Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
InfluxDB et les alertes : Tasks, Checks et Notifications
influxdb timeseries influxdata task flux check notifications kapacitor alertesCérénIT vient de finaliser la migration pour un de ses clients d’un socle InfluxDB/Chronograf/Kapacitor vers InfluxDB2. Ce billet est l’occasion de revenir sur la partie alerting et de la migration de Kapacitor vers des alertes dans InfluxDB2.
Dans le cadre du socle InfluxDB/Chronograf/Kapacitor, le fonctionnement était le suivant :
- Les utilisateurs créent une alerte via l’application métier en définissant un à plusieurs critères d’alertes ; ex: est-ce que l’unité est opérationnelle et est-ce que l’humidité est supérieure à tel taux ou la température supérieure à telle valeur.
- L’application métier traduisait l’alerte en TickScript et enregistrait l’alerte auprès de Kapacitor via son API HTTP
- Kapacitor, en mode streaming, évalue si l’alerte doit être levée ou pas au fur et à mesure de l’arrivée des données
- En cas de seuil franchi, Kapacitor envoie un message à l’application métier via l’API HTTP de cette dernière.
- L’application métier envoie ensuite un mail et/ou un SMS à l’auteur de l’alerte.
Avant d’envisager la migration InfluxDB2, un point de vocabulaire :
- une alerte est globalement composée d’un “check”, d’un endpoint de notiifcation et d’une règle de notification.
- un check est une task simplifiée. Elle permet de définir une requête mono critère, les niveaux de seuils associés (ok, crit, warn, etc) et sa fréquence d’exécution.
- une task est codée flux
- un endpoint de notification : service vers lequel sera envoyé l’alerte: slack, http, etc.
- une règle de notification : les conditions de notifications (ex je passe à un état critique), le check associé, la fréquence d’exécution, le message de notification et le endpoint de notification à utiliser.
Avec la migration InfluxDB2, nous avons voulu maintenir le même mécanisme. Toutefois :
- Les tasks en Flux ne fonctionnent pas en mode streaming, mais uniquement en mode batch et avec une certaine fréquence
- Les checks sont mono-critères et pas multi-critères
Heureusement, la documentation mentionne la possibilité de faire des “custom checks” et un billet très détaillé intitulé “InfluxDB’s Checks and Notifications System” permet de mieux comprendre ce qu’il est possible de faire et donne quelques exemples de code.
Dès lors, il s’agit de :
- développer une tâche “tout en un”, contenant l’ensemble de la logique de l’alerte,
- de conserver un historique des alertes pour permettre d’assurer un suivi des alertes pour l’équipe en charge du projet depuis InfluxDB
- d’être en mesure de notifier l’application métier via son API HTTP
Pour se faire, nous allons nous appuyer sur les mécanismes mis à disposition par Influxdata, à savoir les fonctions monitor.check(), monitor.from() et monitor.notify() et les mécanismes induits.
C’est ce que nous allons voir maintenant :
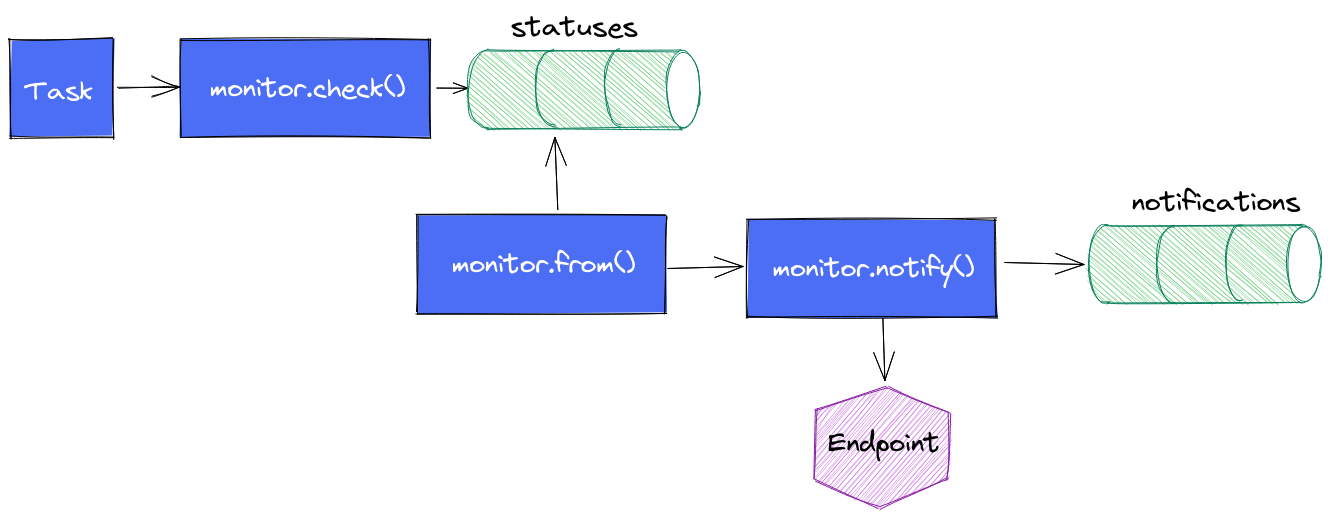
Le cycle de vie d’une alerte est le suivant :
- La task contient une requête en flux plus ou moins complexe en fonction de votre besoin ; ex: quelle est la valeur de la temperature du boitier X depuis la dernière exécution ?
