Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Web, Ops, Data et Time Series - Juillet 2021
kubernetes gitlab-ci buildah podman kaniko golang scaleway ia aws frenchtech euclidia vector sécurité opnsense wireguard katz facebook prophet arima sarima holt-winters lstmCI/CD
- Builder simplement des images Docker avec Gitlab-CI (sans DinD) : Personnellement, j’avais migré sous Kaniko depuis un moment. Je ne savais pas que Buildah pouvait ingérer directement des Dockerfile - il me semblait qu’il fallait passer par Podman pour ça. En reprenant le changelog, il semblerait que la fonctionnalité existe depuis un moment.
Cloud
- AWS’s Egregious Egress : Réflexions de Cloudflare sur la tarification du traffic sortant chez AWS et la marge réalisée. A priori, cela ne se base pas uniquement sur des raisons objectives…
- 23 entreprises européennes de technologie du cloud forment l’Alliance industrielle européenne du cloud (EUCLIDIA) : nouvelle association en faveur du cloud européen sur la base de technologies et de sociétés europénnes.
- « Service après-vente bonjour ! » : Le futur de la French Tech ? : tribune d’acteurs français suite à la doctrine du “cloud souverain” et l’utilisation de licences américaines.
Container & Orchestration
- Kubernetes API and Feature Removals In 1.22: Here’s What You Need To Know : les habituelles dépréciéations d’API prévus pour la version 1.22 (Aout 2021)
- Kubernetes Kosmos : sCaleway lance son offre kuberentes multi-cloud et piloté par leur controle plane. En mode private beta pour le moment.
Golang
- Learning Go by examples: Introduction : Après ses explications sur Docker, Istio et Kubernetes, Aurélie Vache s’attaque à Go.
- Learning Go by examples: part 2 - Create an HTTP REST API Server in Go
- Learning Go by examples: part 3 - Create a CLI app in Go
IA
- AI Days 2020 : la playlist youtube des AI Days 2021 est disponible, avec un angle industriel qui change de d’habitude.
Monitoring
- Vector v0.15.0 release notes : de nouveaux sinks & sources, des transformations et de la visualisation. Vector s’améliore au fil des versions.
Sécurité
- Remote code execution in cdnjs of Cloudflare : cdnjs est un CDN pour des ressources en javascript. Mais que peut-il se passer en cas de faille ou de compromission de ce CDN ? C’est le propos de ce billet.
Time Series
- Covid Tracker built with Warp 10 and Discovery : un tutoriel pour apprendre plein de choses sur Discovery, la solution de dashboard as code de SenX pour Warp 10.
- Kats: a Generalizable Framework to Analyze Time Series Data in Python : j’avais évoqué Katz dans une édition précédente, voici un billet qui rentre un peu plus dans le détail des fonctionnalités disponibles.
WireGuard
- WireGuard Site to Site Configuration : si la documentation pour une configuration itinérante (“Road Warrior”) est assez bien documentée, pour du site à site, c’est plus rare. Une explication simple et efficace.
- OPNsense WireGuard VPN Site-to-Site configuration : la même chose mais appliquée à un routeur géré par OPNSense
- OPNsense WireGuard VPN for Road Warrior configuration : la version “Road Warrior” du tutoriel précédent
- WireGuard Road Warrior Setup : la documentation officielle d’OPNSense pour la version “Road Warrior”
Premiers pas avec Warp 10 : comptabilité et prévisions de fin d'année
warp10 timeseries forecast dashboard warpstudio arimaSuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année (ce billet)
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512
- Partie 6 - Les FEC et le compte de résultat
Cherchant à me familiariser avec la base de données orientée série temporelles Warp 10 d’une part et à améliorer mes tableaux de bord comptables pour me faire des projections à fin d’année (parce que bon, faire juste la moyenne des mois précédents comme valeur pour les mois à venir, c’est un peu trop facile), je me suis dit que c’était un exercice qui pouvait répondre aux deux besoins après avoir lu Time series forecasts in WarpScript.
Pour ceux qui ne connaissent pas encore Warp 10 , c’est une solution de geo-timeseries (séries spatio temporelles) open source, éditée par SenX, société française basée à Brest. Pour en savoir plus sur Warp 10 , vous pouvez regarder l’éditions 1 et l’édition 5 du Paris Time Series Meetup.
Pour prendre en main Warp 10 et appréhender le langage de programmation Warpscript, je vous invite à suivre le tutoriel sur les cyclones en utilisant la Sandbox Warp10 mise à disposition par Senx.
Le jeu de données
Pour le jeu de données, j’ai donc récupéré de mes tableaux de bords mon chiffre d’affaires et mes dépenses mensuels sur la période Janvier 2017 à Mai 2020.
