Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Ma comptabilité, une série temporelle comme les autres - partie 6 - Les FEC et le compte de résultat
warp10 timeseries comptabilité résultat fec dashboard discoverySuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512
- Partie 6 - Les FEC et le compte de résultat (ce billet)
Dans ce sixième et dernier billet pour cette série, nous continuons avec les Fichier d’Ecritures Comptables (FEC) pour produire le compte de résultat et déterminer ainsi le bénéfice de l’exercice en cours. Il faut donc prendre toutes les opérations en classe 6 (charges) et 7 (produits). Pour chaque classe de compte, il peut y avoir des crédits ou des débits (ex pour un compte de classe 7 : un avoir sur une facture émise). C’est donc un chouilla plus compliqué que le compte de trésorerie.
Depuis le dernier billet, j’ai légèrement fait évoluer le modèle de données :
- Initialement, j’avais :
<société>.<bilan ou resultat>.<classe de compte>.<type d'opération: credit ou debit> - Cela a évolué vers :
<société>.<bilan ou resultat>.<classe de compte>; le type d’opération est maintenant un label
Pour un crédit de 100€ avec une référence de pièce à 1234 pour le compte 706, on passe donc de :
<Timestamp de l'écriture comptable>// cerenit.resultat.706.credit{PieceRef=1234} 100
à :
<Timestamp de l'écriture comptable>// cerenit.resultat.706{PieceRef=1234, operation=credit} 100
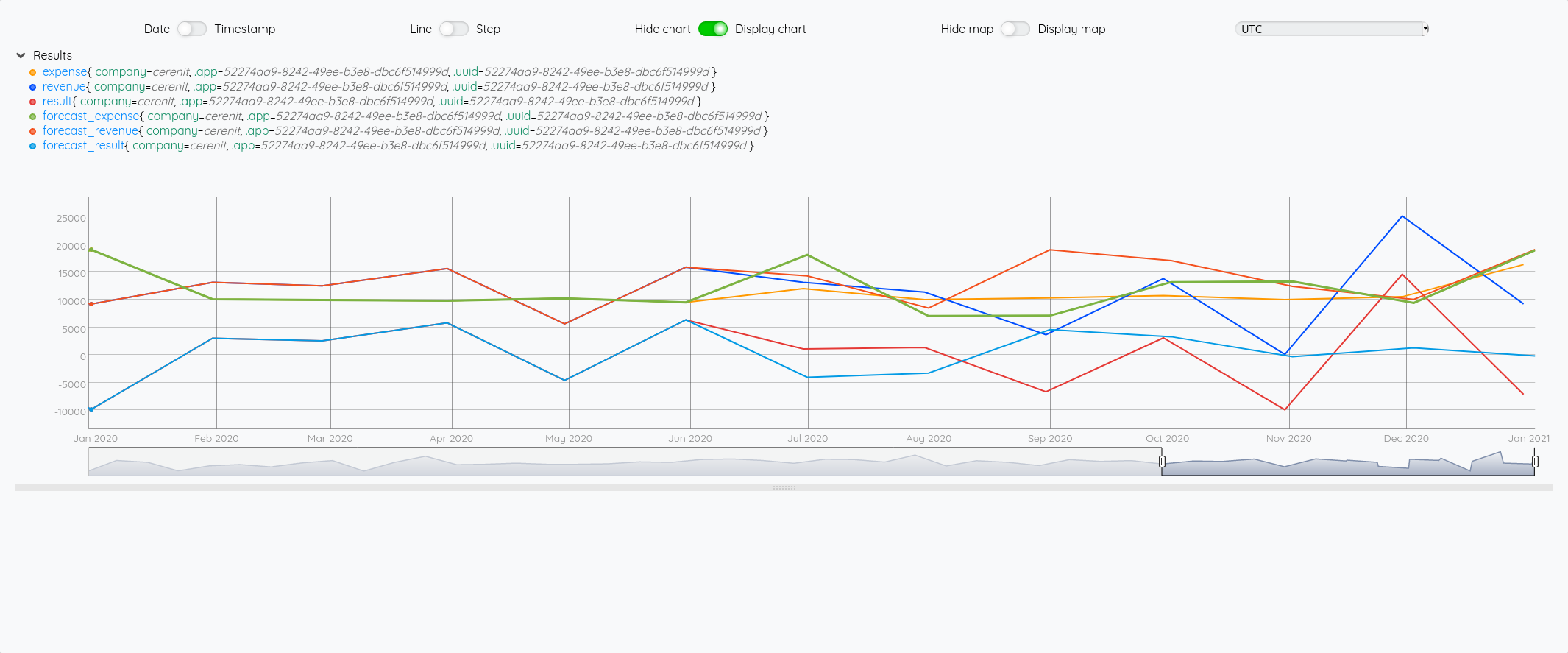
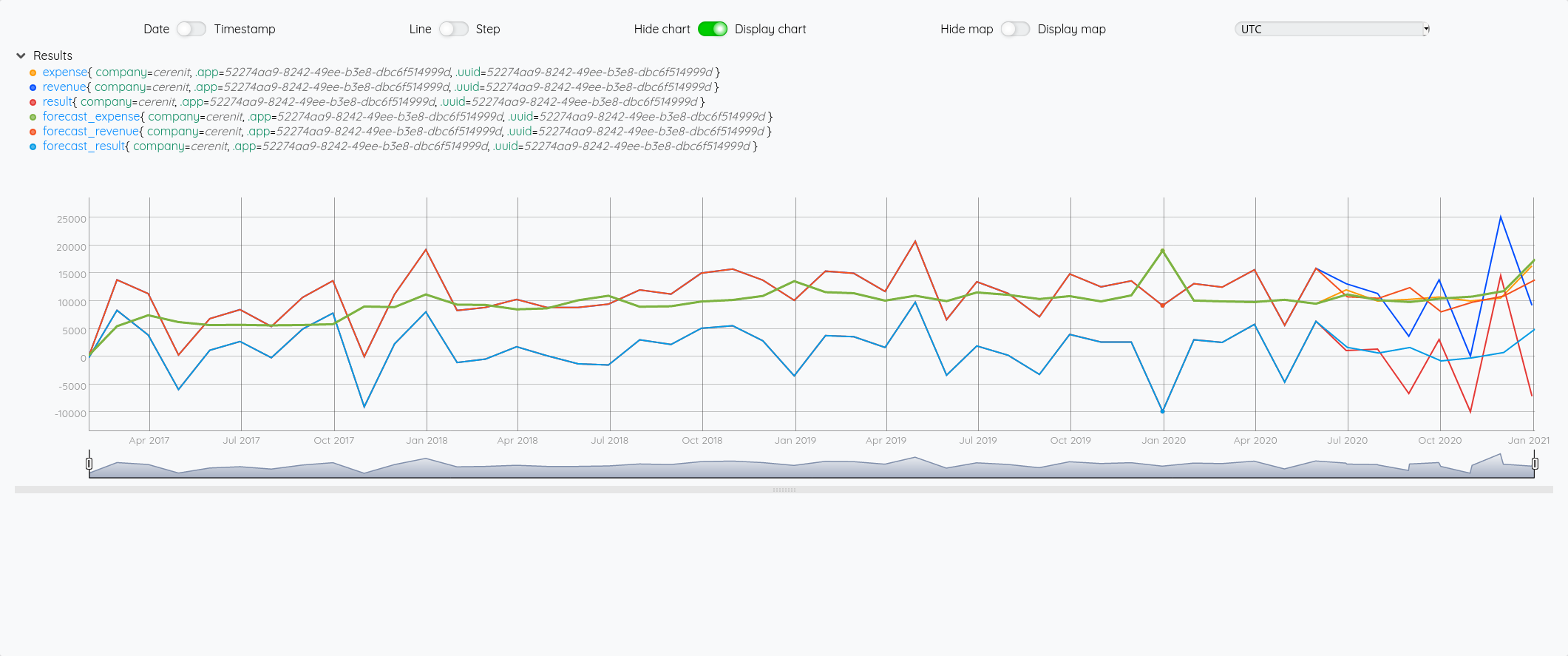
Compte de résultat
"<readToken>" "readToken" STORE
// Récupération de toutes les opérations de crédit pour les comptes charges (classe 6xx)
// Le SORT permet d'être sur d'avoir toutes les opérations triées par date
// Stockage du résultat dans une variable
[ $readToken '~comptabilite.resultat.6.*' { "operation" "credit" } '2020-01-01T00:00:00Z' '2020-12-31T23:59:59Z' ] FETCH
MERGE
SORT
'charges_credit' RENAME
'charges_credit' STORE
// Récupération de toutes les opérations de débit pour les comptes charges (classe 6xx)
// Le SORT permet d'être sur d'avoir toutes les opérations triées par date
// Stockage du résultat dans une variable
[ $readToken '~comptabilite.resultat.6.*' { "operation" "debit" } '2020-01-01T00:00:00Z' '2020-12-31T23:59:59Z' ] FETCH
MERGE
SORT
'charges_debit' RENAME
'charges_debit' STORE
// Fusion des deux listes de séries en une liste qui va avoir l'ensemble des opérations
// Les opérations de débit sont mis en valeur négative du calcul du solde
// Le SORT permet d'être sur d'avoir toutes les opérations triées par date
// Stockage du résultat dans une variable qui contient l'ensemble des opérations
[
$charges_debit -1 *
$charges_credit
] MERGE
SORT
'charges_flux' RENAME
'charges_flux' STORE
// Même opération pour les comptes de produit (7xx)
[ $readToken '~comptabilite.resultat.7.*' { "operation" "credit" } '2020-01-01T00:00:00Z' '2020-12-31T23:59:59Z' ] FETCH
MERGE
SORT
'produits_credit' RENAME
'produits_credit' STORE
[ $readToken '~comptabilite.resultat.7.*' { "operation" "debit" } '2020-01-01T00:00:00Z' '2020-12-31T23:59:59Z' ] FETCH
MERGE
SORT
'produits_debit' RENAME
'produits_debit' STORE
[
$produits_debit -1 *
$produits_credit
] MERGE
SORT
'produits_flux' RENAME
'produits_flux' STORE
// Fusion des 2 flux d'opérations (charges et produits) pour avoir une vision temporelle de ces opérations
// Le SORT permet d'être sur d'avoir toutes les opérations triées par date
// Renommage de la série en "compte_resultat" qu'elle va permettre de batir
// Somme cumulée de l'ensemble des opérations pour avoir un solde à date
// Stockage sous la forme d'une variable
// Affichage de la variable
[
$produits_flux
$charges_flux
] MERGE
SORT
'compte_resultat' RENAME
[ SWAP mapper.sum MAXLONG 0 0 ] MAP
'compte_resultat' STORE
$compte_resultat
Ce qui nous donne dans le Studio :
Du précédent billet et ce celui-ci, nous avons donc :
- Un compte de résultat annuel
- Un compte de trésorerie annuel
Tout ce qu’il faut donc pour faire un dashboard avec Discovery. Il faut dire que le billet Covid Tracker built with Warp 10 and Discovery et dans une moindre mesure Server monitoring with Warp 10 and Telegraf donnent accès à plein d’options pour réaliser ses dashboards.
Macros
Je pourrais mettre le code de mes requêtes directement dans les dashboards mais j’aime pas trop quand des tokens se balladent dans les pages web. Du coup, je vais déporter le code dans des macros. J’ai églément rendu les macro dynamiques dans le sens où elles prennent une année en paramètre pour afficher les données de l’année en question.
On a déjà vu le fonctionnement des macros précédemment, je ne reviendrais donc pas dessus.
La macro du compte de résultat à titre d’exemple :
<%
{
'name' 'cerenit/accountancy/compte-resultat'
'desc' 'Function to calculate the cumulative benefit (or loss) of the company'
'sig' [ [ [ [ 'year:LONG' ] ] [ 'result:GTS' ] ] ]
'params' {
'year' 'Year, YYYY'
'result' 'GTS'
}
'examples' [
<'
2020 @cerenit/accountancy/compte-resultat
'>
]
} INFO
// Actual code
SAVE 'context' STORE
TOLONG // When called from dashboard, it's a string - so convert paramter to LONG first
'year' STORE // Save parameter as year
// Compute 1st Jan of given year
[ $year 01 01 ] TSELEMENTS-> ISO8601
'start' STORE
// Compute 31 Dec of given year
[ $year 12 31 23 59 59 ] TSELEMENTS-> ISO8601
'end' STORE
"<readToken>" "readToken" STORE
[ $readToken '~comptabilite.resultat.6.*' { "operation" "credit" } $start $end ] FETCH
MERGE
SORT
'charges_credit' RENAME
'charges_credit' STORE
[ $readToken '~comptabilite.resultat.6.*' { "operation" "debit" } $start $end ] FETCH
MERGE
SORT
'charges_debit' RENAME
'charges_debit' STORE
[
$charges_debit -1 *
$charges_credit
] MERGE
SORT
{ NULL NULL } RELABEL
'charges_flux' RENAME
'charges_flux' STORE
[ $readToken '~comptabilite.resultat.7.*' { "operation" "credit" } $start $end ] FETCH
MERGE
SORT
'produits_credit' RENAME
'produits_credit' STORE
[ $readToken '~comptabilite.resultat.7.*' { "operation" "debit" } $start $end ] FETCH
MERGE
SORT
'produits_debit' RENAME
'produits_debit' STORE
[
$produits_debit -1 *
$produits_credit
] MERGE
SORT
{ NULL NULL } RELABEL
'produits_flux' RENAME
'produits_flux' STORE
[
$produits_flux
$charges_flux
] MERGE
SORT
'compte_resultat' RENAME
[ SWAP mapper.sum MAXLONG 0 0 ] MAP
'compte_resultat' STORE
$compte_resultat
$context RESTORE
%>
'macro' STORE
$macro
Comme le décrit l’exemple, si on veut le compte de résultat de l’année 2020, on utilisera le code suivant :
2020 @cerenit/accountancy/compte-resultat
J’ai profité de ce billet pour utiliser Warpfleet Synchronizer & Warpfleet Resolver pour simplifier le déploiement des macros ; cela explique que les signatures pour appeler les macros changent par la suite dans le dashboard.