- On appelle
monitor.check()en définissant les informations d’identification du check, le type de check que l’on utilise (threshold, deadman, custom), les différents seuils dont on a besoin, le message à envoyer au endpoint, les données issues de la requête flux. monitor.check()va alors stocker l’ensemble de ces données dans un measurementstatusesdans le bucket_monitoringet il s’arrête là.monitor.from()prend le relais, regarde s’il y a de nouveaux status depuis sa dernière exécution et en fonction des règles de notifications qui ont été définies, il va passer le relaismonitor.notify().monitor.notify()enverra une notification si la règle est validée et il insérera une entrée dans le measurementnotificationsdu bucket_monitoring
Une première version des alertes ont été implémentées sur cette logique. Des dashboards ont été réalisés pour suivre les status et les notifications. Cela fonctionne, pas de soucis ou presque.
Il se peut qu’il y ait un délai entre le moment où l’insertion issue du monitor.check() se fait et le moment où le monitor.from() s’exécute. Si monitor.from() fait sa requête avant l’insertion de données, alors l’alerte ne sera pas immédiatement levée. Elle sera levée à la prochaine exécution de la task, ce qui peut être problématique dans certains cas. Pour une tâche qui s’exécute toutes les minutes, cela ne se voit pas ou presque. Pour une tâche toutes les 5 minutes, ça commence à se voir.
Une version intermédiare de la task est alors née : une fois le monitor.check() exécuté, nous faisons appel à monitor.notify() pour envoyer le message vers le endpoint.
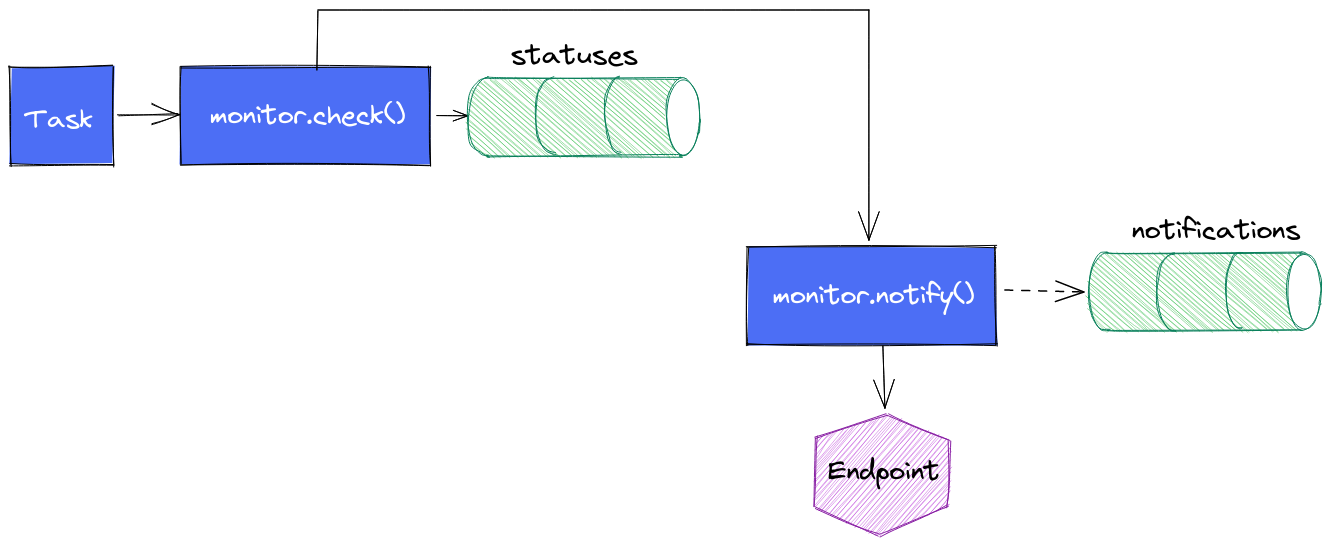
Avantage :
- la notification se déclenche sans délais
Inconvénients :
- cela ne remplit pas le measurement
notificationsde la même façon que précédemment (d’où les pointillés) vu que les données insérées dans le measurementstatusesn’existent pas encore. On perd la visibilité sur les notifications envoyées (mais on a toujours le suivi des statuts ; nous supposons que si on a le statut, alors on sait si la notification a été envoyée) - cela aboutit à un peu de duplication de code sur la gestion des seuils et des messages.
