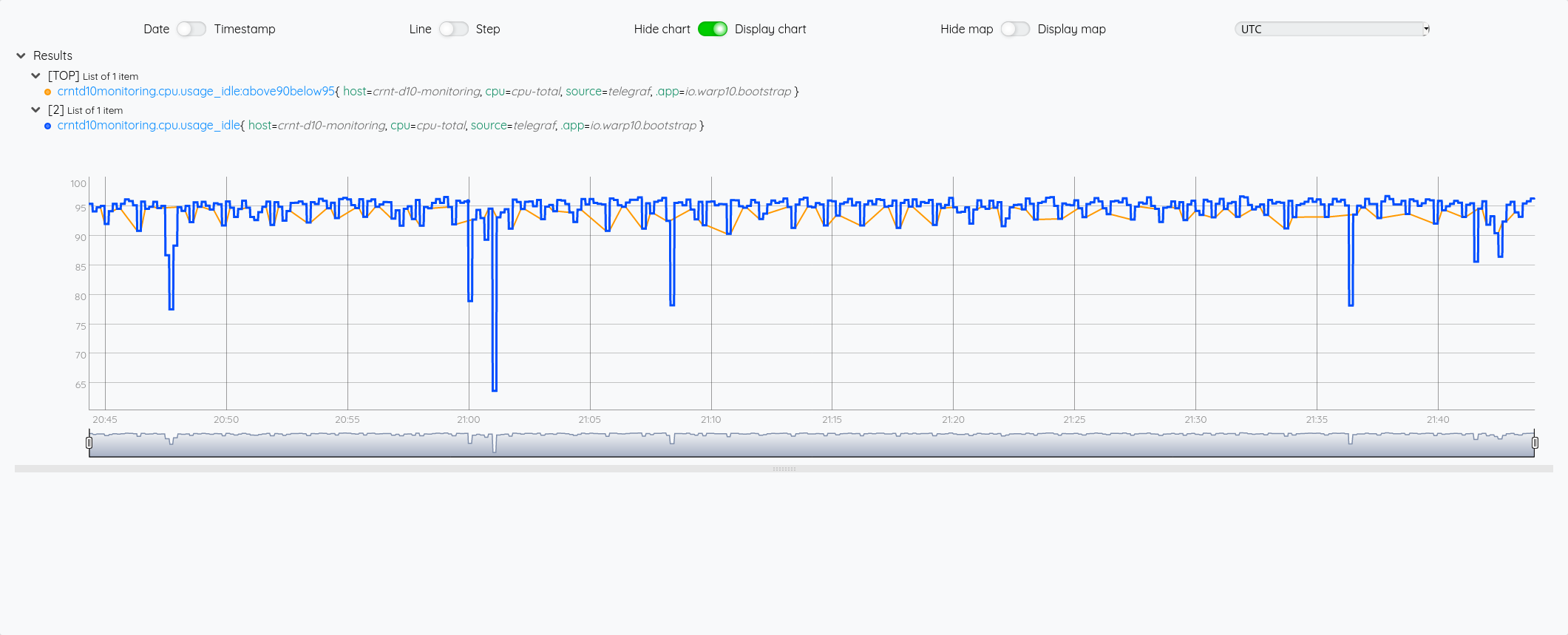
On voit ci-dessous l’usage de DUP avec la valeur humainement lisible, la valeur brute en seconde (puis le reste de la pile):

Si on ne veut pas de dataviz / ne pas conserver les valeurs intermédiaires et n’avoir que la valeur finale, on peut supprimer les lignes avec DUP et RENAME.
'<readToken>' 'readToken' STORE
[ $readToken '~crntd10monitoring.cpu.usage_idle' { 'cpu' 'cpu-total' } NOW 1 h ] FETCH
0 GET
'cpu' STORE
[
$cpu
bucketizer.last
0
1 s
0
]
BUCKETIZE
FILLPREVIOUS
FILLNEXT
[ SWAP 90.0 mapper.ge 0 0 0 ] MAP
[ SWAP 95.0 mapper.lt 0 0 0 ] MAP
0 GET SIZE
1 s *
HUMANDURATION
Et on obtient:
20m20.000000s
Un grand merci à Mathias Herberts pour sa disponiblité, sa patience et son aide face à toutes mes questions pour arriver à produire ce code.
