Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Ma solution pour le Warp 10 Code Contest - partie 2
timeseries warp10 geospatial challengeSuite et fin de ma réponse au code contest après la première partie. Dans ce billet, nous allons voir comment calculer les émissions de CO2 pour la partie de trajet sur la route 66.
// Define points from the car journey on the US66 road
[
// Here is the gts of the car datalogger
@senx/dataset/route66_vehicle_gts
// Here is the route 66 geoshape (+/- 20meters)
@senx/dataset/route66_geoshape
mapper.geo.within 0 0 0
] MAP
"onTheRoad" STORE
$onTheRoad
{
'timesplit' 60 s
}
MOTIONSPLIT
0 GET
'sectionOnTheRoad' STORE
// Compute speed - result in m/s
[ $sectionOnTheRoad mapper.hspeed 1 0 0 ] MAP
// Convert in km/h so x3600 /1000 = 3.6 - mapper.mul expects a constant
[ SWAP 3.6 mapper.mul 0 0 0 ] MAP
'speedFrames' STORE
// Get distance between each points in km (first in meters, then in km)
[ $sectionOnTheRoad mapper.hdist 0 1 0 ] MAP
[ SWAP 0.001 mapper.mul 0 0 0 ] MAP
'distFrames' STORE
// fuel consumption approximation is (8 liters/100km) × (speed (km/h) / 80) +1
// So it's Speed * 8 / 80 / 100 + 1 = V/10 + 1
// F = False => does not return the index
$speedFrames
<%
0.1 *
1.0 +
%> F LMAP
'hundredKmFuelConsumption' STORE
[ ] 'instantConsumption' STORE
<%
'i' STORE // store index
// Get each list and compute one by another
// So we compute consumption for 100 km at given speed (computed previously)
// with related distance
// then we divide by 100 as first value is for 100 km
$distFrames $i GET
$hundredKmFuelConsumption $i GET
*
100 /
'r' STORE
$instantConsumption $r +!
%>
'C' STORE
0 7 $C FOR
CLEAR
// For each GTS, compute fuel consumption as 1 point
[
$instantConsumption
mapper.sum
MAXLONG
MAXLONG
1
] MAP
// Sum all points to get total consumption
0 SWAP <% VALUES 0 GET + %> FOREACH
// 1L = 2392g CO2
2392 *
// Enjoy !
Le premier et le second bloc sont les mêmes que dans la premièr partie. Je vous y renvoie donc si besoin.
A ce stade, nous avons une liste de 8 séries correspondant à chaque section passée sur la route 66. Chaque série comporte un liste de timestamps et de points géospatiaux (lattitude, longitude, élévation).
Concernant le troisième bloc :
- il s’agit de calculer la vitesse en m/s entre chaque point de la série (ce qui explique le
1 0 0pour prendre le point précédent, aucun point suivant et appliquer cette opération sur l’ensemble de la liste - voir la tips 3 de 12 tips to apply sliding window algorithms like an expert). Pour cela, on utilisemapper.hspeed(doc) qui consomme une série et calcule la vitesse en m/s en tenant compte de la longitude/lattitude/élévation. - Ce résultat, on le convertit en km/h dans la foulée en utilisant
mapper.mul(doc) en notant au passage qu’il lui faut une constante (on ne peut pas mettre3600 * 1000 /mais3.6) - On a donc une liste de 8 séries temporelles avec chacune un timestamp, les données géospatiales et une vitesse entre chaque point. C’est stocké dans la variable
speedFrames.
Concernant le 4ème bloc :
- Sur le même modèle que pour la vitesse, on calcul la distance entre chaque point des 8 séries via
mapper.hdistque l’on a vu dans le premier billet. Cette fois-ci, plutôt que de calculer la distance totale, on la distance entre le point et le point suivant et on le fait pout tout les points de la liste, d’où le0 1 0 - La distance étant en mètres, on la divisie par 1000 pour avoir des kilomètres. Mais comme il n’y a pas de mapper de division, alors on utilise
mapper.mulet la valeur0.001 - On a donc une liste de 8 séries temporelles avec chacune un timestamp, les données géospatiales et une distance entre chaque point. C’est stocké dans la variable
distanceFrames.
