Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
InfluxDB et les alertes : Tasks, Checks et Notifications
influxdb timeseries influxdata task flux check notifications kapacitor alertesCérénIT vient de finaliser la migration pour un de ses clients d’un socle InfluxDB/Chronograf/Kapacitor vers InfluxDB2. Ce billet est l’occasion de revenir sur la partie alerting et de la migration de Kapacitor vers des alertes dans InfluxDB2.
Dans le cadre du socle InfluxDB/Chronograf/Kapacitor, le fonctionnement était le suivant :
- Les utilisateurs créent une alerte via l’application métier en définissant un à plusieurs critères d’alertes ; ex: est-ce que l’unité est opérationnelle et est-ce que l’humidité est supérieure à tel taux ou la température supérieure à telle valeur.
- L’application métier traduisait l’alerte en TickScript et enregistrait l’alerte auprès de Kapacitor via son API HTTP
- Kapacitor, en mode streaming, évalue si l’alerte doit être levée ou pas au fur et à mesure de l’arrivée des données
- En cas de seuil franchi, Kapacitor envoie un message à l’application métier via l’API HTTP de cette dernière.
- L’application métier envoie ensuite un mail et/ou un SMS à l’auteur de l’alerte.
Avant d’envisager la migration InfluxDB2, un point de vocabulaire :
- une alerte est globalement composée d’un “check”, d’un endpoint de notiifcation et d’une règle de notification.
- un check est une task simplifiée. Elle permet de définir une requête mono critère, les niveaux de seuils associés (ok, crit, warn, etc) et sa fréquence d’exécution.
- une task est codée flux
- un endpoint de notification : service vers lequel sera envoyé l’alerte: slack, http, etc.
- une règle de notification : les conditions de notifications (ex je passe à un état critique), le check associé, la fréquence d’exécution, le message de notification et le endpoint de notification à utiliser.
Avec la migration InfluxDB2, nous avons voulu maintenir le même mécanisme. Toutefois :
- Les tasks en Flux ne fonctionnent pas en mode streaming, mais uniquement en mode batch et avec une certaine fréquence
- Les checks sont mono-critères et pas multi-critères
Heureusement, la documentation mentionne la possibilité de faire des “custom checks” et un billet très détaillé intitulé “InfluxDB’s Checks and Notifications System” permet de mieux comprendre ce qu’il est possible de faire et donne quelques exemples de code.
Dès lors, il s’agit de :
- développer une tâche “tout en un”, contenant l’ensemble de la logique de l’alerte,
- de conserver un historique des alertes pour permettre d’assurer un suivi des alertes pour l’équipe en charge du projet depuis InfluxDB
- d’être en mesure de notifier l’application métier via son API HTTP
Pour se faire, nous allons nous appuyer sur les mécanismes mis à disposition par Influxdata, à savoir les fonctions monitor.check(), monitor.from() et monitor.notify() et les mécanismes induits.
C’est ce que nous allons voir maintenant :
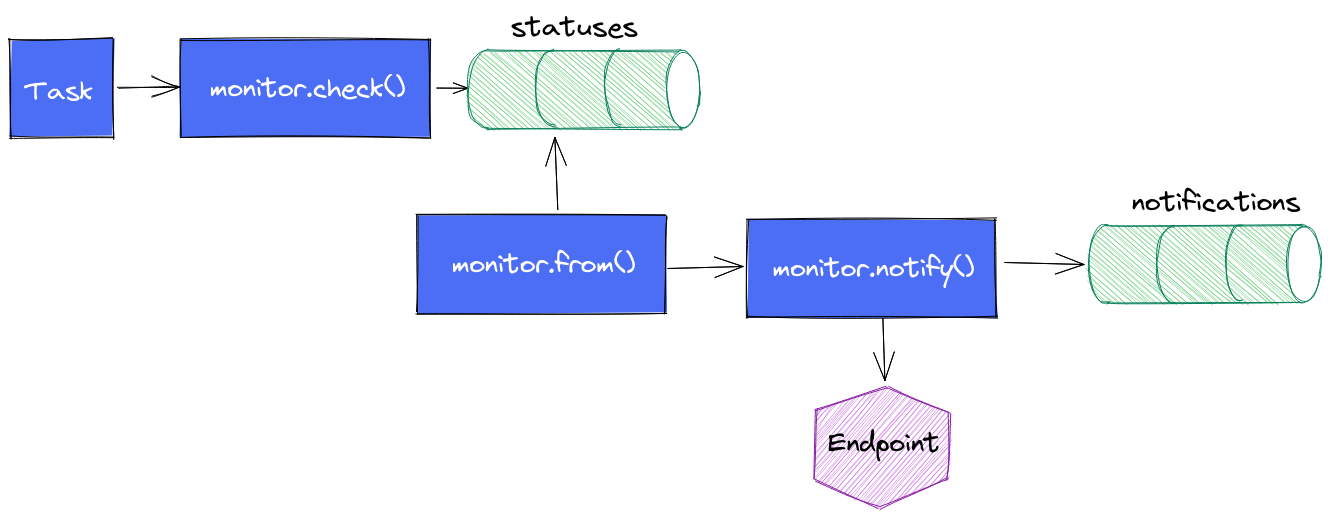
Le cycle de vie d’une alerte est le suivant :
- La task contient une requête en flux plus ou moins complexe en fonction de votre besoin ; ex: quelle est la valeur de la temperature du boitier X depuis la dernière exécution ?