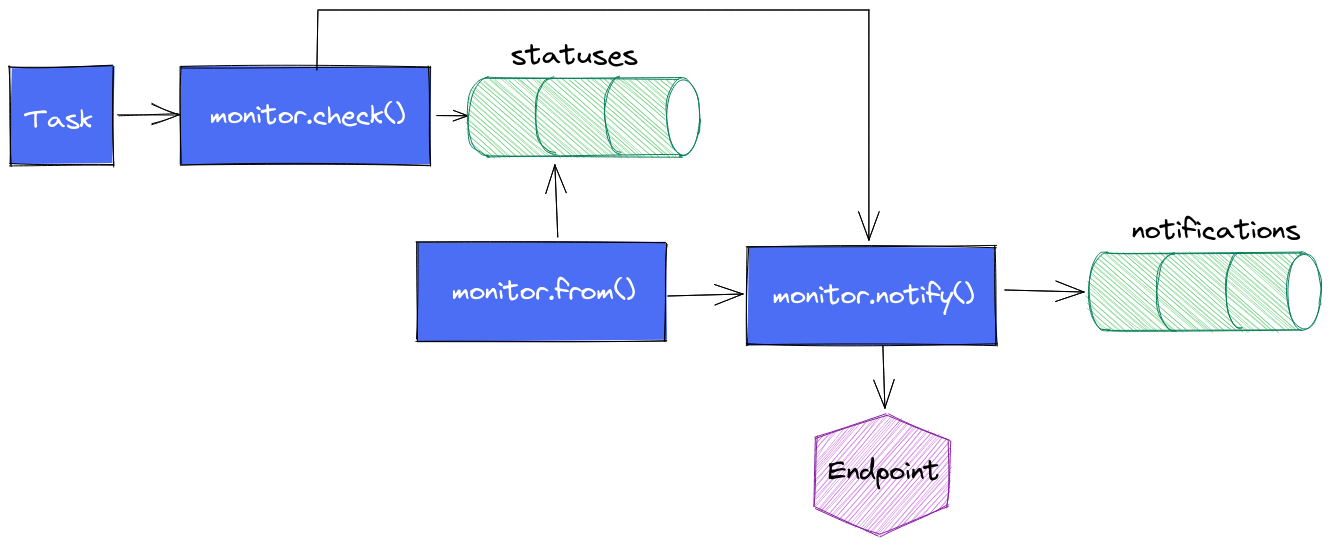
Une variante non essayée à ce stade : elle consiste à faire cette notification au plus tôt mais de conserver le mécanisme de monitor.from() + monitor.notify() pour avoir le measurement notifications correctement mise à jour. A voir si les alertes ne sont pas perturbées par ce double appel à monitor.notify(). Dans le cas présent, c’est l’application métier qui envoie les alertes après que la task InfluxDB ait appelé son API HTTP. Si chaque monitor.notify() en vient à lever une alerte, cela est sans impact pour l’utilisateur. En effet, une fois qu’une alerte est levée, elle est considérée comme levée tant qu’elle n’est pas acquittée. Donc même si la task provoque 2 appels, seul le premier lévera l’alerte et la seconde ne fera rien de plus.
Enfin dernière variante (testée) : s’affranchir complètement de monitor.notify() pour faire directement appel à http.endpoint() et http.post() et faire complètement l’impasse sur le suivi dans notifications.
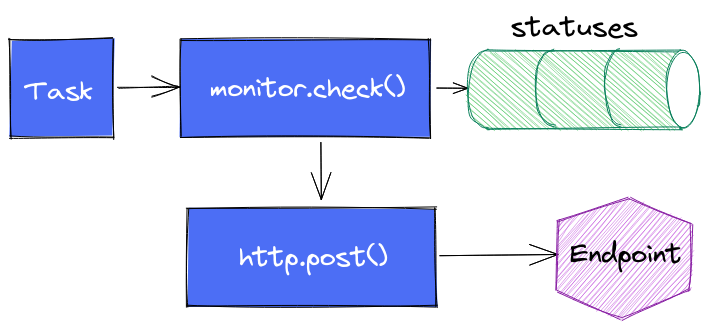
Tout est une histoire de compromis.
En conclusion, nous pouvons retenir que :
- Une alerte est composée d’un check, d’un endpoint de notification et d’une règle de notification
- En 2.0, le principe est que les alertes sont des séries temporelles via le bucket
_monitoringet les measurementsstatusesetnotifications. - Toute personne s’intéressant au sujet doit lire au préalable InfluxDB’s Checks and Notifications System pour bien comprendre les concepts et les rouages.
- Via la UI, les alertes (checks) sont assez basiques (requête monocritère)
- Il est possible de faire des “custom checks” via des tasks en flux
- Les fonctions du package monitor permettent de gérer des alertes
- Les exécutions dans la même task (ou dans des tasks concomittentes) de
monitor.check()etmonitor.from()peuvent conduire à des décalages de levées d’alertes
InfluxDB, shard, shard duration et retention policies
influxdb timeseries influxdata shard shard duration retention policy shard groupCérénIT a été contacté pour mener l’audit d’une instance InfluxDB 1.8 OSS utilisée dans un projet IoT lié à l’énergie. L’audit avait plusieurs objectifs :
- Comprendre la consommation mémoire de l’instance (48Go / 64Go de la VM)
- Faire un état de santé de la plateforme et estimer sa capacité à stocker et procésser des données supplémentaires dans le cadre de l’ouverture d’une application métier
- Expliquer la raison des problèmes observés par le passé et évaluer les solutions apportées
- Etablir des recommendations et éventuellement les implémenter.
