Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Web, Ops & Data - Décembre 2020
docker runc rootless swarm cgroups kubernetes cri dockershim vector aws timestream warp10 dashboard ptsm timescale centos rhel podman influxdb timeseriesContainers et orchestration
- Electro Monkeys #37 – Podman, l’alternative de Redhat à Docker avec Benjamin Vouillaume : je me demandais si podman permettait un management de containers à distance et l’étendue de son écosystème. Le podcast permet de compléter le tour du propriétaire et de se faire une bonne idée de son positionnement.
- How to deploy on remote Docker hosts with docker-compose : dans la même quête, je me demandais s’il était possible de piloter un noeud docker à distance quand je me suis rappelé qu’il était possible de le faire au travers d’une connexion ssh. En creusant un peu plus, j’ai découvert la notion de contexte qui permet ainsi de cibler un noeud docker, docker swarm ou kubernetes.
- Don’t Panic: Kubernetes and Docker et Dockershim Deprecation FAQ : A partir de kubernetes 1.20 (fin 2020) et définitivement à partir de la version 1.23 (fin 2021), le retrait du binaire docker comme CRI de Kubernetes est annoncé. Cela ne devrait pas changer grand chose et c’est essentiellement de la plomberie interne. Plutôt que de passer par Dockershim qui implémentait l’interface CRI et qui discutait ensuite avec Docker pour lancer les conteneurs via containerd, l’appel sera directement fait à containerd. Il n’y a que ceux qui montent la socket docker dans les pods qui vont avoir un souci. Si c’est pour builder des images, il y a des alternatives comme
img,kaniko, etc. Pour les autres cas, il faudra peut être passer par l’API kubernetes ou trouver les alternatives qui vont bien. - What developers need to know about Docker, Docker Engine, and Kubernetes v1.20 et Mirantis to take over support of Kubernetes dockershim : Mirantis et Docker Inc vont assurer le support de cette interface
dockershimpour permettre à ceux qui ont en besoin de pouvoir continuer à l’utliiser. La limite étant que si vous êtes sur du service managé et que votre provider ne le fournit pas, vous ne pourrez pas l’utiliser… - Kubernetes 1.20: The Raddest Release : voilà, la version 1.20 est sortie et apporte son lot de nouveautés et de stabilisation.
- Announcing General Availability of HashiCorp Nomad 1.0 : Nomad 1.0 est également disponible.
- Introducing Docker Engine 20.10 - Docker Blog : Docker 20.10 arrive avec des profondes nouveautés comme le support des cgroupsv2 et un mode rootless,
docker logsfonctionne avec tous les drivers de log et non unqiement json & journald et plein d’autres améliorations/harmonisations au niveau de la CLI. Pour ceux sous Fedora qui avaient bidouillé avec firewalld précédemment pour faire fonctionner docker et qui ont un problème lié à l’interface docker0 au démarrage du service docker, allez voir par ici. - Docker Engine Release Notes - Version 20.10 : En plus des points précédents, il y a l’arrivée des jobs dans swarm - depuis le temps que je l’attendais 🤩 (même si on peut se toujours se poser la question de la pérénnité de swarm depuis qu’il a été racheté par Mirantis)
- New features in Docker 20.10 (Yes, it’s alive) : un billet décrivant plus en détail certaines feautres de docker 20.10 comme support Fedora/CentOS, le rootless mode, l’option
-mount, les jpbs swarm et une synthèse de l’actualité de l’écosystème docker. - Podman Release 2.2.0 : ajout des commandes
network (dis)connect, support des alias avec des noms courts, amélioration des commandesplay|generate kubeet capacité de monter une image OCI dans un container.
Observabilité
- Vector - Collect, transform, & route all observability data with one simple tool. (via) : vector est un outil en rust qui permet de collecter et manipuler des métriques/logs/événements et de les envoyer vers différentes destinations. De quoi remplacer filebeat/journalbeat voire même telegraf ? ;-)
- Our new partnership with AWS gives Grafana users more options : AWS vient d’annoncer un service managé pour Prometheus basé sur Cortex et pour Grafana (version Entrepsise). Grafana et Cortex étant des projets édités par Grafana Labs sous licence OSS (et des déclinaisons Cloud et Entreprise). AWS changerait-il sa façon de travailler avec les projets OSS lorsqu’il souhaite en faire des services managés et prendre ainsi une attitude plus positive vis à vis de la communauté OSS ?
OSS
- Death of an Open Source Business Model : Analyse du passage de Mapbox GL JS v2 sous licence propriétaire, le modèle de l’open core et les menaces des top cloud providers sur le reste de l’économie du logiciel. On peut étendre cela aussi “VC funded OSS company”.
Système
- CentOS Project shifts focus to CentOS Stream, CentOS Stream: Building an innovative future for enterprise Linux et la FAQ associée : Historiquement CentOS Linux était batie sur les sources de Red Hat Entreprise Linux un fois celle-ci disponible. CentOS Stream renverse un peu la tendance avec un cycle d’intégration plutôt Fedora -> CentOS Stream -> RHEL. L’initiative CentOS Stream avait été annoncée en septembre 2019 et ce changement permet donc aux équipes CentOS de se focoaliser sur une seule version (CentOS Stream) et non plus deux versions (CentOS Stream et CentOS Linux). CentOS Linux 7 sera maintenue jusqu’à la fin du support de RHEL 7 et et CentOS 8 jusqu’à fin 2021 (et non pas 2029 comme prévu). Il n’y aura pas de version 9 de CentOS Linux. A tester pour voir si CentOS Stream est plus stable que Fedora mais moins conservateur que RHEL et pourrait alors s’avérer être un bon compromis.
- Before You Get Mad About The CentOS Stream Change, Think About… : un billet assez long d’un employé de Red Hat qui exprime son opinion et cherche à remettre les choses en perspective en dépassionnant le débat.
Time Series
- PTSM Edition #8 - Amazon TimeStream 101 : Edition du Paris time Series Meetup sur AWS Timestream
- TimescaleDB vs. Amazon Timestream: 6000x higher inserts, 5-175x faster queries, 150x-220x cheaper : avec toutes les réserves habitudelles sur les benchmarks, Timescale a comparé son produit avec AWS Timestream et la conclusion semble clairement en faveur de Timescaledb. A noter que l’update des données est arrivé dans AWS Timestream entre temps.
- Truly Dynamic Dashboards as Code : les équipes de SenX ont implémenté leur vision du “Dashboards as Code” sous le nom Discovery. Discovery veut aller plus loin que la simple description d’un dashboard comme on peut le voir dans Grafana ou InfluxDB 2.0 en apportant une touche de dynamisme et de génération dynamique des dashboards en fonction des élements obtenus (ex si valeur X > Y alors afficher la procédure AAA de résolution d’incident). J’ai commencé à jouer avec, un billet de blog sur ce sujet devrait bientôt arriver.
- NeuralProphet : un modèle neuronal orienté série temporelles, inspiré de Facebook Prophet et développé avce PyTorch.
