Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
InfluxDB et les alertes : Tasks, Checks et Notifications
influxdb timeseries influxdata task flux check notifications kapacitor alertesCérénIT vient de finaliser la migration pour un de ses clients d’un socle InfluxDB/Chronograf/Kapacitor vers InfluxDB2. Ce billet est l’occasion de revenir sur la partie alerting et de la migration de Kapacitor vers des alertes dans InfluxDB2.
Dans le cadre du socle InfluxDB/Chronograf/Kapacitor, le fonctionnement était le suivant :
- Les utilisateurs créent une alerte via l’application métier en définissant un à plusieurs critères d’alertes ; ex: est-ce que l’unité est opérationnelle et est-ce que l’humidité est supérieure à tel taux ou la température supérieure à telle valeur.
- L’application métier traduisait l’alerte en TickScript et enregistrait l’alerte auprès de Kapacitor via son API HTTP
- Kapacitor, en mode streaming, évalue si l’alerte doit être levée ou pas au fur et à mesure de l’arrivée des données
- En cas de seuil franchi, Kapacitor envoie un message à l’application métier via l’API HTTP de cette dernière.
- L’application métier envoie ensuite un mail et/ou un SMS à l’auteur de l’alerte.
Avant d’envisager la migration InfluxDB2, un point de vocabulaire :
- une alerte est globalement composée d’un “check”, d’un endpoint de notiifcation et d’une règle de notification.
- un check est une task simplifiée. Elle permet de définir une requête mono critère, les niveaux de seuils associés (ok, crit, warn, etc) et sa fréquence d’exécution.
- une task est codée flux
- un endpoint de notification : service vers lequel sera envoyé l’alerte: slack, http, etc.
- une règle de notification : les conditions de notifications (ex je passe à un état critique), le check associé, la fréquence d’exécution, le message de notification et le endpoint de notification à utiliser.
Avec la migration InfluxDB2, nous avons voulu maintenir le même mécanisme. Toutefois :
- Les tasks en Flux ne fonctionnent pas en mode streaming, mais uniquement en mode batch et avec une certaine fréquence
- Les checks sont mono-critères et pas multi-critères
Heureusement, la documentation mentionne la possibilité de faire des “custom checks” et un billet très détaillé intitulé “InfluxDB’s Checks and Notifications System” permet de mieux comprendre ce qu’il est possible de faire et donne quelques exemples de code.
Dès lors, il s’agit de :
- développer une tâche “tout en un”, contenant l’ensemble de la logique de l’alerte,
- de conserver un historique des alertes pour permettre d’assurer un suivi des alertes pour l’équipe en charge du projet depuis InfluxDB
- d’être en mesure de notifier l’application métier via son API HTTP
Pour se faire, nous allons nous appuyer sur les mécanismes mis à disposition par Influxdata, à savoir les fonctions monitor.check(), monitor.from() et monitor.notify() et les mécanismes induits.
C’est ce que nous allons voir maintenant :
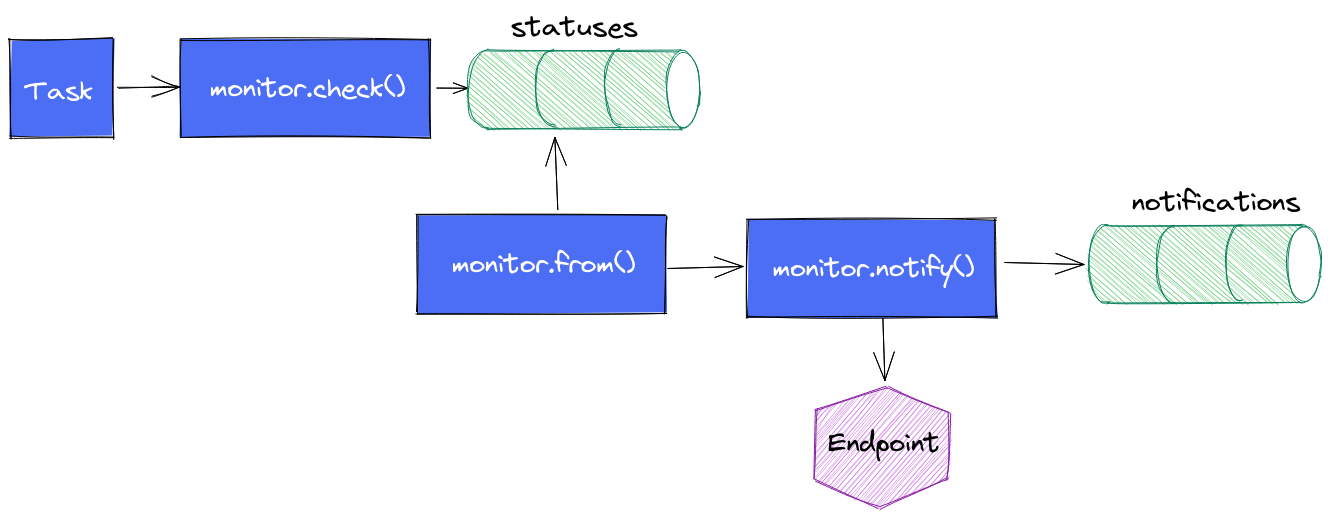
Le cycle de vie d’une alerte est le suivant :
- La task contient une requête en flux plus ou moins complexe en fonction de votre besoin ; ex: quelle est la valeur de la temperature du boitier X depuis la dernière exécution ?
- On appelle
monitor.check()en définissant les informations d’identification du check, le type de check que l’on utilise (threshold, deadman, custom), les différents seuils dont on a besoin, le message à envoyer au endpoint, les données issues de la requête flux. monitor.check()va alors stocker l’ensemble de ces données dans un measurementstatusesdans le bucket_monitoringet il s’arrête là.monitor.from()prend le relais, regarde s’il y a de nouveaux status depuis sa dernière exécution et en fonction des règles de notifications qui ont été définies, il va passer le relaismonitor.notify().monitor.notify()enverra une notification si la règle est validée et il insérera une entrée dans le measurementnotificationsdu bucket_monitoring
Une première version des alertes ont été implémentées sur cette logique. Des dashboards ont été réalisés pour suivre les status et les notifications. Cela fonctionne, pas de soucis ou presque.