Dashboards
Ci-après le code du dashboard :
<%
{
'title' 'Comptabilité CérénIT'
'description' 'Trésorerie et compte de résultat'
'vars' {
'myYear' 2020
}
'tiles' [
{
'title' 'Informations'
'type' 'display'
'w' 11 'h' 1 'x' 0 'y' 0
'data' {
'data' 'Résultat de la série <a href="https://www.cerenit.fr/blog/premiers-pas-avec-warp10-comptabilite-et-previsions/">Ma comptabilité, une série temporelle comme les autres</a> et de l'ingestion des Fichiers d'écritures comptables.'
'globalParams' { 'timeMode' 'custom' }
}
}
{
'title' 'Année'
'type' 'input:list'
'w' 1 'h' 1 'x' 11 'y' 0
'data' {
'data' [ '2017' '2018' '2019' '2020' ]
'events' [ { 'type' 'variable' 'tags' 'year' 'selector' 'myYear' } ]
'globalParams' { 'input' { 'value' '2020' } }
}
}
{
'title' 'Trésorerie (annuel)'
'type' 'line'
'w' 6 'h' 2 'x' 0 'y' 1
'macro' <% $myYear @cerenit/macros/treso %>
'options' { 'eventHandler' 'type=(variable),tag=year' }
}
{
'title' 'Compte de résultat (annuel)'
'type' 'line'
'w' 6 'h' 2 'x' 6 'y' 1
'macro' <% $myYear @cerenit/macros/compteresultat %>
'options' { 'eventHandler' 'type=(variable),tag=year' }
}
{
'title' 'Trésorerie (pluri-annuelle)'
'type' 'line'
'w' 12 'h' 2 'x' 0 'y' 3
'macro' <% [ 2017 $myYear ] @cerenit/macros/treso_multi %>
'options' { 'eventHandler' 'type=(variable),tag=year' }
}
]
}
{ 'url' 'https://w.ts.cerenit.fr/api/v0/exec' }
@senx/discovery2/render
%>
et son rendu :
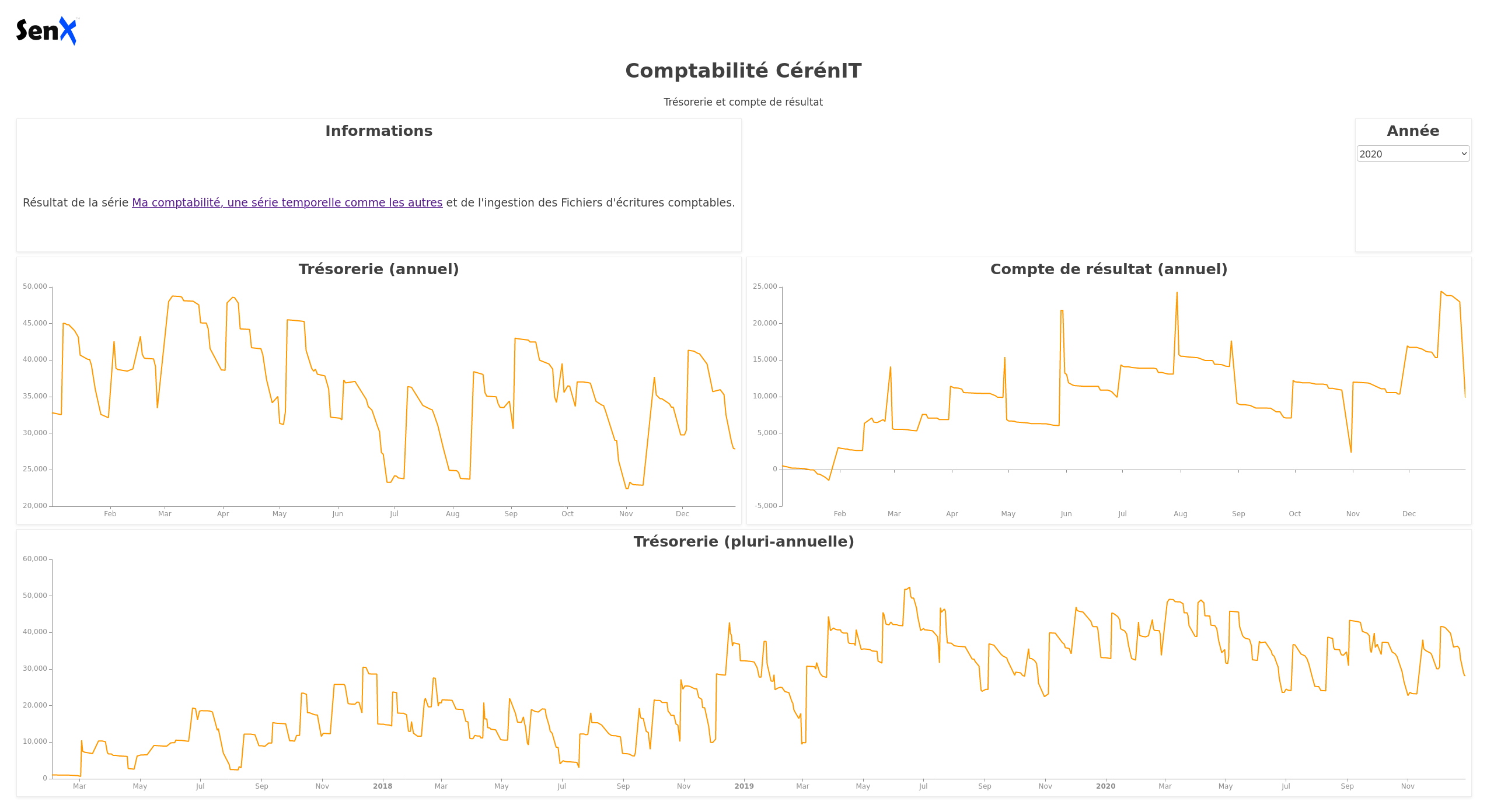
Dans le bloc global du dashboard, on définir une variable myYear, initialisée à 2020. Cette variable est mise à jour dynamiquement lorsque l’on choisit une valeur dans la liste déroulante du bloc “Année”.
<%
{
'title' 'Comptabilité CérénIT'
'description' 'Trésorerie et compte de résultat'
'vars' {
'myYear' 2020
}
...
Le bloc Année justement :
{
'title' 'Année'
'type' 'input:list'
'w' 1 'h' 1 'x' 11 'y' 0
'data' {
'data' [ '2017' '2018' '2019' '2020' ]
'events' [ { 'type' 'variable' 'tags' 'year' 'selector' 'myYear' } ]
'globalParams' { 'input' { 'value' '2020' } }
}
}
C’est une liste déroulante (type: input:list) avec pour valeurs les années 2017 à 2020. Par défaut, elle est initialisée à 2020. Via le mécanisme des “events”, lorsqu’une valeur est choisie, celle-ci est émise sous la forme d’une variable, nommée myYear et ayant pour tag la valeur year.
Ainsi, si je sélectionne 2017 dans la liste, la variable myYear prendra cette valeur. Maintenant que la valeur est définie suite à mon choix et émise vers le reste du dashboard, il faut que les autres tiles récupèrent l’information.
Regardons le tile Trésorerie :
{
'title' 'Trésorerie (annuel)'
'type' 'line'
'w' 6 'h' 2 'x' 0 'y' 1
'macro' <% $myYear @cerenit/macros/treso %>
'options' { 'eventHandler' 'type=(variable),tag=year' }
}
La récupération de la variable se fait via la proriété options et la récupération de l’eventHandler associé et défini précédemment.
Une fois récupérée, la variable myYear peut être utilisée dans le bloc macro et le tile est mis à jour dynamiquement.
En conséquence :
- Les deux premiers tiles afficheront le solde de trésorerie et le compte de résultat de l’année sélectionnée
- Le dernier tile affichera la trésorerie depuis début 2017 jusqu’à la fin d’année sélectionnée. Donc au minimum 2017 et au maximum 2017 > 2020.
Ainsi s’achève cette série sur les données comptable et les séries temporelles. Des analyses complémentaires pourraient être menées (analyse de stocks, réparition d’activité, etc) mais mes données comptables sont insuffisantes pour en valoir l’intérêt. J’espère néanmoins que cela aura sucité votre intérêt et ouvert des horizons.
Cette série fut aussi l’occasion de faire un tour de la solution Warp 10 et de voir :
- l’ingestion de données,
- la manipulation et l’analyse des données,
- la mise en place de dashboards,
- la projection de données avec les algorythmes de machine learning.
Si vous souhaitez poursuivre l’aventure et le sujet, n’hésitez pas à me contacter.
Ma comptabilité, une série temporelle comme les autres - partie 5 - Les FEC et le compte 512
warp10 timeseries comptabilité trésorerie banque fecSuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512 (ce billet)
- Partie 6 - Les FEC et le compte de résultat
Dans ce cinquième billet, nous allons parler de Fichier d’Ecritures Comptables (FEC) et d’un compte simple à analyser : le compte 512 qui correspond à votre compte en banque.
Le Fichier des Ecritures Comptables (FEC)
Le Fichier des Ecritures Comptables (FEC) est un format de fichier normalisé. Sa spécification est disponible et grosso modo, ce qu’il faut en savoir à ce stade :
- C’est un fichier TSV (un CSV avec les champs séparés par des tabulations)
- Il contient 18 champs permettant de décrire les différentes écritures comptables :
- JournalCode
- JournalLib
- EcritureNum
- EcritureDate
- CompteNum
- CompteLib
- CompAuxNum
- CompAuxLib
- PieceRef
- PieceDate
- EcritureLib
- Debit
- Credit
- EcritureLet
- DateLet
- ValidDate
- Montantdevise
- Idevise
En partant de ces informations et après quelques précisions fournies par mon expert-comptable Fabrice Heuvrard sur le fichier, nous avons convenu de commencer par l’analyse du compte 512 correspondant aux opérations bancaires. Facile à calculer (somme des crédits - somme des débits) et facile à vérifier, il me suffit de regarder mon compte en banque et/ou mon bilan en fin d’année.
Continuant à utiliser Warp 10 pour y stocker mes séries temporelles, j’ai réalisé un script en Go qui prend le fichier FEC en entrée et envoie les données dans Warp 10 avec le formalisme suivant : <société>.<bilan ou resultat>.<classe de compte>.<type d'opération: credit ou debit> :
<société>est juste le début de l’arborescence<bilan ou résultat>: le Plan Comptable Général Francais défini que si les comptes de classe 1 à 5 sont des classes de bilan et les classes 6 et 7 sont des classes de compte de résultat. Je suis donc le même principe de séparation des comptes et défiinr la valeurbilanetresultat. Le compte 512 que nous allons étudier commençant par 5, c’est un compte de bilan. Il sera donc dans la sériecerenit.bilan.*<classe de compte>: le plan comptable général est normalisé sur ces trois premiers chiffres. Les trois suivants sont à la discrétion du comptable. Du coup, pour ne pas avoir une série par code comptable, je retrouve par classe du plan de compte. Ainsi, toutes les opérations ayant le code512xxxse retrouvera dans la sériecerenit.bilan.512.*<type d'opération: crédit ou débit> : suivant si l’opération est un débit ou crédit, cela prend la valeur adéquat. Ainsi, toutes les opérations ayant le code512xxxse retrouvera dans la sériecerenit.bilan.512.creditou ``cerenit.bilan.512.debit`- Le montant de l’écriture comptable sera la valeur associée à mon point dans la série.
- Les autres informations seront mises sous la forme de labels (ie meta données de mon point) pour d’éventuelles analyses ultérieures. Il s’agit de couple clé/valeurs.
Ainsi, un crédit de 100€ avec une référence de pièce à 1234 sera représenté sous la forme :
<Timestamp de l'écriture comptable>// cerenit.bilan.512.credit{PieceRef=1234} 100
La modélisation est peut être un peu naive à ce stade, il sera toujours temps de la faire évoluer dans un second temps mais a priori :
- J’ai ma séparation bilan / compte de résultat
- J’ai ma séparation par classe de compte
- J"ai ma séparation débit / crédit
- au pire via les labels, j’ai des axes complémentaires de recherche / sélection.
Contrôle des données
Avant de commencer la moindre analyse, j’ai voulu vérifier l’intégrité de mes données.
