Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Web, Ops, IoT et Time Series - Janvier 2026
ia llm ci forgejo woodpecker aws gpu anthropic python postgres tailwind javascript framework claude excel jquery deepseek gitlab mcpCI/CD
- Breaking Up with GitHub Actions: Our Love Story with Woodpecker CI : l’annonce de changement de prix des Github Actions et des Github Runners (même si Github est partiellement revenu dessus depuis), a encouragé certains à envisager des solutions alternatives comme Forgeo pour la partie Git & issue et Woodpecker CI pour la partie CI. Au passage, on notera l’usage de nginx comme solution de cache (faut bien bosser ses entêtes HTTP mais ça évite des solutions plus lourdes comme Nexus & co)
- CI/CD inputs: Secure and preferred method to pass parameters to a pipeline : Gitlab recommande d’utiliser des
inputsplutôt que desvariables. Lesinputspermettent le typage, une valeur par défaut, un scope ainsi que des règles de validation. De quoi fiabiliser vos pipelines !
Cloud
- AWS raises GPU prices 15% on a Saturday, hopes you weren’t paying attention : vers la fin du mythe où le Cloud coute perpétuellement moins cher d’une période à l’autre et en particulier avec l’IA et les GPU. Acte isolé ou nouvelle tendance ?
Database
- Life Altering Postgresql Patterns : un recueil de bonnes pratiques et astuces pour Postgres.
IA
- 2025: The year in LLMs : Impressionnante retrospective de l’année par Simon Willison sur son usage et sa perpectpion des LLM - une 30aine de “l’année du … avec le LLM”
- Nos prédictions pour 2026 vont vous surprendre ! : les chroniqueurs et quelques invités de Silicon Carne font leur prédictions pour 2026 - si certaines sont déjà impactantes en soit, si on en croisent certaines, cela peut devenir complètement 🤯 ; ça parle beaucoup d’IA, mais pas que !
- Anthropic invests $1.5 million in the Python Software Foundation and open source security. : Après l’acquisition de Bun, Anthropic se met à soutenir la foundation Python. C’est plutôt malin de soutenir l’écosystème.
- Moxie Marlinspike de Signal lance Confer, une IA vraiment privée: le créateur de Signal lance Confer et veut appliquer à l’IA ce qu’il a fait avec Signal : fournir une IA respectueuse de la vie privée et ce de façon simple et intuitive. C’est encore jeune mais c’est prometteur.
- Claude in Excel : Claude va comprendre l’ensemble de votre fichier Excel - est-ce que cela va permettre à ce que les calculs soient moins faux ?
- Le 1er janvier 2026, DeepSeek a publié un nouveau papier de recherche : mHC (Manifold-Constrained Hyper-Connections) et DeepSeek et la révolution de la “plomberie” de l’IA : tout comprendre aux mHC : focus sur la nouvelle approche de DeepSeek qui fait encore parler de lui pour améliorer/stabiliser et accélérer l’entrainement.
- MCP Apps - Bringing UI Capabilities To MCP Clients : les échanges avec MCP se limitaient à du texte, les MCP-Apps permettent de faire des retours avec des interfaces riches et interactives. Modulo un focus sécurité à avoir en tête, cela débloque de nouveaux potentiels inédits. Il va falloir un peu de temps pour appréhender tout ça…
Javascript
- Choisir le bon framework, la bonne librairie JavaScript : un guide pratique pour chaque type de projet : une bonne grille de lecture (principes, sécurité, SEO, API, courbe d’apprentissage, écosysteme, etc) pour choisirs son framework javascript.
- JQuery 4.0.0 : 20 ans après, JQuery est toujours là et est présent sur 60/70% des sites ; VueJS, React et les autres ont encore du boulot devant eux !
OSS
- Tailwind and open source in the LLM era: when documentation no longer monetizes ou Tailwind et l’open source à l’ère des LLM : quand la documentation ne monétise plus: le début de janvier a commencé avec le fondateur de Tailwind indiquant qu’il ne développerait pas une feature dédiée aux LLM dans la mesure où ces mêmes LLM le contraignaient à licencer son équipe et impactaient son modèle économique. Depuis des sponsors sont arrivés mais le billet évoque les différentes pistes de monétisation d’un projet OSS. La désintermédiation des LLM pose aussi la question du financement des projets (OSS, créateurs, etc).
Python
- Stop Hardcoding Everything: Use Dependency Injection : L’injection de dépendance peut sembler parfois magique - un exemple basique et pratique pour apprécier le sujet et rendre son code plus modulaire et propre.