Nous allons donc créer 2 séries (appelées aussi GTS)
Soit crnt-revenue.gts:
# 2017
1483225200000000// revenue{company=cerenit} 0
1485903600000000// revenue{company=cerenit} 13800
1488322800000000// revenue{company=cerenit} 11325
1490997600000000// revenue{company=cerenit} 300
1493589600000000// revenue{company=cerenit} 6825
1496268000000000// revenue{company=cerenit} 8450
1498860000000000// revenue{company=cerenit} 5425
1501538400000000// revenue{company=cerenit} 10650
1504216800000000// revenue{company=cerenit} 13650
1506808800000000// revenue{company=cerenit} 0
1509490800000000// revenue{company=cerenit} 11200
1512082800000000// revenue{company=cerenit} 19225
# 2018
1514761200000000// revenue{company=cerenit} 8300
1517439600000000// revenue{company=cerenit} 8850
1519858800000000// revenue{company=cerenit} 10285
1522533600000000// revenue{company=cerenit} 8850
1525125600000000// revenue{company=cerenit} 8850
1527804000000000// revenue{company=cerenit} 9450
1530396000000000// revenue{company=cerenit} 12000
1533074400000000// revenue{company=cerenit} 11250
1535752800000000// revenue{company=cerenit} 15013
1538344800000000// revenue{company=cerenit} 15750
1541026800000000// revenue{company=cerenit} 13750
1543618800000000// revenue{company=cerenit} 10125
# 2019
1546297200000000// revenue{company=cerenit} 15375
1548975600000000// revenue{company=cerenit} 14750
1551394800000000// revenue{company=cerenit} 11600
1554069600000000// revenue{company=cerenit} 20622
1556661600000000// revenue{company=cerenit} 6376
1559340000000000// revenue{company=cerenit} 13350
1561932000000000// revenue{company=cerenit} 11250
1564610400000000// revenue{company=cerenit} 7050
1567288800000000// revenue{company=cerenit} 14750
1569880800000000// revenue{company=cerenit} 12326
1572562800000000// revenue{company=cerenit} 12513
1575154800000000// revenue{company=cerenit} 9082
# 2020
1577833200000000// revenue{company=cerenit} 13000
1580511600000000// revenue{company=cerenit} 12375
1583017200000000// revenue{company=cerenit} 15500
1585692000000000// revenue{company=cerenit} 5525
1588284000000000// revenue{company=cerenit} 15750
et crnt-expenses.gts:
# 2017
1483225200000000// expense{company=cerenit} 219
1485903600000000// expense{company=cerenit} 5471
1488322800000000// expense{company=cerenit} 7441
1490997600000000// expense{company=cerenit} 6217
1493589600000000// expense{company=cerenit} 5676
1496268000000000// expense{company=cerenit} 5719
1498860000000000// expense{company=cerenit} 5617
1501538400000000// expense{company=cerenit} 5690
1504216800000000// expense{company=cerenit} 5831
1506808800000000// expense{company=cerenit} 9015
1509490800000000// expense{company=cerenit} 8903
1512082800000000// expense{company=cerenit} 11181
# 2018
1514761200000000// expense{company=cerenit} 9352
1517439600000000// expense{company=cerenit} 9297
1519858800000000// expense{company=cerenit} 8506
1522533600000000// expense{company=cerenit} 8677
1525125600000000// expense{company=cerenit} 10136
1527804000000000// expense{company=cerenit} 10949
1530396000000000// expense{company=cerenit} 8971
1533074400000000// expense{company=cerenit} 9062
1535752800000000// expense{company=cerenit} 9910
1538344800000000// expense{company=cerenit} 10190
1541026800000000// expense{company=cerenit} 10913
1543618800000000// expense{company=cerenit} 13569
# 2019
1546297200000000// expense{company=cerenit} 11553
1548975600000000// expense{company=cerenit} 11401
1551394800000000// expense{company=cerenit} 10072
1554069600000000// expense{company=cerenit} 10904
1556661600000000// expense{company=cerenit} 9983
1559340000000000// expense{company=cerenit} 11541
1561932000000000// expense{company=cerenit} 11065
1564610400000000// expense{company=cerenit} 10359
1567288800000000// expense{company=cerenit} 10450
1569880800000000// expense{company=cerenit} 9893
1572562800000000// expense{company=cerenit} 10014
1575154800000000// expense{company=cerenit} 15354
# 2020
1577833200000000// expense{company=cerenit} 9673
1580511600000000// expense{company=cerenit} 9933
1583017200000000// expense{company=cerenit} 9815
1585692000000000// expense{company=cerenit} 9400
1588284000000000// expense{company=cerenit} 9381
Pour chaque fichier:
- le premier champ est un timestamp correspondant au 1er jour de chaque mois à 00h00.