"<readToken>" "readToken" STORE
// Récupération des données de 2020 pour le compte 512
[ $readToken 'cerenit.bilan.512.credit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
// Fusion de l'ensemble des séries temporelles en une seule série
MERGE
// Calcul de la somme de l'ensemle des valeurs de la séries -
// MAXLONG permet de tout récupérer sans calculer la taille exacte de la liste (pour peu que votre liste soit plus petite que la valeur de MAXLONG)
// 1 permet de ne sortir qu'une valeur en sortie
[ SWAP mapper.sum MAXLONG MAXLONG 1 ] MAP
// C'est une liste avec une liste à 1 élément, on "applatit" tout ça
MERGE
VALUES
0 GET
// On stocke la valeur finale dans totalCredit
'totalCredit' STORE
// Même opération sur les débits
[ $readToken 'cerenit.bilan.512.debit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
[ SWAP mapper.sum MAXLONG MAXLONG 1 ] MAP
MERGE
VALUES
0 GET
'totalDebit' STORE
// Calcul du solde
$totalCredit $totalDebit -
Cela me donne : 27746.830000000075
Exploration de la trésorerie
"<readToken>" "readToken" STORE
// Récupération des données de 2020 pour le compte 512
[ $readToken 'cerenit.bilan.512.credit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
// Fusion de l'ensemble des séries temporelles en une seule série
MERGE
// Tri des points par date
SORT
// Renommage de la série
'credit' RENAME
// Suppression des labels
{ NULL NULL } RELABEL
// Stockage dans une variable
'credit' STORE
// Même opération sur les débits
[ $readToken 'cerenit.bilan.512.debit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
SORT
'debit' RENAME
{ NULL NULL } RELABEL
'debit' STORE
// Affichage des deux séries
$credit
$debit
// Création de la série de mouvements
$credit $debit -
'mouvements' RENAME
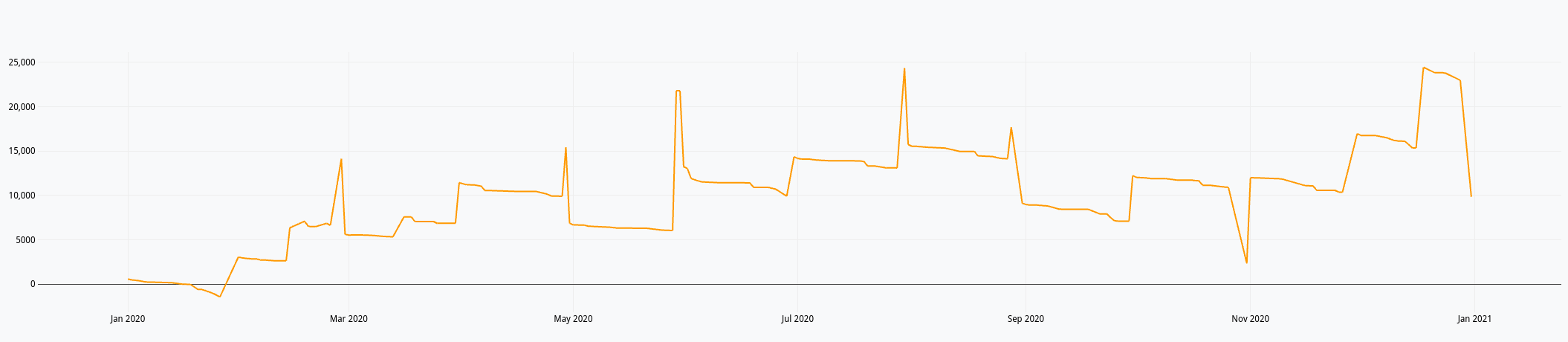
Cela nous donne ces courbes:
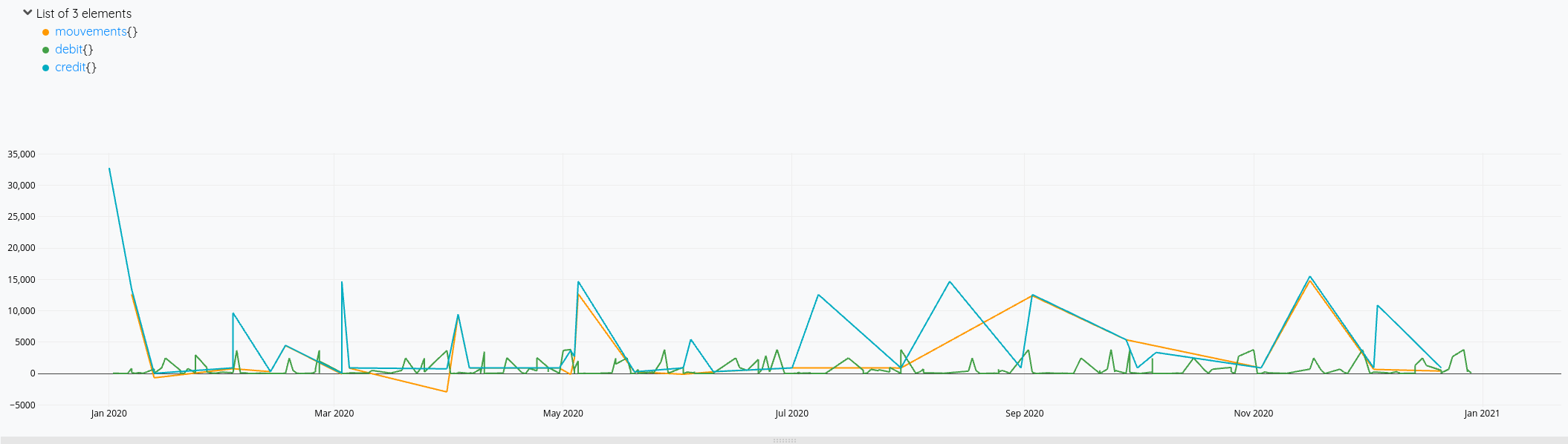
Mais on voit bien à fin décembre qu’il y a des opérations de débit qui ne sont pas prises en compte dans le solde (la ligne orange s’arrête avant la verte).
En cherchant un peu, je me dis qu’il faudrait que je calcule une nouvelle série avec tous les éléments de crédit et débit et faire l’addition de tout cela. Je vois également que FLATTEN (doc)permet de fusionner plusieurs listes en une seule. Mais finalement, seul MERGE sera nécessaire.
Cela me donne la piste suivante :
"<readToken>" "readToken" STORE
// Récupération des données de 2020 pour le compte 512
[ $readToken 'cerenit.bilan.512.credit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
SORT
'credit' RENAME
{ NULL NULL } RELABEL
'credit' STORE
// Même opération sur les débits
[ $readToken 'cerenit.bilan.512.debit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
SORT
'debit' RENAME
{ NULL NULL } RELABEL
// Je multiplie les debits par -1 pour pouvoir faire l'opération de solde ensuite
[ SWAP -1 mapper.mul 0 0 0 ] MAP
'debit' STORE
// Je fusionne les deux séries avec MERGE
[
$credit
$debit
] MERGE
// Je trie les éléments par date
SORT
'mouvements' RENAME
Cette fois-ci, mon solde prend bien en compte toutes les opérations de l’année.
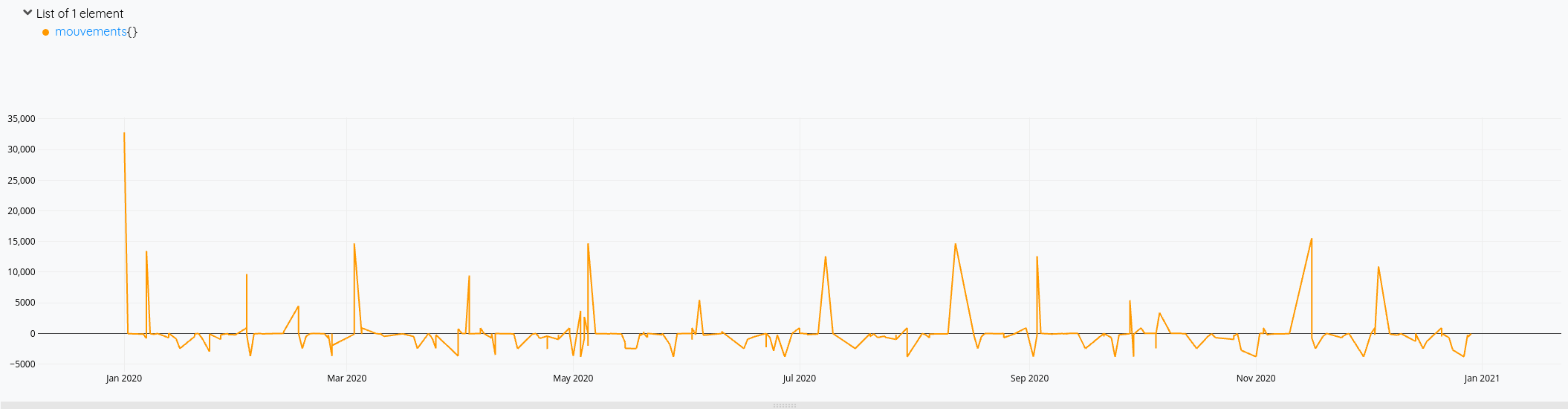
Pour la version consolidée avec le solde du compte :
// Récupération des données de 2020 pour le compte 512
[ $readToken 'cerenit.bilan.512.credit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
SORT
'credit' RENAME
{ NULL NULL } RELABEL
'credit' STORE
// Récupération des données de 2020 pour le compte 512
[ $readToken 'cerenit.bilan.512.debit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
SORT
'debit' RENAME
{ NULL NULL } RELABEL
-1 *
'debit' STORE
// Fusion des débits/crédits comme vu précédemment
[
$credit
$debit
] MERGE
SORT
'mouvements' RENAME
// On applique mapper.sum sur l'ensemble des points précédents le point qui est considéré
// Le premier point ne va donc prendre que lui même
// Le 2nd point va prendre sa valeur et ajouter celle du précédédent
// Le 3ème point va prendre sa valeur et la somme des points précédents
// Et ainsi de quiste
[ SWAP mapper.sum MAXLONG 0 0 ] MAP
Et le résultat en images :
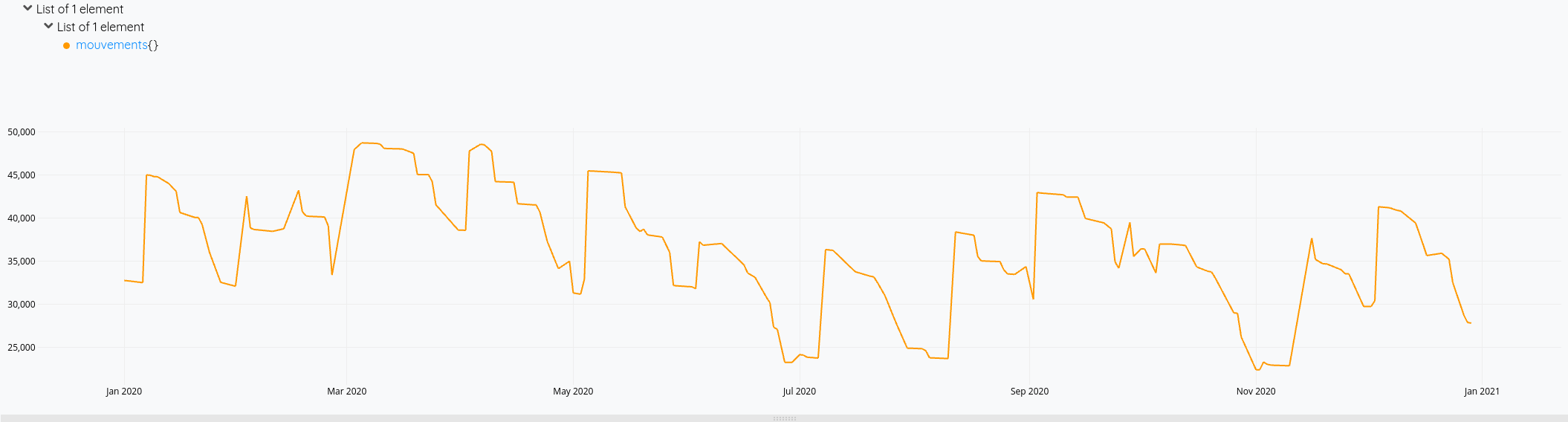
Et voilà !
Il ne me reste plus qu’à :
- ingérer les FEC des autres années pour envisager des comparaisons entre les différents exercices comptables, voire du prédictif pour l’exercice en cours et à venir,
- étendre ces analyses à d’autres comptes maintenant,
- et à créer les dashboards adéquats avec Discovery.
Ma comptabilité, une série temporelle comme les autres - partie 4 - dashboards
warp10 timeseries comptabilité discovery dashboardSuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale
- Partie 4 - Dashboards (ce billet)
- Partie 5 - Les FEC et le compte 512
- Partie 6 - Les FEC et le compte de résultat
Nous allons voir aujourd’hui comment présenter ces données à l’aide de Discovery, la solution de Dashboard as Code pour Warp 10 fournie par SenX.
Installation de Discovery
Tout est décrit dans le billet Truly Dynamic Dashboards as Code
Dans mon cas, warp 10 est dans une partition dédiée /srv/warp10 - warp 10 est donc installé dans /srv/warp10/warp10. C’est la valeur de $WARP10_HOME.
Pour la configuration du plugin HTTP, j’ai un fichier $WARP10_HOME/etc/conf.d/80-discovery.conf contenant :
# Load the HTTP Plugin
warp10.plugin.http = io.warp10.plugins.http.HTTPWarp10Plugin
# Define the directory where endpoint spec files will reside
http.dir = /srv/warp10/discovery
# Define the host and port the plugin should bind to
http.host = 127.0.0.1
http.port = 8081
# Expose the Directory and Store so FETCH requests can be performed via the plugin
egress.clients.expose = true
Le plugin HTTP sera donc accessible via une url de base en http://127.0.0.1:8081/
J’ai ensuite créé le fichier /srv/warp10/discovery/discovery.mc2 où /srv/warp10/discovery est la valeur associée à http.dir dans le fichier précédent.