Docker et déploiement distant : tout est histoire de contexte
docker context ssh gitlab gitlab-ciKubernetes, c’est bien mais parfois on veut faire des choses plus simples et on n’a pas forcément besoin d’avoir un système distribué ou d’une forte disponibilité. Pour autant, il est agréable avec kubernetes de pouvoir interagit à distance avec l’API au travers de kubectl. Je me suis donc mis en quête d’une alternative. Partir sur k3s avec un déploiement mono-node ? Partir sur docker/docker-compose/docker-swarm ?
Je me souvenais que l’on pouvait exposer la socket docker sur le réseau en TCP et authentification par certificat mais cela ne me plaisait pas beaucoup. Je me suis alors rappelé que l’on pouvait interagir avec un hote docker via une connection ssh. En continuant à creuser, je suis tomber sur les contextes dans Docker et ce billet How to deploy on remote Docker hosts with docker-compose. Et là : 🤩
Alors, certes, pas de secrets, configmaps ou cronjobs mais un déploiement remote que je peux automatiser dans gitlab et/ou avec lequel je peux interagir à distance 😍
Création d’un contexte puis utilisation d’un contexte :
# Création du contexte docker
docker context create mon-serveur ‐‐docker “host=ssh://user@monserveur”
# Lister les contextes docker existant
docker context ls
# Utiliser un contexte
docker context use mon-serveur
# Vérifier le bon fonctionnement de la cli docker
docker ps
[liste de conteneurs tournant sur la machine "mon-serveur"]
# Vérifier le bon fonctionnement de la cli docker-compose
cd /path/to/docker/compose/project
docker-compose ps
Pour que cela fonctionne, en plus des versions récentes de docker et docker-compose coté client et serveur. Il vous faut aussi une version récent de paramiko coté client. Celle présente dans Debian 10 n’est pas assez à jour par ex, il a fallu passer par pip3 install paramiko. Il faut aussi avoir une authentification par clé pour se simplifier la vie.
Pour docker-compose, vous avez deux solutions pour utiliser un contexte distant :
# En deux commandes
docker context use <remote context>
docker-compose <command>
# En une commande
docker-compose --context <remote context> <command>
Dans gitlab, dans le fichier .gitlab-ci.yml, on peut alors profiter de cette intégration de la façon suivante ; je prends l’exemple du déploiement du site du Paris Time Series Meetup.
Tout d’abord, dans mon fichier docker-compose.yml, j’ai mis un place holder IMAGE qui sera remplacé par la référence de mon image docker fabriquée par gitlab-ci :
version: '3.8'
services:
web:
image: IMAGE
labels:
[...]
restart: always
Ensuite, dans gitlab-ci :
- le job “publish” génère la version html du site et le stock dans un artefact gitlab.
- le job “kaniko” va générer l’image docker contenant la version html du site. Pour passer la version de l’image, je stocke l’information dans un fichier
docker.env. Ce fichier sera sauvegardé en fin de job sous la forme d’un artefact disponible pour le job “docker”. - le job “docker” recupère ce qui était dans le
docker.envsous la forme de variable d’environnement. Il remplace ensuiteIMAGEpar sa vraie valeur. On initialise le contexte docker pour se connecter au serveur cible et on peut alors réaliser les actions habituelles avecdocker-compose.
---
stages:
- publish
- image
- deploy
publish:
image: $CI_REGISTRY/nsteinmetz/hugo:latest
artifacts:
paths:
- public
expire_in: 1 day
only:
- master
- web
script:
- hugo
stage: publish
tags:
- hugo
kaniko:
stage: image
image:
name: gcr.io/kaniko-project/executor:debug
entrypoint: [""]
variables:
RELEASE_IMAGE: $CI_REGISTRY_IMAGE:$CI_COMMIT_SHORT_SHA-$CI_PIPELINE_ID-$CI_JOB_ID
script:
- echo "IMAGE=${RELEASE_IMAGE}" >> docker.env
- mkdir -p /kaniko/.docker
- echo "{\"auths\":{\"$CI_REGISTRY\":{\"username\":\"$CI_REGISTRY_USER\",\"password\":\"$CI_REGISTRY_PASSWORD\"}}}" > /kaniko/.docker/config.json
- /kaniko/executor --context $CI_PROJECT_DIR --dockerfile $CI_PROJECT_DIR/Dockerfile --destination $RELEASE_IMAGE
only:
- master
- web
when: on_success
tags:
- kaniko
artifacts:
reports:
dotenv: docker.env
docker:
stage: deploy
before_script:
- docker login -u gitlab-ci-token -p $CI_JOB_TOKEN $CI_REGISTRY
script:
- sed -i -e "s|IMAGE|${IMAGE}|g" docker-compose.yml
- docker context use mon-serveur
- docker-compose pull
- docker-compose up -d
needs:
- job: kaniko
artifacts: true
when: on_success
only:
- master
- web
tags:
- shell
environment:
name: production
url: https://www.ptsm.io/
Et voilà ! 😎
Avec ces contextes (que l’on peut utiliser aussi avec swarm et kubernetes), on a donc un moyen simple et efficace pour déployer des conteneurs à distance et de façon automatisée.