- la partie
//indique qu’il n’y a pas de position spatiale (longitude, lattitude, élévation) expenseetrevenuesont les noms des classes qui vont stocker mes informationscompanyest un label que je positionne sur mes données avec le nom de mon entreprise- le dernier champ est la valeur de mon chiffre d’affaires ou de mes dépenses mensuels.
Pour plus d’information sur la modélisation, cf GTS Input Format.
Insertion des données
Lorsque vous utilisez la Sandbox, 3 tokens vous sont donnés :
- un token pour lire les données ; j’y ferai référence via
<readToken>par la suite - un token pour écrire les données ; j’y ferai référence via
<writeToken>par la suite - un token pour supprimer les données ; j’y ferai référence via
<deleteToken>par la suite
#!/usr/bin/env bash
for file in crnt-expenses crnt-revenue ; do
curl -v -H 'Transfer-Encoding: chunked' -H 'X-Warp10-Token: <writeToken>' -T ${file}.gts 'https://sandbox.senx.io/api/v0/update'
done
Premières requêtes
Pour ce faire, nous allons utiliser le Warp Studio ; pour la datasource, il conviendra de veiller à ce que la SenX Sandbox soit bien sélectionnée.
L’équivalent de “SELECT * FROM *” peut se faire de la façon suivante :
# Authentification auprès de l'instance en lecture
'<readToken> 'readToken' STORE
# FETCH permet de récupérer une liste de GTS, ici on demande toutes les classes via ~.* et tous les labels en prenanr les 1000 dernières valeurs ; on récupère donc toutes les séries.
[ $readToken '~.*' {} NOW -1000 ] FETCH
Si vous cliquez sur l’onglet “Dataviz”, vous avez alors immédiatement une représentation graphique de vos points.
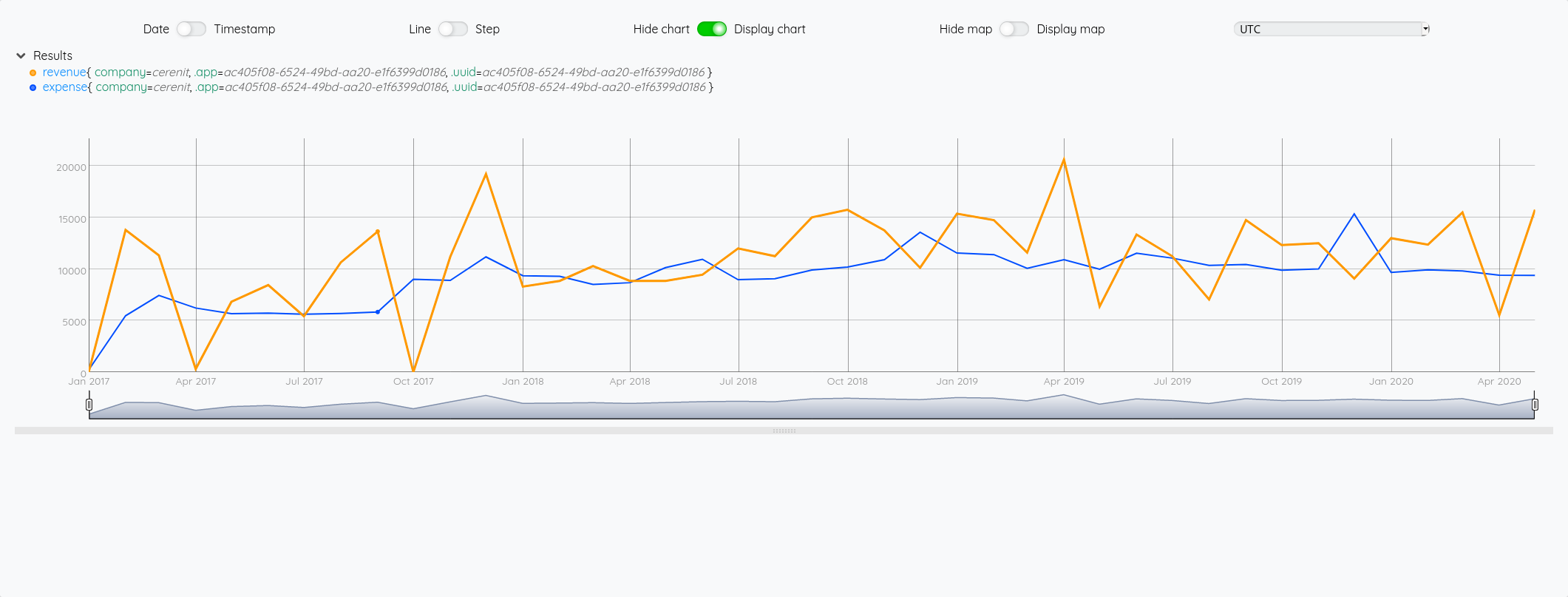
Maintenant que nos données sont bien présentes, on va vouloir aller un peu plus loin dans nos manipulations.