De l’audit, on notera que :
- L’instance contient ~35.000 shards / ~36.000 tsm files pour environ 200 bases permanentes et des dizaines de bases éphémères permettant de calculer des indicateurs ou de recalculer des historiques de données suite à des changements de paramètres de l’application métier (plusieurs dizaines de milliers de bases temporaires par semaine, avec des profondeurs de données variables)
- Les recommendations pour InfluxDB Enterprise sont d’avoir 30/40 bases par data nodes et 1.000 shards par data node
Avant d’aller plus loin, précisons un peu cette notion de shard et les notions liées pour bien appréhender le sujet :
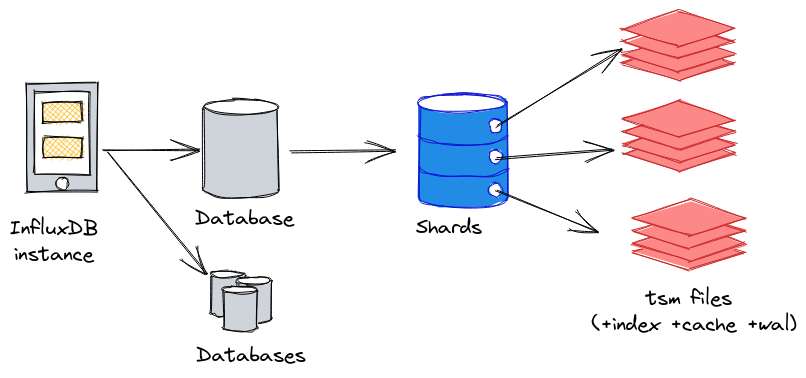
- Une instance InfluxDB peut contenir 1 à n bases de données (database),
- A chaque base de données InfluxDB, on peut définir une “retention policy” qui est la période maximale de conservation des données. Avec une retention policy de 7 jours par ex, seules les données des 7 derniers jours sont conservées. Les données les plus vieilles seront alors supprimées au fur et à mesure que les nouvelles données arriveront via un mécanisme de compaction.
- Les données d’une base de donneés InfluxDB sont réparties au sein de shards au niveau stockage ; chaque shard comprend les données sur une période de temps donnée. Si une base de données a une retention policy d’une semaine, alors chaque shard contiendra 1 jour de données. Nous aurons donc 7 shards pour cette base de données. Ce délai est appelé shard duration.
- Au sein de chaque shard, nous allons retrouver les données sous la forme d’un ou plusieurs fichiers TSM, le fichier d’index pour le shard, ainsi que le fichier de WAL et de cache.
Nous pouvons représenter la logique instance > database > shard(s) > tsm files de la façon suivante :
Par défaut, InfluxDB applique les shard duration suivantes en fonction des retention policy :
| Retention policy | Default shard duration |
|---|---|
| <= 2 days | 1 hour |
| <= 6 months | 1 day |
| > 6 months | 7 days |
Source : InfluxData - Shard group duration
Dès lors, une base de données avec une retention policy infinie aura une shard duration de 7 jours. Ainsi, si cette base contient 10 ans d’hisorique (soit 10 * 52 semaines = 520 semaines), elle contiendra 520 shards.
Du coup, InfluxData recommande les valeurs suivantes (au moins en 1.x ; on peut supposer que cela reste valable en 2.x):
| Retention policy | Default shard duration |
|---|---|
| <= 1 day | 6 hour |
| <= 7 days | 1 day |
| <= 3 months | 7 days |
| > 3 months | 30 days |
| infinite | >= 52 weeks |
Source : Shard group duration recommendations
Selon cette perspective, la base de données avec 10 ans d’historique ne contiendra plus 520 shards mais 10 shards en prenant une shard duration de 52 semaines. L’écart entre la valeur par défaut et la valeur recommandée est plus que significatif.
Pour bien dimensionner vos shard duration, InfluxData recommande :
- La durée doit être égale à 2 fois la période d’analyse la plus longue et la plus fréquente ; si vos analyses les plus fréquentes portent sur 6 mois de données maximum, alors votre shard duration est d’un an
- Chaque shard doit contenir au moins 100.000 points
- Chaque shard doit contenir au moins 1.000 points par série (combinaison de measurement (~table) + combinaison des tags + clés des fields)
Pourquoi nous en arrivons là ? C’est assez simple :
- InfluxDB au lancement va découvrir l’ensemble de ses shards et les périodes qu’ils recouvrent
- InfluxDB cherche à mettre un maximum de données en mémoire par souci d’efficience et de performance
- Une requête sur des périodes longues va nécessiter de monter en mémoire tous les shards correspondants à la période
Dès lors, un nombre important de shards va augmenter d’autant plus la consommation mémoire et le nombre de fichiers ouverts pour manipuler les données associées.
Si on recoupe ces données avec les recommendations pour InfluxDB Entreprise, à savoir 30/40 bases par data nodes et 1.000 shards par node, le bon réglage des retention policy et des shard durations n’est pas à négliger pour la bonne santé de votre instance.
En outre, s’il est possible de mettre à jour la retention policy et la shard duration en 1.x, cela ne s’appliquera que pour les nouveaux shards. Les anciens shards ne seront pas “restructurés” en fonction des nouvelles valeurs.
Pour mettre à jour les shards existants, il faut :
- Arrêter les mécanismes d’ingestion de données
- Exporter les données sous la forme de points au format InfluxDB Line Protocol via influxd inspect export
- Supprimer les measurements (voir la base de données si vous voulez aller plus vite)
- Modifier la retention policy et la shard duration de la base de données (ou créer une nouvelle base de données avec les bonnes valeurs pour la retention policy et la shard duration)
- Importer les données par batch de 5000 à 10.000 points.