{
'path' '/discovery/'
'prefix' true
'parsePayload' true
'macro' <%
'cerenit/dashboards/' @senx/discovery/dispatcher
%>
}
Ce fichier indique que :
- Les dashboards seront disponibles à partir de l’url
/discovery/<nom_du_dashboard>ou/discovery/<dossier_ou_arborescence>/<nom_du_dashboard> - Le dossier où seront les dashboards seront stockés dans
$WARP10_HOME/macros/cerenit/dashboards. Il s’agira de fichier WarpScript ou Flows avec l’extension en.mc2.
Avec ces deux fichiers, nous savons maintenant que :
- nous accèderons aux dashboards via
http://127.0.0.1:8081/discovery/<nom_du_dashboard>. - les dashboards seront des fichiers stockés dans ``$WARP10_HOME/macros/cerenit/dashboards`
- donc le dashboard
$WARP10_HOME/macros/cerenit/dashboards/mon_dashboard.mc2sera accessible viahttp://127.0.0.1:8081/discovery/mon_dashboard.
Création du premier dashboard
Un dashboard se décompose en différentes parties. Celle contenant les données a le mot clé tiles et contient différente tile. Chaque tile affiche un graphique, un zone de texte, un titre ou tout composant warpView. Pour le reste, on s’appuiera sur le template par défaut.
Donc créeons un fichier $WARP10_HOME/macros/cerenit/dashboards/comptabilite/compta1.mc2 contenant :
<%
{
'tiles' [
{
'type' 'display'
'w' 4 'h' 1 'x' 3 'y' 0
'data' 'Compta - Exemple 1'
}
{
'type' 'line'
'w' 4 'h' 2 'x' 1 'y' 3
'data' [
@cerenit/accountancy/revenue
'revenue' STORE
$revenue
]
}
{
'type' 'line'
'w' 4 'h' 2 'x' 5 'y' 3
'data' [
@cerenit/accountancy/expense
'expense' STORE
$expense
]
}
{
'type' 'line'
'w' 4 'h' 2 'x' 3 'y' 5
'data' [
$revenue $expense -
]
}
]
}
@senx/discovery/render
%>
Comme indiqué précédemment, je me focalise sur le contenu de tiles. La grille de présentation des dashboards est fixé à 12 colonnes par défaut.
Ici, je cherche donc à afficher 4 éléments :
- Le premier élément est un bloc titre, contenant “Compta - Exemple 1”. Il est placé sur la 3ème item de la grille en parant de la gauche (valeur de x), il est en haut (valeur y de 0) et il occupe une largeur de 4 (valeur de w) et une hauteur de 1 (valeur de h),
- les trois éléments suivants sont des graphiques de tyme “line” avec un positionnement pour deux les deux premiers soient sur une ligne et le dernier en dessous et plutôt centré par rapport aux deux premmiers.
- le deuxième et troisième éléments font appels à des macros
@cerenit/accountancy/xxx. Je pourrais mettre du code Warpscript directement dans le fichier comme dans l’exemple. Toutefois, le code exécuté dans le dashboard est visible dans le navigateur. Dans la mesure où mes requêtes pour récupérer les données demandent de l’authentification avec un passage de token, je déporte ce code dans une macro et je ne fais donc qu’appeler cette macro. Ainsi, le code sera généré coté serveur et seul le résultat sera retourné dans le navigateur. - le dernier élement illustre la capacité intéressante et différentiante de Discovery : on ne fait pas que décrire le dashboard avec du code, on peut aussi faire des opérations sur nos données. Ici je calcule dynamiquement le résultat à partir des données de chiffre d’affaires (revenue) et de dépenses (expense). J’aurais pu faire l’appel à une troisième macro comme les deux éléments précédents, mais vu que j’ai cette capacité de réaliser des opérations au sein d’un dashboard, pourquoi me priver ?
- enfin, on appelle la fonction
@senx/discovery/renderpour générer le dashboard.
Revenons sur nos macros ; Warp 10 permet d’avoir des macros exécutées coté serveur. Ces macros peuvent être utiles pour créer/partager du code, elles peuvent prendre des paramètres en entrée si besoin et elles sont exécutées coté serveur. Dans notre cas, pour éviter que nos tokens se balladent dans le navigateur comme indiqué précédemment, c’est cette propriété qui va nous intéresser.
La macro @cerenit/accountancy/revenue se trouve donc dans le fichier $WARP10_HOME/macros/cerenit/accountancy/revenue.mc2 et contient :
<%
{
'name' 'cerenit/accountancy/revenue'
'desc' 'Provide revenue'
} INFO
// Actual code
SAVE 'context' STORE
'<readToken>' 'readToken' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } NOW [ 2016 12 1 ] TSELEMENTS-> ] FETCH
0 GET
$context RESTORE
%>
'macro' STORE
$macro
Je ne vais pas m’étendre sur la rédaction des macros mais succintement :
- Le permier bloc donne le nom de la macro et sa description
- La suite indique le code qui va être réalisé - pour ma part, un FETCH sur la classe “revenue” pour la compagny “cerenit” du 01/12/2016 jusqu’à maintenant. Cette liste n’a qu’un élément que je récupère. C’est ce qui me sera retourné.
La macro @cerenit/accountancy/expense est sur le même modèle en remplaçant revenue par expense.
Ces deux macros nous retournent donc chacune une série temporelle sur la période 12/2016 jusqu’à ce jour : une pour le chiffre d’affaires, une pour les dépenses.
Si vous allez sur http://127.0.0.1:8081/discovery/comptabilite/compta1, vous verrez le dashboard suivant :
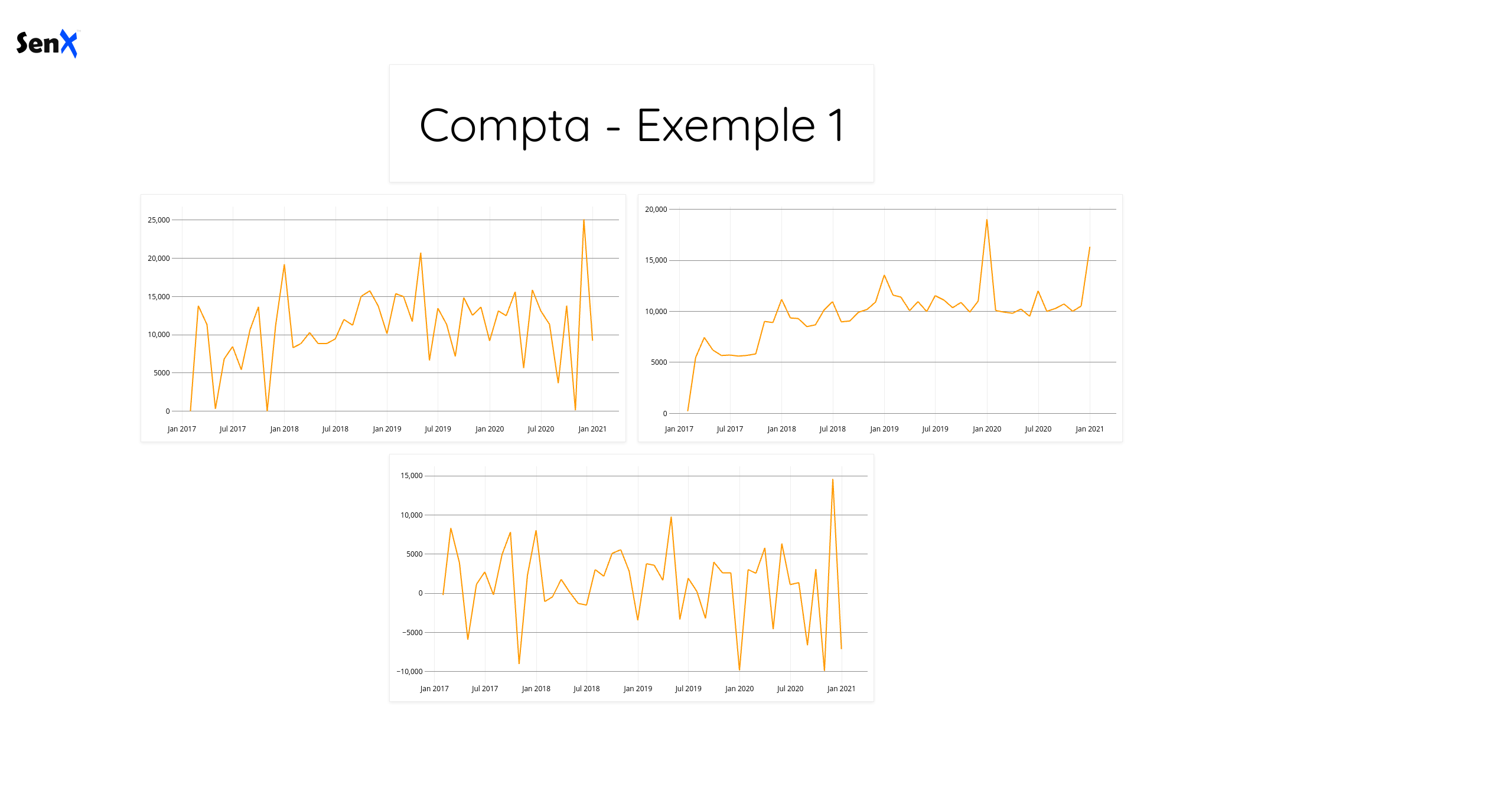
Le template par défaut est assez minimaliste et on note la présence d’un logo SenX. Je n’ai rien contre, mais comme c’est la compatabilité de mon entreprise que je présente, autant changer cet aspect des choses.
Ajustements graphiques
Pour continuer progressivement, nous allons :
- Rajouter un titre et une description à notre dashboard en précisant les propriétés
titleetdescriptionen début de fichier - Rajouter un footer en bas de page en précisant la propriété
footer - Supprimer le logo SenX en précisant la propriété
template - Ajuster la position des blocs pour qu’ils soient centrés comme le reste des éléments
On met cela dans un nouveau fichier $WARP10_HOME/macros/cerenit/dashboards/comptabilite/compta2.mc2.
<%
{
'title' 'Comptabilité CerenIT'
'description' 'Comptabilité CérénIT depuis 2016'
'tiles' [
{
'type' 'display'
'w' 4 'h' 1 'x' 4 'y' 0
'data' 'Compta - Exemple 2'
}
{
'title" "Chiffre d'affaires'
'type' 'line'
'w' 4 'h' 2 'x' 2 'y' 3
'data' [
@cerenit/accountancy/revenue
'revenue' STORE
$revenue
]
}
{
'title' 'Dépenses'
'type' 'line'
'w' 4 'h' 2 'x' 6 'y' 3
'data' [
@cerenit/accountancy/expense
'expense' STORE
$expense
]
}
{
'title' 'Résultat'
'type' 'line'
'w' 4 'h' 2 'x' 4 'y' 5
'data' [
$revenue $expense -
]
}
]
'footer' '<p style="text-align: center;">CérénIT © 2021 - Réalisé avec Discovery et Warp 10 de SenX</p>'
'template'
<'
<!DOCTYPE html><html><head><title id="pageTitle"></title>
{{{CSS}}}
{{{HEAD}}}
</head>
<body>
<div class="heading">
<div class="header"><h1 id="title" class="discovery-title"></h1><p id="desc" class="discovery-description"></p></div>
</div>
{{{HEADER}}}
{{{GRID}}}
{{{FOOTER}}}
{{{JS}}}
</body></html>
'>
}
@senx/discovery/render
%>
Si les propriétés title, description et footer vont de soi, pour trouver comment supprimer le logo SenX, il m’a fallu lire le contenu de la macro @senx/discovery/html pour mieux comprendre les différents placehoders et leur fonctionnement.
