Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Warp 10 - Interactions avec une instance InfluxDB - FLoWS edition
warp10 timeseries influxdb warpscript warpfleet flowsMaintenant que FLoWS est officiellement disponible, je vous propose de revisiter l’article de la semaine dernière Warp 10 - Interactions avec une instance InfluxDB en utliisant FLoWS à la place de WarpScript pour se faire une idée.
Pré-requis: warpfleet
Installons déjà warpfleet, le gestionnaire de package conçu pour Warp 10.
# Installation de npm
sudo dnf install -y npm
# installation de warpfleet
sudo npm install -g @senx/warpfleet
# Vérification de la bonne installation de warpfleet
wf version
___ __ _______________ _____
__ | / /_____ __________________ ____/__ /___________ /_
__ | /| / /_ __ `/_ ___/__ __ \_ /_ __ /_ _ \ _ \ __/
__ |/ |/ / / /_/ /_ / __ /_/ / __/ _ / / __/ __/ /_
____/|__/ \__,_/ /_/ _ .___//_/ /_/ \___/\___/\__/
/_/ ™
version: 1.0.31
1.0.31
Installation de l’extension warp10-ext-influxdb
Sans trop rentrer dans les détails de warpfleet, il utilise un système de namespace appelés “Groups” pour ces packages et qui permettent de définir ses propres dépots. Pour l’extension warp10-ext-influxdb, le “group” est io.warp10.
Ce qui pour l"installation donne la commande suivante :
# Si votre utilisateur n'a pas accès à /path/to/warp10, il vous faudra utiliser sudo
(sudo) wf g -w /path/to/warp10 io.warp10 warp10-ext-influxdb
warpfleet va vous demander quelle version de l’extension vous souhaitez puis va procéder à son téléchargement et son installation.
Cela donne :
sudo wf g -w /opt/warp10 io.warp10 warp10-ext-influxdb
___ __ _______________ _____
__ | / /_____ __________________ ____/__ /___________ /_
__ | /| / /_ __ `/_ ___/__ __ \_ /_ __ /_ _ \ _ \ __/
__ |/ |/ / / /_/ /_ / __ /_/ / __/ _ / / __/ __/ /_
____/|__/ \__,_/ /_/ _ .___//_/ /_/ \___/\___/\__/
/_/ ™
version: 1.0.31
? Which revision do you want to retrieve? latest
✔ ext io.warp10:warp10-ext-influxdb#1.0.1-uberjar retrieved
✔ Download successful: gradle-wrapper.jar
✔ Download successful: gradle-wrapper.properties
✔ Download successful: gradlew
✔ Download successful: gradlew.bat
✔ Dependency warp10-ext-influxdb-1.0.1-uberjar.jar successfully deployed
✔ Done
Note: Pour éviter un bug dans la fonction INFLUXDB.UPDATE identifié lors de la rédaction de ce billet, assurez-vous d’avoir une version >= 1.0.1
Ensuite, il faut créer le fichier /path/to/warp10/etc/conf.d/90--influxdb-extension.conf et y ajouter la ligne suivante:
warpscript.extension.influxdb = io.warp10.script.ext.influxdb.InfluxDBWarpScriptExtension
Je préfère créer un fichier plutôt que d’éditer un fichier existant pour le suivi des mises à jour et j’ai utilisé le prefix 90 car il n’est pas utilisé par les fichiers de Warp10.
