Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Web, Ops & Data - Février 2021
java repository artefact timescale postgres kapacitor grafana nomad hashicorp podman docker-compose registry docker golang vscode warp10 dataviz transformation vector linterContainer et orchrestration
- Running Nomad for home server : pour avoir mené une expérience très similaire sur le mois de janvier, je me retrouve complètement dans ce retour d’expérience sur nomad (vs kubernetes dans une certaine mesure). Le trio nomad/consul/vault permet de faire des choses assez proches de ce que l’on peut faire avec kubernetes et parfois même de façon plus simple. Et ce, avec moins de couches intermédiaires (CSI, CNI, etc) mais aussi quelques fonctionnalités en moins. Un compromis assez réussi je trouve entre un docker nu et/ou avec docker-compose et un kubernetes.
- Podman 3.0 has been released! : support de docker-compose, support des noms courts d’image, amélioration sur le réseau, apport de la dernière version de buildah, correction d’une CVE, etc.
- Donating Docker Distribution to the CNCF : Docker Inc donne sa registry à la fondation CNCF pour fédérer les initiatives autour d’un même standard et élargir le champ des contributeurs/mainteneurs.
- Panorama des outils de sécurité autour des conteneurs : comparaison des outils de bonnes pratiques et d’analyses de vulnérabilités des containers docker pour améliorer la sécurité de vos conteneurs.
Code
- Gopls on by default in the VS Code Go extension - The Go Blog : amélioration du support de Go dans VSCode.
- Awesome Linters : si vous cherchez un linter, vous devriez le trouver dans ce dépot
- Into the Sunset on May 1st: Bintray, JCenter, GoCenter, and ChartCenter : JFrog va arrêter les services Bintray, JCenter, GoCenter et ChartCenter le 1er mai. La proposition est de migrer sur l’offre JFrog Cloud ou de trouver une alternative.
Monitoring & observabilité
- Datadog Acquires Timber Technologies | Datadog : Datadog achète la société Timber Technologies qui édite le project vector. Pourvu que cela ne nuise pas au projet.
- Datadog Signs Definitive Agreement to Acquire Sqreen | Datadog : Datadog achète aussi Sqreen qui était dans le domaine de la sécurité.
- Vector Remap Language : la version 0.12 de vector va apporter un nouveau langage plus fonctionnel pour définir le traitement sur ses logs. A tester !
- Building a Telegraf Assistant – UC Berkeley Codebase : des étudiants de l’universite de Berkeley ont travaillé sur la capacité de pousser une configuration à distance à telegraf. A voir si le code arrive jusque dans le produit telegraf, ce serait sympathique en tous cas !
Time Series
- Time-Series Analytics for PostgreSQL: Introducing the Timescale Analytics Project : Timescale va publier des fonctions orientées time series sous la forme d’extensions postgres. A priori réutilisable sans utiliser le reste de la base Timescale (à confirmer). De quoi simplifier certaines manipulations ?!
- TimescaleDB 2.0 is now Generally Available : annonce officielle de la sortie de TimescaleDB 2.0 même si la 2.0.0 est sortie à Noel et la 2.0.1 fin janvier.
- Grafana 7.4 released: Next-generation graph panel with 30 fps live streaming, Prometheus exemplar support, trace to logs, and more : amélioration des panels, mode livrestream pour un panel, support des variables dans les notifications d’alertes et plein d’autres choses.
- Kapacitor 1.5.8 — Rollback Announcement | InfluxData : Rollback de la version 1.5.8 de Kapacitor (la couche de processing en mode batch/streaming dans un contexte InfluxDB 1.x) pour cause d’opération pouvant conduire à de la perte de données. Un correctif est attendu sous peu.
- TL;DR InfluxDB Tech Tips – How to Monitor States with InfluxDB : ce billet est intéressant pour compléter le billet sur le calcul de la durée d’un état avec des timeseries. Notamment, l’apport de la fonction
monitor.stateChanges()etmonitor.stateChangesOnly(). - Warp 10 2.7.3 : version de maintenance.