- On appelle
monitor.check()en définissant les informations d’identification du check, le type de check que l’on utilise (threshold, deadman, custom), les différents seuils dont on a besoin, le message à envoyer au endpoint, les données issues de la requête flux. monitor.check()va alors stocker l’ensemble de ces données dans un measurementstatusesdans le bucket_monitoringet il s’arrête là.monitor.from()prend le relais, regarde s’il y a de nouveaux status depuis sa dernière exécution et en fonction des règles de notifications qui ont été définies, il va passer le relaismonitor.notify().monitor.notify()enverra une notification si la règle est validée et il insérera une entrée dans le measurementnotificationsdu bucket_monitoring
Une première version des alertes ont été implémentées sur cette logique. Des dashboards ont été réalisés pour suivre les status et les notifications. Cela fonctionne, pas de soucis ou presque.
Il se peut qu’il y ait un délai entre le moment où l’insertion issue du monitor.check() se fait et le moment où le monitor.from() s’exécute. Si monitor.from() fait sa requête avant l’insertion de données, alors l’alerte ne sera pas immédiatement levée. Elle sera levée à la prochaine exécution de la task, ce qui peut être problématique dans certains cas. Pour une tâche qui s’exécute toutes les minutes, cela ne se voit pas ou presque. Pour une tâche toutes les 5 minutes, ça commence à se voir.
Une version intermédiare de la task est alors née : une fois le monitor.check() exécuté, nous faisons appel à monitor.notify() pour envoyer le message vers le endpoint.
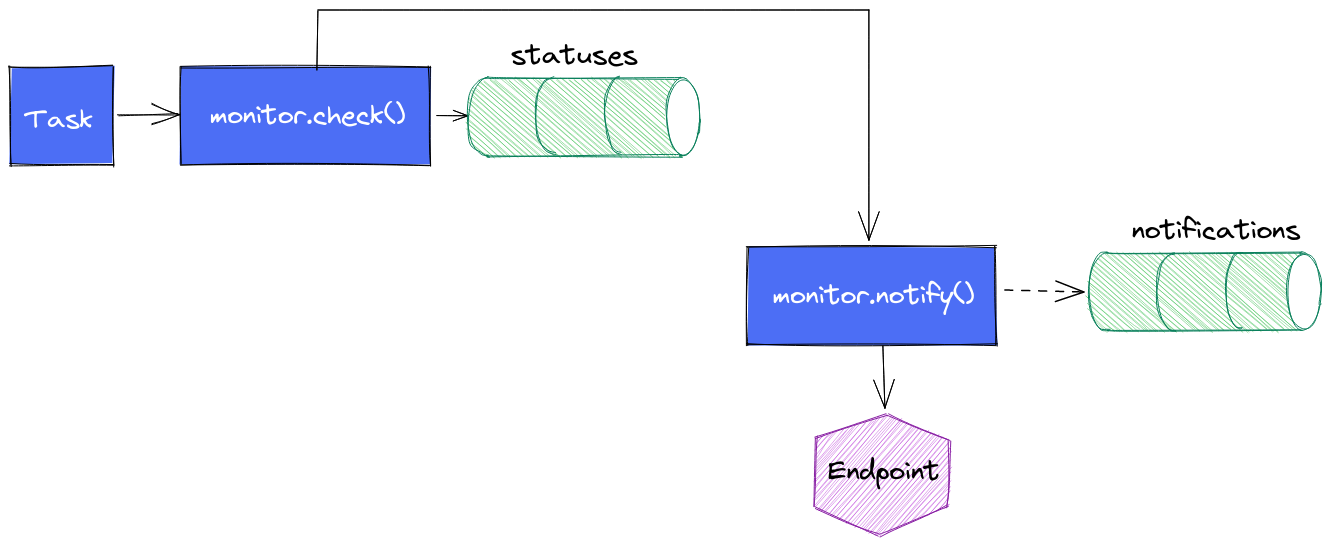
Avantage :
- la notification se déclenche sans délais
Inconvénients :
- cela ne remplit pas le measurement
notificationsde la même façon que précédemment (d’où les pointillés) vu que les données insérées dans le measurementstatusesn’existent pas encore. On perd la visibilité sur les notifications envoyées (mais on a toujours le suivi des statuts ; nous supposons que si on a le statut, alors on sait si la notification a été envoyée) - cela aboutit à un peu de duplication de code sur la gestion des seuils et des messages.