- Valider le bon fonctionnement de l’instance et l’intégrité des données
- Relancer les mécanismes d’ingestion et gérer le rattrapage.
Ultime question, la version 2.x OSS change-t-elle la donne sur le sujet :
- InfluxDB 2.x OSS recommande 20 buckets actifs (databases) par instancce
- Définir la shard duration n’est possible que via l’API ou via la CLI. Rien via l’UI
- Les outils d’analyse et d’inspection comme influx_inspect en 1.x n’étaient pas à niveau en 2.0 OSS mais le sont presque en 2.1 OSS. Manque encore les commandes
reportetreport-disk. - Les templates de monitoring InfluxDB2 OSS Metrics et InfluxDB 2 Operational Monitoring requiert d’envoyer les données dans une instance InfluxCloud pour avoir les données.
- La fonction influxdb.cardinality() n’est disponible en OSS que depuis la 2.0.9
En conclusion, ce qu’il faut retenir :
- La retention policy et la shard duration de vos bases InfluxDB ne sont pas à négliger et les valeurs par défaut ne sont surement pas adaptées à votre cas d’usage
- Il est possible de mettre à jour ses valeurs mais elles ne s’appliqueront qu’aux nouveaux shards - pour les anciens shards, il faut exporter les données sous la forme de points et les réimporter
- Il faut trouver la bonne taille de shard duration adaptée à votre cas d’usage ; trop de shards ou des shards trop gros ont chacun leur limites et auront des effets différents sur la consommation CPU/RAM/IOPS
- Pour InfluxDB (Entreprise), il est recommandé d’avoir maximum 1.000 shards et 30/40 bases par node.
- La version 2.x OSS n’apporte pas grand chose de plus sur le sujet - la version 2.1 permet d’être à peu près au niveau de la 1.x.
Mise à jour : le client reporte les gains suivants post restructuration des bases pour le serveur de recette et production :
- Les dashboards simples sont entre 15% et 30% plus rapides pour leur affichage
- Les dashboards complexes sont entre 3 et 10 fois plus rapides pour leur affichage
- La consommation mémoire reste stable autour de 6/8 Go
- Des changements sur la shard duration de certaines bases ont permis de descendre jusqu’à 600 shards environ.
Web, Ops, Data et Time Series - Mai 2021
hashicorp nomad ovh time leap second gitlab-ci python dbt metabase datatask warp10 monitoring wasm sécurité spectre timescale sql cli readme bootstrap influxdata kapacitor chronografCI
- GitLab CI Python Library : une librairie en python pour créer des pipelines Gitlab-CI plutôt qu’en YAML.
Cloud
Conteneur et orchestration
- Announcing General Availability of HashiCorp Nomad 1.1 : 10 nouvelles fonctionnalités au programme (7 en OSS, 3 en entreprise) : surallocation de mémoire (soft et hard limit), les CPU peuvent être réservés en tant que tel (et non plus uniquement via une fraction), amélioration d’UI, amélioration coté support CSI, distinction entre les “readyness checks” et “liveness checks” au niveau des health checks, exécution distante sur AWS Lambda et AWS ECS (tech preview). Pour la version entreprise : supper des namespaces consul, chargement automatique des licences lors du déploiement de nouveaux noeuds, amélioration de l’autoscaling.
Data
- Hosting SQLite databases on Github Pages : avec une petite pointe de WASM, exemple de pouvoir utiliser une base sqlite en lecture hébergé en statique et un peu de javascript. Intéressant pour mettre à disposition des applications en “lecture seule” et leur scalabilité.
- DataTask pour construire une self-service BI, Revue des principaux concepts de dbt et création d’un premier modèle dans DataTask, DBT : Workflows, Matérialisations et Documentation, Metabase : Les concepts de question, visualisation et dashboard, DBT et la gouvernance des données : tests de validité/qualité et documentation : S&rie de billets sur la mise en place d’une solution de BI avec dbt et Metabase et l’intégration au sein de la plateforme DataTask
- xo/usql (via MACI #42) : une CLI universelle pour des bases SQL comme MySQL, Postgres, SQLite mais aussi des solutions SaaS comme Snowflake, Spanner et même SAP Hana.
Docs
- readme.so (via MACI #42) : Vous ne savez pas quoi mettre dans votre README ? Ce site est fait pour vous et peut aussi vous aider à réorganiser vos fichiers.
Europe
- Souveraineté et cloud, quel rapport ? : remise en perspective du cloud souverain et implications des décisions européenes. La remise en cause du Privacy Shield et les clauses contractuelles font qu’au final : “tout transfert de données personnelles sous juridiction américaine est illégal.”. La reglementation européene, centré sur le respect des droits des personnes permettrait de fiare un protectionnisme reglementaire dans l’idée de développer un écosystème numérique européen et conforme aux valeurs européennes. A lire et méditer !
License
- Third Party Dependencies that have been Relicensed to AGPL : la position de la CNCF sur les projets passant sous licence AGPL et leur éventuelle intégration dans des projets CNCF. Plutôt mal parti…
Système
- negative leap second news! : une seconde est intercallée de temps à autre pour se resynchroniser avec la rotation terrestre. En général, on ajoutait une seconde. Là, on va retirer une seconde - c’est apparemment la première fois que cela se passe.