Il se peut qu’il y ait un délai entre le moment où l’insertion issue du monitor.check() se fait et le moment où le monitor.from() s’exécute. Si monitor.from() fait sa requête avant l’insertion de données, alors l’alerte ne sera pas immédiatement levée. Elle sera levée à la prochaine exécution de la task, ce qui peut être problématique dans certains cas. Pour une tâche qui s’exécute toutes les minutes, cela ne se voit pas ou presque. Pour une tâche toutes les 5 minutes, ça commence à se voir.
Une version intermédiare de la task est alors née : une fois le monitor.check() exécuté, nous faisons appel à monitor.notify() pour envoyer le message vers le endpoint.
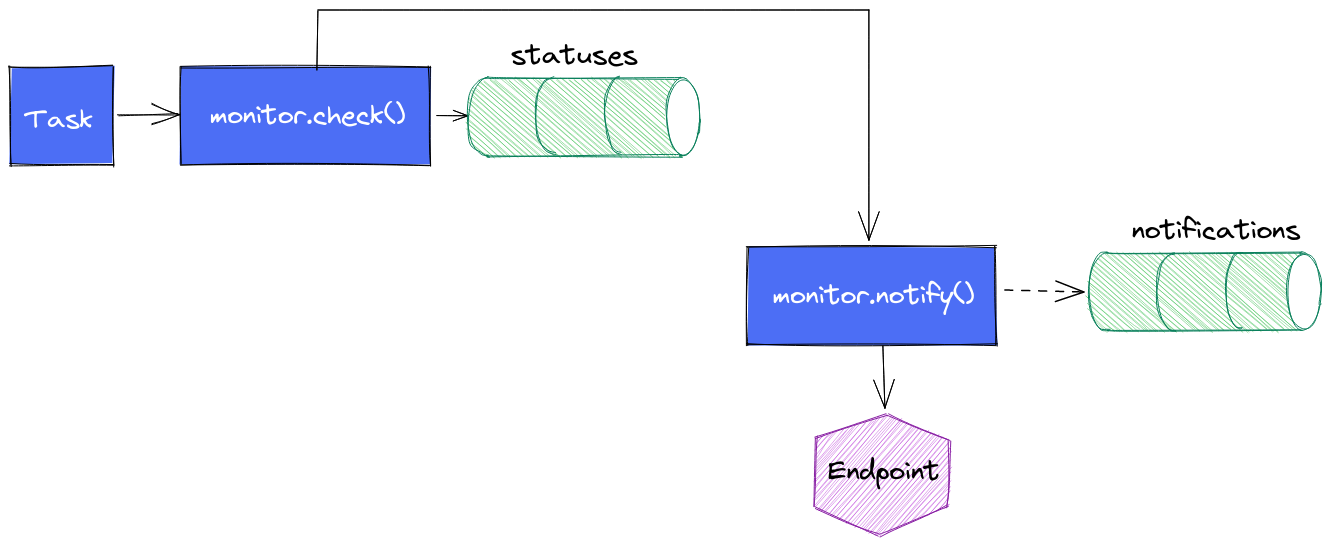
Avantage :
- la notification se déclenche sans délais
Inconvénients :
- cela ne remplit pas le measurement
notificationsde la même façon que précédemment (d’où les pointillés) vu que les données insérées dans le measurementstatusesn’existent pas encore. On perd la visibilité sur les notifications envoyées (mais on a toujours le suivi des statuts ; nous supposons que si on a le statut, alors on sait si la notification a été envoyée) - cela aboutit à un peu de duplication de code sur la gestion des seuils et des messages.
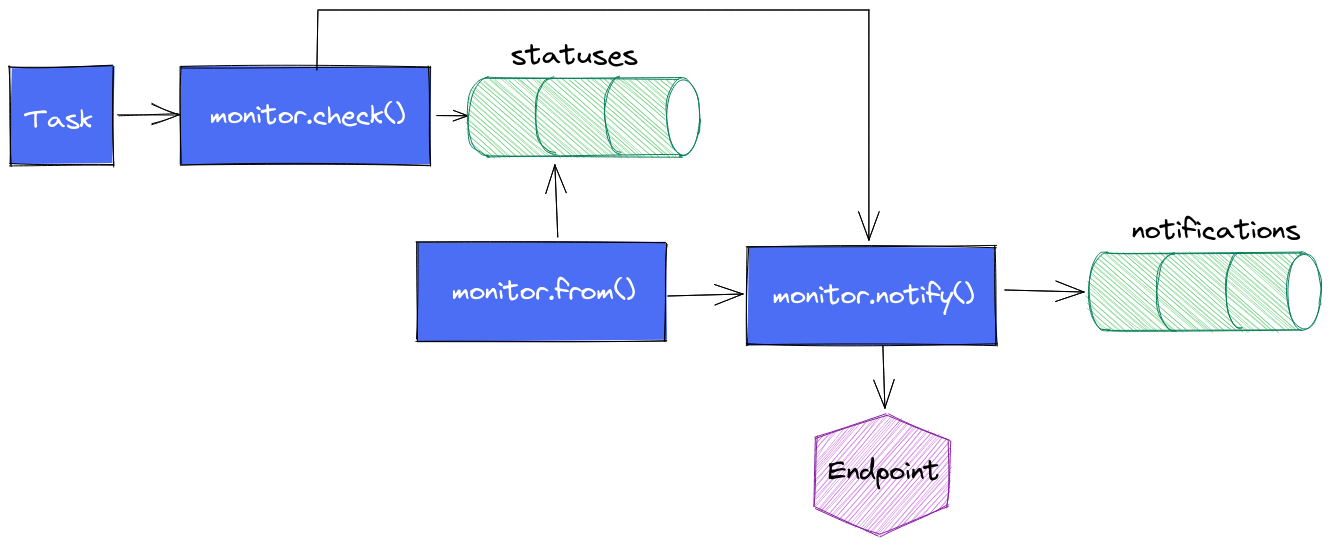
Une variante non essayée à ce stade : elle consiste à faire cette notification au plus tôt mais de conserver le mécanisme de monitor.from() + monitor.notify() pour avoir le measurement notifications correctement mise à jour. A voir si les alertes ne sont pas perturbées par ce double appel à monitor.notify(). Dans le cas présent, c’est l’application métier qui envoie les alertes après que la task InfluxDB ait appelé son API HTTP. Si chaque monitor.notify() en vient à lever une alerte, cela est sans impact pour l’utilisateur. En effet, une fois qu’une alerte est levée, elle est considérée comme levée tant qu’elle n’est pas acquittée. Donc même si la task provoque 2 appels, seul le premier lévera l’alerte et la seconde ne fera rien de plus.