- A review of smoothing transforms in WarpLib : revue des possibilités de “lissage” de vos séries avec différents algorithmes inclus dans Warp 10 de la moyenne glissante simple à des algorithmes capables d’excluer les anomalies et pics ponctuels.
Si vous êtes en manque de news, vous pouvez aller consulter (et vous abonner) aux brèves du BigData Hebdo
InfluxDB 2.0 OSS - Notes de mise à jour
timeseries influxdb flux grafana telegrafInfluxDB 0SS 2.0 étant sortie, j’ai testé la mise à jour d’une instance 1.8.3 vers 2.0.1 sur une VM Debian 10 à jour.
Mise à jour
La documentation pour une mise à jour 1.x vers 2.x est disponible. La vidéo “Path to InfluxDB 2.0: Seamlessly Migrate 1.x Data” reprend cela et va plus loin en présentant bien tous les points à prendre en compte (y compris pour Telegraf, Chronograf et Kapacitor). Je ne rajouterai donc que mes remarques.
Concernant la commande influxd upgrade :
- Il est fort probable qu’il faille rajouter la commande
sudopour ne pas avoir de problèmes de permisisons. - Par défaut, les données migrées vont être mises dans
~/.influxdbV2. Or je doute que vous vouliez que vos données soient à cet endroit. Je vous invite donc à regarder la documentation deinfluxd upgradepour définir les propriétés--engine-pathet--bolt-path
Exemple:
mkdir -p /srv/influxdb/influxdb2
influxd upgrade --engine-path /srv/influxdb/influxdb2/engine --bolt-path /srv/influxdb/influxdb2/influxd.bolt
- A l’issue de la migration, un fichier
config.tomlest généré dans/etc/influxdb/. Il contient quelques valeurs issues de la migration et des valeurs par défaut. Je l’ai personnalisé de la façon suivante pour tenir compte de mes valeurs :
bolt-path = "/srv/influx/influxdb2/influxd.bolt"
engine-path = "/srv/influx/influxdb2/engine"
http-bind-address = "127.0.0.1:8086"
storage-series-id-set-cache-size = 100
- Post-migration, le service
influxdcherchait à initialiser ses fichiers dans/var/lib/influxdb/.influxdbv2. Ayant noté que le service InfluxDB prennait/etc/default/influxdbcomme fichier d’environnement, j’ai ajouté dans ce fichier :
# /etc/default/influxdb
INFLUXD_CONFIG_PATH=/etc/influxdb/config.toml
Dès lors, /etc/influxdb/config.toml était bien pris en compte et InfluxDB démarrait bien avec mes données.
Une fois InfluxDB 2 démarré, j’ai pu noter avec plaisir :
- que l’ingestion via telegraf continuait à se faire sans interruption,
- que mes dashboards Grafana continuaient à fonctionner.
Je n’ai donc pas d’urgence à migrer la configuration et le paramétrage de ces derniers. Je vais pouvoir le faire progressivement ces prochains jours.
N’utilisant pas Chronograf et Kapacitor, je n’ai pas eu de données à migrer ou d’ajustements à faire à ce niveau là. La vidéo reprend bien les points d’attention et les éventuelles limitations à prendre en compte dans le cadre de la migration.
Finalement, c’est pas mal qu’ils aient réintégrer les endpoints 1.x dans la version 2.0 à ce niveau là ;-)
La 2.0.2 étant sortie pendant ma mise à jour, j’ai poursuivi la mise à jour. Je suis tombé sur ce bug rendant l’écriture de données impossibles. Cela a mis en évidence un bug sur la migration des “retention policies” et sur le fait que j’avais aussi des très vieilles bases InfluxDB. Je n’aurai a priori pas eu ce bug en faisant la migration 1.8.3 vers 2.0.2. En tous cas, une 2.0.3 devrait donc arriver prochainement avec une amélioration du processus de migration faisant suite à ma séance de troubleshooting.