Concernant le 5ème bloc :
- j’ai voulu calculer la consommation d’essence sur la base de la formule:
(8 liters/100km) × (speed (km/h) / 80) +1
- Cela se simplifie en
Speed/10 + 1. - Si on multiplie ce coefficient par les vitesses entre deux points obtenues précédemment (dans
speedFrames), on obtient une consommation pour 100km avec chaque vitesse. Il faudra dans un second temps le pondérer par la distance parcourue entre deux points (distanceFrames) pour avoir un instantané de consommation pour la vitesse et la distance parcourue. - Pour faire cette consommation au 100km non pondérée, on utilise
LMAP(doc)pour appliquer une MACRO à chaque élément de la liste. Cette macro contient le coefficient de consommation d’essence.LMAPretourne normalement l’index et la valeur associée. Or l’index ne nous sert à rien, on met donc l’argument concernant l’index àFalse(abrégéF) pour qu’il ne soit pas retourné. - On stocke le résultat dans
hundredKmFuelConsumptionet on a donc une liste de 8 series avec la consommation pour 100km à la vitesse donnée. Il nous faut maintenant pondérée cette liste par la distance pour avoir un instantané de consommation.
Concernant le 6ème bloc :
- On commence par créer une liste vide appelée
instantConsumption. - On sait que l’on a une liste de 8 éléments, donc on peut faire un boucle
FOR(doc) dessus avec un indice allant de 0 à 7.FORprend comme dernier argument une MACRO que j’ai nomméC - Dans la MACRO définie au dessus, je commence par stocker l’index de la boucle. Mes deux listes de 8 séries temporelles sont identiques en terme de points, avec l’une contenant les consommations pour 100km
hundredKmFuelConsumptionet la seconde les distances entre chaque pointdistFrames. L’idée est donc de multiplier chaque série dehundredKmFuelConsumptionpar la série équivalente dansdistFrameset de diviser par 100 pour finir notre proportionnalité. - On stocke cet consommation instantanée dans la variable
r. - On ajoute ce résultat
rdans la listeinstantConsumption, ce qui permet de reconstituer notre liste de 8 séries mais ayant pour valeur cette fois ci les instantanés de consommation entre chaque point de chaque série.
Un petit interlude visuel avant le dernier bloc :
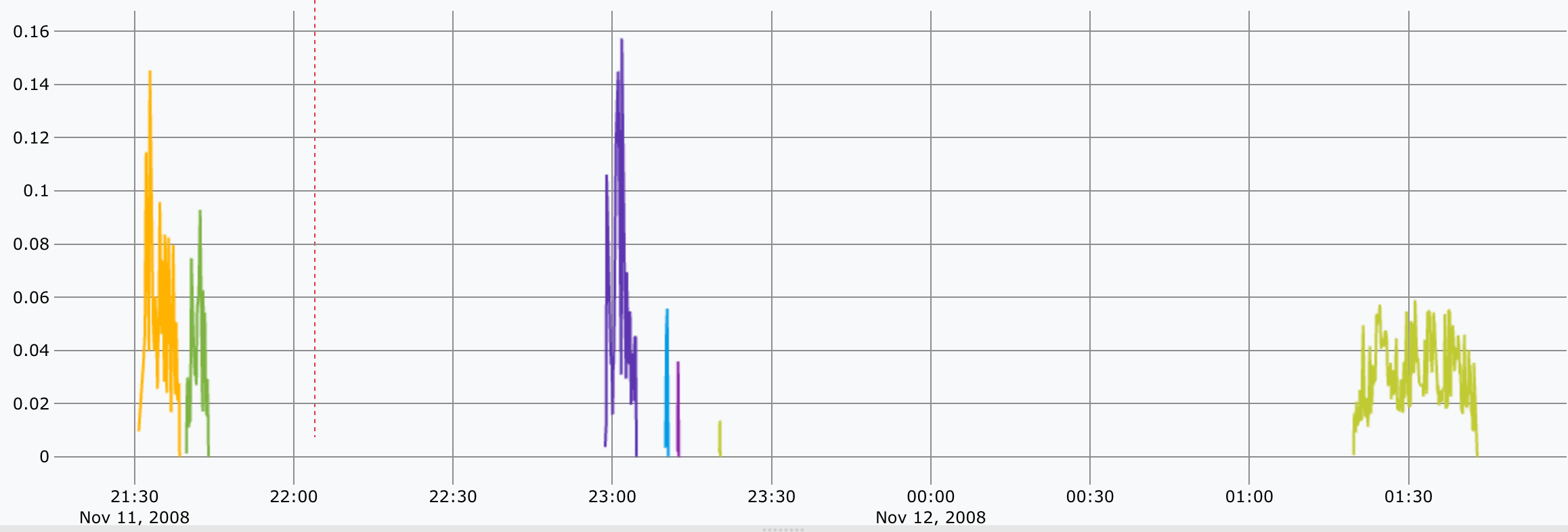
Concernant le 7ème bloc :
- Le but est de faire la somme de chaque instantanné de consommation pour avoir la consommation totale.
- Comme dans la première partie, on utilise cette fois-ci