- Release Notes InfluxDB 2.0.3 et Release Announcement: InfluxDB OSS 2.0.3 : build arm64 en preview, un petit conflit de packaging entre
influxdbetinfluxdb2à passer pour ceux qui étaient déjà en 2.0 et ceci afin d’éviter que des gens en 1.x passent involontairement en 2.x, le “delete with predicate” a été réactivé, améliorations sur le process d’upgrade, des commandes autour des actions en mode V1, mise à jour de flux, et plein d’autres corrections/améliorations.
Web
- Web Almanac 2020 - Rapport annuel de HTTP Archive sur l’état du Web : une synthèse de l’état du web d’après HTTP Archive sur une base de 7.5 millions de sites testés, soit 31.3 To de données traitées. De quoi relativisez un peu les biais de notre bulle technologique : non tout le monde ne fait pas du React/Angular/Vue.js par ex mais plutôt du JQuery ! Suivant vos usages, plein d’enseignements et de choses intéressantes à tirer de cette synthèse.
Il ne me reste plus qu’à vous souhaiter de bonnes fêtes de fin d’année et on se retrouve l’année prochaine !
Web, Ops & Data - Septembre 2020
podman timezone grafana dashboard terraform sécurité terrascan terracost nvidia arm cni csi network storage cilium calico longhorn portworx openebs rancher python gke warp10 influxdb data-engineer date-scientist sqlCloud
- terrascan : terrascan va scanner vos fichiers terraform et les valider contre 500+ règles de sécurité (au format Open Policy Agent) afin d’identifier les éventuels problèmes de sécurité. L’outil supporte AWS, GCP et Azure.
- infracost : estimez le coût de vos projets terraform à l’heure ou au mois. Il est même possible de faire apparaitre les évolutions de vos coûts d’infra lors d’une MR/PR. A défaut d’être forcément précis, cela pourra au moins donner une idée et permettra peut être de sensibiliser les développeurs et/ou les clients aux évolutions de couts de leurs projets.
Code
- All Python versions before 3.6 are now totally unsupported : Python 2 n’est plus supporté depuis le début de l’année - c’est au tour de Python 3.5 de ne plus l’être depuis le 13 sept. Pour Python 3.6, ce sera décembre 2021.
- nackjicholson/aiosql : juste milieu (?) entre du SQL brut et un ORM, aiosql semble permettre d’associer une requête SQL à une fonction pour une manipulation assez simple ensuite dans le code par la suite.
Container et orchestration
- Tick-tock. Does your container know what time it is? : le fichier
/etc/localtimeest en général défini dans votre image de base et peut ne pas convenir à votre fuseau horaire. Podman permet de surcharger cela en précisant à l’exécution ou via un point de configuration le fuseau horaire à utiliser. Pratique plutôt que de modifier le fichier via votre Dockerfile. - Kubernetes Storage Performance Comparison v2 (2020 Updated) : une comparaison des solutions de stockage rook/Ceph, Azure PVC, Azure hosyPath, GlusterFS, Portworx, OpenEBS MayaStor et Rancher Longhorn. La conclusion se termine par un trio de tête emmené par Portworx, OpenEBS et Longhorn. Ce dernier étant plus adapté pour des besoins légers de stockage.
- New GKE Dataplane V2 increases security and visibility for containers & Google announces Cilium & eBPF as the new networking dataplane for GKE : GKE va utilise Cilium comme CNI pour son data plane v2 (il utilise actuellement Calico comme CNI si les network policy sont activées lors de la création de votre cluster)
- Benchmark results of Kubernetes network plugins (CNI) over 10Gbit/s network (Updated: August 2020) : pour des petits clusters, la solution la plus performante serait/resterait Calico et Cilium ne serait efficace que pour des gros clusters.
(Big) data
- #19. Lucien Fregosi - Hugo Larcher - Erika Gelinard - Dessine moi un data engineer : Pour cette saison 2 de DataBuzzWord, des réflexions intéressantes autour du Data Engineer / Data Scientists, le Data Engineer qui fait du Build/Run, les pipelines & job as a service et de l’importance de simplifier / déporter le run pour que le Data Engineer et a fortiori le Data Scientist se concentrent sur leurs pipelines ou leur exploitation et gérer moins d’infrastructure.
Hardware
- NVIDIA to Acquire Arm for $40 Billion, Creating World’s Premier Computing Company for the Age of AI : Nvidia sur le point d’acheter ARM pour en faire un leader des processeurs (CPU/GPU) et de l’IA. On voit que le sujet est politique dans le soin qui est apporté au site ARM de Cambridge et de son développement à venir.
Time Series
- InfluxDB OSS 2.0 General Availability Roadmap : un bon résumé sur les avancées d’Influx 2.0 OSS et la transition 1.x vers 2.x ; Début septembre, j’étais sceptique quand même avec le retour du stockage et du requêtage da la V1 dans la branche v2 (cf la PR “Port TSM1 storage engine”) et ce à un mois de la date de release prévue annoncés aux Influxdays de Londres (ie fin septembre). Au final, la version 2.0 OSS et Entreprise auront les feautres “frontend” de la V2 (Tasks, Dashobards, etc) mais uniquement le moteur de stockage de la V1. Si je comprends le besoin pour ne pas perdre leurs clients dans la migration, c’est un écart de plus entre les version OSS/Entreprise et la version Cloud. Les couches hautes (API, UI, fonctionnalités type Task/Dashboards/…) seront commmunes mais sous le capot (stockage, ingestion), cela diffère. On peut raisonnablement se demander si c’est une phase intermédiaire avant une migration ultérieure sur le moteur de stockage de la 2.0 quand InfluxData aura plus de recul sur le sujet ou bien si les projets Cloud et OSS/Entreprise ne vont pas diverger significativement à moyen terme. Ceux qui ont commencé à alimenter leur base InfluxDB 2.0 sur la base des versions beta devront repartir de zéro du fait de cette incompatibilité de version de moteur de stockage.
- Popular community plugins that can improve your Grafana dashboards : une collection de plugins Grafana pour améliorer vos dashboards.
- September 2020: Warp 10 release 2.7.0, ready for FLoWS : la version 2.7 de Warp 10 est disponible et est la première version qui va supporter FLoWS, la syntaxe fonctionnelle alternative à WarpScript. Pour en savoir plus sur FLoWS, je vous renvoie à l’édition 5 du Paris Time Series Meetup avec la présentation de FLoWS. D’autres améliorations font partie de cette release, tant d’un point de vue fonctionnalités que performances.
Premiers pas avec Warp 10 : comptabilité et prévisions de fin d'année
warp10 timeseries forecast dashboard warpstudio arimaSuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année (ce billet)
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512
- Partie 6 - Les FEC et le compte de résultat
Cherchant à me familiariser avec la base de données orientée série temporelles Warp 10 d’une part et à améliorer mes tableaux de bord comptables pour me faire des projections à fin d’année (parce que bon, faire juste la moyenne des mois précédents comme valeur pour les mois à venir, c’est un peu trop facile), je me suis dit que c’était un exercice qui pouvait répondre aux deux besoins après avoir lu Time series forecasts in WarpScript.