Web, Ops & Data - Octobre 2020
kubernetes ingress yaml pipeline gitlab traefik rootless mesh yq jq devops data maturité mariadb s3 flows warp10 timeseries influxdb pulsar amqp mqtt kafka python git vscode arm nvidiaDes nouvelles du Paris Time Series Meetup : l’éditions 6 sur TimescaleDB et l’édition 7 sur QuestDB
CI/CD
- 3 YAML tips for better pipelines : la troisième est certainement la plus intéressante - il est possible d’avoir des mécanismes de “composabilité” / “héritage” avec YAML et Gitlab. Si les
includeetextendssont déjà sympathiques, lesanchorsont l’air de faire des choses intéressantes aussi !
Code
- What’s New In Python 3.9 et un thread twitter qui donne des exemples des principales nouveautés : au programme nouvelle syntaxe pour la fuston des dictionnaires, des méthides pour supprimer des suffixes/préfixes sur les strings, du typage et plein d’autres améliorations et corrections.
- Fortunately, I don’t squash my commits : s’il peut être tentant sur une MR/PR de faire un squash des commits, l’article vous confortera dans l’idée que ce n’est pas une bonne idée. En écrasant l’historique des commits, on y perd sur nos capacités de debug. Par ailleurs, il est conseillé de faire des petits commits pour capturer un ensemble de changements traduisant un moment précis du développement.
Container et orchestration
- Kubernetes Ingress Goes GA : l’apparition de IngressClassName dans k8s 1.19 va plus loin qu’un simple renommage de champ comme je l’avais compris initialement. C’est une vraie ressource et cela ouvre aussi des possibilités. Avant de l’utiliser, vérifiez aussi que vos ingress controller le supporte (en plus d’attendre d’être en 1.19)
- Houston, we have Plugins! Traefik 2.3 Announcement : la version 2.3 dont on a déjà parlé ici, est arrivé en version stable avec son support des plugins, son intégration avec Traefik Pilot, le support d’Amazone ECS et le support de la ressource IngressClassName. Au passage, Containous, la société éditrice de Traefik s’appelle maintenant Traefik Labs.
- Introducing Traefik Pilot 1.0: the Traefik Control Center : Version 1.0 de ce nouveau “Control Plane” de Traefik qui permet d’avoir une vision globale sur ses instances traefik, d’utiliser les plugins et d’avoir un monitoring et des alertes autour de la disponibilité, des performances et de la sécurité.
- Rootless mode : A voir si cela pourra être inclus dans la version 1.20 mais le rootless mode est clairement une tendance de fond dans kubernetes et les conteneurs en général. Si vous ne vous y êtes pas déjà mis, ne tardez pas !
- Announcing Traefik Mesh 1.4 - New Name, New Features : nouvelle version du service mesh par Traefik Labs et qui s’appelle maintenant Traefik Mesh (et non uniquement Maesh). Le reste des améliorations semble porter sur le filtrage des headers et des paths.
- yq : A command line tool that will help you handle your YAML resources better : vous voulez faire des opératoins sur des fichiers YAML sans faire un chart helm ou sortir kustomize, vous pouvez faire des choses minimalistes avec yq (le pendant yaml de jq).
- Bridge to Kubernetes GA, “bridge to kubernetes” est une extension pour vscode permettant de connecter une application tournant en local avec d’autres applications situées dans un ckuster kubernetes et faciliter ainsi l’expérience des développeurs.
Culture DevOps
- La culture de la résilience à travers le DevOps, DevPO, et DevQA : article intéressant de Paul Leclerq sur la résilience et la collaboration au sein d’une équipe.
Data
- How to Measure Your Organization’s Data Maturity : les différents stade de maturité de votre organisation concernant la gestion et l’exploitation des données.
- Announcing MQTT-on-Pulsar: Bringing Native MQTT Protocol Support to Apache Pulsar: Apache Pulsar, la plateforme de message distribué et de streaming, se dote d’un plugin “MQTT On Pulsar” (MoP) permettant ainsi de migrer vos applications MQTT sur Apache Pulsar. Après le plugin Kafka (KoP) il y a quelques mois en partenariat avec OVHCloud, Pulsar ajoute une corde à son arc pour devenir la plateforme universelle. Le protocole AMQP est déjà aussi supporté depuis plusieurs mois.