mapper.sum(doc) en prenant l’ensemble des données des listes capturées viaMAXLONGet on récupère1seule valeur qui s’avère être le total. On a donc la consommation totale de chaque série - Comme vu aussi en fin de première partie, on fait alors la somme de chaque liste pour avoir la consommation totale (
9.823366576601234) - On sait que 1L = 2392g CO2, il nous reste donc à faire cette multiplication.
- On obtient alors :
23497.492851230152ou23,497kg de CO2.
J’espère avoir été clair dans ces explications - si ce n’est pas le cas - dites le moi (via Twitter, Mail, LinkedIn, etc) et je préciserai les choses.
Bilan personnel de ce code contest :
- Opportunité de découvrir une partie des fonctionnalités géospatiales de Warp 10 que je n’avais pas encore utilisé
- Améliorer mon usage autour de
MAP, lesmapper, lesMACROetLMAPet plein de petites choses ici ou là. MAPs’applique sur des GTS mais aussi des listes de GTS sans rien avoir à faire. Pas besoin de se rajouter des boucles supplémentaires !MAXLONGutilisé dans lesMAPpermet de ne pas avoir à se soucier de la taille de l’élément sur laquelle on appliqueMAP. Cela ne fait pas non plus une erreur du styleindex out of range.- en bonus, obtenir quelques lots sympathiques 😎


J’espère néanmoins apprendre des choses du corrigé officiel : Working with GEOSHAPEs: code contest results.
Ma solution pour le Warp 10 Code Contest - partie 1
timeseries warp10 geospatial challengeLa société SenX a proposé un code contest suite à la publication de son article sur les formes géospatiales. L’objet du concours porte sur le trajet d’un véhicule aux USA et il consiste à déterminer :
- la distance réalisée sur la fameuse route 66 durant ce trajet,
- de déterminer les émissions de CO2 réalisées durant ce trajet sur la route 66.
Maintenant que le gagnant a été annoncé (TL;DR: moi 😎🎉) et en attendant le corrigé officiel, voici ma proposition de solution.
Distance parcourue sur la route 66
Les données de départ sont :
@senx/dataset/route66_vehicle_gts: le trajet réalisé par le véhicule@senx/dataset/route66_geoshape: la route 66
// Define points from the car journey on the US66 road
[
// Here is the gts of the car datalogger
@senx/dataset/route66_vehicle_gts
// Here is the route 66 geoshape (+/- 20meters)
@senx/dataset/route66_geoshape
mapper.geo.within 0 0 0
] MAP
"onTheRoad" STORE
$onTheRoad
{
'timesplit' 60 s
}
MOTIONSPLIT
0 GET
'sectionOnTheRoad' STORE
// Compute distance for each GTS and output it as a single point
[ $sectionOnTheRoad mapper.hdist MAXLONG MAXLONG 1 ] MAP
// Sum all GTS
0 SWAP <% VALUES 0 GET + %> FOREACH
// Convert to km
1000 /
// Enjoy !