Migration des configurations
Elle peut se faire très progressivement - si par ex vous utilisez telegraf pour envoyer vos données et Grafana pour la partie dashboarding :
- Vous pouvez mettre à jour votre configuration telegraf en passant de l’outputs
influxdbà l’outputinfluxdb_v2sans impacter grafana qui continuera à accéder à vos données en InfluxQL - Vous pouvez ensuite mettre à jour votre datasource InfluxDB ou plutôt en créer une nouvelle et migrer vos dashboards progressivement sans interruption de service
Créer un accès en InfluxQL à un nouveau bucket
Si vous devez rétablir un accès à vos données via les API 1.x à un bucket nouvellement créé (j’ai profité de la migration pour mettre des buckets clients dans des organisations représentant les clients en question).
# Créer le bucket
influx bucket create --name <BUCKET_NAME> --retention 0 --org <ORGANISATION>
# Récupérer l'ID de bucket via la liste des buckets
influx bucket list
# Créer une DBRP (DataBase Retention Policies) pour le bucket en question - les accès en 1.x se font en mode SELECT * FROM <db_name>.<retention_policies> ...
influx v1 dbrp create --bucket-id=<BUCKET_ID> --db=<BUCKET_NAME> --rp=autogen --default=true
# Créer un utilsateur sans mot de passe pour le moment
influx v1 auth create --username <USER> --read-bucket <BUCKET_ID> --write-bucket <BUCKET_ID> --org <ORGANISATION> --no-password
# Créer un mot de passe au format V1
influx v1 auth set-password --username <USER>
Les utilisateurs migrés depuis la version 1.x sont visibles via influx v1 auth list.
Intégration InfluxDB 2.0 / Flux et Grafana
Le support de Flux dans Grafan existe depuis la version 7.1 mais il n’est pas aussi aisé que celui dans InfluxDB 2.0 OSS. Il y a certes de la complétion au niveau du code ou le support des variables mais pas de capacité d’introspection sur la partie données.
Pour le moment, je procède donc de la façon suivante :
- Création de la Requête via le Query Builder dans InfluxDB 0SS
- Passage en mode “Script editor” pour dynamiser les variables ou ajuster certains comportements
- Copier/coller dans l’éditeur de Grafana
- Ajustement des variables pour les mettre au format attendu par Grafana.
Ex coté InfluxDB 2.0 OSS / Flux :
from(bucket: v.bucket)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "net")
|> filter(fn: (r) => r["_field"] == "bytes_recv" or r["_field"] == "bytes_sent")
|> filter(fn: (r) => r["host"] == v.host)
|> derivative(unit: v.windowPeriod, nonNegative: false)
|> yield(name: "derivative")
La version dans Grafana :
from(bucket: "${bucket}")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "net")
|> filter(fn: (r) => r["_field"] == "bytes_recv" or r["_field"] == "bytes_sent")
|> filter(fn: (r) => r["host"] == "${host}")
|> derivative(unit: v.windowPeriod, nonNegative: false)
|> yield(name: "derivative")
La différence portant sur la gestion des variables v.host vs "${host}" et v.bucket vs "${bucket}".
Autre bonne nouvelle, les variables sont supportées dans Grafana ; vous pouvez donc définir les variables comme celles vu juste au-dessus :
Variable bucket de type “Query” en prenant InfluxDB/Flux comme datasource :
buckets()
|> filter(fn: (r) => r.name !~ /^_/)
|> rename(columns: {name: "_value"})
|> keep(columns: ["_value"])
Variable host de type “Query” en prenant InfluxDB/Flux comme datasource :
# Provide list of hosts
import "influxdata/influxdb/schema"
schema.tagValues(bucket: v.bucket, tag: "host")
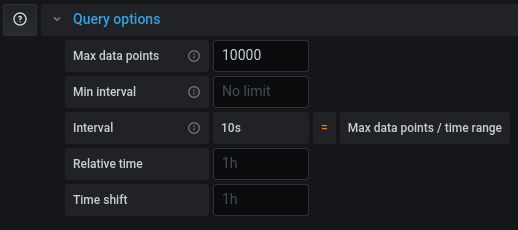
Si votre requête fonctionne dans un dashboard InfluxDB ou en mode explore mais qu’elle est tronquée dans Grafana, il vous faudra ajuster le “Max Data Points” pour récupérer plus de points pour cette requête (cf grafana/grafana#26484).