- Building An Event-Driven Orchestration Engine : retour d’expérience sur les raisons de la migration à Apache Pulsar e la simplificaiton apportée en ayant une platforme riche et complète (streaming + queue + fonctions + data tiering sur S3 + …)
Hardware
- NVidia’s Planned Acquisition of Arm Portends Radical Data Center Changes : une analyse assez en profondeur sur le rachat d’arm par nvidia et les autres acteurs du marché comme AMD.
IaC
- Announcing HashiCorp Terraform 0.14 Beta: la capacité à marquer des variables comme sensibles pour éviter que leur valeur soit visible dans les logs/diff/…, un diff plus concis, un lock sur les providers et des binaires disponibles pour arm64.
Monitoring
- Long-term store for Prometheus, with the combined power of SQL and PromQL : Timescale s’ajoute à la liste des solutions permettant un stockage long terme à vos données Prometheus. En plus de ce stockage long terme, elle fournit une couche d’analytics. Un connecteur récupère les données dans Prometheus et les injecte dans TimescaleDB. On en parle dans l’édition 6 du PTSM.
Pratique
- endoflife.date : recense les dates de fin de support de vos langages et technologies préférées. Tout n’est pas complètement à jour mais cela permet de récupérer rapidement les informations.
SQL
- Exciting and New Features in MariaDB 10.5 : évoqué au mois d’aout, le support de S3 dans MariaDB est disponible en version GA dans la version 10.5. D’autres améliorations existent comme le support du type INET6, des améliorations sur ColumnStore, la gestion des privilèges, le cluster Galera supporte complètement le GTID, du refactoring au niveau d’InnoDB et enfin les binaires mariadb vont enfin s’appeler mariadb et non plus mysql (avec une couche de compatibilité via des liens symboliques)
Time Series
- Introducing FLoWS, a functional language for Time Series Analytics : FLoWS est arrivé - il vous faudra utiliser une version 2.7.1+ de Warp10 pour profiter de cette approche fonctionnelle en alternative à Warpscript.
- How can you tell which Time Series Database is suited to your needs? : un petit rappel sur les critères à prendre en compte pour choisir une base de données séries temporelles ; j’avais déjà parlé du guide de Senx sur le sujet - il est disponible en fin de billet.
- InfluxDB 2.0 Release Candidate Now Available : la première Relese Candidate (RC0) pour InfluxDB 2.0 OSS avec le retour du moteur de stockage de la V1 - qui contrairement à ce que j’ai pu dire le mois dernier ne concernerait que la façon dont les données sont stockées sur disque et pas le reste d’une part et sera maintenu et amélioré par Influxdata d’autre part. Quelques changements sur le port (retour au port 8086). Pour ceux qui étaient en version alpha/beta, il faudra suivre une procédure de migration. La migration depuis une version 1.x n’est pas encore disponible, cela devrait être dans une prochaine RC. Vous pourrez tester néanmoins les API 1.x, les templates, une version récente de Flux ou encore les améliorations de la CLI.
- Release Announcement: InfluxDB 2.0.0 RC 1 : cette version apporte essentiellement l’upgrade des données 1.x vers 2.x et une mise à jour de Flux.
- Store and Access Time Series Data at Any Scale with Amazon Timestream – Now Generally Available - Getting Started with Amazon Timestream - AWS Releases Amazon Timestream into General Availability : AWS sort enfin son produit orienté time series après l’avoir annoncé il y a deux ans.
Sur la base des informations disponibles pour le moment :
- vous définissez une période de rétention en mémoire (entre 1h et 1 an) et une période de rétention sur stockage magnétique (1 jour à 200 ans),
- le requêtage des données se fait en SQL (via Presto ?),
- les données à requêter communément sont à mettre dans la même table,
- le join est limité à la même table,
- des mesures simples (pas de multi mesures pour un même enregistrement),
- une intégration avec l’écosystème comme telegraf, grafana, etc en plus de l’intégration avec différents composants AWS
Pour les moins bons côtés :
- pas d’UPDATE/DELETE sur vos données ; en cas de doublons, c’est le premier arrivé qui gagne
- pas de bulk import de vos données, donc pas de reprise de vos données existantes. En effet, il n’est pas possible d’ingérer des données plus vieille que la période en mémoire,
- dans la même veine, si un incident de production dépasse votre période de rétention, vous ne pourrez pas réinjecter vos données
- il ne semble pas possible de mettre à jour ses durées de rétention - donc pas de ménage possible ou d’ajustements en cours de route
Une solution a priori très orienté pour du monitoring et qui semble souffir des mêmes travers qu’InfluxDB avec InfluxQL et pourtant en passe d’être résolus avec Flux.