Explications :
- Le premier bloc utilise le mapper
mapper.geo.within(doc). Ce mapper compare deux zones géographiques et ne retient que les poits qui sont dans la zone voulue. Ici, je prends donc tous les points du trajet et les compare avec ceux de la route 66. Seuls les points sur la route 66 sont conservés. Le résultat est une aggrégation de points que l’on stocke dans la variableonTheRoad. - Pour le second bloc : dans le studio, lorsque l’on regarde la liste des points obtenus dans l’onglet “Tabular view”, on peut voir que les points sont espacés en général de minimum 10 secondes et jusqu’à une minute environ. Après avoir relu le billet “Use motion to automatically split GTS”, j’ai retenu ce seuil d’une minute et la fonction
MOTIONSPLIT(doc) pour calculer la distance entre deux points. Obtenant une liste de 1 élément contenant une liste, j’ai rajouté le0 GETpour supprimer la liste parente. On obtient alors une liste de 8 séries temporelles (GTS) correspondant à chaque tronçon sur la route. On stocke cela dans la variablesectionOnTheRoad.
- Pour le dernier bloc - partie 1 :
mapper.hdist(doc) permet de calculer la distance totale sur une fenêtre glissante de points. L’utilisation deMAXLONGpermet d’avoir une valeur suffisamment grande pour notre cas d’espèce pour prendre l’ensemble des données de chacune des 8 listes - il n’est pas nécessaire de connaitre la taille exacte de la liste pour travailler dessus et cela ne crée pas d’erreur non plus ; ça peut déstabiliser !. Le1permet de n’avoir qu’une valeur en sortie. On a donc en sortie la distance de chacune des 8 sections.
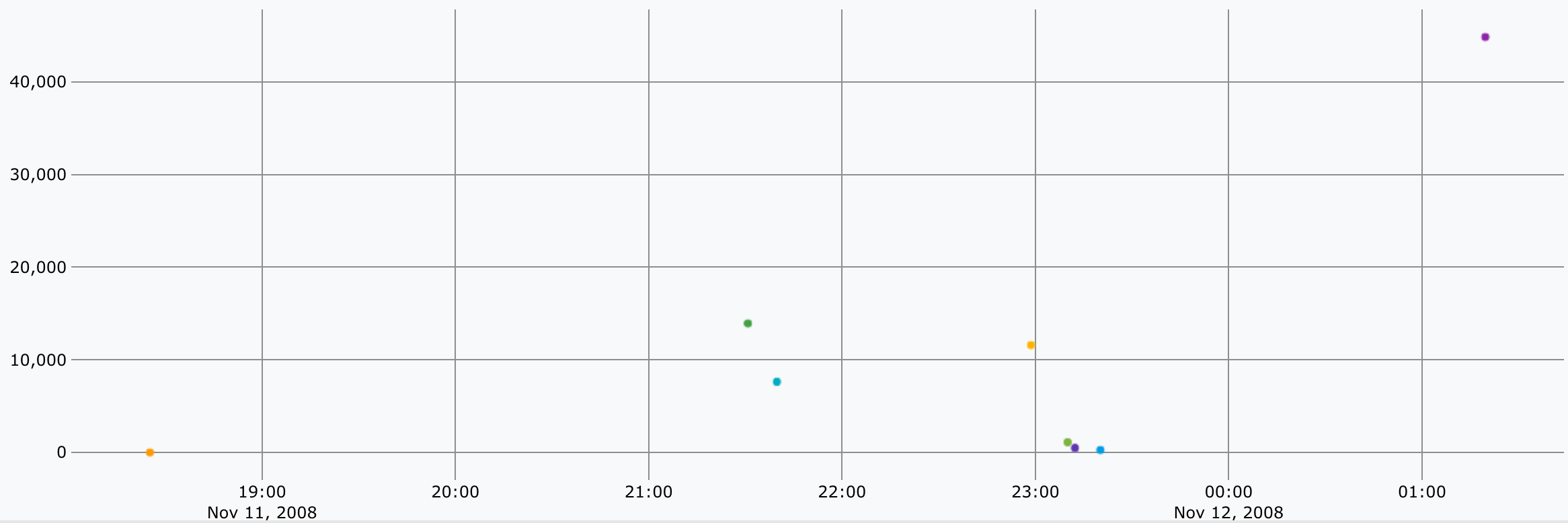
- Pour le dernier bloc - partie 2 : là, j’avoue la syntaxe est un peu cryptique 🤯. L’idée est donc de faire la somme de toutes les distances totales obtenues précédemment. Il faut donc faire
0(pour initialiser l’opération d’addition) et ajouter la première valeur de la liste et ainsi de suite. Une fois qu’on a la somme, on divise par 1000 pour avoir des kilomètres - La réponse est alors:
79.82147744769853
Pour comprendre la partie 2, on peut réécrire la chose de la façon suivante :
[ $sectionOnTheRoad mapper.hdist MAXLONG MAXLONG 1 ] MAP