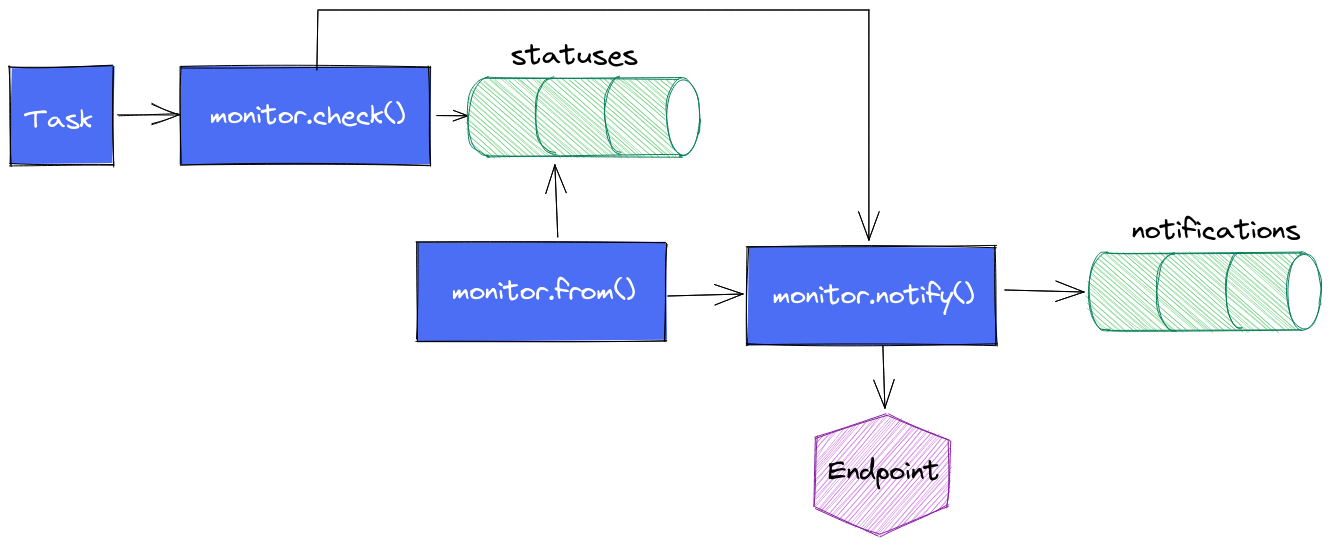
Une variante non essayée à ce stade : elle consiste à faire cette notification au plus tôt mais de conserver le mécanisme de monitor.from() + monitor.notify() pour avoir le measurement notifications correctement mise à jour. A voir si les alertes ne sont pas perturbées par ce double appel à monitor.notify(). Dans le cas présent, c’est l’application métier qui envoie les alertes après que la task InfluxDB ait appelé son API HTTP. Si chaque monitor.notify() en vient à lever une alerte, cela est sans impact pour l’utilisateur. En effet, une fois qu’une alerte est levée, elle est considérée comme levée tant qu’elle n’est pas acquittée. Donc même si la task provoque 2 appels, seul le premier lévera l’alerte et la seconde ne fera rien de plus.
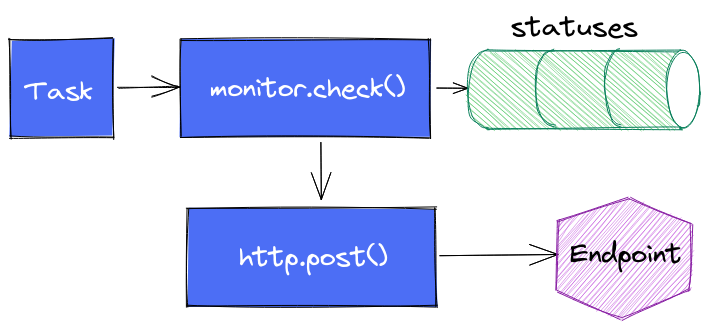
Enfin dernière variante (testée) : s’affranchir complètement de monitor.notify() pour faire directement appel à http.endpoint() et http.post() et faire complètement l’impasse sur le suivi dans notifications.
Tout est une histoire de compromis.
En conclusion, nous pouvons retenir que :
- Une alerte est composée d’un check, d’un endpoint de notification et d’une règle de notification
- En 2.0, le principe est que les alertes sont des séries temporelles via le bucket
_monitoringet les measurementsstatusesetnotifications. - Toute personne s’intéressant au sujet doit lire au préalable InfluxDB’s Checks and Notifications System pour bien comprendre les concepts et les rouages.
- Via la UI, les alertes (checks) sont assez basiques (requête monocritère)
- Il est possible de faire des “custom checks” via des tasks en flux
- Les fonctions du package monitor permettent de gérer des alertes
- Les exécutions dans la même task (ou dans des tasks concomittentes) de
monitor.check()etmonitor.from()peuvent conduire à des décalages de levées d’alertes