On devrait en parler plus en détail dans une prochaine édition du Paris Time Series Meetup avec des personnes de chez AWS ;-)
Work
- Virtual First Toolkit : toolkit proposé par Dropbox dans le cadre de leur passage non pas à Remote first mais à virtual first.
Intégration Gitlab dans Kubernetes pour automatiser ses déploiements
gitlab kubernetes deployment service-account gitlab-ciDepuis que j’ai migré des sites sous kubernetes, j’avais perdu l’automatisation du déploiement de mes conteneurs. Pour ce site, je modifiais donc le site et une fois le git push realisé, j’attendais que Gitlab-CI crée mon conteneur. Je récupérai alors le tag du conteneur que je mettais dans le dépôt git où je stocke mes fichiers de configuration pour kubernetes. Une fois le tag mis à jour, je pouvais procéder au déploiement de mon conteneur. Il était temps d’améliorer ce workflow.
Gitlab propose depuis un moment une intégration avec kubernetes mais je lui trouve quelques inconvénients au regard de mes besoins :
- Il faut créer un compte avec un ClusterRole cluster-admin et je ne suis pas super à l’aise avec cette idée,
- Il est nécessaire de déployer Helm encore en version 2 alors que je suis passé en version 3 pour les rares projets où je l’utilise,
- L’ingress s’appuie sur nginx-ingress, alors que j’utilise Traefik,
- Je n’ai pas l’usage des autres fonctionnalités fournies par Gitlab dans mon contexte de “cluster de test” hébergeant quelques sites et applications web.
Mon besoin pourrait se résumer à pouvoir interagir avec mon cluster au travers de kubectl et de pouvoir y déployer la nouvelle version du conteneur que je viens de créer. Cela suppose alors d’avoir 3 choses :
- le binaire kubectl accessible sous la forme d’un conteneur ou directement en shell dans le runner,
- un fichier
kubeconfigpour m’authentifier auprès du cluster et interagir avec, - la référence de l’image docker fraichement crée par Gitlab-CI à appliquer sur un Deployment kubernetes.
Création d’un compte de service avec authentification par token
Utilisant le service managé d’OVH, je n’ai pas accès à tous les certificats du cluster permettant de créer de nouveaux comptes utilisateurs. Par ailleurs, pour les intégrations comme Gitlab, il est recommandé d’utiliser des Service Accounts. C’est ce que nous allons faire.
En plus du Service Account, il nous faut donner un rôle à notre compte pour qu’il puisse réaliser des actions sur le cluster. Par simplicité pour ce billet, je vais lui donner les droits d’admin au sein d’un namespace. Le compte de service pourra alors faire ce qu’il veut mais uniquement au sein du namespace en question. En cas de fuite du compte, les dégats potentiels sont donc moindres qu’avec un compter qui est admin global du cluster. Le rôle admin existe déjà sous kubernetes, il s’agit du ClusteRole admin mais qui est restreint à un namespace via le RoleBinding.
Créons le fichier gitlab-integtration.yml avec ces éléments :
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: gitlab-example
namespace: example
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: gitlab-admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: admin
subjects:
- kind: ServiceAccount
name: gitlab-example
namespace: example
Déployons notre configuration sur le cluster :
# Apply yml file on the cluster
kubectl apply -f gitlab-integration.yml
serviceaccount/gitlab-example created
rolebinding.rbac.authorization.k8s.io/gitlab-admin created
Pour alimenter notre fichier kubeconfig, il nous faut récupérer le token :
# Get secret's name from service account
SECRETNAME=`kubectl -n example get sa/gitlab-example -o jsonpath='{.secrets[0].name}'`
# Get token from secret, encoded in base64
TOKEN=`kubectl -n example get secret $SECRETNAME -o jsonpath='{.data.token}'`
# Decode token
CLEAR_TOKEN=`echo $TOKEN |base64 --decode`
En prenant votre fichier kubeconfig de référence, vous pouvez alors créer une copie sous le nom kubeconfig-gitlab-example.yml et l’éditer de la façon suivante :
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: <Existing certificate in a base64 format from your original kubeconfig file>
server: <url of your k8s http endpoint like https://localhost:6443/ >
name: kubernetes # adjust your cluster name
contexts:
- context:
cluster: kubernetes # adjust your cluster name
namespace: example # adjust your namespace
user: gitlab-example # adujust your user
name: kubernetes-ovh # adujust your context
current-context: kubernetes-ovh # adujust your context
kind: Config
preferences: {}
users:
- name: gitlab-example # adujust your user
user:
token: <Content of the CLEAR_TOKEN variable>
Vous pouvez tester son bon fonctionnement via :
# Fetch example resources if any:
kubectl --kubeconfig=./kubeconfig-gitlab-example.yml get all
...