Pour ceux qui ne connaissent pas encore Warp 10 , c’est une solution de geo-timeseries (séries spatio temporelles) open source, éditée par SenX, société française basée à Brest. Pour en savoir plus sur Warp 10 , vous pouvez regarder l’éditions 1 et l’édition 5 du Paris Time Series Meetup.
Pour prendre en main Warp 10 et appréhender le langage de programmation Warpscript, je vous invite à suivre le tutoriel sur les cyclones en utilisant la Sandbox Warp10 mise à disposition par Senx.
Le jeu de données
Pour le jeu de données, j’ai donc récupéré de mes tableaux de bords mon chiffre d’affaires et mes dépenses mensuels sur la période Janvier 2017 à Mai 2020.
Nous allons donc créer 2 séries (appelées aussi GTS)
Soit crnt-revenue.gts:
# 2017
1483225200000000// revenue{company=cerenit} 0
1485903600000000// revenue{company=cerenit} 13800
1488322800000000// revenue{company=cerenit} 11325
1490997600000000// revenue{company=cerenit} 300
1493589600000000// revenue{company=cerenit} 6825
1496268000000000// revenue{company=cerenit} 8450
1498860000000000// revenue{company=cerenit} 5425
1501538400000000// revenue{company=cerenit} 10650
1504216800000000// revenue{company=cerenit} 13650
1506808800000000// revenue{company=cerenit} 0
1509490800000000// revenue{company=cerenit} 11200
1512082800000000// revenue{company=cerenit} 19225
# 2018
1514761200000000// revenue{company=cerenit} 8300
1517439600000000// revenue{company=cerenit} 8850
1519858800000000// revenue{company=cerenit} 10285
1522533600000000// revenue{company=cerenit} 8850
1525125600000000// revenue{company=cerenit} 8850
1527804000000000// revenue{company=cerenit} 9450
1530396000000000// revenue{company=cerenit} 12000
1533074400000000// revenue{company=cerenit} 11250
1535752800000000// revenue{company=cerenit} 15013
1538344800000000// revenue{company=cerenit} 15750
1541026800000000// revenue{company=cerenit} 13750
1543618800000000// revenue{company=cerenit} 10125
# 2019
1546297200000000// revenue{company=cerenit} 15375
1548975600000000// revenue{company=cerenit} 14750
1551394800000000// revenue{company=cerenit} 11600
1554069600000000// revenue{company=cerenit} 20622
1556661600000000// revenue{company=cerenit} 6376
1559340000000000// revenue{company=cerenit} 13350
1561932000000000// revenue{company=cerenit} 11250
1564610400000000// revenue{company=cerenit} 7050
1567288800000000// revenue{company=cerenit} 14750
1569880800000000// revenue{company=cerenit} 12326
1572562800000000// revenue{company=cerenit} 12513
1575154800000000// revenue{company=cerenit} 9082
# 2020
1577833200000000// revenue{company=cerenit} 13000
1580511600000000// revenue{company=cerenit} 12375
1583017200000000// revenue{company=cerenit} 15500
1585692000000000// revenue{company=cerenit} 5525
1588284000000000// revenue{company=cerenit} 15750
et crnt-expenses.gts:
# 2017
1483225200000000// expense{company=cerenit} 219
1485903600000000// expense{company=cerenit} 5471
1488322800000000// expense{company=cerenit} 7441
1490997600000000// expense{company=cerenit} 6217
1493589600000000// expense{company=cerenit} 5676
1496268000000000// expense{company=cerenit} 5719
1498860000000000// expense{company=cerenit} 5617
1501538400000000// expense{company=cerenit} 5690
1504216800000000// expense{company=cerenit} 5831
1506808800000000// expense{company=cerenit} 9015
1509490800000000// expense{company=cerenit} 8903
1512082800000000// expense{company=cerenit} 11181
# 2018
1514761200000000// expense{company=cerenit} 9352
1517439600000000// expense{company=cerenit} 9297
1519858800000000// expense{company=cerenit} 8506
1522533600000000// expense{company=cerenit} 8677
1525125600000000// expense{company=cerenit} 10136
1527804000000000// expense{company=cerenit} 10949
1530396000000000// expense{company=cerenit} 8971
1533074400000000// expense{company=cerenit} 9062
1535752800000000// expense{company=cerenit} 9910
1538344800000000// expense{company=cerenit} 10190
1541026800000000// expense{company=cerenit} 10913
1543618800000000// expense{company=cerenit} 13569
# 2019
1546297200000000// expense{company=cerenit} 11553
1548975600000000// expense{company=cerenit} 11401
1551394800000000// expense{company=cerenit} 10072
1554069600000000// expense{company=cerenit} 10904
1556661600000000// expense{company=cerenit} 9983
1559340000000000// expense{company=cerenit} 11541
1561932000000000// expense{company=cerenit} 11065
1564610400000000// expense{company=cerenit} 10359
1567288800000000// expense{company=cerenit} 10450
1569880800000000// expense{company=cerenit} 9893
1572562800000000// expense{company=cerenit} 10014
1575154800000000// expense{company=cerenit} 15354
# 2020
1577833200000000// expense{company=cerenit} 9673
1580511600000000// expense{company=cerenit} 9933
1583017200000000// expense{company=cerenit} 9815
1585692000000000// expense{company=cerenit} 9400
1588284000000000// expense{company=cerenit} 9381
Pour chaque fichier:
- le premier champ est un timestamp correspondant au 1er jour de chaque mois à 00h00.
- la partie
//indique qu’il n’y a pas de position spatiale (longitude, lattitude, élévation) expenseetrevenuesont les noms des classes qui vont stocker mes informationscompanyest un label que je positionne sur mes données avec le nom de mon entreprise- le dernier champ est la valeur de mon chiffre d’affaires ou de mes dépenses mensuels.
Pour plus d’information sur la modélisation, cf GTS Input Format.
Insertion des données
Lorsque vous utilisez la Sandbox, 3 tokens vous sont donnés :
- un token pour lire les données ; j’y ferai référence via
<readToken>par la suite - un token pour écrire les données ; j’y ferai référence via
<writeToken>par la suite - un token pour supprimer les données ; j’y ferai référence via
<deleteToken>par la suite
#!/usr/bin/env bash
for file in crnt-expenses crnt-revenue ; do
curl -v -H 'Transfer-Encoding: chunked' -H 'X-Warp10-Token: <writeToken>' -T ${file}.gts 'https://sandbox.senx.io/api/v0/update'
done
Premières requêtes
Pour ce faire, nous allons utiliser le Warp Studio ; pour la datasource, il conviendra de veiller à ce que la SenX Sandbox soit bien sélectionnée.