Relancer ensuite Warp 10 pour que le plugin soit chargé au démarrage de l’instance :
(sudo) /path/to/warp10/bin/warp10-standalone.init restart
Dans /path/to/warp10/logs/warp10.log, vous devriez voir apparaitre :
2020-09-17T10:59:23,742 main INFO script.WarpScriptLib - LOADED extension 'io.warp10.script.ext.influxdb.InfluxDBWarpScriptExtension'
Installation de FLoWS
Assurez-vous d’avoir préalablement une version >= 2.7.1 de Warp 10
sudo wf g -w /opt/warp10 io.warp10 warp10-ext-flows
___ __ _______________ _____
__ | / /_____ __________________ ____/__ /___________ /_
__ | /| / /_ __ `/_ ___/__ __ \_ /_ __ /_ _ \ _ \ __/
__ |/ |/ / / /_/ /_ / __ /_/ / __/ _ / / __/ __/ /_
____/|__/ \__,_/ /_/ _ .___//_/ /_/ \___/\___/\__/
/_/ ™
version: 1.0.31
? Which revision do you want to retrieve? latest
✔ ext io.warp10:warp10-ext-flows#0.1.0-uberjar retrieved
✔ Download successful: gradle-wrapper.jar
✔ Download successful: gradle-wrapper.properties
✔ Download successful: gradlew
✔ Download successful: gradlew.bat
✔ Dependency warp10-ext-flows-0.1.0-uberjar.jar successfully deployed
warpscript.extension.flows = io.warp10.ext.flows.FLoWSWarpScriptExtension
? Choose what you want to add (Press <space> to select, <a> to toggle all, <i> to invert selection)warpscript.extension.flows = io.warp10.ext.flows.FLoWSWarpScriptExtension
✔ warpscript.extension.flows = io.warp10.ext.flows.FLoWSWarpScriptExtension added to /opt/warp10/etc/conf.d/io.warp10-warp10-ext-flows.conf
✔ Done
Relancer ensuite Warp 10 pour que le plugin soit chargé au démarrage de l’instance :
(sudo) /path/to/warp10/bin/warp10-standalone.init restart
Dans /path/to/warp10/logs/warp10.log, vous devriez voir apparaitre :
2020-10-08T10:59:51,288 main INFO script.WarpScriptLib - LOADED extension 'io.warp10.ext.flows.FLoWSWarpScriptExtension'
Préalable sur FLoWS
FLoWS ne dispose pas encore d’un endpoint /flows ; nous continuons donc à utiliser les “endpoints historiques warpscript compatibles”.