Web, Ops & Data - Septembre 2020
podman timezone grafana dashboard terraform sécurité terrascan terracost nvidia arm cni csi network storage cilium calico longhorn portworx openebs rancher python gke warp10 influxdb data-engineer date-scientist sqlCloud
- terrascan : terrascan va scanner vos fichiers terraform et les valider contre 500+ règles de sécurité (au format Open Policy Agent) afin d’identifier les éventuels problèmes de sécurité. L’outil supporte AWS, GCP et Azure.
- infracost : estimez le coût de vos projets terraform à l’heure ou au mois. Il est même possible de faire apparaitre les évolutions de vos coûts d’infra lors d’une MR/PR. A défaut d’être forcément précis, cela pourra au moins donner une idée et permettra peut être de sensibiliser les développeurs et/ou les clients aux évolutions de couts de leurs projets.
Code
- All Python versions before 3.6 are now totally unsupported : Python 2 n’est plus supporté depuis le début de l’année - c’est au tour de Python 3.5 de ne plus l’être depuis le 13 sept. Pour Python 3.6, ce sera décembre 2021.
- nackjicholson/aiosql : juste milieu (?) entre du SQL brut et un ORM, aiosql semble permettre d’associer une requête SQL à une fonction pour une manipulation assez simple ensuite dans le code par la suite.
Container et orchestration
- Tick-tock. Does your container know what time it is? : le fichier
/etc/localtimeest en général défini dans votre image de base et peut ne pas convenir à votre fuseau horaire. Podman permet de surcharger cela en précisant à l’exécution ou via un point de configuration le fuseau horaire à utiliser. Pratique plutôt que de modifier le fichier via votre Dockerfile. - Kubernetes Storage Performance Comparison v2 (2020 Updated) : une comparaison des solutions de stockage rook/Ceph, Azure PVC, Azure hosyPath, GlusterFS, Portworx, OpenEBS MayaStor et Rancher Longhorn. La conclusion se termine par un trio de tête emmené par Portworx, OpenEBS et Longhorn. Ce dernier étant plus adapté pour des besoins légers de stockage.
- New GKE Dataplane V2 increases security and visibility for containers & Google announces Cilium & eBPF as the new networking dataplane for GKE : GKE va utilise Cilium comme CNI pour son data plane v2 (il utilise actuellement Calico comme CNI si les network policy sont activées lors de la création de votre cluster)
- Benchmark results of Kubernetes network plugins (CNI) over 10Gbit/s network (Updated: August 2020) : pour des petits clusters, la solution la plus performante serait/resterait Calico et Cilium ne serait efficace que pour des gros clusters.
(Big) data
- #19. Lucien Fregosi - Hugo Larcher - Erika Gelinard - Dessine moi un data engineer : Pour cette saison 2 de DataBuzzWord, des réflexions intéressantes autour du Data Engineer / Data Scientists, le Data Engineer qui fait du Build/Run, les pipelines & job as a service et de l’importance de simplifier / déporter le run pour que le Data Engineer et a fortiori le Data Scientist se concentrent sur leurs pipelines ou leur exploitation et gérer moins d’infrastructure.
Hardware
- NVIDIA to Acquire Arm for $40 Billion, Creating World’s Premier Computing Company for the Age of AI : Nvidia sur le point d’acheter ARM pour en faire un leader des processeurs (CPU/GPU) et de l’IA. On voit que le sujet est politique dans le soin qui est apporté au site ARM de Cambridge et de son développement à venir.