Premières manipulations
Ce que nous voulons faire :
- Sélectionner chaque série et la stocker dans une variable,
- Calculer le résultat mensuel et le persister dans une troisième série temporelle
- Afficher les trois séries.
Pour sélectionner chaque série et la stocker dans une variable:
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# FETCH : permet de récupérer une liste de série, ici on filtre sur la classe expense, sur le label company = cerenit et sur les dates du 01/12/2016 au 01/06/2020.
# 0 GET : on sait que l'on a qu'une seule série qui correspond à la requête. Donc on ne retient que le 1er élément pour passer d'une liste de GTS à une seule et unique GTS.
# STORE : stocke le résultat dans une variable exp.
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
# Idem pour la classe revenue, stockée dans une variable revenue.
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
# Affiche les 2 séries
$exp
$revenue
A ce stade, vous avez la même représentation graphique que précédemment si vous cliquez sur Dataviz.
Calculons maintenant le résultat mensuel (chiffre d’affaires - dépenses) :
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# Le même bloc que précédemment
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
# Calcul: il suffit se soustraire les deux éléments pour avoir le résultat
$revenue $exp -
# on affiche également les deux autres variables pour la dataviz
$exp
$revenue
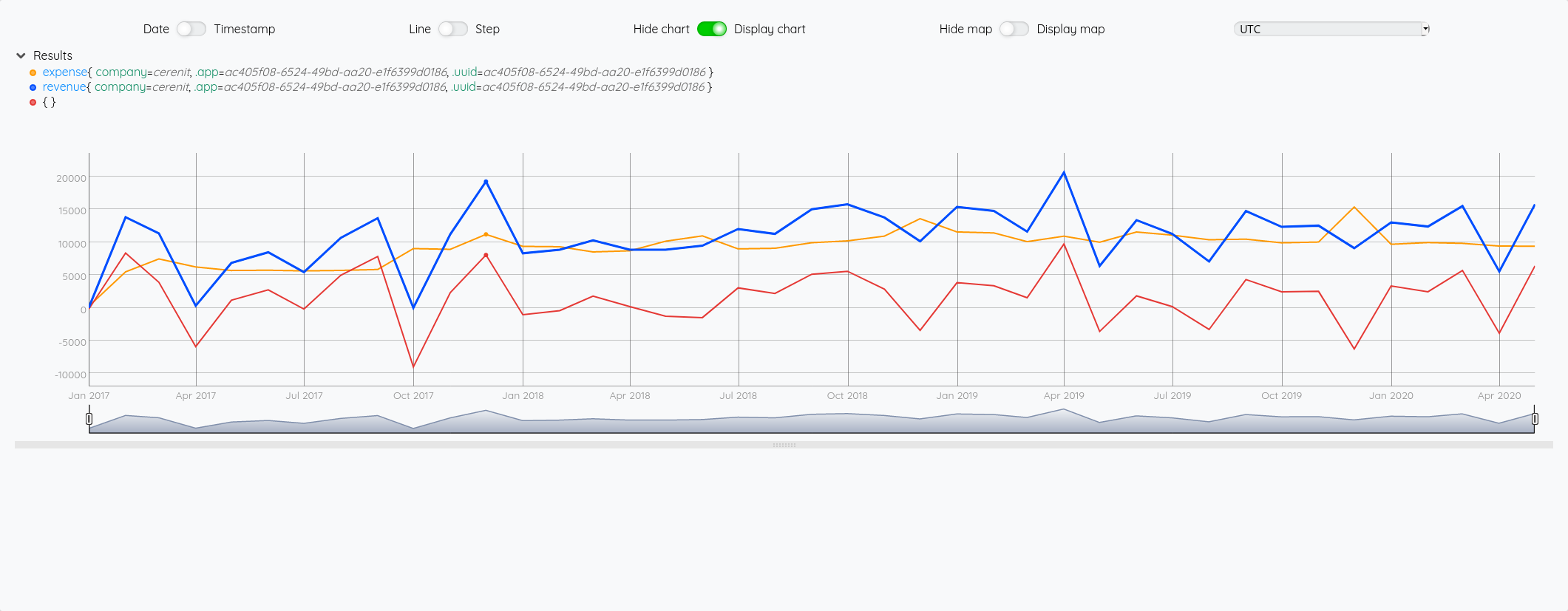
A ce stade :
- Au niveau de la dataviz, la légende ne fournit aucune information sur la nature de la série
- Cette donnée n’est pas encore persistée
Jusqu’à présent, nous avons utilisé que le <readToken> pour lire les données. Pour la persistence, nous allons utilier le <writeToken>.