Sécurité
- Defenseless: UVA Engineering Computer Scientists Discover Vulnerability Affecting Computers Globally : Vous pensiez en avoir fini avec SPECTRE ? Les correctifs arrivaient assez tard dans la chaine de traitement, des chercheurs ont réussi à intervenir avant pour récupérer des informations. Publications à compter du mois de juin.
- Everything Old is New Again: Binary Security of WebAssembly : si certains pensaient être sauvés par WebAssembley, c’est raté. La VM WebAssembly peut avoir ses propres failles d’une part et d’autre part, un code source vulnérable en WebAssembly présenterait les mêmes failles une fois compilé.
Time Series
- $40 million to help developers measure everything that matters : Timescale annonce une levée en série B de 40 Millions de dollars - environ 2 millions d’instances actives et une dizaine de sorties produits pour le mois de Mai.
- How we made DISTINCT queries up to 8000x faster on PostgreSQL : dans le cadre de la sortie de TimescaleDB 2.2.1, l’arrivée de “Skip Scan” permet d’accélérer les
SELECT DISTINCTentre 28x et 8000x. Cela est valable tant pour les données Timescale que les données natives Postgres. Une contribution upstream est prévue. - TimescaleDB 2.3: Improving columnar compression for time-series on PostgreSQL : Après le rajout des ALTER/RENAME des colonnes compressées en 2.1 - le rajout des INSERT avec une compression en deux temps (compression de l’insert en lui même puis recompaction des données au niveau du chunk)
- QuestDB 6.0 : implémentation de la gestion du Out Of Order, amélioration sur le InfluxDB Inline Protocol ainsi que sur l’UI et la couche SQL.
- How we achieved write speeds of 1.4 million rows per second : retour plus détaillé sur la gestion du Out Of Order dans QuestDB.
- InfluxDB OSS and Enterprise Roadmap Update from InfluxDays EMEA : InfluxData juge qu’à partir de la version 2.0.6, la mise à jour depuis une version 1.8 est stable. La version 1.8 sera donc maintenue jusqu’à la fin d’année. Au-delà de cette date, les correctifs ajoutés seront dans la branche master mais il n’y aura plus de packaging de la version 1.8 OSS. Seule la version 1.8 Entreprise aura de nouveaux binaires. Abandon des binaires en 32 bits pour InfluxDB 2.x. Concernant la version Entreprise, InfluxDB 1.9 va apporter des améliorations notamment concernant le support de Flux. Par ailleurs Chronograf 1.9 et Kapacitor 1.6 vont sortir en juin avec diverses améliorations. Ces deux produits seront compatibles avec InfluxDB 2.x pour aider à la montée de version vers InfluxDB 2.x. Enfin, InfluxDB 0SS 2.1 va sortir aussi en juin avec notamment l’ajout des notebooks, les annotations sur les dashboards et des améliorations de Flux.
- Release Announcement: InfluxDB OSS and InfluxDB Enterprise 1.8.6 : version de maintenance avec une faille de sécurité pour la version Entreprise.
- Monitorer son infra avec Warp 10 - Partie 1, Partie 2, Partie 3 : Mise en oeuvre des outils de la plateforme Warp 10 pour monitorer son infrastructure. Cela couvre l’installation, la collecte des métriques, l’exploration des données et calcul des premiers métriques, et pour finir la création des dashboards.
- Mon Linky dans Warp 10 avec un joli dashboard : Ingestion des données issues du Linky dans Warp 10 et présentation de ces données dans un Dashboard Discovery.
- May 2021: Warp 10 releases 2.8.0 and 2.8.1 - SenX : En résumé (liste non exhaustive, va falloir qqs billets plus détaillés pour comprendre toutes les nouveautés) : Gestion plus fine des “capabilities” au niveau des tokens, Utilisation de FLoWS simplifié, Intégration avec la blockchain Ethereum, Des fonctions de crypto / signature / …, Des améliorations sur la manipulation de JSON, Une fonction HTTP pour permettre des appels distants, Ajout de mapper.geo.fence pour voir si un point est dans/en dehors d’une zone, Des choses autours des MACRO et plein d’autres améliorations/corrections.
- Working with GEOSHAPEs: code contest results : le corrigé du concours lancé par SenX autour des GEOSHAPEs dans Warp 10. Concours que j’ai remporté et voici mes réponses : partie 1 & partie 2
- Wikipedia / Warp 10 : Warp 10 dispose de sa page Wikipedia
- « Le bateau qui vole » : l’analytique en temps réel au service d’un skipper : de l’utilité des séries temporelles dans le monde de la course au large pour une meilleure appréhension du fonctionnement du bateau et de ses performances. Ce retour d’expérience sera le thème d’une prochaine édition du Time Series France !
Web
- Bootstrap 5 : nouvelle version majeure du framework Boostrap avec la suppression de la dépendance à JQuery et la fin de support de plein de vieux navigateurs notamment.
Web, Ops, Data et Time Series - Avril 2021
falco sysdig sécurité dashboard raspberrypi pico hashicorp vault vector containerd git git-filter-repo psp gitlab-ci podman warp10 sqlite terraform timescale velero docker docker-compose grafana loki tempo kubernetes minio influxdata notebook geospatial agpl bme680 co2Code
- Docteur, j’ai commité 8 Go dans mon Git. C’est grave ? : un petit exemple de l’utilisation de git-filter-repo pour nettoyer son historique git de fichiers inutiles.