# Check you can't access other namespaces information, like kube-system:
kubectl --kubeconfig=./kubeconfig-gitlab-example.yml get all -n kube-system
Error from server (Forbidden): pods is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "pods" in API group "" in the namespace "kube-system"
Error from server (Forbidden): replicationcontrollers is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "replicationcontrollers" in API group "" in the namespace "kube-system"
Error from server (Forbidden): services is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "services" in API group "" in the namespace "kube-system"
Error from server (Forbidden): daemonsets.apps is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "daemonsets" in API group "apps" in the namespace "kube-system"
Error from server (Forbidden): deployments.apps is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "deployments" in API group "apps" in the namespace "kube-system"
Error from server (Forbidden): replicasets.apps is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "replicasets" in API group "apps" in the namespace "kube-system"
Error from server (Forbidden): statefulsets.apps is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "statefulsets" in API group "apps" in the namespace "kube-system"
Error from server (Forbidden): horizontalpodautoscalers.autoscaling is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "horizontalpodautoscalers" in API group "autoscaling" in the namespace "kube-system"
Error from server (Forbidden): jobs.batch is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "jobs" in API group "batch" in the namespace "kube-system"
Error from server (Forbidden): cronjobs.batch is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "cronjobs" in API group "batch" in the namespace "kube-system"
Integration Gitlab : stocker le kubeconfig
Gitlab permet de stocker des variables. Dans le cas d’un fichier kubeconfig, on va vouloir ne jamais afficher son contenu dans les logs ou autre. Pour cela il est possible de masquer vos variables en respectant quelques contraintes et notamment que la valeur de la variable tienne sur une seule ligne.
Nous allons donc encoder le fichier en base64 et rajouter un argument pour que tout soit sur une seule ligne (et non pas sur plusieurs lignes par défaut):
# create a one line base64 version of kubeconfig file
cat kubeconfig-gitlab-example.yml | base64 -w 0
Copier le contenu obtenu dans une variable que nous appelerons KUBECONFIG et dont on cochera bien la case “Mask variable”. Une fois la variable sauvée, vous avez ceci :
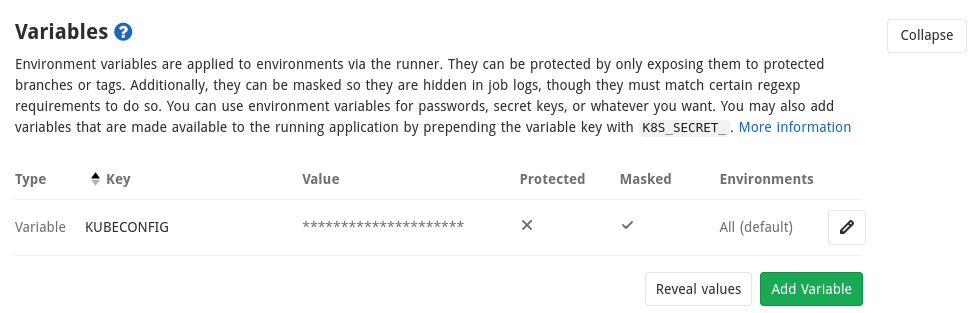
Intégration Gitlab : passer la référence de l’image au job de déploiement
Soit le fichier .gitlab-ci.yml suivant:
---
stages:
- publish
- image
- deploy
publish:
image: $CI_REGISTRY/nsteinmetz/hugo:latest
artifacts:
paths:
- public
expire_in: 1 day
only:
- master
- web
script:
- hugo
stage: publish
tags:
- go
docker:
stage: image
image: docker:stable
services:
- docker:dind
variables:
DOCKER_HOST: tcp://docker:2375
DOCKER_DRIVER: overlay2
RELEASE_IMAGE: $CI_REGISTRY_IMAGE:$CI_COMMIT_SHORT_SHA-$CI_PIPELINE_ID-$CI_JOB_ID
before_script:
- docker login -u gitlab-ci-token -p $CI_JOB_TOKEN $CI_REGISTRY
script:
- echo "IMAGE=${RELEASE_IMAGE}" >> docker.env
- docker build --pull -t $RELEASE_IMAGE .