Si vous allez sur http://127.0.0.1:8081/discovery/comptabilite/compta2, vous verrez le dashboard suivant :
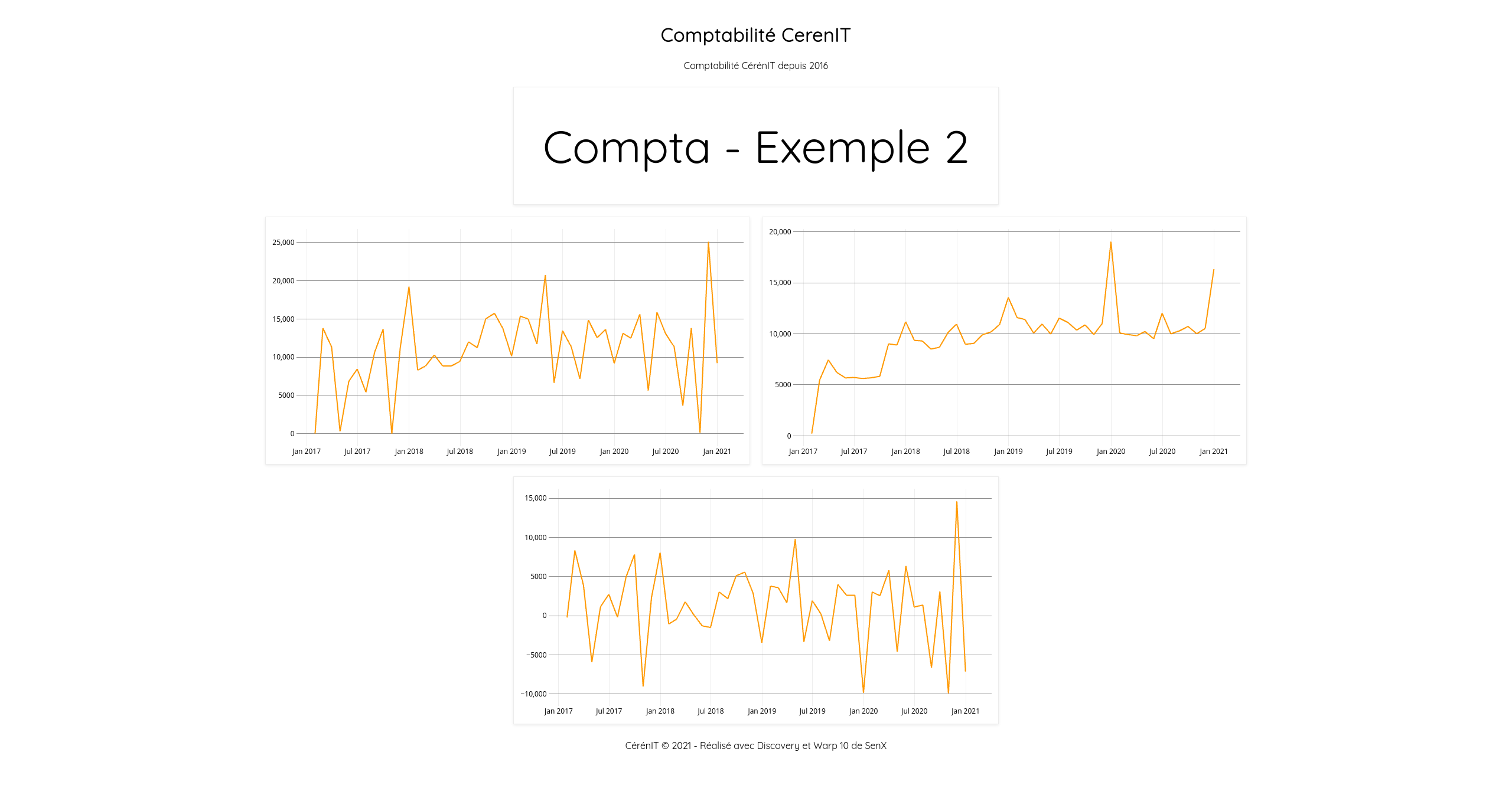
A ce stade, on note que les propriétés title de chaque graphique n’est pas affiché. En dehors de ça, nous retrouvons bien tous nos éléments ajustés.
Néanmoins, cette lecture de @senx/discovery/html permet de voir que l’on a pas mal de points d’entrée pour rajouter des éléments spécifiques. Le tout sera de veiller à ne pas impacter les composants graphiques WarpView dans leur sémantique pour ne pas créer de dysfonctionnement.
Un petit coup de bar(re)
Pour finir ce tutoriel, nous allons :
- lisser un peu ces lignes d’une part, en remplaçant le type de
lineàsplinepour les trois graphiques déjà réalisés (pour les autres modes de réprésentation, voir les options de chart) - rajouter un histogramme avec le cumul annuel de nos données avec un chart de type
bar.
On met cela dans un nouveau fichier $WARP10_HOME/macros/cerenit/dashboards/comptabilite/compta3.mc2.
<%
{
'title' 'Comptabilité CerenIT'
'description' 'Comptabilité CérénIT depuis 2016'
'tiles' [
{
'type' 'display'
'w' 4 'h' 1 'x' 4 'y' 0
'data' 'Compta - Exemple 3'
}
{
'title' 'Chiffre d\'affaires'
'type' 'spline'
'w' 4 'h' 2 'x' 2 'y' 3
'data' [
@cerenit/accountancy/revenue
'revenue' STORE
$revenue
]
}
{
'title' 'Dépenses'
'type' 'spline'
'w' 4 'h' 2 'x' 6 'y' 3
'data' [
@cerenit/accountancy/expense
'expense' STORE
$expense
]
}
{
'title' 'Résultat'
'type' 'spline'
'w' 4 'h' 2 'x' 4 'y' 5
'data' [
$revenue $expense -
]
}
{
'title' 'Consolidation annuelle'
'type' 'bar'
'w' 4 'h' 2 'x' 4 'y' 7
'data' [
[ $revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ @cerenit/accountancy/result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
]
'options' { 'timeMode' 'timestamp' }
}
]
'footer' '<p style="text-align: center;">CérénIT © 2021 - Réalisé avec Discovery et Warp 10 de SenX</p>'
'template'
<'
<!DOCTYPE html><html><head><title id="pageTitle"></title>
{{{CSS}}}
{{{HEAD}}}
</head>
<body>
<div class="heading">
<div class="header"><h1 id="title" class="discovery-title"></h1><p id="desc" class="discovery-description"></p></div>
</div>
{{{HEADER}}}
{{{GRID}}}
{{{FOOTER}}}
{{{JS}}}
</body></html>
'>
}
@senx/discovery/render
%>
Pour ce dernier graphique, il est donc de type bar. Pour le détail des requêtes, je vous renvoie à la partie 2 qui explique cela. Dans notre cas, il faut juste veiller à passer une option supplémentaires pour que timeMode interprête la date issue de la requête comme un timestamp et non comme une date par défaut. D’autres options comme la gestion de la présentation en mode vertical/horizontal ou en mode “stacked” ou pas.
Si vous allez sur http://127.0.0.1:8081/discovery/comptabilite/compta3, vous verrez le dashboard suivant :
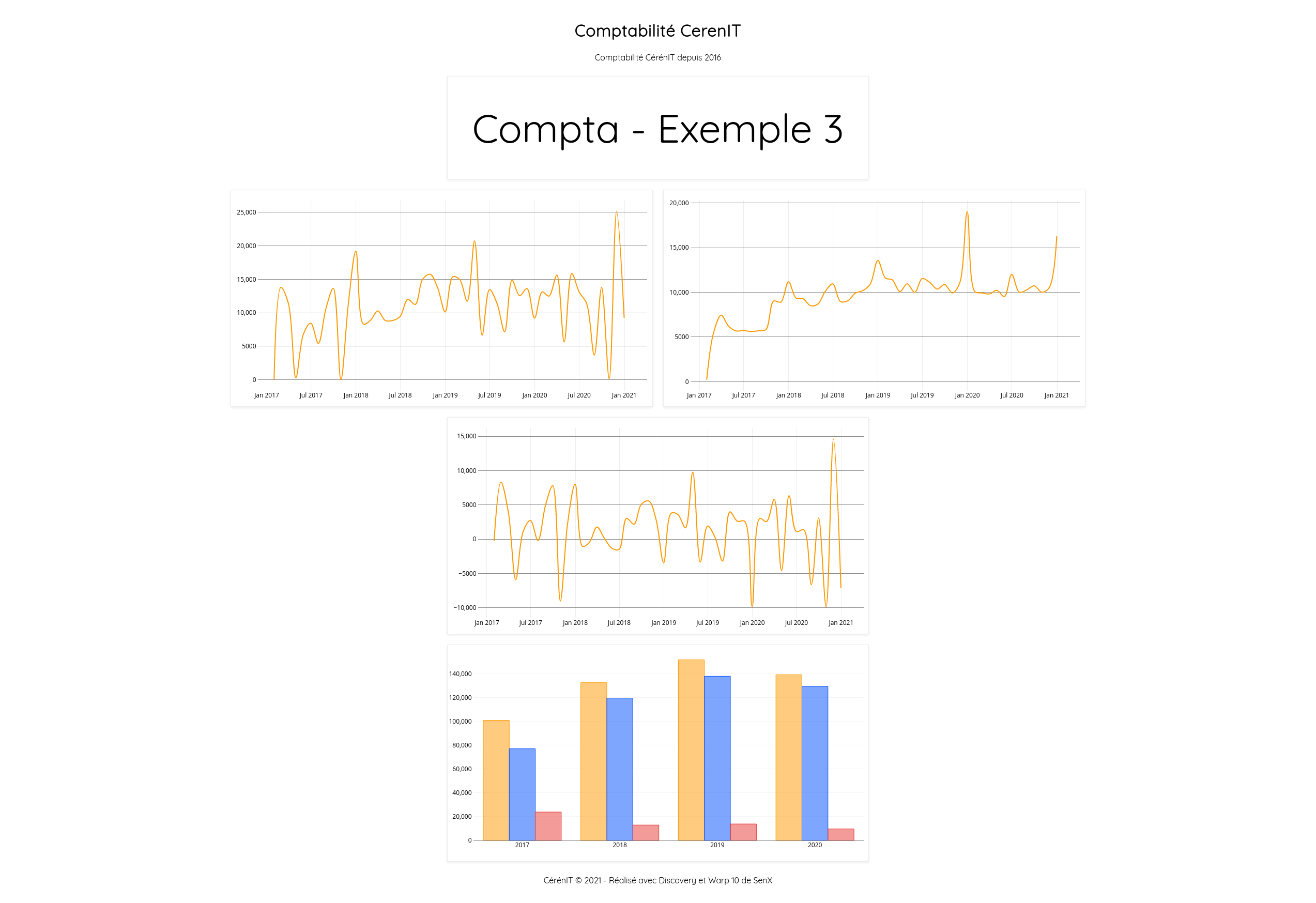
Pour résumer ce billet, nous aovns pu voir que :
- Warp 10 dispose d’une solution de Dashboard avec Discovery
- Comme on pouvait le voir dans le studio, à partir du moment où l’on a nos requêtes, il est aisé de les mettre dans des dashboards
- Les macros permettent de ne pas exposer des tokens dans le navigateur et de faire des calculs cotés serveur
- Il est possible de personnaliser l’apparence des dashboards - des points d’entrée et des mécanismes de surcharges sont à notre disposition pour en faire ce que l’on souhaite
- Les composants WarpView sont assez riches et se configurent facilement
Ma comptabilité, une série temporelle comme les autres - partie 3 - exécution distante
warp10 timeseries comptabilité remote execution rexec lmap templateSuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale (ce billet)
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512
- Partie 6 - Les FEC et le compte de résultat
A l’issue du précédent billet, depuis le WarpStudio et en stockant les données dans la sandbox, nous avons manipuler les données pour :
- refaire les précisions de juin à décembre 2020 à partir des données de 01/2017 à 05/2017
- comparer ses prévisions avec les résultats réels
- faire les prévisions pour 2021.
Cependant, cela n’est pas parfait :
- La durée de vie des données dans la sandbox est limitée à 2 semaines
- Il faut copier/coller ses requêtes dans le studio pour obtenir les graphiques
- Mais cela permet d’évaluer les extensions commerciales déployées sur la sandbox mais que vous n’avez pas forcément sur votre instance Warp 10 (au moins pour le moment)
Nous allons voir aujourd’hui comment rappatrier les données générées dans sa propre instance Warp 10.
Génération des prévisions
Pour commencer du bon pied et être sur que tout le monde est au même niveau, nous allons regénérer les prévisions et chaque prévision sera alors stockée dans une sériée dédiée. Cela nous permet d’avoir notre jeu de données de départ. On doit pouvoir sauver directement nos données dans une base distante, mais pour simplifier le tutoriel, nous allons le faire en deux étapes.
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des séries 2017 > 2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// Prévision sur les 12 prochains mois avec AUTO
// On n'a pas besoin d'afficher les données
// Donc plus besoin de les stocker sous forme de variable avec utilisation de la fonction STORE
// Par contre, on veut perstister les données en base
// ce qui se fait avec UPDATE et l'utilsation d'un token en écriture
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_result" RENAME
$writeToken UPDATE
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_revenue" RENAME
$writeToken UPDATE
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_expense" RENAME
$writeToken UPDATE
# Prévisions avec SAUTO
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_result" RENAME
$writeToken UPDATE
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_revenue" RENAME
$writeToken UPDATE
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_expense" RENAME
$writeToken UPDATE
Si nous vouulons vérifier que vos données sont bien en base, il faut utiliser FETCH :
// Ex de FETCH avec la série auto_revenue
'<read token>' 'readToken' STORE
[ $readToken 'auto_revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2022-01-01T00:00:00Z' ] FETCH
0 GET
Attaquons maintenant la grande traversée des données vers mon instance Warp 10.
Activation de l’exécution à distance
Alors on pourrait simplement migrer les données à coup de “curl in/curl out” mais l’idée ici est plus d’illustrer les interactions possibles entre des instances Warp 10.
Pour exécuter du warpscrip sur une instance distante, il faut utiliser la fonction REXEC
Cette exécution distante est désactivée par défaut, il faut donc activer cette extension:
Dans /path/to/warp10/etc/conf.d/70--extensions.conf, nous avons :
// REXEC
#warpscript.extension.rexec = io.warp10.script.ext.rexec.RexecWarpScriptExtension
#warpscript.rexec.endpoint.patterns = .*
// REXEC connect timeout in ms (default = 0, no timeout)
#warpscript.rexec.timeout.connect = 3600000
// REXEC read timeout in ms (default = 0, no timeout)
#warpscript.rexec.timeout.read = 3600000
Décommentons ces lignes et relançons warp 10.