Enfin dernière variante (testée) : s’affranchir complètement de monitor.notify() pour faire directement appel à http.endpoint() et http.post() et faire complètement l’impasse sur le suivi dans notifications.
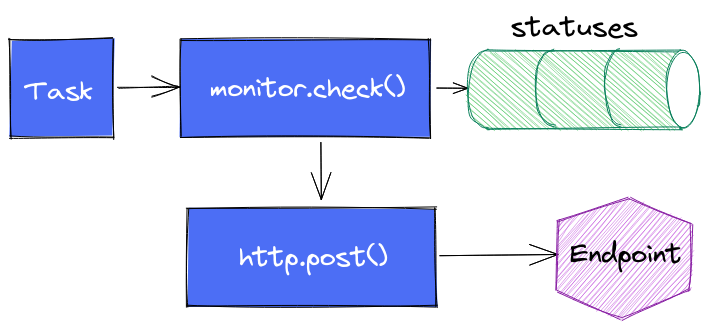
Tout est une histoire de compromis.
En conclusion, nous pouvons retenir que :
- Une alerte est composée d’un check, d’un endpoint de notification et d’une règle de notification
- En 2.0, le principe est que les alertes sont des séries temporelles via le bucket
_monitoringet les measurementsstatusesetnotifications. - Toute personne s’intéressant au sujet doit lire au préalable InfluxDB’s Checks and Notifications System pour bien comprendre les concepts et les rouages.
- Via la UI, les alertes (checks) sont assez basiques (requête monocritère)
- Il est possible de faire des “custom checks” via des tasks en flux
- Les fonctions du package monitor permettent de gérer des alertes
- Les exécutions dans la même task (ou dans des tasks concomittentes) de
monitor.check()etmonitor.from()peuvent conduire à des décalages de levées d’alertes
SAFT
timeseries influxdb flux alerting dashboardContexte
Dans le cadre du maintien en condition opérartionnelle de sa plateforme et pour faire des analyses plus poussées de ses données, la SAFT souhaite mettre à jour sa stack InfluxDB 1.x OSS, Chronograf et Kapacitor vers InfluxDB 2.0 OSS. Fort des précédentes missions, la SAFT nous a confié cette mission, à laquelle s’ajoute une période de support post déploiement en production de la nouvelle plateforme.
Notre réponse
- Montée de version InfluxDB OSS 1.x vers 2.x
- Migration des dashboards Chronograf vers InfluxDB2
- Migration des alertes en TickScript vers des “custom checks” (tasks flux)
- Restructuration des données avec une shard duration conforme aux recommandations InfluxData
- Mise à jour de Telegraf et de sa configuration
- Mise à jour de la partie exploitation (backups, etc)
- Documentation
- Support post déploiement en production
Bénéfices pour le client
- Expertise sur InfluxDB
- Connaissance prélable du contexte suite aux précécentes missions
InfluxDB 2.0 OSS - Notes de mise à jour
timeseries influxdb flux grafana telegrafInfluxDB 0SS 2.0 étant sortie, j’ai testé la mise à jour d’une instance 1.8.3 vers 2.0.1 sur une VM Debian 10 à jour.
Mise à jour
La documentation pour une mise à jour 1.x vers 2.x est disponible. La vidéo “Path to InfluxDB 2.0: Seamlessly Migrate 1.x Data” reprend cela et va plus loin en présentant bien tous les points à prendre en compte (y compris pour Telegraf, Chronograf et Kapacitor). Je ne rajouterai donc que mes remarques.
Concernant la commande influxd upgrade :
- Il est fort probable qu’il faille rajouter la commande
sudopour ne pas avoir de problèmes de permisisons. - Par défaut, les données migrées vont être mises dans
~/.influxdbV2. Or je doute que vous vouliez que vos données soient à cet endroit. Je vous invite donc à regarder la documentation deinfluxd upgradepour définir les propriétés--engine-pathet--bolt-path
Exemple:
mkdir -p /srv/influxdb/influxdb2
influxd upgrade --engine-path /srv/influxdb/influxdb2/engine --bolt-path /srv/influxdb/influxdb2/influxd.bolt
- A l’issue de la migration, un fichier
config.tomlest généré dans/etc/influxdb/. Il contient quelques valeurs issues de la migration et des valeurs par défaut. Je l’ai personnalisé de la façon suivante pour tenir compte de mes valeurs :
bolt-path = "/srv/influx/influxdb2/influxd.bolt"
engine-path = "/srv/influx/influxdb2/engine"
http-bind-address = "127.0.0.1:8086"
storage-series-id-set-cache-size = 100
- Post-migration, le service
influxdcherchait à initialiser ses fichiers dans/var/lib/influxdb/.influxdbv2. Ayant noté que le service InfluxDB prennait/etc/default/influxdbcomme fichier d’environnement, j’ai ajouté dans ce fichier :
# /etc/default/influxdb
INFLUXD_CONFIG_PATH=/etc/influxdb/config.toml
Dès lors, /etc/influxdb/config.toml était bien pris en compte et InfluxDB démarrait bien avec mes données.
Une fois InfluxDB 2 démarré, j’ai pu noter avec plaisir :
- que l’ingestion via telegraf continuait à se faire sans interruption,
- que mes dashboards Grafana continuaient à fonctionner.