Warp 10 / WarpScript - version agrégée
On peut aussi vouloir avoir une version agrégée de la donnée plutôt que de filter sur un état particulier. Ainsi, on peut avoir la répartition des valeurs que prend un équipement sur un indicateur donnée.
'<readToken>' 'readToken' STORE
// Récupération des métriques comme précédemment
[ $readToken '~crntd10monitoring.cpu.usage_idle' { 'cpu' 'cpu-total' } NOW 1 h ] FETCH
0 GET
'cpu' STORE
// Reformatage des données comme précédemment
[
$cpu
bucketizer.last
0
1 s
0
]
BUCKETIZE
FILLPREVIOUS
FILLNEXT
// Utilisation de QUANTIZE
// QUANTIZE a besoin que l'on définisse des sous-ensembles dans un ensemble
// Notre indicateur CPU étant un pourcentage, on prend par ex 10 sous ensemble compris entre 0 et 100
// QUANTIZE gère aussi les cas où l'on est plus petit que la première valeur et plus grand que la derinère valeur de l'ensemble
0 100 10 LBOUNDS
// On a donc 10+2 = 12 sous-ensembles : ]-infini,0],[1, 10],[11, 20],...,[90, 100],[101, inf+[
// Pour chaque valeur que nous allons passer à QUANTIZE, elle va retourer une valeur associée au sous ensemble dans laquelle la valeur va "tomber".
// Ainsi, un valeur de 95% va aller dans gt90.
// Liste des valeurs pour les 12 sous-ensembles :
[ 'neg' 'gt0' 'gt10' 'gt20' 'gt30' 'gt40' 'gt50' 'gt60' 'gt70' 'gt80' 'gt90' 'gt100' ]
QUANTIZE
// A ce stade, notre GTS de départ ne contient plus les valeurs de cpu mais les valeurs associées au tableau de QUANTIZE
// on passe donc de [<timestamp>, 95.45] à [<timestamp>, 'gt90']
// Utilisation de VALUEHISTOGRAM qui va compter le nombre d'occurences de chaque valeur d'une liste de GTS
VALUEHISTOGRAM
On obtient alors :
[{"gt90":3491,"gt80":40,"gt70":40,"gt60":10}]
Et voilà !
Web, Ops & Data - Octobre 2020
kubernetes ingress yaml pipeline gitlab traefik rootless mesh yq jq devops data maturité mariadb s3 flows warp10 timeseries influxdb pulsar amqp mqtt kafka python git vscode arm nvidiaDes nouvelles du Paris Time Series Meetup : l’éditions 6 sur TimescaleDB et l’édition 7 sur QuestDB
CI/CD
- 3 YAML tips for better pipelines : la troisième est certainement la plus intéressante - il est possible d’avoir des mécanismes de “composabilité” / “héritage” avec YAML et Gitlab. Si les
includeetextendssont déjà sympathiques, lesanchorsont l’air de faire des choses intéressantes aussi !
Code
- What’s New In Python 3.9 et un thread twitter qui donne des exemples des principales nouveautés : au programme nouvelle syntaxe pour la fuston des dictionnaires, des méthides pour supprimer des suffixes/préfixes sur les strings, du typage et plein d’autres améliorations et corrections.
- Fortunately, I don’t squash my commits : s’il peut être tentant sur une MR/PR de faire un squash des commits, l’article vous confortera dans l’idée que ce n’est pas une bonne idée. En écrasant l’historique des commits, on y perd sur nos capacités de debug. Par ailleurs, il est conseillé de faire des petits commits pour capturer un ensemble de changements traduisant un moment précis du développement.