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# Authentification auprès de l'instance en écriture
'<writeToken>' 'writeToken' STORE
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
# La première ligne est inchangée, elle calcule le résultat mensuel et la donnée est de type GTS
# Du coup, comme nous sommes dans une pile et que l'on hérite de ce qu'il s'est passé avant, on peut lui assigner un nom via RENAME
# Puis lui ajouter le label company avec pour valeur cerenit
# Et utiliser la fonction UPDATE pour stocker en base la GTS ainsi obtenue.
$revenue $exp -
"result" RENAME
{ "company" "cerenit" } RELABEL
$writeToken UPDATE
# Comme pour revenue et expense, on récupère les données sous la forme d'une GTS que l'on stocke dans une variable
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
# On vide la pile
CLEAR
# On affiche les variables créées
$revenue
$exp
$result
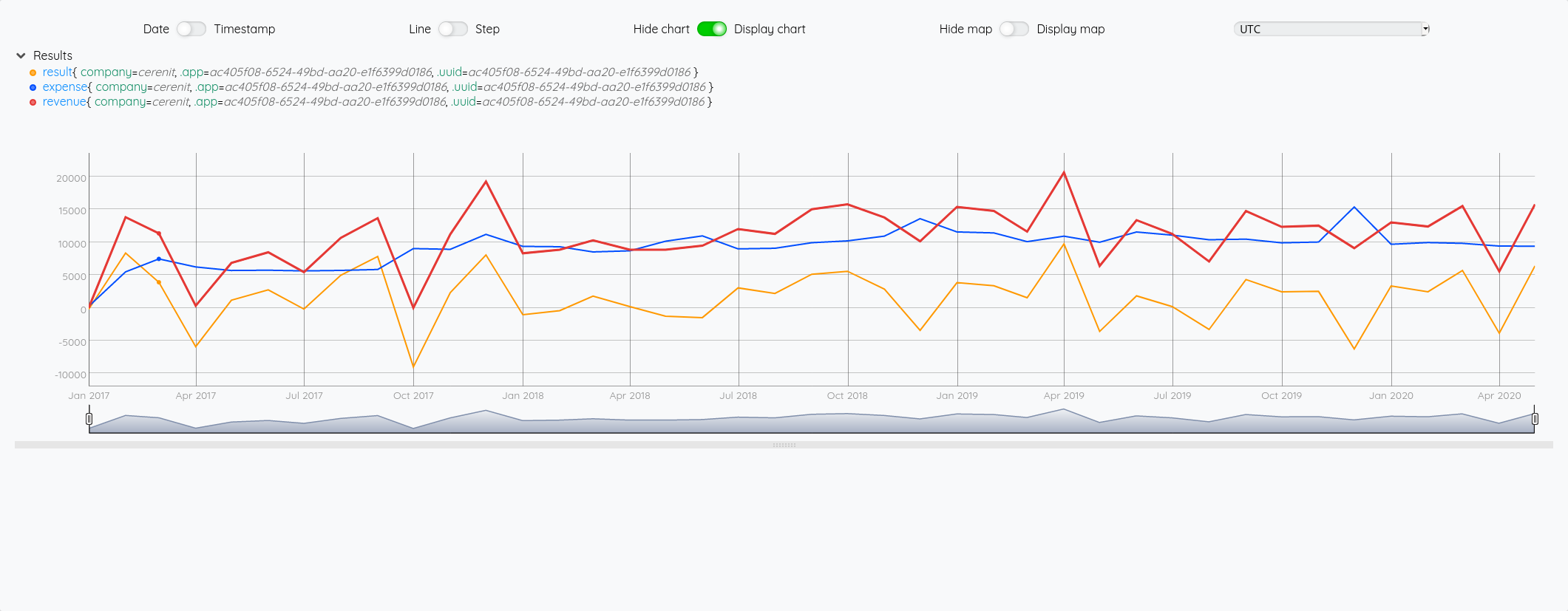
Et voilà !
Prévoyons le futur
Warp10 dispose d’une extension propriétaire et payante permettant d’appliquer des algorithmes de prévisions sur des séries temporelles : warp10-ext-forecasting. Il est possible d’utiliser cette extension sur la Sandbox Warp10 mise à disposition par SenX.
Il existe une fonction AUTO et SAUTO (version saisonnière) qui applique automatiquement des algorythmes d’AutoML sur vos données.
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# Récupération des trois séries
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
CLEAR
$revenue
$exp
$result
# MAP: la fonction `AUTO` s'attend à manipuler des nombres au format `DOUBLE` et non des entiers. Il faut donc faire la conversion.