Pour valider que REXEC est bien activé, depuis le studio, nous pouvons faire un test simple:
'2 2 +' 'https://warp10.url:port/api/v0/exec' REXEC
La réponse est 4.
Attention, il faut choisir votre instance comme endpoint dans la liste déroulante du studio. Si vous êtes sur le endpoint de la sandbox, vous auez le message d’erreur suivant :
https://sandbox.senx.io/api/v0/exec
line #2: Exception at ''2%202%20+' 'https://warp10.url:port/api/v0/exec' =>REXEC<=' in section [TOP] (REXEC encountered a forbidden URL 'http://warp10.url:port/api/v0/exec')
En effet, depuis la Sandbox, il n’est pas possible d’accéder à n’importe quelle machine par mesure de sécurité.
Requêtage simple à distance
Dans le studio, à partir de maintenant, il doit être configuré pour utliiser votre instance Warp 10 comme endpoint.
Le test simple étant fonctionnel, passons à un test un peu plus compliqué, à savoir recupérer nos données hébergées depuis la sandbox en lecture pour le moment.
// tokens pour la sandbox
'<sandboxReadToken>' 'sandboxReadToken' STORE
'<sandboxWriteToken>' 'sandoxWriteToken' STORE
// Url de la sandbox
'https://sandbox.senx.io/api/v0/exec' 'url' STORE
// On introduit ici la notion de template - comme on va vouloir récupérer plusieurs séries avec les mêmes paramètres
// Autant automatiser un peu et s'appuyer sur une boucle ! :-)
// On crée donc un TEMPLATE pour la fonction FETCH qui va récupérer un token en écriture
// et un nom de classe permettant de récupérer nos GTS.
// Rappel le <' ... '> permet de faire des strings en multi-lignes
// On stocke le template sous la forme d'une variable fetchTpl.
<'
{
'token' '{{ remoteReadToken }}'
'class' '{{ remoteClass }}'
'labels' {}
'start' '2016-12-01T00:00:00Z'
'end' '2022-01-31T00:00:00Z'
} FETCH
'>
'fetchTpl' STORE
// Avec la fonction TEMPLATE, on remplace les clés par leurs valeurs en fournissant le template
// et un dictionnaire à la fonction.
$fetchTpl
{ 'remoteReadToken' $sandboxReadToken 'remoteClass' 'revenue' } TEMPLATE
// Execution de la requête distante avec REXECZ
// La différence avec REXEC est qu'une compression est appliquée sur la réponse à la requête
$url REXECZ
// La liste de GTS issue de FETCH ne contient qu'une liste, on prend donc la première
0 GET
// Stockage sous la forme d'une variable
'revenueGTS' STORE
// Affichage de la série
$revenueGTS
Si vous allez dans l’onglet dataviz, vous pouvez constater que vos données issues de la sandbox mais qui ont transité via votre instance sont bien disponibles.
Transfert des données - 1 série
Si nous commençons par une seule série :
// tokens de l'instance
'<instanceReadToken>' 'instanceReadToken' STORE
'<instanceWriteToken>' 'instanceWriteToken' STORE
// tokens pour la sandbox
'<sandboxReadToken>' 'sandboxReadToken' STORE
'<sandboxWriteToken>' 'sandoxWriteToken' STORE
// Url de la sandbox
'https://sandbox.senx.io/api/v0/exec' 'url' STORE
// Template de code warpscript
<'
{
'token' '{{ remoteReadToken }}'
'class' '{{ remoteClass }}'
'labels' {}
'start' '2016-12-01T00:00:00Z'
'end' '2022-01-31T00:00:00Z'
} FETCH
'>
'fetchTpl' STORE
// Substitution des variables
$fetchTpl
{ 'remoteReadToken' $sandboxReadToken 'remoteClass' 'revenue' } TEMPLATE
// Exécution de la requête
$url REXECZ
// La liste de GTS issue de FETCH ne contient qu'une liste, on prend donc la première
0 GET
// Il faut renommer "localement" la série avant de pouvoir la stocker dans l'instance
// Peut éviter de mauvaises manipulations que l'on pourrait regretter :-)
"revenue" RENAME
// Persistance des données
$instanceWriteToken UPDATE
Il y a quelques occurences de “revenue” en dur dans le code, il va falloir améliorer cela.
Transfert des données - plusieurs séries
Et maintenant, traitons nos 9 series d’un coup
// tokens de l'instance
'<instanceReadToken>' 'instanceReadToken' STORE
'<instanceWriteToken>' 'instanceWriteToken' STORE
// tokens pour la sandbox
'<sandboxReadToken>' 'sandboxReadToken' STORE
'<sandboxWriteToken>' 'sandoxWriteToken' STORE
// Url de la sandbox
'https://sandbox.senx.io/api/v0/exec' 'url' STORE
// Template de code warpscript
<'
{
'token' '{{ remoteReadToken }}'
'class' '{{ remoteClass }}'
'labels' {}
'start' '2016-12-01T00:00:00Z'
'end' '2022-01-31T00:00:00Z'
} FETCH
'>
'fetchTpl' STORE
// Création d'une liste avec nos 9 séries
// C'est cette liste que nous allons passer ensuite dans une MACRO.
// Cette MACRO va être exécutée sur chaque élément de la liste via l'utilisation de la fonction LMAP
// https://www.warp10.io/doc/LMAP
[ 'revenue' 'exp' 'result' 'auto_revenue' 'auto_result' 'auto_expense' 'sauto_revenue' 'sauto_result' 'sauto_expense' ]
// Début de la MACRO
<%
// On récupère la valeur de la liste que l'on stocke sous la forme d'une variable
'remoteClass' STORE
// Substitution des valeurs de template
$fetchTpl
{ 'remoteReadToken' $sandboxReadToken 'remoteClass' $remoteClass } TEMPLATE
// Exécution distante de la requête
$url REXECZ
// On récupère ici une liste de GTS - plutôt que d'en extraire la GTS comme précédemment
// on va garder une liste de GTS à 1 élément, mais ce qui permet à nouveau d'utiliser la fonction LMAP
// Sur chaque entrée de la liste, une seconde macro est appliquée
// Le contenu de notre macro consiste à utliser la fonction RENAME
// '+' RENAME, cela revient à renommer la GTS en prenant le même nom que celui qui est fourni
// '+x' RENAME aurait ajouté un x au nom de la série
// Il reste l'index de la liste à traiter - soit on le supprime avec DROP
//<% DROP '+' RENAME %> LMAP
// Soit on passe F comme 3ème argument à LMAP - cela permet d'ignorer cet index
// <% '+' RENAME %> F LMAP
// Prenons la seconde forme :
<% '+' RENAME %> F LMAP
// Toutes nos séries ont été correctement renommées !
// On persiste la GTS dans la base locale
$instanceWriteToken UPDATE
%>
// Fin de la MACRO
// Application de la fonction LMAP pour que notre macro soit exécutée sur chaque élément de la liste.
// Comme on ne veut que les valeurs de la liste et pas les index, on positionne aussi F
// comme 3ème argument à LMAP
F LMAP
Et voilà, nos données ont été récupérées de la Sandbox et stockées dans notre instance locale.