Je n’ai donc pas d’urgence à migrer la configuration et le paramétrage de ces derniers. Je vais pouvoir le faire progressivement ces prochains jours.
N’utilisant pas Chronograf et Kapacitor, je n’ai pas eu de données à migrer ou d’ajustements à faire à ce niveau là. La vidéo reprend bien les points d’attention et les éventuelles limitations à prendre en compte dans le cadre de la migration.
Finalement, c’est pas mal qu’ils aient réintégrer les endpoints 1.x dans la version 2.0 à ce niveau là ;-)
La 2.0.2 étant sortie pendant ma mise à jour, j’ai poursuivi la mise à jour. Je suis tombé sur ce bug rendant l’écriture de données impossibles. Cela a mis en évidence un bug sur la migration des “retention policies” et sur le fait que j’avais aussi des très vieilles bases InfluxDB. Je n’aurai a priori pas eu ce bug en faisant la migration 1.8.3 vers 2.0.2. En tous cas, une 2.0.3 devrait donc arriver prochainement avec une amélioration du processus de migration faisant suite à ma séance de troubleshooting.
Migration des configurations
Elle peut se faire très progressivement - si par ex vous utilisez telegraf pour envoyer vos données et Grafana pour la partie dashboarding :
- Vous pouvez mettre à jour votre configuration telegraf en passant de l’outputs
influxdbà l’outputinfluxdb_v2sans impacter grafana qui continuera à accéder à vos données en InfluxQL - Vous pouvez ensuite mettre à jour votre datasource InfluxDB ou plutôt en créer une nouvelle et migrer vos dashboards progressivement sans interruption de service
Créer un accès en InfluxQL à un nouveau bucket
Si vous devez rétablir un accès à vos données via les API 1.x à un bucket nouvellement créé (j’ai profité de la migration pour mettre des buckets clients dans des organisations représentant les clients en question).
# Créer le bucket
influx bucket create --name <BUCKET_NAME> --retention 0 --org <ORGANISATION>
# Récupérer l'ID de bucket via la liste des buckets
influx bucket list
# Créer une DBRP (DataBase Retention Policies) pour le bucket en question - les accès en 1.x se font en mode SELECT * FROM <db_name>.<retention_policies> ...
influx v1 dbrp create --bucket-id=<BUCKET_ID> --db=<BUCKET_NAME> --rp=autogen --default=true
# Créer un utilsateur sans mot de passe pour le moment
influx v1 auth create --username <USER> --read-bucket <BUCKET_ID> --write-bucket <BUCKET_ID> --org <ORGANISATION> --no-password
# Créer un mot de passe au format V1
influx v1 auth set-password --username <USER>
Les utilisateurs migrés depuis la version 1.x sont visibles via influx v1 auth list.
Intégration InfluxDB 2.0 / Flux et Grafana
Le support de Flux dans Grafan existe depuis la version 7.1 mais il n’est pas aussi aisé que celui dans InfluxDB 2.0 OSS. Il y a certes de la complétion au niveau du code ou le support des variables mais pas de capacité d’introspection sur la partie données.
Pour le moment, je procède donc de la façon suivante :
- Création de la Requête via le Query Builder dans InfluxDB 0SS
- Passage en mode “Script editor” pour dynamiser les variables ou ajuster certains comportements
- Copier/coller dans l’éditeur de Grafana
- Ajustement des variables pour les mettre au format attendu par Grafana.
Ex coté InfluxDB 2.0 OSS / Flux :
from(bucket: v.bucket)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "net")
|> filter(fn: (r) => r["_field"] == "bytes_recv" or r["_field"] == "bytes_sent")
|> filter(fn: (r) => r["host"] == v.host)
|> derivative(unit: v.windowPeriod, nonNegative: false)
|> yield(name: "derivative")
La version dans Grafana :
from(bucket: "${bucket}")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "net")
|> filter(fn: (r) => r["_field"] == "bytes_recv" or r["_field"] == "bytes_sent")
|> filter(fn: (r) => r["host"] == "${host}")
|> derivative(unit: v.windowPeriod, nonNegative: false)
|> yield(name: "derivative")
La différence portant sur la gestion des variables v.host vs "${host}" et v.bucket vs "${bucket}".
Autre bonne nouvelle, les variables sont supportées dans Grafana ; vous pouvez donc définir les variables comme celles vu juste au-dessus :
Variable bucket de type “Query” en prenant InfluxDB/Flux comme datasource :
buckets()
|> filter(fn: (r) => r.name !~ /^_/)
|> rename(columns: {name: "_value"})
|> keep(columns: ["_value"])
Variable host de type “Query” en prenant InfluxDB/Flux comme datasource :
# Provide list of hosts
import "influxdata/influxdb/schema"
schema.tagValues(bucket: v.bucket, tag: "host")
Si votre requête fonctionne dans un dashboard InfluxDB ou en mode explore mais qu’elle est tronquée dans Grafana, il vous faudra ajuster le “Max Data Points” pour récupérer plus de points pour cette requête (cf grafana/grafana#26484).
Calcul de la durée d'un état avec des timeseries
timeseries influxdb flux warp10 warpscript durationUn client m’a demandé la chose suivante : “Nicolas, je voudrais savoir la durée pendant laquelle mes équipements sont au delà d’un certain seuil ; je n’arrive pas à le faire simplement”.
Souvent, quand on manipule des séries temporelles, la requête est de la forme “Sur la période X, donne moi les valeurs de tel indicateur”. On a moins l’habitude de travailler dans le sens inverse, à savoir : “Donne moi les périodes de temps pour laquelle la valeur est comprise entre X et Y”.
C’est ce que nous allons chercher à trouver.
Influx 1.8 et InfluxQL
Avec l’arrivée imminente d’Influx 2.0, j’avoue ne pas avoir cherché la solution mais je ne pense pas que cela soit faisable purement en InfluxQL.