Ce qui nous amène à réaliser une seule action en RPN/NPI (Notation Polonaise Inversée) lorsque l’on soumet du code FLoWS à Warp 10 :
# Multiligne WarpScript qui permet de mettre son code FLoWS
<'
... Code FLoWS ...
'>
# Applique la fonction FLOWS au code ci-dessus
FLOWS
Pour les types, les notations, etc - je voue renvoie au billet de blog introduisant FLoWS.
Requêtage d’une instance InfluxDB 1.x
La semaine dernière nous écrivions en WarpScript :
# Requête INFLUXQL et informations de connection à InfluxDB 1.X
{ 'influxql' "select * from cpu where host=%27myHost%27 and time > now() - 1h" 'db' "myDatabase" 'password' "myPassword" 'user' "myUser" 'url' "http://url.to.influxdb:8086" }
INFLUXDB.FETCH
# On récupère une liste de liste de séries GTS. Il n'y a qu'un seul élément dans cette liste. Nous le prenons pour n'avoir plus qu'une liste de séries GTS.
0 GET
# Sauvegarde de la liste dans une variable cpu
'cpu' STORE
# Affichage de la liste de GTS
$cpu
Cette semaine, nous écrivons en FLoWS :
<'
# Récupération de la liste de GTS
cpu_fetch = INFLUXDB.FETCH({'influxql':'select * from cpu where host=%27myHost%27 and time > now() - 1h', 'db':'myDatabase', 'password':'myPassword', 'user':'myUser', 'url':'http://url.to.influxdb:8086'})
# Récupération de la GTS en prenant l'index 0 de la liste
cpu = GET(cpu_fetch, 0)
# Affichage de la liste de GTS
return cpu
'>
FLOWS
On peut déjà noter :
- la lecture du code correspond plus à nos habitudes dans les autres lanagage
- les fonctions ont les mêmes noms, leur signature ne change pas non plus
- le mot clé
returnest nouveau ici et permet d’afficher la GTS dans le studio par ex. - les tableaux (MAP) sont plus lisibles (arguments séparés par des virugules, la clé et la valeur sont séparés par deux points) et moins sources d’erreurs (gestion des espaces plus sensibles en WarpScript)