L’équivalent de “SELECT * FROM *” peut se faire de la façon suivante :
# Authentification auprès de l'instance en lecture
'<readToken> 'readToken' STORE
# FETCH permet de récupérer une liste de GTS, ici on demande toutes les classes via ~.* et tous les labels en prenanr les 1000 dernières valeurs ; on récupère donc toutes les séries.
[ $readToken '~.*' {} NOW -1000 ] FETCH
Si vous cliquez sur l’onglet “Dataviz”, vous avez alors immédiatement une représentation graphique de vos points.
Maintenant que nos données sont bien présentes, on va vouloir aller un peu plus loin dans nos manipulations.
Premières manipulations
Ce que nous voulons faire :
- Sélectionner chaque série et la stocker dans une variable,
- Calculer le résultat mensuel et le persister dans une troisième série temporelle
- Afficher les trois séries.
Pour sélectionner chaque série et la stocker dans une variable:
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# FETCH : permet de récupérer une liste de série, ici on filtre sur la classe expense, sur le label company = cerenit et sur les dates du 01/12/2016 au 01/06/2020.
# 0 GET : on sait que l'on a qu'une seule série qui correspond à la requête. Donc on ne retient que le 1er élément pour passer d'une liste de GTS à une seule et unique GTS.
# STORE : stocke le résultat dans une variable exp.
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
# Idem pour la classe revenue, stockée dans une variable revenue.
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
# Affiche les 2 séries
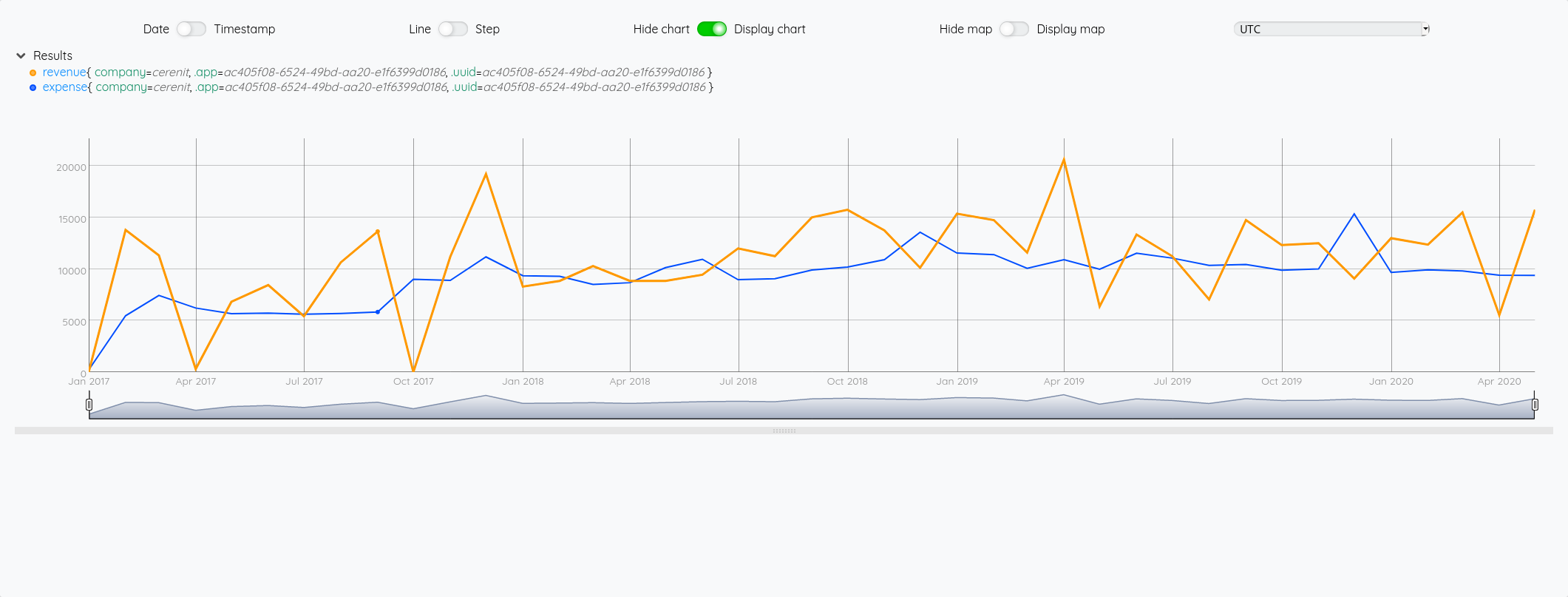
$exp
$revenue
A ce stade, vous avez la même représentation graphique que précédemment si vous cliquez sur Dataviz.
Calculons maintenant le résultat mensuel (chiffre d’affaires - dépenses) :
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# Le même bloc que précédemment
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
# Calcul: il suffit se soustraire les deux éléments pour avoir le résultat
$revenue $exp -
# on affiche également les deux autres variables pour la dataviz
$exp
$revenue
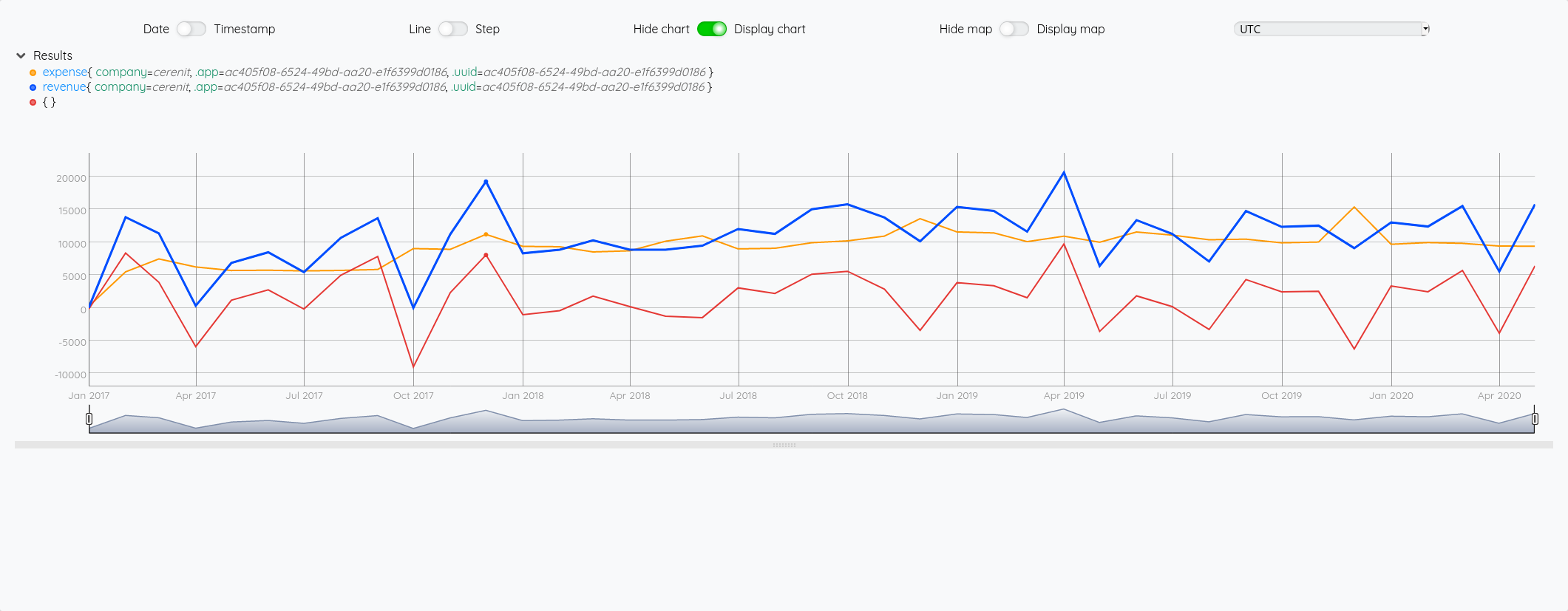
A ce stade :
- Au niveau de la dataviz, la légende ne fournit aucune information sur la nature de la série
- Cette donnée n’est pas encore persistée
Jusqu’à présent, nous avons utilisé que le <readToken> pour lire les données. Pour la persistence, nous allons utilier le <writeToken>.