- Les pipelines parent-enfant de gitlab-ci : article sur la modularisation de gitlab-ci avec les pipelines parent/enfant au sein d’un même dépôt de code ou entre plusieurs dépot avec passage de variables entre eux.
- Minio Changes License to AGPL : Minio passe (aussi) son code en AGPL, l’annonce officielle n’est pas encore arrivée.
Conteneur et orchestration
- Electro Monkeys - Docker Compose avec Nicolas de Loof : Retour sur la Developper Experience autour de Docker, l’historique et le futur de docker-compose, la création de la spécification Compose, les intégrations AWS/ECS et Azure/ACI, l’intégration Kubernetes, etc.
- nerdctl: Docker-compatible CLI for contaiNERD : une CLI qui imite la CLI Docker mais en interagissant directement avec containerd. Elle permet aussi de bénéficier de certaines fonctionnalités de containerd qui ne sont pas prévues pour tout de suite dans Docker apparemment.
- Blog: Kubernetes 1.21: Power to the Community : au programme de cette nouvelle version : Cronjobs GA, Immutable Secrets and ConfigMaps GA, IPv4/IPv6 dual-stack support, Graceful Node Shutdown, PersistentVolume Health Monitor mais aussi PodSecurityPolicy Deprecation et TopologyKeys Deprecation
- PodSecurityPolicy Deprecation: Past, Present, and Future: article plus détaillé sur la dépréciation des PSP.
- Podman v3.1.0 Released : ajout de la gestion des secrets, améliorations des commandes kube avec notamment la génération des PersistentVolumeClaim ou encore la gestion des propriétaires des volumes.
- Velero 1.6.0 : améliorations diverses comme le support des identifiants par buckets (et non globaux uniquement), mise à jour de restic vers 0.12.0, etc.
- Compose CLI Tech Preview :
composedevrait devenir une sous-commande officiel de la CLI Docker ; on pourra alors fairedocker compose up -d - Docker 20.10.6 : version de maintenance avec le support des puces Apple Silicon M1.
- Kubernetes : vers 3 releases par an au lieu de 4 : de quoi courrir un peu moins derrière les versions et à relier avec le support de chaque version étendue à 1 an depuis la 1.19.
Data
- sq: swiss-army knife for data : le
jqpour les données relationelles. Du SQL ou des fichiers Excel/CSV/JOSN/XML en entrée et les mêmes formats en sortie (et un peu plus). - SQLite is not a toy database : On a souvent une fausse image de sqlite - l’article permet de se mettre à jour…
IaC
- Conditional nested blocks in Terraform : si les dynamic blocks avec terraform sont utiles pour peupler dynamiquement des structures à partir de tableaux/listes/objets, il peut aussi être utiliser pour gérer la présence conditionnelle de blocs.
- Announcing HashiCorp Terraform 0.15 General Availability : la plus grosse annonce étant que la 0.15 initie les travaux en vue de la release 1.0 ; pour ceux qui sont à jour, la mise à jour ne devait pas poser de problèmes (cf guide). Pour plus d’informations, cf CHANGELOG.
- HashiCorp is the latest victim of Codecov supply-chain attack : victime de la supply chain attach de codecov, Hashicorp vient de publier les versions patchées de Terraform des versions 0.11 à 0.15. Faites la mise à jour rapidement même si la clé volée n’a a priori pas été utilisée frauduleusement.
IoT
- Pico 2 Pi Adapter Board : un petit adapteur sympathique pour Raspeberry Pi Pico et vous permettre de brancher facilement vos composants sans soudure et mener ainsi vos expériences.
- Piper Make : Pour programmer facilement votre Raspberry Pi Pico en MicroPython mais avec une logique de blocs à la Scratch.
- Utilisation des BME680 et RV3028 avec Raspberry Pi Pico : le composant BME680 permet d’évaluer la qualité de l’air - le projet permet donc de capturer et d’afficher cette information avec un Raspberry Pi. Son successeur, le BME688 dispose d’une pincée d’IA.
- Projet CO2 et Makers CO2 : pour mieux comprendre les enjeux autour de l’aération des pièces et comment faire vos capteurs.
Observabilité & Monitoring
- Coder ses dashboards Grafana avec Grafonnet : Grafonnet est une extension de jsonnet ; il permet de déclarer ses dashboards Grafana via un lanage formalisé plutôt que de copier/coller des dashboards en JSON. Cela permet ainsi d’avoir une approche un peu plus “Dashboard as code”.
- Grafana 7.5 released: Loki alerting and label browser for logs, next-generation pie chart, and more! : un nouveau panel pour les “camembers” (“pie charts”), des améliorations pour les autres produits grafana (loki, tempo), ainsi qu’Elasticsearch, Postgresql et Cloudwatch et sur la version Entreprise.