Le résultat est identique :
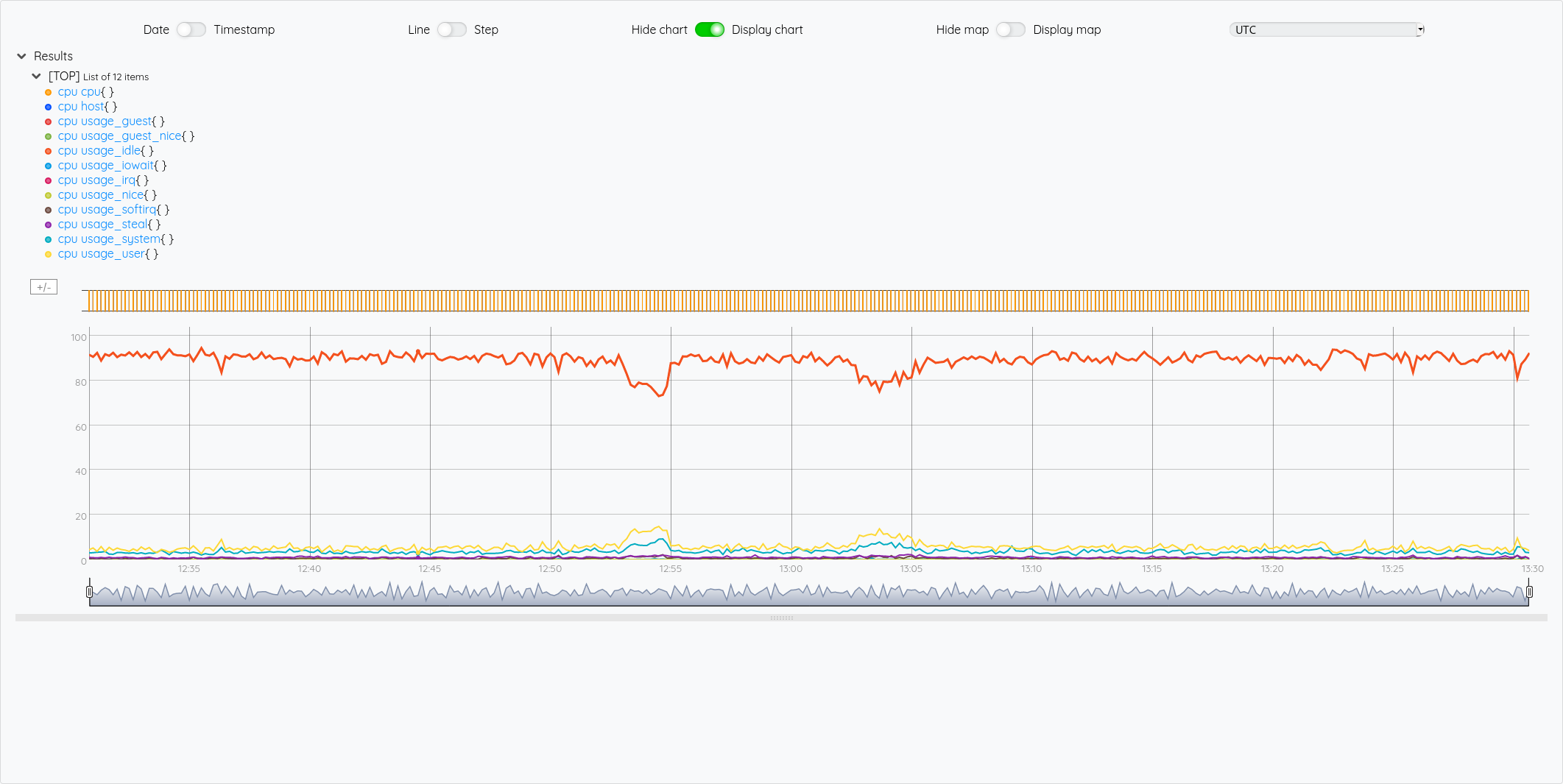
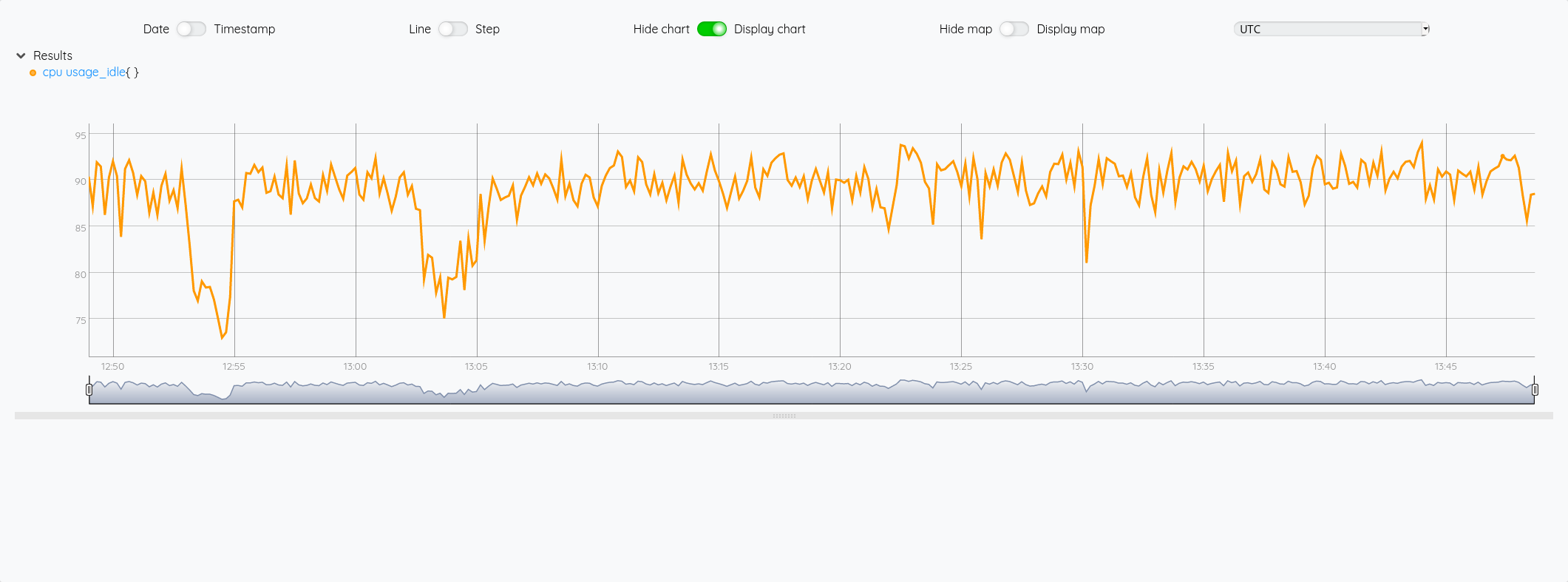
Pour illustrer cette liste de liste de GTS, si on veut récupérer la GTS du cpu idle, on voit dans le graphique que c’est la 5ème courbe, donc un indice 4.
En WarpScript :
{ 'influxql' "select * from cpu where host=%27myHost%27 and time > now() - 1h" 'db' "myDatabase" 'password' "myPassword" 'user' "myUser" 'url' "http://url.to.influxdb:8086" }
INFLUXDB.FETCH
0 GET
'cpu' STORE
# Récupération de la 5ème liste (indice 4)
$cpu 4 GET
En FLoWS :
<'
cpu_fetch = INFLUXDB.FETCH({'influxql':'select * from cpu where host=%27myHost%27 and time > now() - 1h', 'db':'myDatabase', 'password':'myPassword', 'user':'myUser', 'url':'http://url.to.influxdb:8086'})
cpu = GET(cpu_fetch, 0)
# Récupération de la 5ème liste (indice 4)
# on pourrait écrire : return GET(cpu, 4) mais on peut aussi écrire de façon plus concise :
return cpu[4]
'>
FLOWS
Requêtage d’une instance InfluxDB 2.x
La semaine dernière, nous écrivions en WarpScript :
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
<'
from(bucket: "crntbackup")
|> range(start: -1h, stop: now())
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> aggregateWindow(every: 1s, fn: mean, createEmpty: false)
|> yield(name: "mean")
'>
'fluxquery' STORE
# Paramètres de la fonction INFLUX.FLUX avec la requête flux (la variable fluxquery) et les informations de connection à InfluxDB 2.x
{ 'flux' $fluxquery 'org' "myOrganisation" 'token' "myToken" 'url' "http://url.to.influxdb2:9999" }
INFLUXDB.FLUX
# Sauvegarde de la liste dans une variable cpu
'cpu' STORE
# Affichage de la liste de GTS
$cpu
En FLoWS :
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
<'
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
fluxquery = 'from(bucket: "crntbackup")
|> range(start: -1h, stop: now())
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> aggregateWindow(every: 1s, fn: mean, createEmpty: false)