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# Authentification auprès de l'instance en écriture
'<writeToken>' 'writeToken' STORE
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
# La première ligne est inchangée, elle calcule le résultat mensuel et la donnée est de type GTS
# Du coup, comme nous sommes dans une pile et que l'on hérite de ce qu'il s'est passé avant, on peut lui assigner un nom via RENAME
# Puis lui ajouter le label company avec pour valeur cerenit
# Et utiliser la fonction UPDATE pour stocker en base la GTS ainsi obtenue.
$revenue $exp -
"result" RENAME
{ "company" "cerenit" } RELABEL
$writeToken UPDATE
# Comme pour revenue et expense, on récupère les données sous la forme d'une GTS que l'on stocke dans une variable
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
# On vide la pile
CLEAR
# On affiche les variables créées
$revenue
$exp
$result
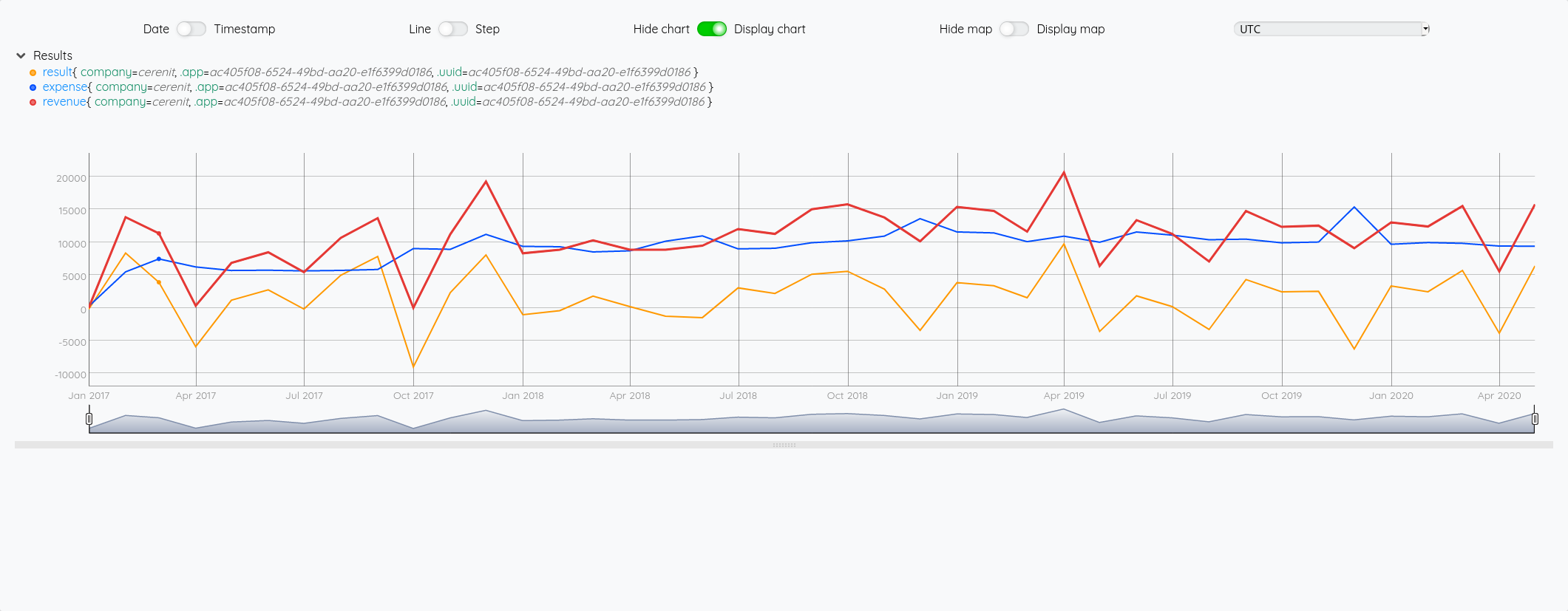
Et voilà !
Prévoyons le futur
Warp10 dispose d’une extension propriétaire et payante permettant d’appliquer des algorithmes de prévisions sur des séries temporelles : warp10-ext-forecasting. Il est possible d’utiliser cette extension sur la Sandbox Warp10 mise à disposition par SenX.
Il existe une fonction AUTO et SAUTO (version saisonnière) qui applique automatiquement des algorythmes d’AutoML sur vos données.
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# Récupération des trois séries
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
CLEAR
$revenue
$exp
$result
# MAP: la fonction `AUTO` s'attend à manipuler des nombres au format `DOUBLE` et non des entiers. Il faut donc faire la conversion.