# FORECAST: sur les données obtenues du MAP, on applique la fonction AUTO et on demande les 8 prochaines occurents (pour aller jusqu'à la fin d'année)
# Le .ADDVALUES permet de "fusionner" les prévisions avec la série parente (sans les persister en base à ce stade)
# Commes les 3 projections sont disponibles dans la pile, elles sont également affichées
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
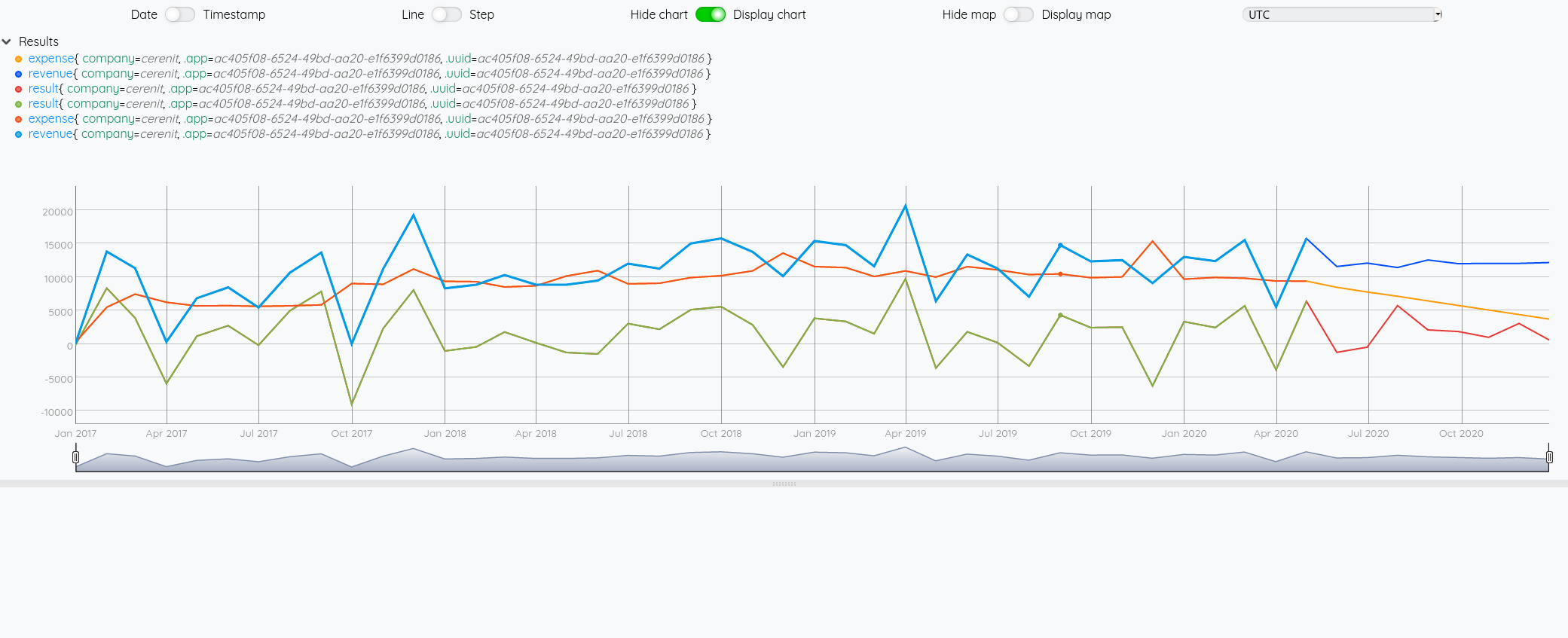
Du fait du FORECAST.ADDVALUES, on pourrait se passer d’afficher les trois premières séries. Mais vistuellement, cela permet de voir la différence entre la série originale et la projection.
Une fois l’effet Whaou passé, on peut se demander quel modèle a été appliqué. Pour cela il y a la fonction MODELINFO
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# Récupération des trois séries
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
CLEAR
[ $result mapper.todouble 0 0 0 ] MAP
AUTO MODELINFO
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO MODELINFO
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO MODELINFO
Dans l’onglet des résultats, on voit l’information: "model": "ARIMA".

Si on veut alors faire la même chose en utilisant le modèle ARIMA :
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
# Récupération des trois séries
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
CLEAR
# SEARCH.ARIMA: applique un modèle ARIMA (ARMA ou ARIMA) sur la GTS passée en paramètre
# FORECAST.ADDVALUES: fait une précision sur les 7 prochaines occurences et les fusionne avec la série sur laquelle la projection est faite.