Container et orchestration
- Kubernetes Ingress Goes GA : l’apparition de IngressClassName dans k8s 1.19 va plus loin qu’un simple renommage de champ comme je l’avais compris initialement. C’est une vraie ressource et cela ouvre aussi des possibilités. Avant de l’utiliser, vérifiez aussi que vos ingress controller le supporte (en plus d’attendre d’être en 1.19)
- Houston, we have Plugins! Traefik 2.3 Announcement : la version 2.3 dont on a déjà parlé ici, est arrivé en version stable avec son support des plugins, son intégration avec Traefik Pilot, le support d’Amazone ECS et le support de la ressource IngressClassName. Au passage, Containous, la société éditrice de Traefik s’appelle maintenant Traefik Labs.
- Introducing Traefik Pilot 1.0: the Traefik Control Center : Version 1.0 de ce nouveau “Control Plane” de Traefik qui permet d’avoir une vision globale sur ses instances traefik, d’utiliser les plugins et d’avoir un monitoring et des alertes autour de la disponibilité, des performances et de la sécurité.
- Rootless mode : A voir si cela pourra être inclus dans la version 1.20 mais le rootless mode est clairement une tendance de fond dans kubernetes et les conteneurs en général. Si vous ne vous y êtes pas déjà mis, ne tardez pas !
- Announcing Traefik Mesh 1.4 - New Name, New Features : nouvelle version du service mesh par Traefik Labs et qui s’appelle maintenant Traefik Mesh (et non uniquement Maesh). Le reste des améliorations semble porter sur le filtrage des headers et des paths.
- yq : A command line tool that will help you handle your YAML resources better : vous voulez faire des opératoins sur des fichiers YAML sans faire un chart helm ou sortir kustomize, vous pouvez faire des choses minimalistes avec yq (le pendant yaml de jq).
- Bridge to Kubernetes GA, “bridge to kubernetes” est une extension pour vscode permettant de connecter une application tournant en local avec d’autres applications situées dans un ckuster kubernetes et faciliter ainsi l’expérience des développeurs.
Culture DevOps
- La culture de la résilience à travers le DevOps, DevPO, et DevQA : article intéressant de Paul Leclerq sur la résilience et la collaboration au sein d’une équipe.
Data
- How to Measure Your Organization’s Data Maturity : les différents stade de maturité de votre organisation concernant la gestion et l’exploitation des données.
- Announcing MQTT-on-Pulsar: Bringing Native MQTT Protocol Support to Apache Pulsar: Apache Pulsar, la plateforme de message distribué et de streaming, se dote d’un plugin “MQTT On Pulsar” (MoP) permettant ainsi de migrer vos applications MQTT sur Apache Pulsar. Après le plugin Kafka (KoP) il y a quelques mois en partenariat avec OVHCloud, Pulsar ajoute une corde à son arc pour devenir la plateforme universelle. Le protocole AMQP est déjà aussi supporté depuis plusieurs mois.
- Building An Event-Driven Orchestration Engine : retour d’expérience sur les raisons de la migration à Apache Pulsar e la simplificaiton apportée en ayant une platforme riche et complète (streaming + queue + fonctions + data tiering sur S3 + …)
Hardware
- NVidia’s Planned Acquisition of Arm Portends Radical Data Center Changes : une analyse assez en profondeur sur le rachat d’arm par nvidia et les autres acteurs du marché comme AMD.
IaC
- Announcing HashiCorp Terraform 0.14 Beta: la capacité à marquer des variables comme sensibles pour éviter que leur valeur soit visible dans les logs/diff/…, un diff plus concis, un lock sur les providers et des binaires disponibles pour arm64.
Monitoring
- Long-term store for Prometheus, with the combined power of SQL and PromQL : Timescale s’ajoute à la liste des solutions permettant un stockage long terme à vos données Prometheus. En plus de ce stockage long terme, elle fournit une couche d’analytics. Un connecteur récupère les données dans Prometheus et les injecte dans TimescaleDB. On en parle dans l’édition 6 du PTSM.