# FORECAST: sur les données obtenues du MAP, on applique la fonction AUTO et on demande les 8 prochaines occurents (pour aller jusqu'à la fin d'année)
# Le .ADDVALUES permet de "fusionner" les prévisions avec la série parente (sans les persister en base à ce stade)
# Commes les 3 projections sont disponibles dans la pile, elles sont également affichées
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
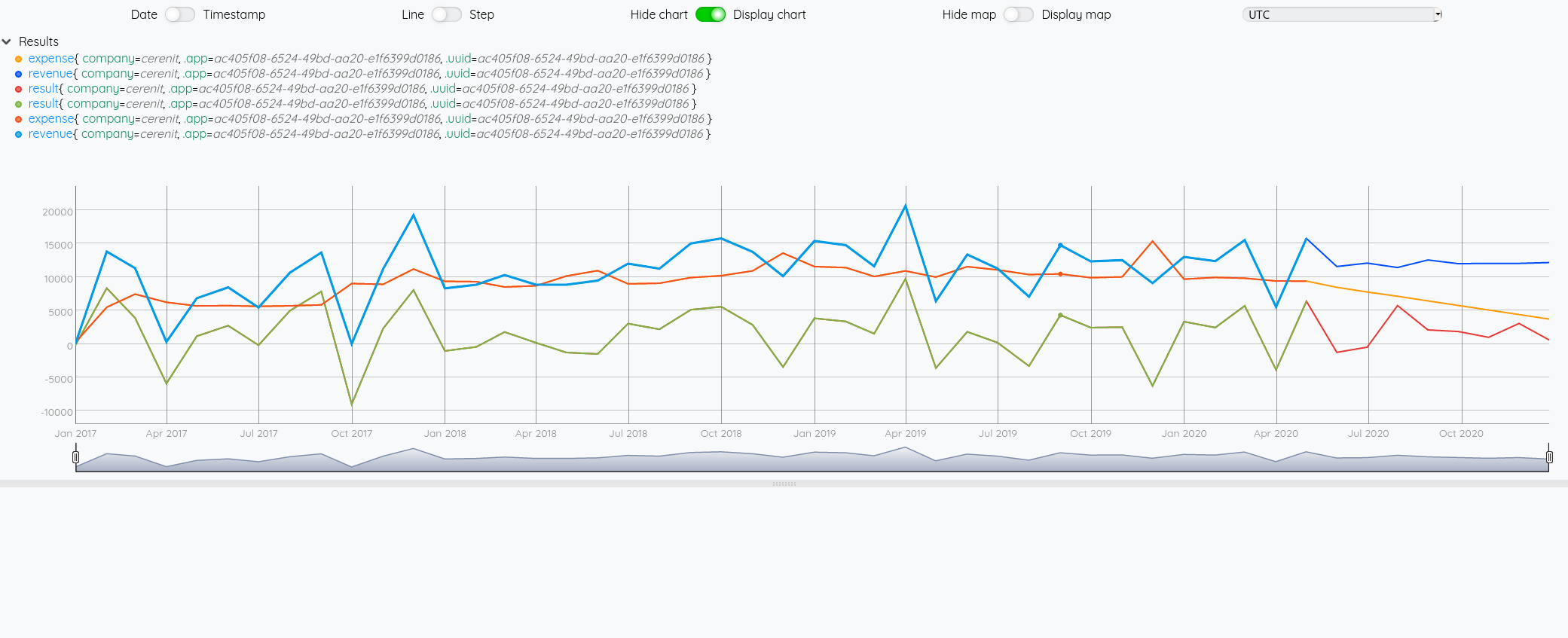
Du fait du FORECAST.ADDVALUES, on pourrait se passer d’afficher les trois premières séries. Mais vistuellement, cela permet de voir la différence entre la série originale et la projection.
Une fois l’effet Whaou passé, on peut se demander quel modèle a été appliqué. Pour cela il y a la fonction MODELINFO
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# Récupération des trois séries
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
CLEAR
[ $result mapper.todouble 0 0 0 ] MAP
AUTO MODELINFO
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO MODELINFO
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO MODELINFO
Dans l’onglet des résultats, on voit l’information: "model": "ARIMA".

Si on veut alors faire la même chose en utilisant le modèle ARIMA :
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# Récupération des trois séries
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
CLEAR
# SEARCH.ARIMA: applique un modèle ARIMA (ARMA ou ARIMA) sur la GTS passée en paramètre
# FORECAST.ADDVALUES: fait une précision sur les 7 prochaines occurences et les fusionne avec la série sur laquelle la projection est faite.
# Les 3 projections restant dans la pile, elles sont affichées
[ $revenue mapper.todouble 0 0 0 ] MAP
SEARCH.ARIMA
7 FORECAST.ADDVALUES
[ $exp mapper.todouble 0 0 0 ] MAP
SEARCH.ARIMA
7 FORECAST.ADDVALUES
[ $result mapper.todouble 0 0 0 ] MAP
SEARCH.ARIMA
7 FORECAST.ADDVALUES
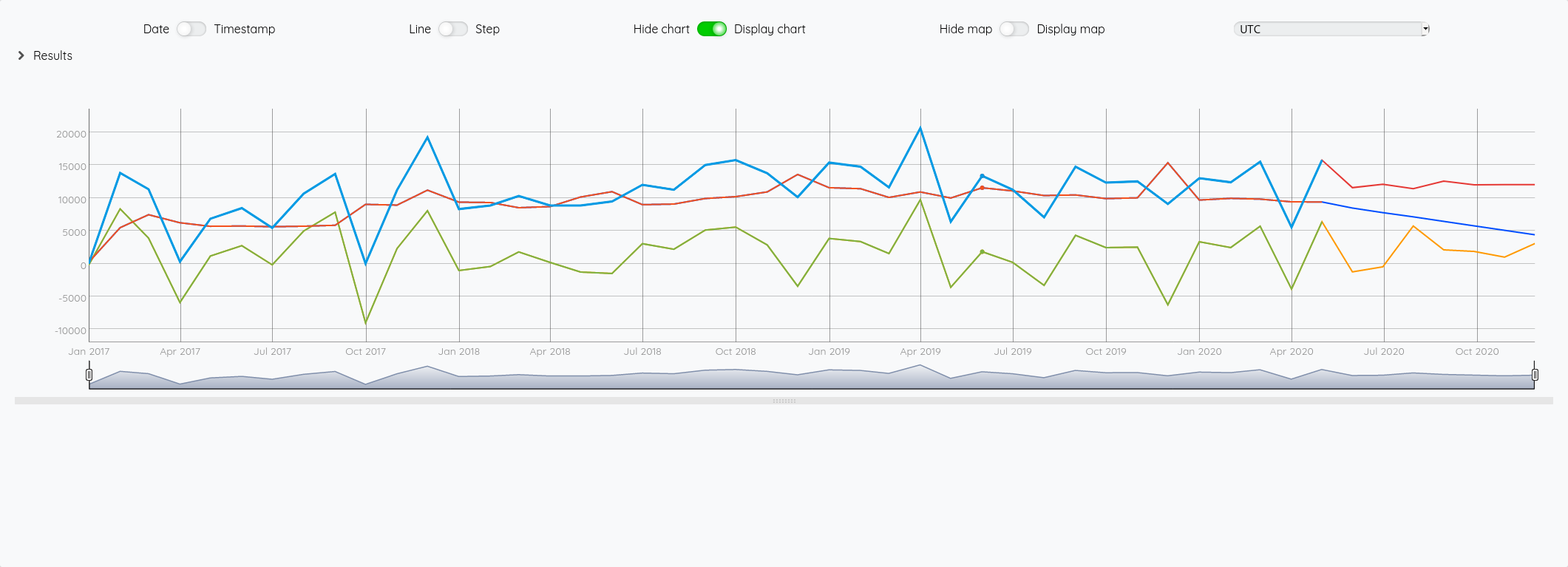
Et nous obtenons bien le même résultat.