Bonus
Une version alternative - dans mes données, je peux tricher et ne filtrer que sur le label company avec pour valeur cerenit:
// tokens de l'instance
'<instanceReadToken>' 'instanceReadToken' STORE
'<instanceWriteToken>' 'instanceWriteToken' STORE
// tokens pour la sandbox
'<sandboxReadToken>' 'sandboxReadToken' STORE
'<sandboxWriteToken>' 'sandoxWriteToken' STORE
// Url de la sandbox
'https://sandbox.senx.io/api/v0/exec' 'url' STORE
// Warpscript template
<'
{
'token' '{{ remoteReadToken }}'
'class' '~.*'
'labels' { 'company' 'cerenit' }
'start' '2016-12-01T00:00:00Z'
'end' '2022-01-31T00:00:00Z'
} FETCH
'>
'fetchTpl' STORE
// Substitution dans le template
$fetchTpl
{ 'remoteReadToken' $sandboxReadToken } TEMPLATE
// Execution de la requête
$url REXECZ
// Renommage des séries
<% '+' RENAME %> F LMAP
// Presistence des données
$instanceWriteToken UPDATE
Bravo si vous m’avez suivi jusqu’ici, nous avons pu voir l’utilisation de :
- Comment permettre un requêtage à distance d’une instance Warp 10 avec les fonctions
REXECetREXECZ - Comment traiter dynamiquement notre liste de GTS avec
LMAPet uneMACRO - Comment faire un template warpscript et de la substitution de variables avec
TEMPLATE
Nous verrons dans un prochain épisode :
- Comment utiliser Discovery pour faire nos premiers dashboards
- Pourquoi/comment utiliser des macros coté server (spoiler: pour éviter que vos tokens se retrouvent dans votre navigateur à l’exécution des dashboards)
Ma comptabilité, une série temporelle comme les autres - partie 2 - actualisation des données et des prévisions
warp10 timeseries comptabilité prévision forecastSuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021 (ce billet)
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512
- Partie 6 - Les FEC et le compte de résultat
L’année dernière, nous avions travaillé sur Warp 10 et mes données de comptabilité et jouer un peu avec les algo de prévision.
Les données comptables ayant été un peu ajustées entre temps et la librairie de prévision ayant aussi évolué coté SenX, les résultats ne sont plus tout à fait les mêmes. Nous allons donc reprendre tout ça.
Rappel des fais et prévisions à fin 2020
En septembre dernier, nous avions ce code pour avoir les données jusqu’au mois de Mai 2020 et une prévision jusqu’à la fin d’année:
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de dépenses / chiffre d'affaires / résult pour la période du 01/01/2017 -> 31/05/2020
// Chaque série est stockée dans une variable
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// On affiche les trois courbes
$revenue
$exp
$result
// On génère et affiche les prévisions - on renomme les séries pour mieux les différencier ensuite au niveau dataviz
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_expense" RENAME
Au global :
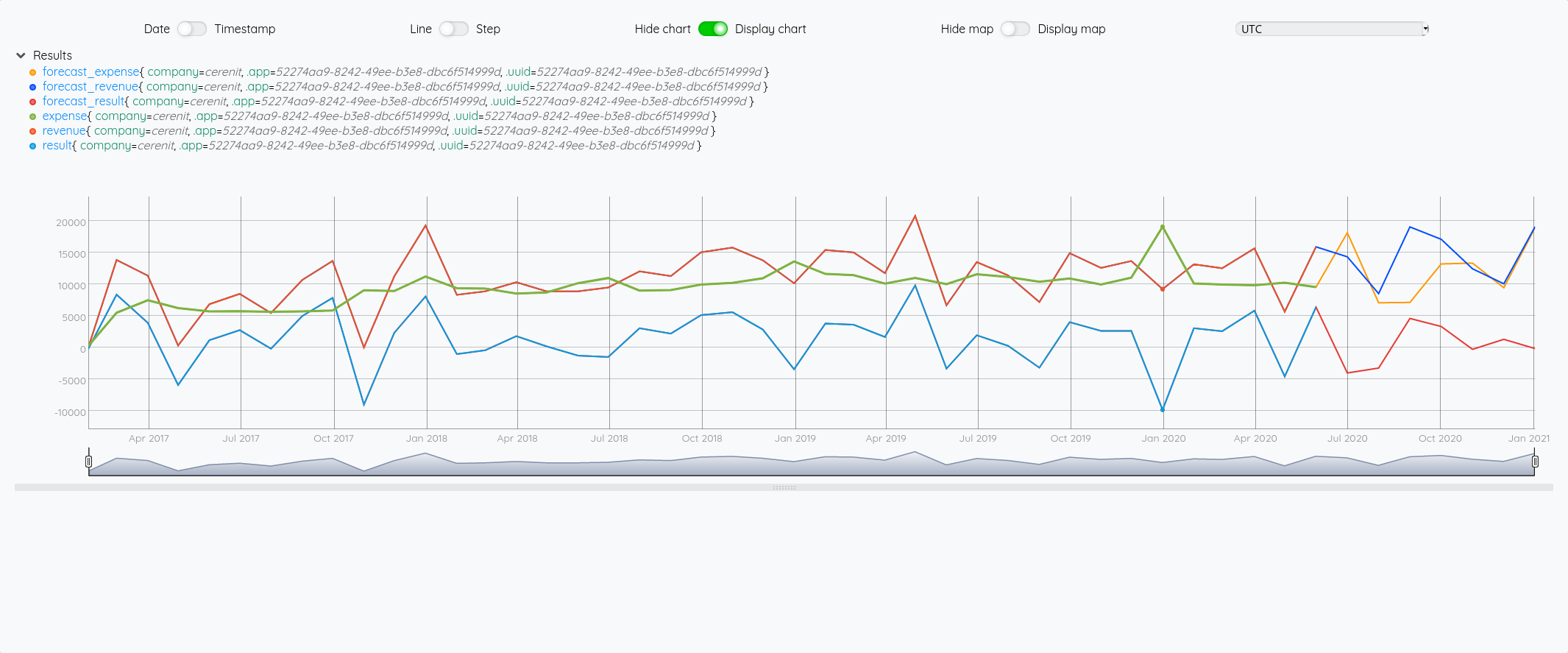
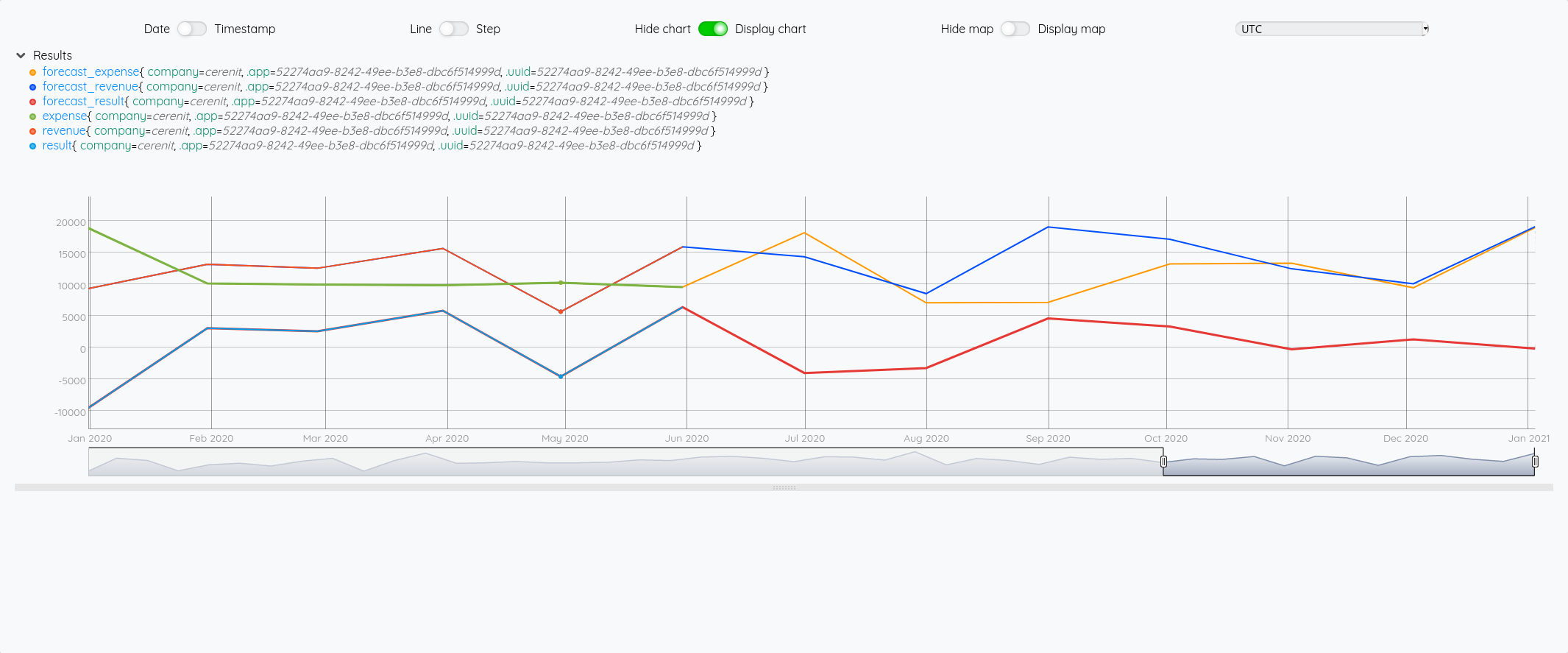
Focus 2020 avec la partie prévision à partir de juin :
Si on fait la même chose en prenant un algo incluant un effet de saisonnalité :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de dépenses / chiffre d'affaires / résult pour la période du 01/01/2017 -> 31/05/2020
// Chaque série est stockée dans une variable
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// On affiche les trois courbes
$revenue
$exp
$result
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_expense" RENAME
Au global :
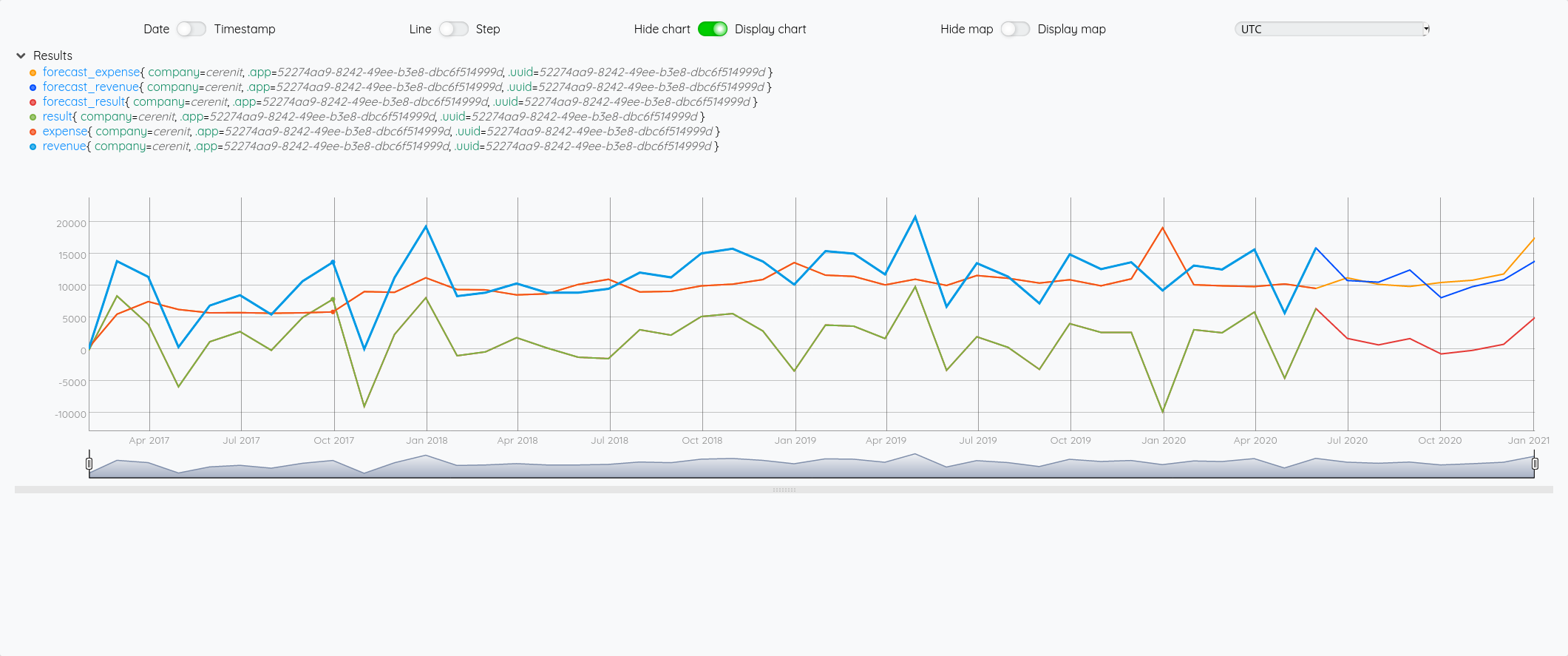
Focus 2020 avec la partie prévision à partir de juin :
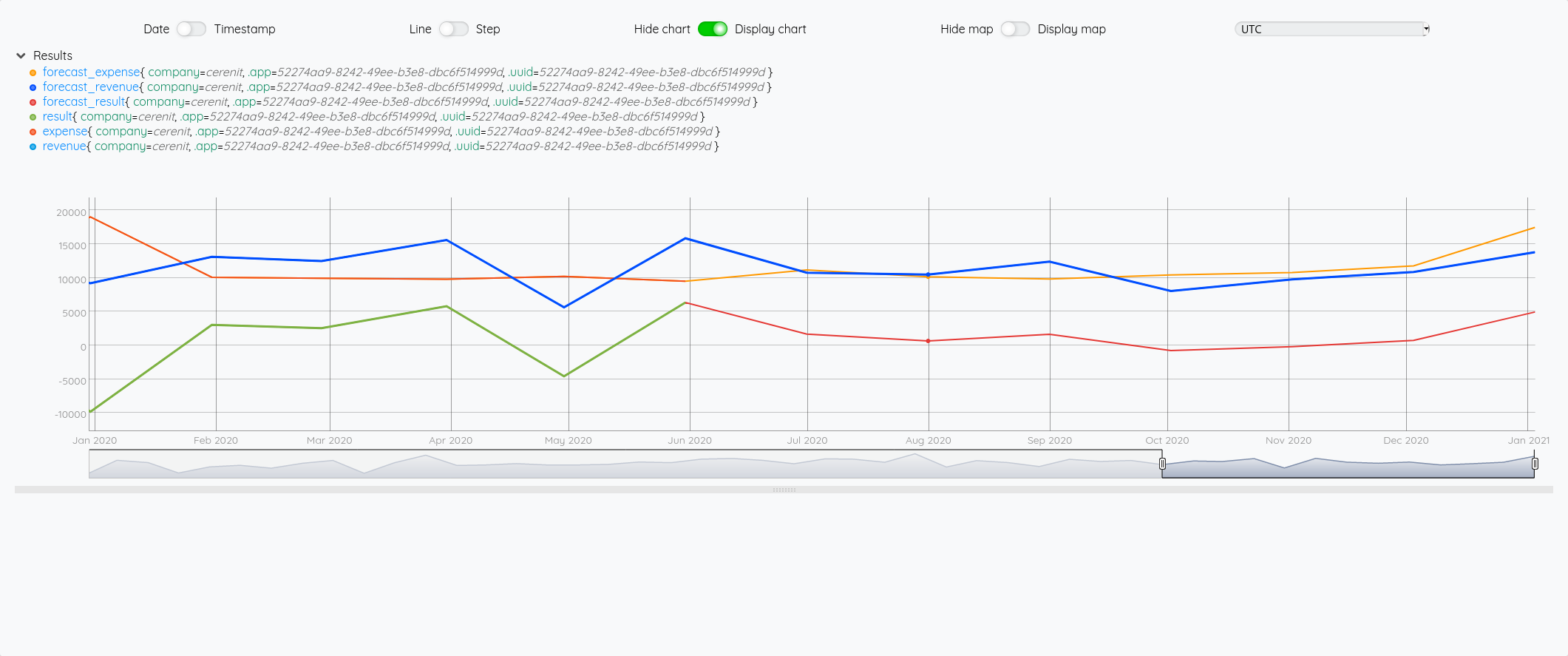
On a bien un petit écart de comportement sur la prévision entre les deux modèles (focus sur 2020 avec les différentes prévisions à partir de juin) :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de dépenses / chiffre d'affaires / résult pour la période du 01/01/2017 -> 31/05/2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_expense" RENAME
// On génère et affiche les prévisions - on renomme les séries pour mieux les différencier ensuite au niveau dataviz
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_expense" RENAME
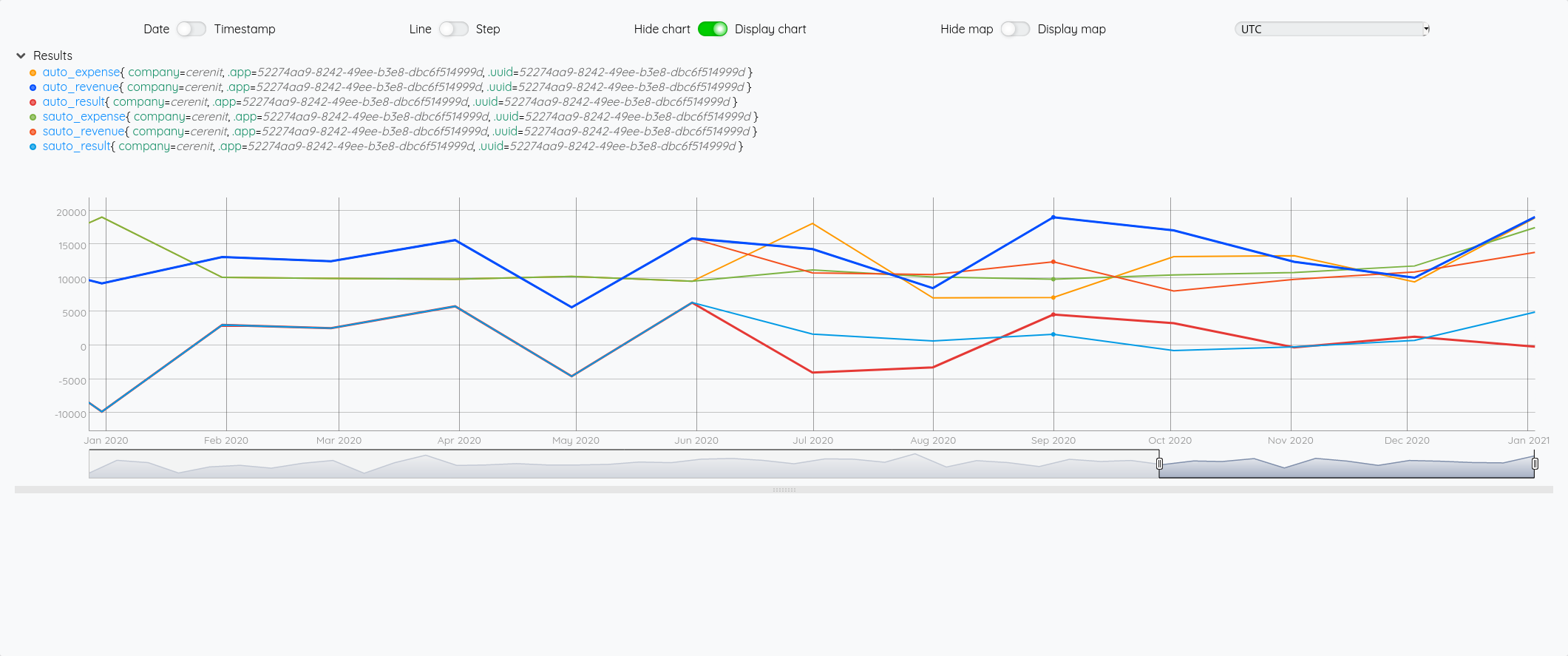
Prévisions vs réalité
Comparons maintenant les prévisions à la réalité - je vais rajouter les requêtes pour avoir la vue complète des données - pour éviter de trop surcharger le graphique, comme les séries forecast_* reprennent les données sources et y ajoutent la prévision, je ne vais afficher que ces séries et les séries réelles :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de base qui serviront ensuite pour la prévision
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// Récupération des données réelles de la période 01/01/2017 > 31/12/2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_result' STORE
// Génération des prévisions
// Pour SAUTO, il faut définir en plus un cycle, ici 12 mois
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_expense" RENAME
$real_result
$real_revenue
$real_exp
Ce qui nous donne au global :
et avec le focus 2020 :
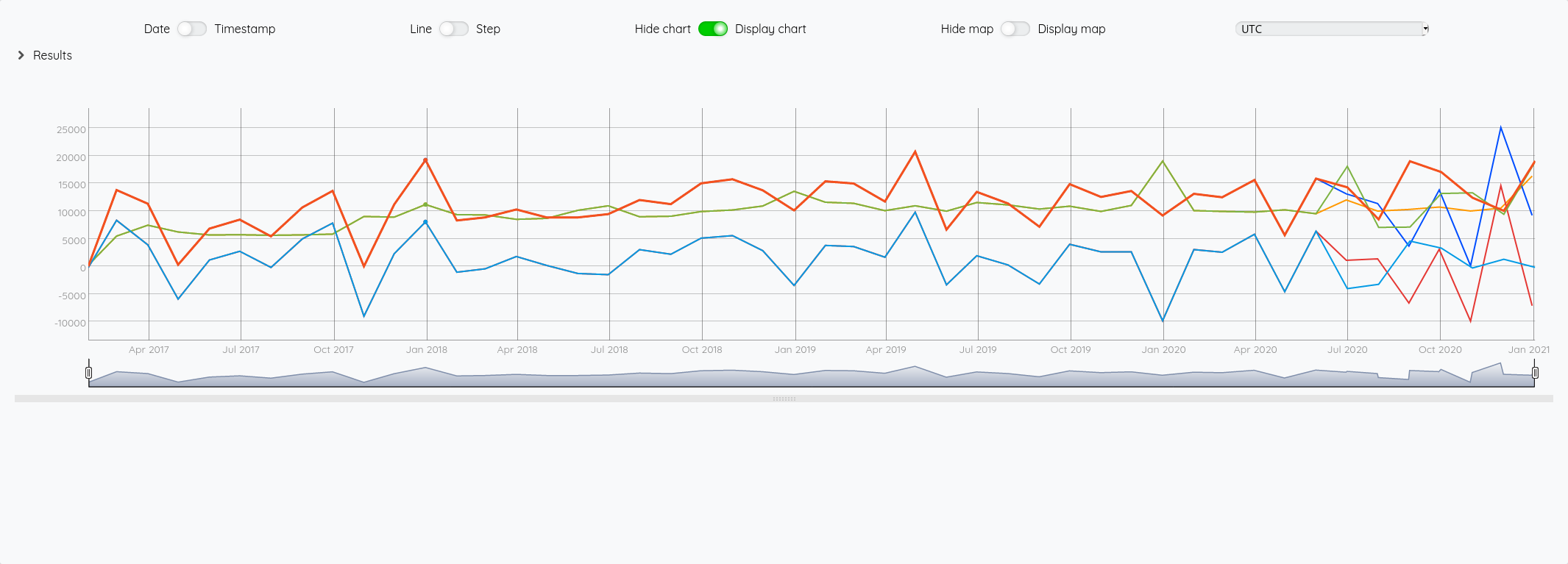
Si on fait la même chose avec SAUTO
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de base qui serviront ensuite pour la prévision
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// Récupération des données réelles de la période 01/01/2017 > 31/12/2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_result' STORE
// Génération des prévisions
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_expense" RENAME
$real_result
$real_revenue
$real_exp
Au global :
Focus 2020 avec la partie prévision à partir de juin :
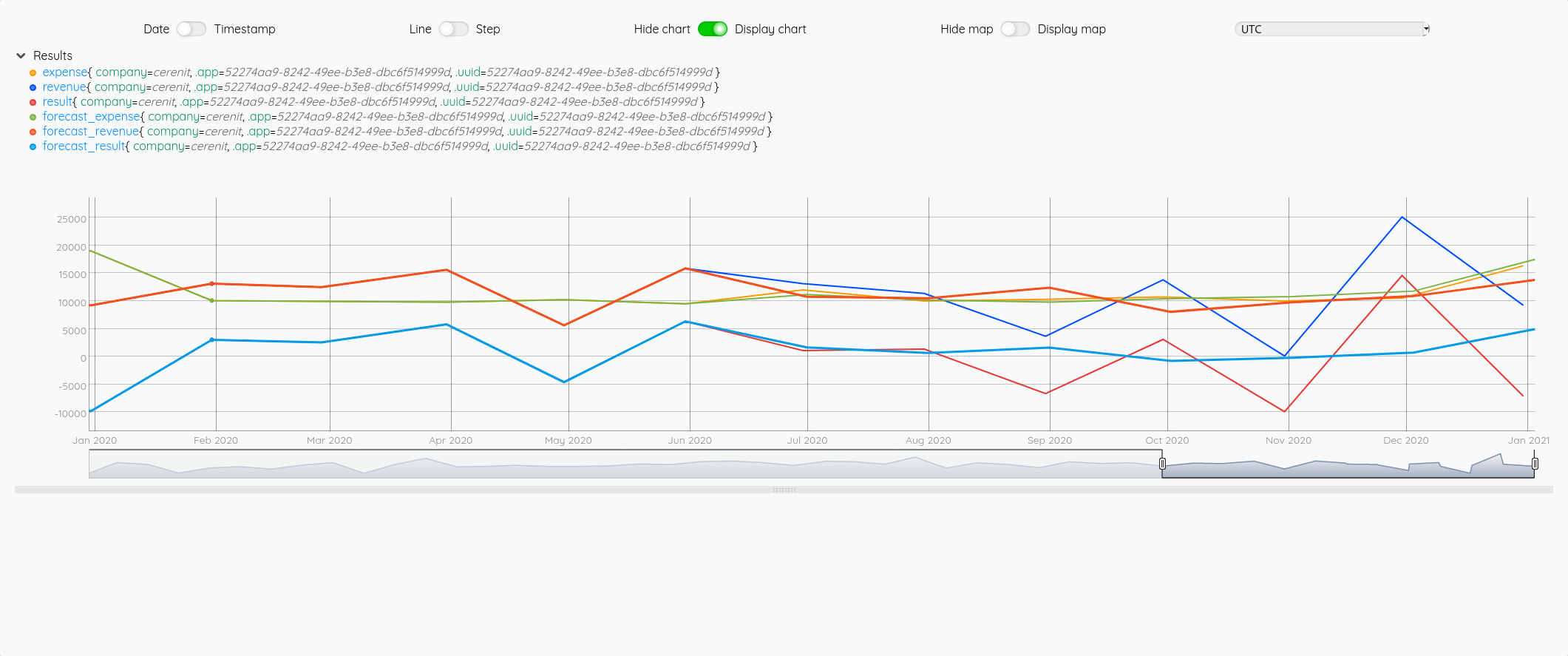
Essayons d’analyser tout ça (il faut regarder les fins de mois - les points sont en date du dernier jour du mois) :
- Pour Juin/Juillet, la prévision est plutôt bonne.
- Pour Aout : l’écart vient du fait que j’ai pris mes vacances en aout et pas à cheval sur juillet/aout comme les autres années
- Pour Septembre, c’est correct
- Pour Octobre, il faut voir que j’ai tardé à éditer mes factures - elles ont donc été pris en compte sur Novembre - si on divise le montant de Novembre en deux, on retombe à peu près sur nos points