Pratique
- endoflife.date : recense les dates de fin de support de vos langages et technologies préférées. Tout n’est pas complètement à jour mais cela permet de récupérer rapidement les informations.
SQL
- Exciting and New Features in MariaDB 10.5 : évoqué au mois d’aout, le support de S3 dans MariaDB est disponible en version GA dans la version 10.5. D’autres améliorations existent comme le support du type INET6, des améliorations sur ColumnStore, la gestion des privilèges, le cluster Galera supporte complètement le GTID, du refactoring au niveau d’InnoDB et enfin les binaires mariadb vont enfin s’appeler mariadb et non plus mysql (avec une couche de compatibilité via des liens symboliques)
Time Series
- Introducing FLoWS, a functional language for Time Series Analytics : FLoWS est arrivé - il vous faudra utiliser une version 2.7.1+ de Warp10 pour profiter de cette approche fonctionnelle en alternative à Warpscript.
- How can you tell which Time Series Database is suited to your needs? : un petit rappel sur les critères à prendre en compte pour choisir une base de données séries temporelles ; j’avais déjà parlé du guide de Senx sur le sujet - il est disponible en fin de billet.
- InfluxDB 2.0 Release Candidate Now Available : la première Relese Candidate (RC0) pour InfluxDB 2.0 OSS avec le retour du moteur de stockage de la V1 - qui contrairement à ce que j’ai pu dire le mois dernier ne concernerait que la façon dont les données sont stockées sur disque et pas le reste d’une part et sera maintenu et amélioré par Influxdata d’autre part. Quelques changements sur le port (retour au port 8086). Pour ceux qui étaient en version alpha/beta, il faudra suivre une procédure de migration. La migration depuis une version 1.x n’est pas encore disponible, cela devrait être dans une prochaine RC. Vous pourrez tester néanmoins les API 1.x, les templates, une version récente de Flux ou encore les améliorations de la CLI.
- Release Announcement: InfluxDB 2.0.0 RC 1 : cette version apporte essentiellement l’upgrade des données 1.x vers 2.x et une mise à jour de Flux.
- Store and Access Time Series Data at Any Scale with Amazon Timestream – Now Generally Available - Getting Started with Amazon Timestream - AWS Releases Amazon Timestream into General Availability : AWS sort enfin son produit orienté time series après l’avoir annoncé il y a deux ans.
Sur la base des informations disponibles pour le moment :
- vous définissez une période de rétention en mémoire (entre 1h et 1 an) et une période de rétention sur stockage magnétique (1 jour à 200 ans),
- le requêtage des données se fait en SQL (via Presto ?),
- les données à requêter communément sont à mettre dans la même table,
- le join est limité à la même table,
- des mesures simples (pas de multi mesures pour un même enregistrement),
- une intégration avec l’écosystème comme telegraf, grafana, etc en plus de l’intégration avec différents composants AWS
Pour les moins bons côtés :
- pas d’UPDATE/DELETE sur vos données ; en cas de doublons, c’est le premier arrivé qui gagne
- pas de bulk import de vos données, donc pas de reprise de vos données existantes. En effet, il n’est pas possible d’ingérer des données plus vieille que la période en mémoire,
- dans la même veine, si un incident de production dépasse votre période de rétention, vous ne pourrez pas réinjecter vos données
- il ne semble pas possible de mettre à jour ses durées de rétention - donc pas de ménage possible ou d’ajustements en cours de route
Une solution a priori très orienté pour du monitoring et qui semble souffir des mêmes travers qu’InfluxDB avec InfluxQL et pourtant en passe d’être résolus avec Flux.
On devrait en parler plus en détail dans une prochaine édition du Paris Time Series Meetup avec des personnes de chez AWS ;-)
Work
- Virtual First Toolkit : toolkit proposé par Dropbox dans le cadre de leur passage non pas à Remote first mais à virtual first.