Time Series
- InfluxDB OSS 2.0 General Availability Roadmap : un bon résumé sur les avancées d’Influx 2.0 OSS et la transition 1.x vers 2.x ; Début septembre, j’étais sceptique quand même avec le retour du stockage et du requêtage da la V1 dans la branche v2 (cf la PR “Port TSM1 storage engine”) et ce à un mois de la date de release prévue annoncés aux Influxdays de Londres (ie fin septembre). Au final, la version 2.0 OSS et Entreprise auront les feautres “frontend” de la V2 (Tasks, Dashobards, etc) mais uniquement le moteur de stockage de la V1. Si je comprends le besoin pour ne pas perdre leurs clients dans la migration, c’est un écart de plus entre les version OSS/Entreprise et la version Cloud. Les couches hautes (API, UI, fonctionnalités type Task/Dashboards/…) seront commmunes mais sous le capot (stockage, ingestion), cela diffère. On peut raisonnablement se demander si c’est une phase intermédiaire avant une migration ultérieure sur le moteur de stockage de la 2.0 quand InfluxData aura plus de recul sur le sujet ou bien si les projets Cloud et OSS/Entreprise ne vont pas diverger significativement à moyen terme. Ceux qui ont commencé à alimenter leur base InfluxDB 2.0 sur la base des versions beta devront repartir de zéro du fait de cette incompatibilité de version de moteur de stockage.
- Popular community plugins that can improve your Grafana dashboards : une collection de plugins Grafana pour améliorer vos dashboards.
- September 2020: Warp 10 release 2.7.0, ready for FLoWS : la version 2.7 de Warp 10 est disponible et est la première version qui va supporter FLoWS, la syntaxe fonctionnelle alternative à WarpScript. Pour en savoir plus sur FLoWS, je vous renvoie à l’édition 5 du Paris Time Series Meetup avec la présentation de FLoWS. D’autres améliorations font partie de cette release, tant d’un point de vue fonctionnalités que performances.
Web, Ops & Data - Juillet 2020
terraform acme letsencrypt influxdb influxdays questdb timeseries rancher suse stash kubedb maesh warp10 warpscript flows ptsm rgpd safe-harbor données personnelles grafana fluxCloud
- Gestion automatisée de certificats TLS avec Let’s Encrypt via Terraform et Ansible sur AWS : exemple d’utilisation du provider
acmeavec terraform pour la génération et le déploiement d’un certificat Let’s Encrypt dans un contexte AWS. - Custom Variable Validation in Terraform 0.13 : introduite en version expérimentale en 0.12.20, la validation personnalisée de variable sera stable en v ersion 0.13. De quoi valider ses ressources plus simplement.
- Avec l’acquisition d’OpenIO, OVHcloud se donne pour ambition de créer la meilleure offre de Stockage Objet du marché : acquisition d’OpenIO par OVHCloud. OpenIO fournit une solution de stockage compatible S3 et apparemment OVHVloud et OpenIO étaient habituées à travailler ensemble notamment autour de Swift (le stockage objet dans Openstack). Intéressant de voir ce type d’acquisition en Europe d’une part et de voir qu’OVHCloud remonte dans la chaine de valeur et rentre de plus en plus dans le monde du logiciel. A suivre !
Container et orchestration
- Announcing Maesh 1.3 : Maesh continue son chemin et ajoute la capacité de surveiller des namespace particuliées (en plus de pouvoir en ignorer), le support du lookup des ports (http -> 80), le support de CoreDNS chez AKS et d’autres améliorations encore.
- Electro Mpnkeys #9 – Traefik et Maesh : de l’ingress au service mesh avec Michael Matur : si vous voulez en savoir plus sur Traefik et Maesh, je vous conseille cet épisode (et les autres) du podcast Electro Monkeys.
- Introducing Traefik Pilot: a First Look at Our New SaaS Control Platform for Traefik : Containous, la société derrière Traefik, Maesh et Yaegi sort son offre SaaS pour piloter et monitorer ses instances traefik. Un système de plugins pour les middleware fait également son apparaition. Il faut une version 2.3+ (actuellement en RC) de Traefik pour bénéficier de cette intégration.