'totalDistancePerSection' STORE
0 $totalDistancePerSection <% VALUES 0 GET + %> FOREACH
Non, toujours pas ? Vous me rassurez, j’ai du creuser plus loin aussi.
Commençons par :
$totalDistancePerSection <% VALUES 0 GET %> FOREACH
VALUES (doc) consomme une série temporelle et en sort les valeurs sous la forme d’une liste. Nous avons une liste initiale de 8 séries que nous avons ramené à 8 points. Avec FOREACH (doc), on applique donc la fonction VALUES sur chaque série contenant un seul point. Plutôt que d’avoir en sortie des listes à un seul point, le 0 GET permet d’avoir directement la valeur.
Pour faire une addition, en WarpScript, c’est :
1 1 +
ou :
1
1
+
Par celà, j’entends que pour appliquer +, il faut que les deux éléments soient définis dans la pile.
Notre boucle FOREACH emet dans la pile chaque valeur qu’il faut ajouter à la précédente. On peut donc rajouter le + dans la boucle FOREACH :
$totalDistancePerSection <% VALUES 0 GET + %> FOREACH
Mais si je cherche à exécuter cela, cela ne fonctionne pas - cela reviendrait à faire:
valeur1IssueDuForeach +
valeur2IssueDuForeach +
valeur3IssueDuForeach +
valeur4IssueDuForeach +
...
Si on part de la fin, la valeur 4 va pouvoir être additionnée à la valeur 3 car celle-ci existe dans la pile. MAIS la valeur 1 n’est additionnée à rien à ce stade et l’opération est invalide. D’où la nécessité de rajouter le 0 pour pouvoir avoir deux éléments pour notre première addition.
Ce qui nous donne bien :
0 $totalDistancePerSection <% VALUES 0 GET + %> FOREACH
Maintenant que la brume s’est éclaircie et que le 🤯 est passé à 😎 pour cette syntaxe de fin, je vous propose de nous retrouver dans un prochain billet pour la suite de ma solution au concours.
Web, Ops, Data et Time Series - Avril 2021
falco sysdig sécurité dashboard raspberrypi pico hashicorp vault vector containerd git git-filter-repo psp gitlab-ci podman warp10 sqlite terraform timescale velero docker docker compose grafana loki tempo kubernetes minio influxdata notebook geospatial agpl bme680 co2Code
- Docteur, j’ai commité 8 Go dans mon Git. C’est grave ? : un petit exemple de l’utilisation de git-filter-repo pour nettoyer son historique git de fichiers inutiles.