- docker push $RELEASE_IMAGE
when: on_success
tags:
- go
artifacts:
reports:
dotenv: docker.env
kube:
stage: deploy
script:
- echo $KUBECONFIG | base64 --decode > kubeconfig
- export KUBECONFIG=`pwd`/kubeconfig
- sed -i -e "s|IMAGE|${IMAGE}|g" deployment.yml
- kubectl apply -f deployment.yml
needs:
- job: docker
artifacts: true
when: on_success
tags:
- shell
Petite explication rapide :
- l’étape
publishva générer la version html du site et la stocker sous la forme d’un artefact qui sera passé aux jobs suivants, - l’étape
dockerva créer l’image en mettant l’artefact du job précédent dans un conteneur nginx et le publier dans la registry gitlab avec le nom suivantgitlab.registry/group/project:<short commit>-<pipeline id>-<job id> - l’étape
kubeva récupérer le contenu de la variableKUBECONFIG, le décoder et créer un fichierkubeconfig. On initialise la variable d’environnementKUBECONFIGpour que kubectl puisse l’utiliser. On met à jour la référence de l’image docker obtenue précédemment dans le fichierdeployment.ymlqui sert de modèle de déploiement. On applique le fichier obtenu sur le cluster kubernetes pour mettre à jour le déploiement.
Le point d’attention ici est que le passage de la variable RELEASE_IMAGE se fait via un dotenv qui est créé sous la forme d’un artefact à l’étape docker et est donc disponible à l’étape kube. Cela devrait être automatique mais j’ai ajouté une dépendance explicite via la directive needs. Lors de l’étape kube, le contenu du fichier docker.env est disponible sous la forme de variables d’environnement. On peut alors faire la substitution de notre placeholder par la valeur voulue dans deployment.yml.
Tout ce mécanisme est expliqué dnas la doc des variables gitlab et sur les variables d’environnement héritées. Attention, il vous faut Gitlab 13.0+ pour avoir cette fonctionnalité et en plus, il faut préalablement activer ce feature flag.
sudo gitlab-rails console
Feature.enable(:ci_dependency_variables)
En conclusion, nous avons vu comment :
- Créer un compte de service (Service Account) sous kubernetes avec un rôle d’administrateur de namespace,
- Stocker le fichier
kubeconfigutilisant notre service account dans Gitlab sous la forme d’une variable masquée, - Passer une référence d’un job à un autre via les dotenv au niveau du job amont et les variables d’environnement au niveau du job en aval,
- Récupérer le contenu de la variable kubeconfig pour créer une variable d’environnement et être en mesure d’utiliser kubectl.
Ainsi, toute mise à jour de master conduira à une mise à jour du déploiement associé au sein du cluster kubernetes et ne nécessitera plus d’interventions manuelles comme précédemment. Avec un service account lié à un namespace, on évite aussi de s’exposer inutilement en cas de fuite des identifiants.
Web, Ops & Data - Avril 2020
traefik scaleway kubernetes telegraf cassandra kafka confluent helm influxdb warp10 timescaledb docker compose apache-pulsar pubsub deprek8 conftest opa raspberrypi gitlab sidecarCode et Outillage
- 18 GitLab features are moving to open source : Gitlab va rendre disponible dans sa version Open Source 18 fonctionnalités de sa version payante. C’est un peu la lutte avec Github et ses Github Actions ou ses dernières évolutions tarifaires.
Container & orchestration
- Announcing the Compose Specification : Docker Inc vient de lancer une spécificiation officielle autour de Compose (celle derrière les
docker-compose.yml) pour la rendre plus “cloud native” et plus générique avec une extension au provider cloud d’une part et d’autre part à des solutions comme kubernetes ou Amazone ECS par ex. - Announcing Traefik 2.2, ainsi que la version Entreprise TraefikEE 2.1 basée dessus : on notera le retour du support des annotations pour gérer les Ingress, le support de l’UDP (en plus de HTTP et TCP), le support d’Elastic APM, le support des stores KV (Consul, Etcd, Redis, etc) et le Dark Mode.
- Scaleway Kubernetes Kapsule : l’offre managée kubernetes de Scaleway est disponible. Dommage que les CPU des profils de machine
DEV*soient surprovisionnés et qu’il faille envisager des profilsGP*pour avoir des performances correctes. L’offre est du coup moins compétitive en termes de prix pour des petits clusters. - Kubernetes 1.18 : Fit & Finish : une version de consolidation
- How to detect outdated Kubernetes APIs : présentation de Deprek8 et de Conftest pour vous permettre d’évaluer les ressources kubernetes pour lesquelles vous n’êtes pas à jour au niveau des API.
- Helm 3.2.0 avec un correctif de sécurité sur les versions 3.0.x et 3.1.x et d’autres améliorations (comme le retour de certaines fonctionnalités non encore migrées depuis la 2.x)
- Cortex v1.0 released: The highly scalable, fast Prometheus implementation is generally available for production use : la solution de monitoring distribuée et avec un stockage de long terme basée sur Prometheus arrive en version 1.0. C’est l’occasion de se repencher sur son architecture et son fonctionnement.