On peut se poser alors la question de voir si la projection sur le résultat est la même que la soustraction entre la projection de chiffres d’affaires et de dépenses et mesurer l’éventuel écart.
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
[[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
CLEAR
# La différence sur les 3 projections est que l'on stocke chaque résultat dans une variable
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
'fresult' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
'frevenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
'fexp' STORE
$frevenue
$fexp
$fresult
# ici on calcule la projection du résultat sur la base des projections de chiffres d'affaires et de dépenses
$frevenue $fexp -
On constate bien un écart entre la courbe orange (la soustraction des projections) et la courbe bleu (la projection du résultat).
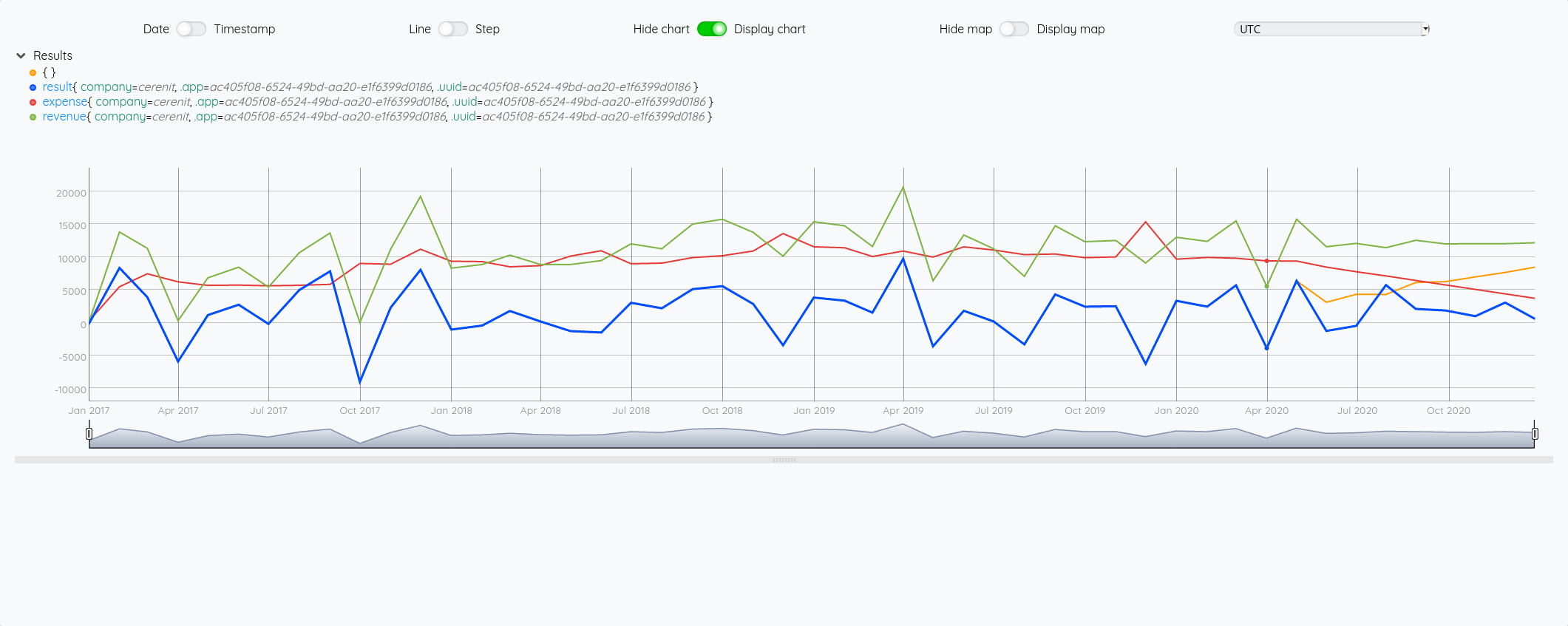
Nous voilà à la fin de ce billet, j’espère que ce tour du propriétaire vous aura permis d’apprécier Warp10 et ses capacités.
Il ne reste plus qu’à voir en fin d’année dans quelles mesures ces projections seront valides ou pas !
Mon bilan sur Warp10 à ce stade :
- Il faut absolument suivre le tutoriel sur les cyclones, cela permet de se mettre progressivement à Warpscript et de comprendre les mécanismes de fonctionnement du langage et de la pile (stack).
- la notation de Warpscript est particulière au début mais on s’y fait petit à petit et sinon FLoWS devrait lever les dernières réticences.
- Comme on a une pile, il ne faut pas hésiter à utiliser
STOPetTYPOEOFnotamment pour savoir ce que l’on manipule comme donnée à un instant T ; cf Debugging WarpScript - Le WarpStudio ou l’extension VSCode permettent d’avoir un contexte de développement agréable avec l’autocomplétion, la documentation des fonctions, etc.
- Contrairement à InfluxDB où tout s’articule autour du measurement (équivalent de la classe ici), le fait d’avoir un langage de manipulation (et pas principalement de requêtage avec quelques transformations) de données permet d’avoir une modélisation plus souple et de réconcilier les données ensuite. Le même exercice dans InfluxDB supposerait d’avoir un seul measurement et d’avoir les différentes valeurs en son sein. Du coup, cela empêcherait le calcul et le stockage du résultat par ex. Il aurait fallu le calculer au préalable et l’insérer dans la base en même temps que les données de chiffre d’affaires et de dépenses pour que les données soient ensemble. Certes Flux et InfluxDB 2.0 vont lever quelques contraintes de modélisation et de manipulation de données, mais le prisme de la modélisation autour du measurement reste primordial dans le produit.
- Avoir un langage de manipulation de données et non uniquement de requêtage et quelques transformation évite aussi de devoir sortir les données pour les analyser puis les renvoyer vers la base de données le cas échéant. Non seulement on reste au plus près de la donnée (éxécution coté serveur) mais on évite aussi les problématiques de drivers, conversion dans les structures de données du langage cible, etc.
- Les classes de warpscript sont certes mono valeurs (même si le multivalue existe) mais je présume que cela sert surtout pour des données de même nature plutôt que pour des données hétérogènes. En effet, il s’agit d’une liste et non d’un tableau de données. (NDLR: Mathias me précise qu’une multivalue est une GTS et non une simple liste - cela est précisé si on lit bien la totalité de la doc de multivalue)
Une expérience au final positive qui pousse à aller creuser plus loin les fonctionnalités de cette plateforme. Ce sera l’opportunité de rédiger d’autres billets à l’avenir.
Web, Ops & Data - Décembre 2019
influxdb docker kubernetes traefik grafana dashboard cassandra reaper warp10 timeseries timescaledb helm machine learningRendez-vous le 21 janvier prochain à la troisième édition du Paris Time Series Meetup consacré à TSL (billet introductif à TSL : TSL: a developer-friendly Time Series query language for all our metrics) et le module RedisTimeSeries qui apporte des fonctionnalités et des structures Time Seriies à Redis. Le meetup était prévu initialement le mardi 17 décembre mais a été reporté du fait des grèves.