- Relicensing Stash & KubeDB : KubeDB, l’operateur de bases de données et Stash, l’outil de sauvegarde se cherchent un modèle économique et changent de licence. La version gratuite, avec code source disponible, reste disponible pour des usages non commerciaux (voir les détails de la licence pour une slite exacte). Pour un usage commercial, il faudra passer par la version Entreprise qui apporte aussi des fonctionnalités supplémentaires.
- Suse to acquire Rancher : Suse était sorti de mon radar; c’est donc pour moi l’entrée (ou le retour ?) de Suse dans le monde de kubernetes et de son orchestration. Est-ce une volonté d’aller prendre des parts de marchés à Redhat/Openshift ou de faire face à des rumeurs telles que Google en discussion pour acquérir D2IQ (ex Mesoshphère) ? A voir si cette acquisition va être un tremplin pour Rancher et ses différents projets (rke, rio, k3s, longhorn, etc) comme l’indique son CTO ou pas.
Time Series
- QuestDB nabs $2.3M seed to build open source time series database : QuestDB, historiquement issue du monde du trading à haute fréquence, commence à faire parler d’elle (notamment en récupérant un des DevRel d’InfuxData David G Simmons et vient de lever 2.3 millions de dollars. Elle a une approche SQL sur le traitement des données, se veut performante. A voir si elle reste une spécialiste de la série temporelle financière ou si elle parvient à s’ouvrir à d’autres usages.
- InfluxDays 2020 Virtual Experience : les vidéos et supports des InfluxDays sont disponibles.
- Paris Time Series Meetup #5 : De retour des InfluxDays et FLoWS : Résumé des keynotes autour des annonces produits des InfluxDays et présentation de FLoWS, la nouvelle syntaxte proposée par SenX pour interagir avec Warp10, en alternative à WarpScript. Le but est de faciliter la courbe d’apprentissage autour de Warp10. FLoWS est déjà disponible sur la sandbox et sera disponible cet été ou à la rentrée dans la version 2.7.0 de Warp10.
- Grafana v7.1 released: New features for InfluxDB and Elasticsearch data sources, table panel transformations, and more : grosse nouvelle version mineure de Grafana avec son lots d’amélioration et de nouveautés. Je vous laisse lire l’annonce.
- How to Build Grafana Dashboards with InfluxDB, Flux and InfluxQL : A l’occasion de la sortie de Grafana 7.1 qui apporte le support de Flux, présentation des nouveaux modes d’interaction entre Grafana et InfluxDB
Vie privée & données personnelles
Le Privacy Shield, l’accord entre l’Europe et les USA sur le transfert des données des Européens vers les USA (ou les sociétés américaines) vient d’être invalidé par la cour de justice européene. Les flux “absolument nécessaires” peuvent continuer à se faire pour le moment et la cour a validé “les clauses contractuelles types” définies par la Commission Européenne pourront être utilisées par les entreprises. Néanmoins, pour s’y référer, il semble qu’il faut vérifier que l’entreprise protège effectivement les données. Je vous invite à contacter votre juriste ou avocat pour mieux appréhender les impacts de cette invalidation si vous utilisez les plateformes cloud et des services dont les entreprises sont basées aux USA. En tant qu’individu, il peut être intéressant de se poser des questions également. N’étant pas juriste, je vais donc limiter mon interprétation ici et vous laisse lire les liens ci-dessous.
- La justice européenne sabre le transfert de vos données vers les USA à cause de la surveillance de masse
- L’accord sur le transfert de données personnelles entre l’UE et les Etats-Unis annulé par la justice européenne
- CJEU Judgment - First Statement
- L’accord sur le transfert de données personnelles avec les États-Unis invalidé par la justice européenne
- Invalidation du « Privacy shield » : la CNIL et ses homologues analysent actuellement ses conséquences
- Statement on the Court of Justice of the European Union Judgment in Case C-311/18 - Data Protection Commissioner v Facebook Ireland and Maximillian Schrems
- The End of the Privacy Shield Agreement Could Lead to Disaster for Hyperscale Cloud Providers
Web, Ops & Data - Mai 2020
docker ovh openstack fedora harbor registry traefik maesh percona mysql operator timescaledb grafana kubernetes terraform iac cert-manager devops raspberrypiLe mois prochain, dans le cadre d’InfluxDays London, j’aurai le plaisir de présenter un talk sur le passage d’un monitoring Bare Metal vers un monitoring dans un monde Kubernetes avec Telegraf et InfluxDB.