Influx 1.8 / 2.0 et Flux
Avec Flux, j’ai rapidement trouvé des fonctions comme duration et surtout stateDuration
L’exemple ci-dessous se fait avec une base InfluxDB 1.8.3 pour laquelle Flux a été activé. Le requêtage se fait depuis une instance Chronograf en version 1.8.5.
Pour approcher l’exemple de mon client, j’ai considéré le pourcentage d’inactivité des CPU d’un serveur que l’on obtient de la façon suivante:
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
Cela donne:

Ensuite, j’ai besoin d’une fonction qui va me rajouter une colonne avec mon état. Cet état est calculé en fonction de seuils - par souci de lisibilité, je vais extraire cette fonction de la façon suivante et appliquer la fonction à ma requête :
set_level = (tables=<-) =>
tables
|> map(fn: (r) => ({
r with
level:
if r._value >= 95 then "fully_idle"
else if r._value >= 90 and r._value <95 then "something_is_moving"
else if r._value >= 85 and r._value <90 then "oh_oh"
else if r._value >= 80 and r._value <85 then "hmm"
else if r._value < 80 then "i_have_to_work"
else "overloaded"
})
)
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
|> set_level()
La colonne “level” n’est à ce stade pas persistée en base contrairement aux autres données issue de la base de données.
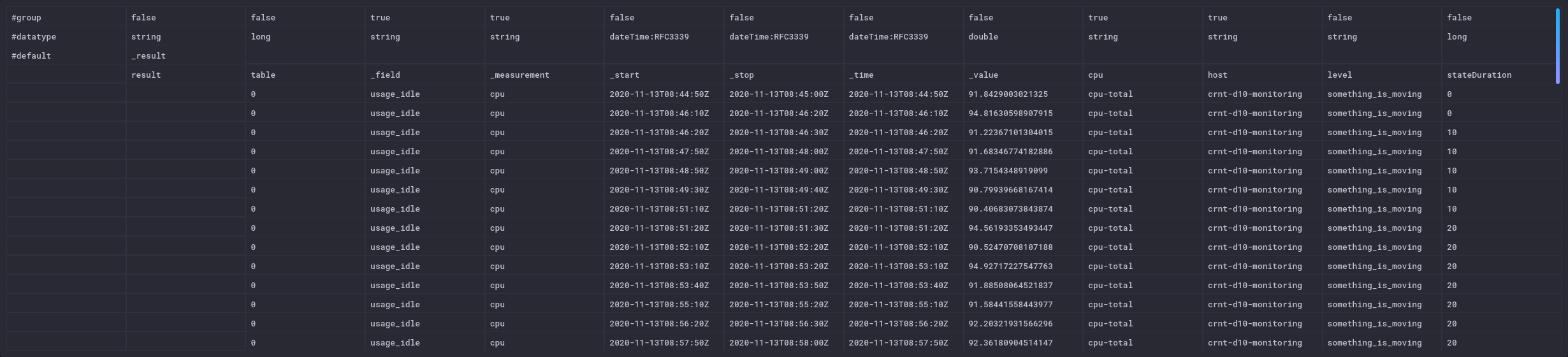
Cela donne ceci en mode “raw data” - tout à fait à droite

Maintenant que j’ai mon état, je peux application la fonction stateDuration() ; elle va calculer la périodes de temps où le seuil est “something_is_moving” par tranche de 1 seconde. Le résulat sera stocké dans une colonne “stateDuration”. Pour les autres états, la valeur est de -1. La valeur se remet à 0 à chaque fois que l’état est atteint puis la durée est comptée :
set_level = (tables=<-) =>
tables
|> map(fn: (r) => ({
r with
level:
if r._value >= 95 then "fully_idle"
else if r._value >= 90 and r._value <95 then "something_is_moving"
else if r._value >= 85 and r._value <90 then "oh_oh"
else if r._value >= 80 and r._value <85 then "hmm"
else if r._value < 80 then "i_have_to_work"
else "overloaded"
})
)
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
|> set_level()
|> stateDuration(fn: (r) => r.level == "something_is_moving", column: "stateDuration", unit: 1s)
On voit le rajout de la colonne stateDuration en mode “raw data” ; elle n’ont plus n’est pas persistée dans la base à ce stade :

et coté visualisation :

Maintenant que j’ai ces périodes, je vais vouloir savoir quelle est la durée totale de ces différentes périodes que nous avons identifée. On peut en effet imaginer un cas où on sait que l’équipement est à remplacer lorsqu’il a atteint un seuil donné pendant plus de X heures.
Pour cela, je vais:
- filtrer sur un état voulu,
- calculer le différentiel entre chaque valeur de stateDuration pour n’avoir que les écarts non plus la somme des durées en supprimant les valeurs négatives pour gérer les retours à la valeur 0
- et faire la somme de l’ensemble.
set_level = (tables=<-) =>
tables
|> map(fn: (r) => ({
r with
level:
if r._value >= 95 then "fully_idle"
else if r._value >= 90 and r._value <95 then "something_is_moving"
else if r._value >= 85 and r._value <90 then "oh_oh"
else if r._value >= 80 and r._value <85 then "hmm"
else if r._value < 80 then "i_have_to_work"
else "overloaded"
})
)
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
|> set_level()
|> stateDuration(fn: (r) => r.level == "something_is_moving", column: "stateDuration", unit: 1s)
|> filter(fn: (r) => r.level == "something_is_moving")
|> derivative(unit: 10s, nonNegative: true, columns: ["stateDuration"], timeColumn: "_time")
|> sum(column: "stateDuration")
Ce qui me donne un total de 2230 secondes pour l’heure (3600s) qui vient de s’écouler.

C’est un POC rapide pour démontrer la faisabilité de la chose. Le code est surement améliorable/perfectible.
Dans un contexte InfluxDB 2.0, il y a aussi la fonction events.duration qui semble intéressante. Ce billet “TL;DR InfluxDB Tech Tips – How to Monitor States with InfluxDB” montre aussi l’usage de la fonction monitor.stateChanges() qui peut compléter l’approche.