# Les 3 projections restant dans la pile, elles sont affichées
[ $revenue mapper.todouble 0 0 0 ] MAP
SEARCH.ARIMA
7 FORECAST.ADDVALUES
[ $exp mapper.todouble 0 0 0 ] MAP
SEARCH.ARIMA
7 FORECAST.ADDVALUES
[ $result mapper.todouble 0 0 0 ] MAP
SEARCH.ARIMA
7 FORECAST.ADDVALUES
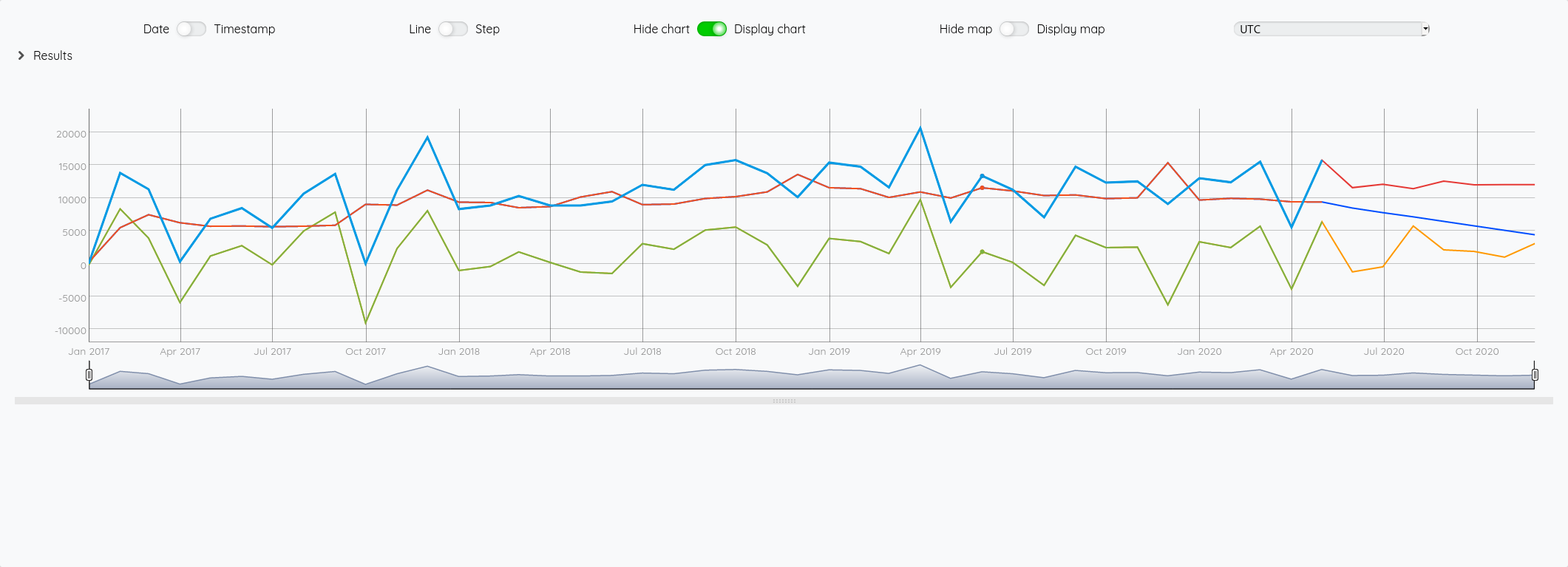
Et nous obtenons bien le même résultat.
On peut se poser alors la question de voir si la projection sur le résultat est la même que la soustraction entre la projection de chiffres d’affaires et de dépenses et mesurer l’éventuel écart.
# Authentification auprès de l'instance en lecture
'<readToken>' 'readToken' STORE
[[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
CLEAR
# La différence sur les 3 projections est que l'on stocke chaque résultat dans une variable
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
'fresult' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
'frevenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 8 FORECAST.ADDVALUES
'fexp' STORE
$frevenue
$fexp
$fresult
# ici on calcule la projection du résultat sur la base des projections de chiffres d'affaires et de dépenses
$frevenue $fexp -
On constate bien un écart entre la courbe orange (la soustraction des projections) et la courbe bleu (la projection du résultat).