- Build your very own self-hosting platform with Raspberry Pi and Kubernetes : une série d’articles pour déployer un cluster kubernetes sur vos raspberrypi avec la distributions k3s et y déployer différentes applications.
- Rook v1.3: Storage Operator Improvements : si vous n’êtes pas dans un environnement cloud, il y a de fortes chances pour que vous utilisiez Rook. La version 1.3 vient de sortir et apporte son lot d’améliorations.
- Sidecar container lifecycle changes in Kubernetes 1.18 : dans la version 1.19, le cycle de vie des sidecars dans kubernetes sera améliorée. Ainsi, ils démarreront avant le conteneur principal et s’arrêteront après. Le billet revient sur les problèmes existant et comment ce nouveau cycle de vie va améliorer la situation.
(Big) Data
- Confluent Raises $250M and Kicks Off Project Metamorphosis : Confluent, la soéciété éditrice de la Confluent Platform et d’Apache Kafka, vient de lever 250 millions de dollars et annonce le projet Metamorphosis et prévoit des annonces tous les mois sur Apache Kafka, Confluent Platform et ce projet à compter du mois de Mai. On en reparlera très certainement sur BigData Hebdo.
- Cassandra: The Definitive Guide, 3rd Edition : nouvelle édition de l’ouvrage de référence sur Cassandra, mis à jour notamment pour Cassandra 4.0 (version à venir)
- Announcing Kafka-on-Pulsar: bring native Kafka protocol support to Apache Pulsar : On en parle dans le prochain épisode de BigData Hebdo, mais Pulsar est une plateforme vraiment intéressante (Pulsar 101 en français ou en anglais) et les équipes d’OVHCloud viennent de publier un connecteur qui permet d’utliser l’API Kafka mais que les messages soient stockés dans Pulsar. Il existe aussi une vidéo sur Kafka on Pulsar et un article sur le blog d’OVHCloud.
Time Series
- Release Announcement: Telegraf 1.14.0 : 9 nouveaux inputs, 3 nouveaux processors et 1 nouvel output warp10 sont au programme de cette version. Les versions 1.14.1 et 1.14.2 sont sorties également avec quelques corrections.
- Release Announcement: InfluxDB 1.8.0 with Long-Awaited Features : la branche 1.x d’InfluxDB se voit donc dotée d’une version récente de flux qui se veut “production ready” et les endpoints d’InfluxDB 2.x sont aussi disponibles. Ce qui permet d’utiliser les nouveaux clients officiels InfluxDB prévus pour la 2.x d’une part et de faire des requêtes en Flux d’autre part.
- Release Announcement: InfluxDB 2.0.0 Beta 9 : mise à jour de Flux, autocomplétion flux dans l’éditeur de requêtes et amélioration de la CLI.
- InfluxDB Templates: Easily Share Your Monitoring Expertise : le billet a pour intérêt de présenter des bonnes pratiques sur la réalisation de templates InfluxDB. Pour rappel, les templates InfluxDB sont des “ressources” que l’on peut déclarer, exporter et importer dans une instance InfluxDB 2.x. Cela concerne des variables, labels, tasks, dashboards, alertes, etc.
- April 2020: Warp 10 release 2.5.0 : La version 2.5 de Warp10 apporte notamment un Accelerator c’est à dire un cache en mémoire pour les versions standalones. D’autres corrections et améliorations font également partie de cette release.
- WarpScript ❤️ Kafka Streams : si vous utiliser Kafka Streams et que vous voulez utiliser Warpscript pour consommer, processer et envoyer des données vers Kafka, c’est possible.
- Forecasting : Microsoft publie des exemples et des bonnes pratiques autour de la prévision à base de séries temporelles. Il y a des exemples en Python / R et quelques exemples avec Azure-ML.
- TimescaleDB 1.7: fast continuous aggregates with real-time views, PostgreSQL 12 support, and more Community features : Nouvelle version de TimeScaleDB apportant la compatibilité avec Postgresql 12.x, des aggrégats en temps réel et des fonctionnalités de gestion de données (réordonnancement et rétention) de la version Entreprise sont maintenant disponibles dans la version Community.
Web
- jQuery 3.5.0 Released! : une faille XSS a été identifiée sur
jQuery.htmlFilterpour toutes les versions inférieures à 3.5.0 ; il est vivement encouragé de mettre à jour vos sites. Pour le reste, je vous renvoie à la lecture de l’article.