Influx 1.8 / Flux - variante pour les séries irrégulières
La fonction derivative impose d’avoir des durées régulières pour calculer le delta. Dans le cas d’une série irrégulière, cela peut coincer rapidement et fausser les calculs. On peut donc remplacer les deux dernières lignes par la fonction increase. Elle prend la différence entre deux valeurs consécutives (quelque soit leur timestamp) et réalise une somme cumulative. Les différences négatives sont ignorées de la même façon que nous le faisions précédemment.
set_level = (tables=<-) =>
tables
|> map(fn: (r) => ({
r with
level:
if r._value >= 95 then "fully_idle"
else if r._value >= 90 and r._value <95 then "something_is_moving"
else if r._value >= 85 and r._value <90 then "oh_oh"
else if r._value >= 80 and r._value <85 then "hmm"
else if r._value < 80 then "i_have_to_work"
else "overloaded"
})
)
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
|> set_level()
|> stateDuration(fn: (r) => r.level == "something_is_moving", column: "stateDuration", unit: 1s)
|> filter(fn: (r) => r.level == "something_is_moving")
|> increase(columns: ["stateDuration"])
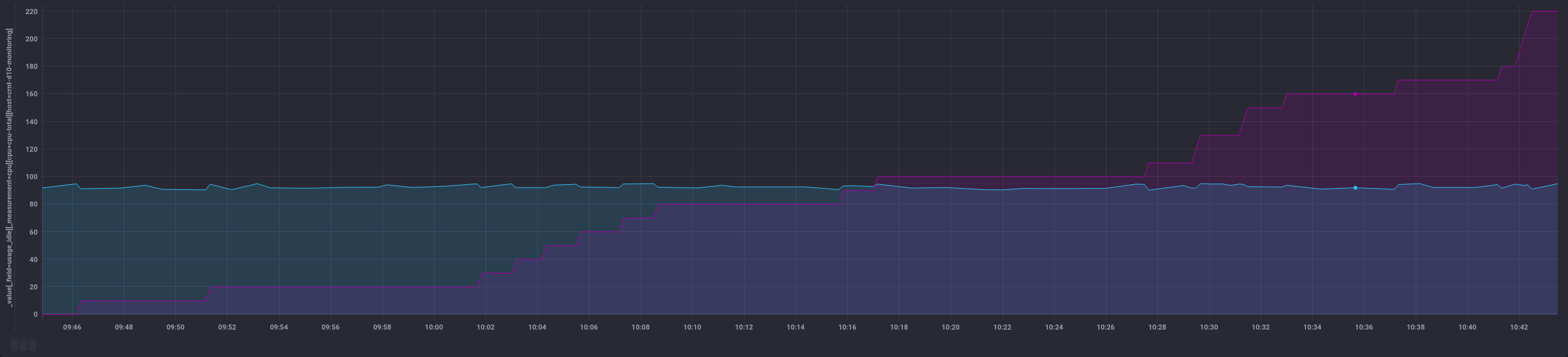
La sortie change un peu car au lieu d’un nombre unique, on a l’ensemble des points filtrés et leur somme au fur et à mesure (colonne de droite):
Cela donne des possiblités différentes au niveau dataviz :
Warp 10 / WarpScript
En la même chose en WarpScript avec Warp 10, cela donne quoi ? Regardons cela :
'<readToken>' 'readToken' STORE
// Récupération des données de cpu de type "usage_idle" en ne prenant que le label "cpu-total"
[ $readToken '~crntd10monitoring.cpu.usage_idle' { 'cpu' 'cpu-total' } NOW 1 h ] FETCH
0 GET // Fetch retourne une liste de GTS, on prend donc la première (et unique) GTS
'cpu' STORE // Stockage dans une variable cpu
// Utilisation de BUCKETIZE pour créer une série régulière de données séparées par 1 seconde
// Mes données étant espacées d'environ 10s, cela va donc créer 10 entrées de 1 seconde au final
// Pour chaque espace, on utliise la dernière valeur connue de l'espace en question pour garder les valeurs de la GTS de départ
[
$cpu
bucketizer.last
0
1 s
0
]
BUCKETIZE
// Les espaces insérés n'ont pas encore de valeurs associées
// On remplit les entrées sans valeurs avec les valeurs ci-dessus
// On utilise FILLPREVIOUS et FILLNEXT pour gérer aussi les premières et dernières valeurs
FILLPREVIOUS
FILLNEXT
// A ce stade, on a donc une GTS avec un point toute les secondes et la valeur associée. Cette valeur était la valeur que l'on avait toutes les 10s précédemment.