Cloud
- Terraform v0.13.0 beta program : Terraform 0.13 (beta) devrait supporter au niveau des modules
depends_on,countetfor_each. Cela devrait éviter des dépendances parfois cryptiques. - Deploy Any Resource With The New Kubernetes Provider for HashiCorp Terraform : la prochaine version du provider kubernetes de terraform permettra de déployer n’importe quelle ressource. Pratique ! Il vous faudra un cluster kubernetes 1.17+ pour utliser la fonctionnalité “Server Side Apply”.
- OVH : Utilisation de l’API OpenStack : Tutoriel pour le déploiement d’un wordpress sur un cluser k3s chez OVH en utilisant l’API OpenStack ; le reste du blog La Grotte du Barbu fournit plein de ressources sur kubernetes, traefik, docker, etc.
Container & orchestration
- How To Install Docker On Fedora 32 Or 31 (And Alternatives) : Même si l’utilisation de podman est recommandée en lieu et place de docke-ce depuis Fedora 31, il peut être nécessaire de vouloir utiliser docker-ce sous Fedora. Avec Fedora 32, il faut en plus des cgroups v1 à activer, il y a une règle firewall à ajouter pour que vos conteneurs aient accès au réseau / à internet.
- Harbor 2.0 : Version 2.0 de la registry Harbor qui permet d’héberger aussi des charts Helm. Pour la partie scan de vulnérabilités, le produit Clair de Quay a été remplacé par Aqua Trivy
- Announcing Maesh 1.2 : la solution de Service Mesh de Containous basée sur Traefik sort en 1.2 ; elle se base sur Traefik 2.2 et apporte donc le support de l’UDP au niveau reverse proxy. Cette version permet aussi des améliorations au niveau ACL, gestion de la configuration et gestion des middlewares par service.
- Introduction to Percona Kubernetes Operator for Percona XtraDB Cluster
- Cert-manager v0.15 and beyond
- CDK for Kubernetes : AWS vient de sortir un “Cloud Development Kit” permettant de manipuler et déployer des ressources kubernetes en python, typescript ou javascript.
DevOps
- DevOps : Discovering, Learning and Sharing (code source) : Guilhem vient de publier sa formation de culture DevOps ; à consulter !
- Radio DevOps : un podcast qui s’améliore d’épisode en épisode et plutôt adressé à des débutants dans le monde du DevOps.
IoT
- Raspberry Pi 4 USB mass storage beta (beta means it not ready yet, and not officially released!) : Le Raspberry Pi 4 va pouvoir démarrer sur un périphérique USB (clé USB, disque SSD, etc) avec l’arrivée du prochain firmware. La nécessité de la SDCard va disparaitre.
Time Series
- A multi-node, elastic, petabyte scale, time-series database on Postgres for free (and more ways we are investing in our community) : Timescale annonce que sa version cluster de TimescaleDB sera gratuite (sous licence Timescale, source code available mais pas le droit de faire un produit SaaS avec). La version monoserveur reste sous licence Apache 2.
- Grafana v7.0 released: New plugin architecture, visualizations, transformations, native trace support, and more : A l’occasion de la GrafanaCon 2020, Grafana Labs a sorti notamment Grafana 7.0 avec des tonnes d’amélioration. Il va falloir un peu de temps pour bien apprécier tout cela.
- GrafanaCon 2020 : la conférence annuelle de Grafana s’est tenue tout le mois de Mai, les vidéos sont accessibles sur la page de chaque talk après avoir saisi son email. Je n’ai malheureusement pas encore eu le temps de les visionner. Cortex 1.1 et Loki 1.5 y ont notamment été annoncés.