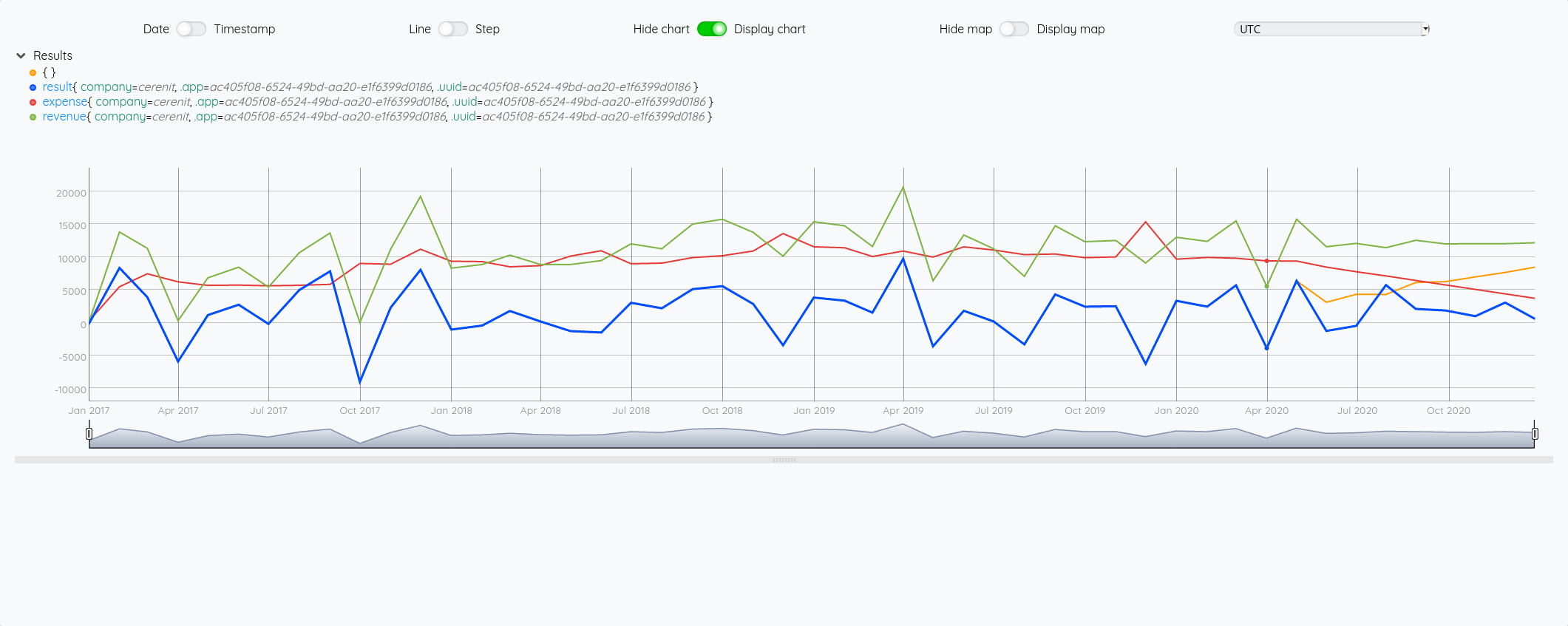
Nous voilà à la fin de ce billet, j’espère que ce tour du propriétaire vous aura permis d’apprécier Warp10 et ses capacités.
Il ne reste plus qu’à voir en fin d’année dans quelles mesures ces projections seront valides ou pas !
Mon bilan sur Warp10 à ce stade :
- Il faut absolument suivre le tutoriel sur les cyclones, cela permet de se mettre progressivement à Warpscript et de comprendre les mécanismes de fonctionnement du langage et de la pile (stack).
- la notation de Warpscript est particulière au début mais on s’y fait petit à petit et sinon FLoWS devrait lever les dernières réticences.
- Comme on a une pile, il ne faut pas hésiter à utiliser
STOPetTYPOEOFnotamment pour savoir ce que l’on manipule comme donnée à un instant T ; cf Debugging WarpScript - Le WarpStudio ou l’extension VSCode permettent d’avoir un contexte de développement agréable avec l’autocomplétion, la documentation des fonctions, etc.
- Contrairement à InfluxDB où tout s’articule autour du measurement (équivalent de la classe ici), le fait d’avoir un langage de manipulation (et pas principalement de requêtage avec quelques transformations) de données permet d’avoir une modélisation plus souple et de réconcilier les données ensuite. Le même exercice dans InfluxDB supposerait d’avoir un seul measurement et d’avoir les différentes valeurs en son sein. Du coup, cela empêcherait le calcul et le stockage du résultat par ex. Il aurait fallu le calculer au préalable et l’insérer dans la base en même temps que les données de chiffre d’affaires et de dépenses pour que les données soient ensemble. Certes Flux et InfluxDB 2.0 vont lever quelques contraintes de modélisation et de manipulation de données, mais le prisme de la modélisation autour du measurement reste primordial dans le produit.
- Avoir un langage de manipulation de données et non uniquement de requêtage et quelques transformation évite aussi de devoir sortir les données pour les analyser puis les renvoyer vers la base de données le cas échéant. Non seulement on reste au plus près de la donnée (éxécution coté serveur) mais on évite aussi les problématiques de drivers, conversion dans les structures de données du langage cible, etc.
- Les classes de warpscript sont certes mono valeurs (même si le multivalue existe) mais je présume que cela sert surtout pour des données de même nature plutôt que pour des données hétérogènes. En effet, il s’agit d’une liste et non d’un tableau de données. (NDLR: Mathias me précise qu’une multivalue est une GTS et non une simple liste - cela est précisé si on lit bien la totalité de la doc de multivalue)
Une expérience au final positive qui pousse à aller creuser plus loin les fonctionnalités de cette plateforme. Ce sera l’opportunité de rédiger d’autres billets à l’avenir.