// On fait une copie de la GTS pour pouvoir comparer avec la version filtrée par ex
DUP
// On filtre sur les valeurs qui nous intéressent, ici on veut les valeurs >= 90 et < 95
[ SWAP 90.0 mapper.ge 0 0 0 ] MAP
[ SWAP 95.0 mapper.lt 0 0 0 ] MAP
// On renomme la liste (pratique si on affiche par ex l'ancienne et la nouvelle liste dans la partie dataviz - cf capture ci-dessous)
'+:above90below95' RENAME
// On compte le nombre d'élément de la GTS qui est sous la forme d'une liste de GTS à l'issu du MAP
0 GET SIZE
// On multiplie le nombre d'entrées par 1 s
1 s *
// on garde une copie de la valeur en secondes
DUP
// On applique le filtre HUMANDURATION qui transforme ce volume de secondes en une durée compréhensible
HUMANDURATION
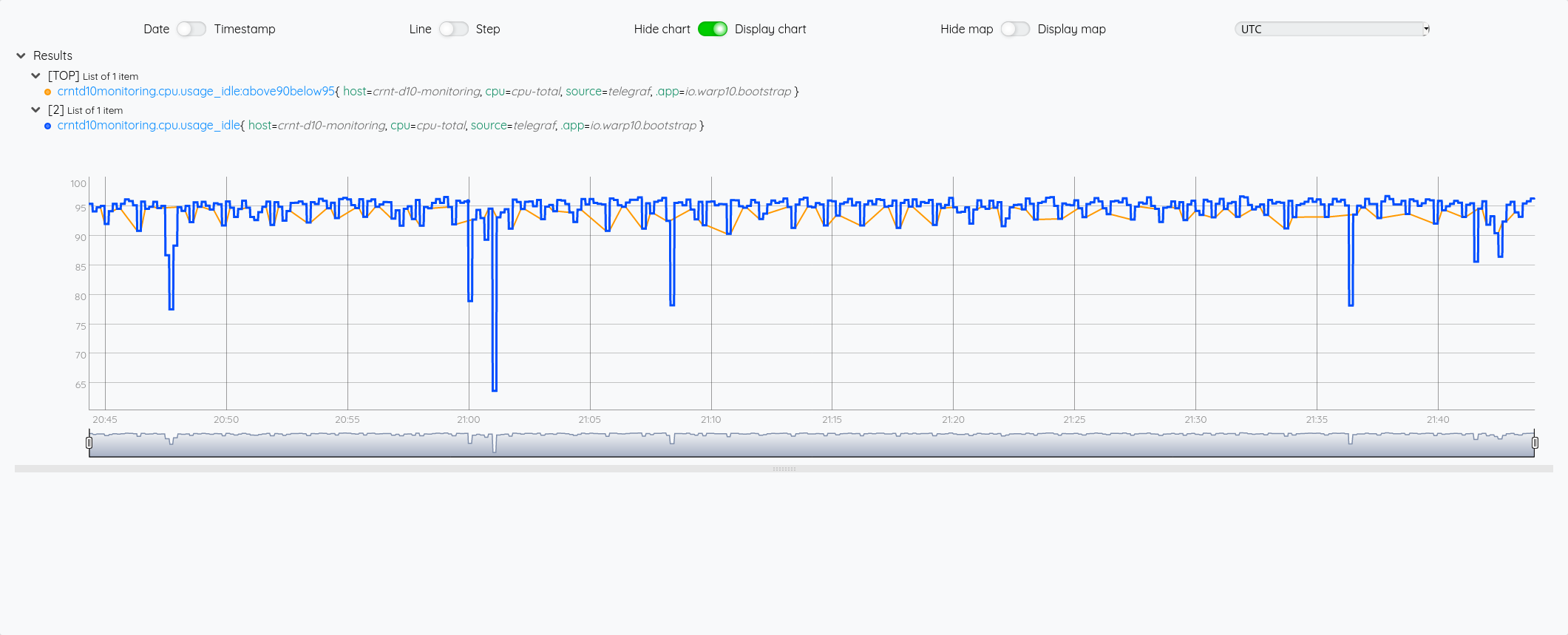
On voit ci-dessous l’usage de DUP avec la valeur humainement lisible, la valeur brute en seconde (puis le reste de la pile):

Si on ne veut pas de dataviz / ne pas conserver les valeurs intermédiaires et n’avoir que la valeur finale, on peut supprimer les lignes avec DUP et RENAME.
'<readToken>' 'readToken' STORE
[ $readToken '~crntd10monitoring.cpu.usage_idle' { 'cpu' 'cpu-total' } NOW 1 h ] FETCH
0 GET
'cpu' STORE
[
$cpu
bucketizer.last
0
1 s
0
]
BUCKETIZE
FILLPREVIOUS
FILLNEXT
[ SWAP 90.0 mapper.ge 0 0 0 ] MAP
[ SWAP 95.0 mapper.lt 0 0 0 ] MAP
0 GET SIZE
1 s *
HUMANDURATION
Et on obtient:
20m20.000000s
Un grand merci à Mathias Herberts pour sa disponiblité, sa patience et son aide face à toutes mes questions pour arriver à produire ce code.
Warp 10 / WarpScript - version agrégée
On peut aussi vouloir avoir une version agrégée de la donnée plutôt que de filter sur un état particulier. Ainsi, on peut avoir la répartition des valeurs que prend un équipement sur un indicateur donnée.
'<readToken>' 'readToken' STORE
// Récupération des métriques comme précédemment
[ $readToken '~crntd10monitoring.cpu.usage_idle' { 'cpu' 'cpu-total' } NOW 1 h ] FETCH
0 GET
'cpu' STORE
// Reformatage des données comme précédemment
[
$cpu
bucketizer.last
0
1 s
0
]
BUCKETIZE
FILLPREVIOUS
FILLNEXT
// Utilisation de QUANTIZE
// QUANTIZE a besoin que l'on définisse des sous-ensembles dans un ensemble
// Notre indicateur CPU étant un pourcentage, on prend par ex 10 sous ensemble compris entre 0 et 100
// QUANTIZE gère aussi les cas où l'on est plus petit que la première valeur et plus grand que la derinère valeur de l'ensemble
0 100 10 LBOUNDS
// On a donc 10+2 = 12 sous-ensembles : ]-infini,0],[1, 10],[11, 20],...,[90, 100],[101, inf+[
// Pour chaque valeur que nous allons passer à QUANTIZE, elle va retourer une valeur associée au sous ensemble dans laquelle la valeur va "tomber".
// Ainsi, un valeur de 95% va aller dans gt90.
// Liste des valeurs pour les 12 sous-ensembles :
[ 'neg' 'gt0' 'gt10' 'gt20' 'gt30' 'gt40' 'gt50' 'gt60' 'gt70' 'gt80' 'gt90' 'gt100' ]
QUANTIZE
// A ce stade, notre GTS de départ ne contient plus les valeurs de cpu mais les valeurs associées au tableau de QUANTIZE
// on passe donc de [<timestamp>, 95.45] à [<timestamp>, 'gt90']
// Utilisation de VALUEHISTOGRAM qui va compter le nombre d'occurences de chaque valeur d'une liste de GTS
VALUEHISTOGRAM
On obtient alors :
[{"gt90":3491,"gt80":40,"gt70":40,"gt60":10}]
Et voilà !