- Pour décembre, un effet vacances également.
La pertinence est prévisions est donc plutôt correct au global et les écarts sont expliquables.
Consolidation annuelle
Et au niveau annuel ? Est-ce que les prévisions de chiffres d’affaires / dépenses / résultats sont bonnes si on ne tient plus compte des petits écarts de temps ci-dessus ?
Voyons celà :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des différentes séries comme précédemment
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_result' STORE
// Calcul des prévisions comme précédemment
// Petit ajout, on stocke le résultat sous la forme d'une variable pour être réutilisé ultérieurement
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_result" RENAME
'auto_result' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_revenue" RENAME
'auto_revenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_expense" RENAME
'auto_expense' STORE
// Aggrégation annuelle
// Utilisation de BUCKETIZE.CALENDAR et de la macro BUCKETIZE.byyear qui s'appuie dessus et qui permet de faire une aggrégation annuelle sur des données
// bucketizer.sum permet d'appliquer une somme sur les données regroupées par année
// UNBUCKETIZE.CALENDAR permet de retransformer l'indice issue de BUCKETIZE.CALENDAR en timestamp
[ $real_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $real_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $real_exp bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $auto_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $auto_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $auto_expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
// Meme chose pour SAUTO
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_result" RENAME
'sauto_result' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_revenue" RENAME
'sauto_revenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_expense" RENAME
'sauto_expense' STORE
[ $sauto_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $sauto_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $sauto_expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
Pour expliciter un peu au dessus :
On veut obtenir un résultat annuel couvant la période du 01/01 au 31/12 d’une année. Il faut donc prendre tous les points de l’année en question et en fait la somme.
Si on fait:
[ $real_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear
On obtient :
[{"c":"revenue","l":{"company":"cerenit",".app":"52274aa9-8242-49ee-b3e8-dbc6f514999d",".uuid":"52274aa9-8242-49ee-b3e8-dbc6f514999d"},"a":{".buckettimezone":"UTC",".bucketduration":"P1Y",".bucketoffset":"0"},"la":1612528364518,"v":[[47,100850],[48,132473],[49,151714],[50,139146]]}]
Les valeus obtenues sont :
[[47,100850],[48,132473],[49,151714],[50,139146]]
Les indices 47, 48, 49, 50 sont en fait un delta par rapport au 01/01/70. En effet, 2020 = 1970 + 50
En appliquant UNBUCKETIZE.CALENDAR, on retransforme ce 50 par ex en son équivalent sous la forme d’un timestamp : 1609459199999999.
On peut aussi utiliser TIMESHIFT de la façon suivante :
[ $real_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
Pour obtenir pour la partie valeur :
[[2017,100850],[2018,132473],[2019,151714],[2020,139146]]
Pour en savoir plus sur BUCKETIZE.CALENDAR et ses utilisations : Aggregate by calendar duration in WarpScript
Une fois qu’on reprend toutes ses données, on peut essayer de mesurer les écarts entre le réél et les prévisions des deux modèles :
| AUTO | SAUTO | Réel | AUTO vs Réel | SAUTO vs Réel | |
|---|---|---|---|---|---|
| Chiffre d’affaires | 144.029 | 125.128 | 139.146 | -3,39% | +11,20% |
| Dépénses | 117.701 | 113.765 | 129.464 | +9,99% | +13,80% |
| Résultat | 14.754 | 16.893 | 9.682 | -34,38% | -42,69% |
| Résultat corrigé | 26.328 | 11.363 | 9.682 | -63,23% | -14,79% |
Intéressant, la prévision de résultat n’est pas égale à la différence entre la prévision de chiffre d’affaires et la prévision des dépenses ! C’est la raison de la ligne “Résultat corrigé”.
A ce stade, il ne me semble pas possible de privilégier un modèle plus qu’un autre - même si du fait de la récurrence des vacances, on peut supposer que le modèle avec saisonnalité pourrait être plus pertinent.
Prévisions pour 2021
Pour aller au bout de cet exerice, il ne reste plus qu’à voir ce que nos algoritmes prévoient pour 2021 :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des séries 2017 > 2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// Prévision sur les 12 prochains mois
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_result" RENAME
'auto_result' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_revenue" RENAME
'auto_revenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_expense" RENAME
'auto_expense' STORE
// Consolidation annuelle avec AUTO
[ $auto_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $auto_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $auto_expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
// Prévisions avec SAUTO
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_result" RENAME
'sauto_result' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_revenue" RENAME
'sauto_revenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_expense" RENAME
'sauto_expense' STORE
// Consolidation annuelle avec SAUTO
[ $sauto_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $sauto_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $sauto_expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
On passe tout ça dans le shaker et on obtient :
| Prévu avec AUTO | Prévu avec SAUTO | |
|---|---|---|
| Chiffre d’affaires | 78.230 | 129.465 |
| Dépénses | 118.383 | 110.434 |
| Résultat prévu | 5.730 | 4.049 |
| Résultat corrigé | -40.153 | 19.031 |
Rendez-vous à la fin de l’année pour voir ce qu’il en est… et on peut espérer que la réalité sera proche du modèle avec saisonnalité !
Pour le moment, on travalle toujours dans le WarpStudio et on voudrait bien avoir des (jolis) dashboards qui font tout ça pour nous plutôt que de copier/coller du Warpscript. Ce sera le sujet de la partie 3.