- Vector v0.12.0 Release Notes, 0.12.1, 0.12.2 : Comme indiqué en février, la release de Vector apportant leur nouveau langage de traitement “Vector Remap Language est disponible, ainsi que des améliorations sur
vector top, la sourceinternal_logset l’API GraphQL. Un guide de mise à jour vers la nouvelle syntaxe est disponible. - Release Announcement: Telegraf 1.18.1 : version de maintenance
- Grafana, Loki, and Tempo will be relicensed to AGPLv3 & Q&A with Grafana Labs CEO Raj Dutt about our licensing changes : les produits phares de Grafana Labs passent d’une licence Apache 2 à AGPLv3. Les autres produits pourront rester sous licence ASL 2.0. L’AGPL étant contaminante, cela pourrait interdire l’usage de ces produits dans certains contextes, y compris à la CNCF. Vu l’implication de Grafana Labs dans le monde Prometheus, il va falloir suivre comment cela va se passer.
Réseau
- The Mystery of AS8003 : Une entité inconnue jusque là mais liée à l’administration américaine a annoncé la gestion d’une très grande plage réseau. Les implications et les motivations sont encore à éclaircir. Le billet émet différents hypothèses. Le thread twitter associé est intéressant aussi.
Sécurité
- Electro Monkeys - La sécurité dans tous ses états – détection de comportements indésirables grâce à Falco avec Thomas Labarussias : Présentation des projets falco et sysdig qui permettent d’analyser les comportements de vos applications (conteneurisées ou pas) en se basant sur les syscalls.
- Announcing HashiCorp Vault 1.7 : version mineure avec des améliorations internes au produit, sur la version entreprise et un peu au niveau UI.
Time Series
- InfluxDays EMEA 2021 Virtual Experience : InfluxData organise la session européenne de sa conférence avec le point sur les différents produits et les développements à venir. Des nouvelles de l’écosystème (Grafana, etc) sont attendues aussi, ainsi que des retours clients. Des formations Flux et Telegraf sont aussi prévues respectivement les 10/11 mai et le 17 Mai.
- InfluxData releases InfluxDB Notebooks to enhance collaboration for teams working with time series data & Build notebooks in InfluxDB Cloud | InfluxDB Cloud Documentation : InfluxData lance son offre de notebook intégré à sa plareforme InfluxDB (version cloud uniquement pour le moment)
- Build a Complete Application with Warp 10, from TCP Stream to Dashboard : exemple complet de l’utilisation de la plateforme Warp 10 depuis l’ingestion des messages AIS des bateaux via un client TCP jusqu’à la visualisation des données après un passage par les étapes de stockage et nettoyage des données. Très intéressant même si je vais devoir relire tranquillement le billet pour bien comprendre certaines astuces et certains “raccourcis” au niveau du code.
- Working with GEOSHAPEs & Working with GEOSHAPEs: code contest! : un billet (et un concours) pour exploiter la dimension géospatiale de Warp 10.
- TimescaleDB 2.2.0 : diverses améliorations mais surtout une annonce sur la fin de support de Postgresql 11 à compter de mi-juin et de la prochaine version de TimescaleDB. C’est justifié par l’absence d’une fonctionnalité dans Postgresql 11.x et requise pour la prochaine version de TimescaleDB.
Web, Ops & Data - Février 2020
kubernetes tls swarm docker warp10 ptsm influxdata telegraf linky grafanaContainer et orchestration
- Deprecations AKA KubePug - Pre UpGrade (Checker) : Pas encore testé mais un outil qui validerait les objets kubernettes déployés dans un cluster versus une version d’API donnée. Vous pourriez ainsi identifier et anticiper les dépréciations et évolutions d’API.
- Mirantis will continue to support and develop Docker Swarm : Mirantis, qui a racheté il y a peu Docker Entreprise et aussi l’orchestrateur de conteneurs Swarm, vient d’annonce qu’ils continuaient à développer Swarm sans limite de temps. Mirantis a récemment ajouter la notion de Swarm Jobs et travaille sur la gestion des volumes via les plugins CSI (Container Storage Interface)
Sécurité
- It’s the Boot for TLS 1.0 and TLS 1.1 : Mozilla, Microsoft, Apple et Google se sont mis d’accord pour ne plus supporter les versions 1.0 et 1.1 de TLS pour des raisons évidentes de sécurité. Reste que cela risque de coincer un peu de part les configurations parfois un peu hasardeuses des serveurs et de l’irrégularité de leurs maintenances ou de la vieillesse de certains packages dans certaines distributions.
Time Series
- Monitoring the Linky electricity meter : un exemple d’ingestion et de visualisation des données du compteur Linky avec InfluxDB et Grafana. Mais c’est aussi faisable avec warp10
- Les vidéos du Meetup 4 du Paris Time Series Meetup sont en ligne : David McKay, developer advocate InfluxData nous a présenté InfluxDB 2.0 & Flux ainsi que les bonnes pratiques avec Telegraf. Vous pouvez retrouver des exemples sur le dépot git influxdb-examples ainsi que le projet bring your own telegraf. Les slides sont visibles sur son compte speakerdeck.
- [Interview] How AIM45 uses Warp 10 to analyze ocean races data? : Interview d’Olivier Douillard d’AIM45 qui utilise la solution Warp10 pour collecter les données des bateaux de course au large en vue d’améliorer leurs performances de navigation mais aussi avoir le suivi de nombreux indicateurs matériels, etc. C’est aussi très bien montré sur cette vidéo “Big Data aboard the Maxi Edmond de Rothschild” avec ses 500 points de mesure qui donnent 10 millions de points par heure et quelques gigas de données après une course à analyser.