Container et orchestration
- DockerSlim : le projet vise à réduire la taille de vos images et à améliorer leur sécurité en procédant à différentes optimisations. Cela peut être intéressant dans une stratégie d’améliorations de vos images docker mais à tester néanmoins. Les exemples données partent d’Ubuntu 14.04 dont l’image fait 60 / 65 Mo alors que l’image Ubuntu 16.04 fait moitié moins et Alpine fait 30 fois moins. Donc certains gains semblent faciles à obtenir, à creuser plus en détail.
- Kubernetes 1.17: Stability : après une version 1.16 marquée notamment par la dépréciation de certaines APIs, cette version se veut plus une consolidation autour des “Cloud Provider Labels” qui passent en GA, le snapshot de volumes qui passe en beta, ainsi que la couche de stockage CSI avec la poursuite de la migration des plugins “in-tree” vs “out-of-tree”. La fin de cette migration est prévue pour les versions 1.19 / 1.20 et le retrait complet des plugins “in-tree” pour les versions 1.21 / 1.22.
- A visual guide on troubleshooting Kubernetes deployments : un guide du troublehooting des déploiements sous kubernetes avec un joli diagramme des cas possibles et les explications associées en repartant d’un exemple simple.
- How to migrate from Helm v2 to Helm v3 : les opérations à mener pour migrer de Helm V2 à Helm V3.
- Traefik 2.1 : le provider Consul Catalog fait son retour (il était absent en 2.0.x) et diverses améliorations sur la CRD Kubernetes ont été apportées pour mieux gérer le mirroring du traffic, les déploiements canary et la gestion des sessions. La migration ne consistant pas seulement à changer le numéro de version et suite à une remarque de ma part, une note a été ajoutée pour la migration 2.0.x vers 2.1.x
Dataviz
- Pro Tips: Dashboard Navigation Using Links : améliorer vos dashboards Grafana avec des liens à différents niveaux dans l’interface pour pointer vers des ressources utiles.
NoSQL
- Cassandra Reaper 2.0 was released : la solution de réparation de vos clusters Cassandra passe en 2.0 ; elle apporte un déploiement en mode sidecar (reaper est lancé dans la même jvm que Cassandra), le support d’Apache Cassandra 4.0 (pas encore officiellement disponible), de nouveaux thèmes, une amélioration du support de Postgresql comme backend de déploiement et pleins d’autres choses.
Time Series
- Release Announcement: InfluxDB 2.0.0 Alpha 21 : Cette version alpha apporte notamment le début de la transpilation des requêtes InfluxQL en Flux. C’est peut être un des plus gros enjeux pour la migration entre la version 1.x et 2.x d’InfluxDB et la gestion de l’écosystème associé.
- Warp 10™ release 2.3.0 : la plateforme Warp10 continue son chemin avec une fonctionnalité intéressante permettant de mieux définir les points que l’on veut récupérer pour une requête donnée (nombre de points, échantillonage, points du début et de fin, etc)
- Motion Split : Présentation d’une autre fonctionnalité intéressante de Warp10 2.3.0 si vous suivez des objets qui se déplacent et que vous voulez définir des groupes de points en fonction d’un délai, d’une distance, d’arrêts.
- New: Helm Charts for deploying TimescaleDB on Kubernetes : pour ceux qui utilisent TimescaleDB, des charts helm sont à votre disposition pour déployer une instance, avec gestion de la réplication des données.
- Time series features extraction using Fourier and Wavelet transforms on ECG data : Application de la théorie des signaux sur des séries temporelles dans le cadre d’analyse d’électrocardiogramme. Cela complète les articles du mois précédent.
Je n’ai plus qu’à vous souhaiter des bonnes fêtes de fin d’année ; nous nous retrouvons l’année prochaine !
Web, Ops & Data - Semaine 48
traefik docker kubernetes grafana null aws alerte monitoring dashboard reverse-proxyContainer & orchrestration
- Kompose: a tool to go from Docker-compose to Kubernetes : en cours d’incubation chez Kubernetes, ce projet permet de faciliter la transition de Docker à Kubernetes en transformant les fichier
docker-compose.ymlen fichiers Manifests Kubernetes. Un pivot intéressant si on considère que les développeurs vont utiliser Docker (et au mieux Swarm) pour leurs environnements de développement et en production éventuellement Swarm et ensuite vouloir migrer vers Kubernetes pour ses fonctionnalités plus évoluées. - Introducing Distributed Cheese: Traefik 1.1 Camembert Is Out! : Traefik, le reverse proxy moderne qui sait s’interfacer notamment avec Docker, Consul, Kubernetes et plein d’autres est sorti en version 1.1.x. Cette version apporte notamment le support de l’API Docker Swarm (Docker 1.12+), une meilleure gestion des contraintes, le support de Mesos, une meilleure gestion des affinités de sessions, un mode cluster pour Traefik (expérimental) et une image officielle docker basée sur alpine. J’ai profité de l’installation d’un nouveau serveur pour déployer Traefik et c’est vraiment agréable de pouvoir déclarer dynamiquement ses containers docker. Par ailleurs, je rappelle que je maintiens des images docker de Traefik pour sa version ARM
- Docker for AWS Public Beta : l’offre Docker pour AWS passe d’une version alpha à une verion beta. On notera essentiellement qu’il s’agit d’une version plus intégrée avec l’offre AWS que si l’on déployait un docker soi-même. A suivre mais attention à vérifier qu’il n’y a pas un lock-in qui se crée à la fin, que l’intégration apporte un plus et ne nuit pas à la portabilité des containers.
Dashboard, Monitoring
- What’s new in Grafana v4.0 : la fonctionnalité phare de cette version est la capacité de définir des alertes au niveau de chaque élément d’un dashboard. Pour se faire il faut définir les règles à appliquer et ensuite s’appuyer sur la partie notification. Pour ceux qui étaient tentés d’installer Chronograf 1.1 (béta) pour avoir cet alerting en plus des dashboards adhoc de Grafana, ils pourraient bien finalement rester dans Grafana (dont la maturité n’est plus à prouver) plutôt que d’attendre que Chronograf se stabilise… A moins que Chonograf n’apporte une valeur ajoutée de part son intégration native avec Telegraf.
Pépites
- Si vous pensiez que toutes les villes commencent par une lettre, maintenant vous savez que c’est faux avec la ville de ’s_Herenelderen. Vous pouvez mettre vos regexp à jour !
- These unlucky poeple have names that break computers : même si l’article concède que ce problème est de moins en moins vrai au fur et à mesure des progrès réalisés et de la prise de conscience par les développeurs, mais s’appeller “Null” ou avoir un nom de famille très long (36 caractères dans l’exemple donné ou même 8 au Japon quand l’habitude est de 4…), cela pose des tas de problèmes dans la vie du quotidien.