- Les pipelines parent-enfant de gitlab-ci : article sur la modularisation de gitlab-ci avec les pipelines parent/enfant au sein d’un même dépôt de code ou entre plusieurs dépot avec passage de variables entre eux.
- Minio Changes License to AGPL : Minio passe (aussi) son code en AGPL, l’annonce officielle n’est pas encore arrivée.
Conteneur et orchestration
- Electro Monkeys - Docker Compose avec Nicolas de Loof : Retour sur la Developper Experience autour de Docker, l’historique et le futur de docker-compose, la création de la spécification Compose, les intégrations AWS/ECS et Azure/ACI, l’intégration Kubernetes, etc.
- nerdctl: Docker-compatible CLI for contaiNERD : une CLI qui imite la CLI Docker mais en interagissant directement avec containerd. Elle permet aussi de bénéficier de certaines fonctionnalités de containerd qui ne sont pas prévues pour tout de suite dans Docker apparemment.
- Blog: Kubernetes 1.21: Power to the Community : au programme de cette nouvelle version : Cronjobs GA, Immutable Secrets and ConfigMaps GA, IPv4/IPv6 dual-stack support, Graceful Node Shutdown, PersistentVolume Health Monitor mais aussi PodSecurityPolicy Deprecation et TopologyKeys Deprecation
- PodSecurityPolicy Deprecation: Past, Present, and Future: article plus détaillé sur la dépréciation des PSP.
- Podman v3.1.0 Released : ajout de la gestion des secrets, améliorations des commandes kube avec notamment la génération des PersistentVolumeClaim ou encore la gestion des propriétaires des volumes.
- Velero 1.6.0 : améliorations diverses comme le support des identifiants par buckets (et non globaux uniquement), mise à jour de restic vers 0.12.0, etc.
- Compose CLI Tech Preview :
composedevrait devenir une sous-commande officiel de la CLI Docker ; on pourra alors fairedocker compose up -d - Docker 20.10.6 : version de maintenance avec le support des puces Apple Silicon M1.
- Kubernetes : vers 3 releases par an au lieu de 4 : de quoi courrir un peu moins derrière les versions et à relier avec le support de chaque version étendue à 1 an depuis la 1.19.
Data
- sq: swiss-army knife for data : le
jqpour les données relationelles. Du SQL ou des fichiers Excel/CSV/JOSN/XML en entrée et les mêmes formats en sortie (et un peu plus). - SQLite is not a toy database : On a souvent une fausse image de sqlite - l’article permet de se mettre à jour…
IaC
- Conditional nested blocks in Terraform : si les dynamic blocks avec terraform sont utiles pour peupler dynamiquement des structures à partir de tableaux/listes/objets, il peut aussi être utiliser pour gérer la présence conditionnelle de blocs.
- Announcing HashiCorp Terraform 0.15 General Availability : la plus grosse annonce étant que la 0.15 initie les travaux en vue de la release 1.0 ; pour ceux qui sont à jour, la mise à jour ne devait pas poser de problèmes (cf guide). Pour plus d’informations, cf CHANGELOG.
- HashiCorp is the latest victim of Codecov supply-chain attack : victime de la supply chain attach de codecov, Hashicorp vient de publier les versions patchées de Terraform des versions 0.11 à 0.15. Faites la mise à jour rapidement même si la clé volée n’a a priori pas été utilisée frauduleusement.
IoT
- Pico 2 Pi Adapter Board : un petit adapteur sympathique pour Raspeberry Pi Pico et vous permettre de brancher facilement vos composants sans soudure et mener ainsi vos expériences.
- Piper Make : Pour programmer facilement votre Raspberry Pi Pico en MicroPython mais avec une logique de blocs à la Scratch.
- Utilisation des BME680 et RV3028 avec Raspberry Pi Pico : le composant BME680 permet d’évaluer la qualité de l’air - le projet permet donc de capturer et d’afficher cette information avec un Raspberry Pi. Son successeur, le BME688 dispose d’une pincée d’IA.
- Projet CO2 et Makers CO2 : pour mieux comprendre les enjeux autour de l’aération des pièces et comment faire vos capteurs.