Web, Ops & Data - Juillet 2020
terraform acme letsencrypt influxdb influxdays questdb timeseries rancher suse stash kubedb maesh warp10 warpscript flows ptsm rgpd safe-harbor données personnelles grafana fluxCloud
- Gestion automatisée de certificats TLS avec Let’s Encrypt via Terraform et Ansible sur AWS : exemple d’utilisation du provider
acmeavec terraform pour la génération et le déploiement d’un certificat Let’s Encrypt dans un contexte AWS. - Custom Variable Validation in Terraform 0.13 : introduite en version expérimentale en 0.12.20, la validation personnalisée de variable sera stable en v ersion 0.13. De quoi valider ses ressources plus simplement.
- Avec l’acquisition d’OpenIO, OVHcloud se donne pour ambition de créer la meilleure offre de Stockage Objet du marché : acquisition d’OpenIO par OVHCloud. OpenIO fournit une solution de stockage compatible S3 et apparemment OVHVloud et OpenIO étaient habituées à travailler ensemble notamment autour de Swift (le stockage objet dans Openstack). Intéressant de voir ce type d’acquisition en Europe d’une part et de voir qu’OVHCloud remonte dans la chaine de valeur et rentre de plus en plus dans le monde du logiciel. A suivre !
Container et orchestration
- Announcing Maesh 1.3 : Maesh continue son chemin et ajoute la capacité de surveiller des namespace particuliées (en plus de pouvoir en ignorer), le support du lookup des ports (http -> 80), le support de CoreDNS chez AKS et d’autres améliorations encore.
- Electro Mpnkeys #9 – Traefik et Maesh : de l’ingress au service mesh avec Michael Matur : si vous voulez en savoir plus sur Traefik et Maesh, je vous conseille cet épisode (et les autres) du podcast Electro Monkeys.
- Introducing Traefik Pilot: a First Look at Our New SaaS Control Platform for Traefik : Containous, la société derrière Traefik, Maesh et Yaegi sort son offre SaaS pour piloter et monitorer ses instances traefik. Un système de plugins pour les middleware fait également son apparaition. Il faut une version 2.3+ (actuellement en RC) de Traefik pour bénéficier de cette intégration.
- Relicensing Stash & KubeDB : KubeDB, l’operateur de bases de données et Stash, l’outil de sauvegarde se cherchent un modèle économique et changent de licence. La version gratuite, avec code source disponible, reste disponible pour des usages non commerciaux (voir les détails de la licence pour une slite exacte). Pour un usage commercial, il faudra passer par la version Entreprise qui apporte aussi des fonctionnalités supplémentaires.
- Suse to acquire Rancher : Suse était sorti de mon radar; c’est donc pour moi l’entrée (ou le retour ?) de Suse dans le monde de kubernetes et de son orchestration. Est-ce une volonté d’aller prendre des parts de marchés à Redhat/Openshift ou de faire face à des rumeurs telles que Google en discussion pour acquérir D2IQ (ex Mesoshphère) ? A voir si cette acquisition va être un tremplin pour Rancher et ses différents projets (rke, rio, k3s, longhorn, etc) comme l’indique son CTO ou pas.
Time Series
- QuestDB nabs $2.3M seed to build open source time series database : QuestDB, historiquement issue du monde du trading à haute fréquence, commence à faire parler d’elle (notamment en récupérant un des DevRel d’InfuxData David G Simmons et vient de lever 2.3 millions de dollars. Elle a une approche SQL sur le traitement des données, se veut performante. A voir si elle reste une spécialiste de la série temporelle financière ou si elle parvient à s’ouvrir à d’autres usages.
- InfluxDays 2020 Virtual Experience : les vidéos et supports des InfluxDays sont disponibles.
- Paris Time Series Meetup #5 : De retour des InfluxDays et FLoWS : Résumé des keynotes autour des annonces produits des InfluxDays et présentation de FLoWS, la nouvelle syntaxte proposée par SenX pour interagir avec Warp10, en alternative à WarpScript. Le but est de faciliter la courbe d’apprentissage autour de Warp10. FLoWS est déjà disponible sur la sandbox et sera disponible cet été ou à la rentrée dans la version 2.7.0 de Warp10.
- Grafana v7.1 released: New features for InfluxDB and Elasticsearch data sources, table panel transformations, and more : grosse nouvelle version mineure de Grafana avec son lots d’amélioration et de nouveautés. Je vous laisse lire l’annonce.
- How to Build Grafana Dashboards with InfluxDB, Flux and InfluxQL : A l’occasion de la sortie de Grafana 7.1 qui apporte le support de Flux, présentation des nouveaux modes d’interaction entre Grafana et InfluxDB
Vie privée & données personnelles
Le Privacy Shield, l’accord entre l’Europe et les USA sur le transfert des données des Européens vers les USA (ou les sociétés américaines) vient d’être invalidé par la cour de justice européene. Les flux “absolument nécessaires” peuvent continuer à se faire pour le moment et la cour a validé “les clauses contractuelles types” définies par la Commission Européenne pourront être utilisées par les entreprises. Néanmoins, pour s’y référer, il semble qu’il faut vérifier que l’entreprise protège effectivement les données. Je vous invite à contacter votre juriste ou avocat pour mieux appréhender les impacts de cette invalidation si vous utilisez les plateformes cloud et des services dont les entreprises sont basées aux USA. En tant qu’individu, il peut être intéressant de se poser des questions également. N’étant pas juriste, je vais donc limiter mon interprétation ici et vous laisse lire les liens ci-dessous.
- La justice européenne sabre le transfert de vos données vers les USA à cause de la surveillance de masse
- L’accord sur le transfert de données personnelles entre l’UE et les Etats-Unis annulé par la justice européenne
- CJEU Judgment - First Statement
- L’accord sur le transfert de données personnelles avec les États-Unis invalidé par la justice européenne
- Invalidation du « Privacy shield » : la CNIL et ses homologues analysent actuellement ses conséquences
- Statement on the Court of Justice of the European Union Judgment in Case C-311/18 - Data Protection Commissioner v Facebook Ireland and Maximillian Schrems
- The End of the Privacy Shield Agreement Could Lead to Disaster for Hyperscale Cloud Providers