Observabilité & Monitoring
- Coder ses dashboards Grafana avec Grafonnet : Grafonnet est une extension de jsonnet ; il permet de déclarer ses dashboards Grafana via un lanage formalisé plutôt que de copier/coller des dashboards en JSON. Cela permet ainsi d’avoir une approche un peu plus “Dashboard as code”.
- Grafana 7.5 released: Loki alerting and label browser for logs, next-generation pie chart, and more! : un nouveau panel pour les “camembers” (“pie charts”), des améliorations pour les autres produits grafana (loki, tempo), ainsi qu’Elasticsearch, Postgresql et Cloudwatch et sur la version Entreprise.
- Vector v0.12.0 Release Notes, 0.12.1, 0.12.2 : Comme indiqué en février, la release de Vector apportant leur nouveau langage de traitement “Vector Remap Language est disponible, ainsi que des améliorations sur
vector top, la sourceinternal_logset l’API GraphQL. Un guide de mise à jour vers la nouvelle syntaxe est disponible. - Release Announcement: Telegraf 1.18.1 : version de maintenance
- Grafana, Loki, and Tempo will be relicensed to AGPLv3 & Q&A with Grafana Labs CEO Raj Dutt about our licensing changes : les produits phares de Grafana Labs passent d’une licence Apache 2 à AGPLv3. Les autres produits pourront rester sous licence ASL 2.0. L’AGPL étant contaminante, cela pourrait interdire l’usage de ces produits dans certains contextes, y compris à la CNCF. Vu l’implication de Grafana Labs dans le monde Prometheus, il va falloir suivre comment cela va se passer.
Réseau
- The Mystery of AS8003 : Une entité inconnue jusque là mais liée à l’administration américaine a annoncé la gestion d’une très grande plage réseau. Les implications et les motivations sont encore à éclaircir. Le billet émet différents hypothèses. Le thread twitter associé est intéressant aussi.
Sécurité
- Electro Monkeys - La sécurité dans tous ses états – détection de comportements indésirables grâce à Falco avec Thomas Labarussias : Présentation des projets falco et sysdig qui permettent d’analyser les comportements de vos applications (conteneurisées ou pas) en se basant sur les syscalls.
- Announcing HashiCorp Vault 1.7 : version mineure avec des améliorations internes au produit, sur la version entreprise et un peu au niveau UI.
Time Series
- InfluxDays EMEA 2021 Virtual Experience : InfluxData organise la session européenne de sa conférence avec le point sur les différents produits et les développements à venir. Des nouvelles de l’écosystème (Grafana, etc) sont attendues aussi, ainsi que des retours clients. Des formations Flux et Telegraf sont aussi prévues respectivement les 10/11 mai et le 17 Mai.
- InfluxData releases InfluxDB Notebooks to enhance collaboration for teams working with time series data & Build notebooks in InfluxDB Cloud | InfluxDB Cloud Documentation : InfluxData lance son offre de notebook intégré à sa plareforme InfluxDB (version cloud uniquement pour le moment)
- Build a Complete Application with Warp 10, from TCP Stream to Dashboard : exemple complet de l’utilisation de la plateforme Warp 10 depuis l’ingestion des messages AIS des bateaux via un client TCP jusqu’à la visualisation des données après un passage par les étapes de stockage et nettoyage des données. Très intéressant même si je vais devoir relire tranquillement le billet pour bien comprendre certaines astuces et certains “raccourcis” au niveau du code.
- Working with GEOSHAPEs & Working with GEOSHAPEs: code contest! : un billet (et un concours) pour exploiter la dimension géospatiale de Warp 10.
- TimescaleDB 2.2.0 : diverses améliorations mais surtout une annonce sur la fin de support de Postgresql 11 à compter de mi-juin et de la prochaine version de TimescaleDB. C’est justifié par l’absence d’une fonctionnalité dans Postgresql 11.x et requise pour la prochaine version de TimescaleDB.