|> yield(name: "mean")'
# Paramètres de la fonction INFLUX.FLUX avec la requête flux (la variable fluxquery) et les informations de connection à InfluxDB 2.x
params = {'flux':fluxquery, 'org':'myOrganisation', 'token':'myToken', 'url':'http://url.to.influxdb2:9999' }
# Sauvegarde de la liste dans une variable cpu
cpu = INFLUXDB.FLUX(params)
# Affichage de la liste de GTS
return cpu
'>
FLOWS
On obtient :
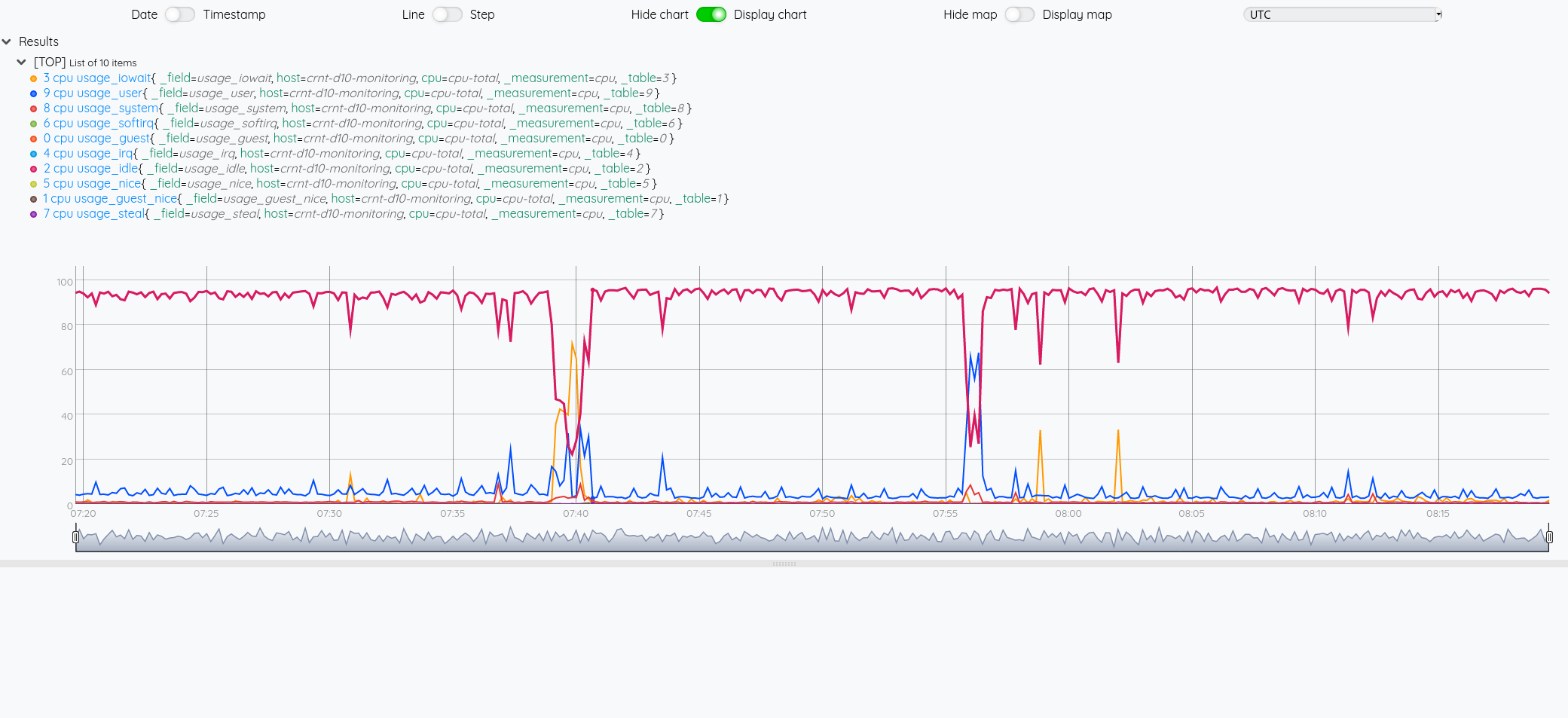
Si on veut comme précédemment avec InfluxQL afficher la courbe du CPU idle.
En WarpScript :
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
<'
from(bucket: "crntbackup")
|> range(start: -1h, stop: now())
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> aggregateWindow(every: 1s, fn: mean, createEmpty: false)
|> yield(name: "mean")
'>
'fluxquery' STORE
# Paramètres de la fonction INFLUX.FLUX avec la requête flux (la variable fluxquery) et les informations de connection à InfluxDB 2.x
{ 'flux' $fluxquery 'org' "myOrganisation" 'token' "myToken" 'url' "http://url.to.influxdb2:9999" }
INFLUXDB.FLUX
# Sauvegarde de la liste dans une variable cpu
'cpu' STORE
# Affiche la 7eme liste (incide 6)
$cpu 6 GET
En FLoWS :
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
<'
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
fluxquery = 'from(bucket: "crntbackup")
|> range(start: -1h, stop: now())
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> aggregateWindow(every: 1s, fn: mean, createEmpty: false)
|> yield(name: "mean")'
# Paramètres de la fonction INFLUX.FLUX avec la requête flux (la variable fluxquery) et les informations de connection à InfluxDB 2.x
params = {'flux':fluxquery, 'org':'myOrganisation', 'token':'myToken', 'url':'http://url.to.influxdb2:9999' }
# Sauvegarde de la liste dans une variable cpu
cpu = INFLUXDB.FLUX(params)
# Affiche la 7eme liste (incide 6)
return cpu[6]
'>
FLOWS
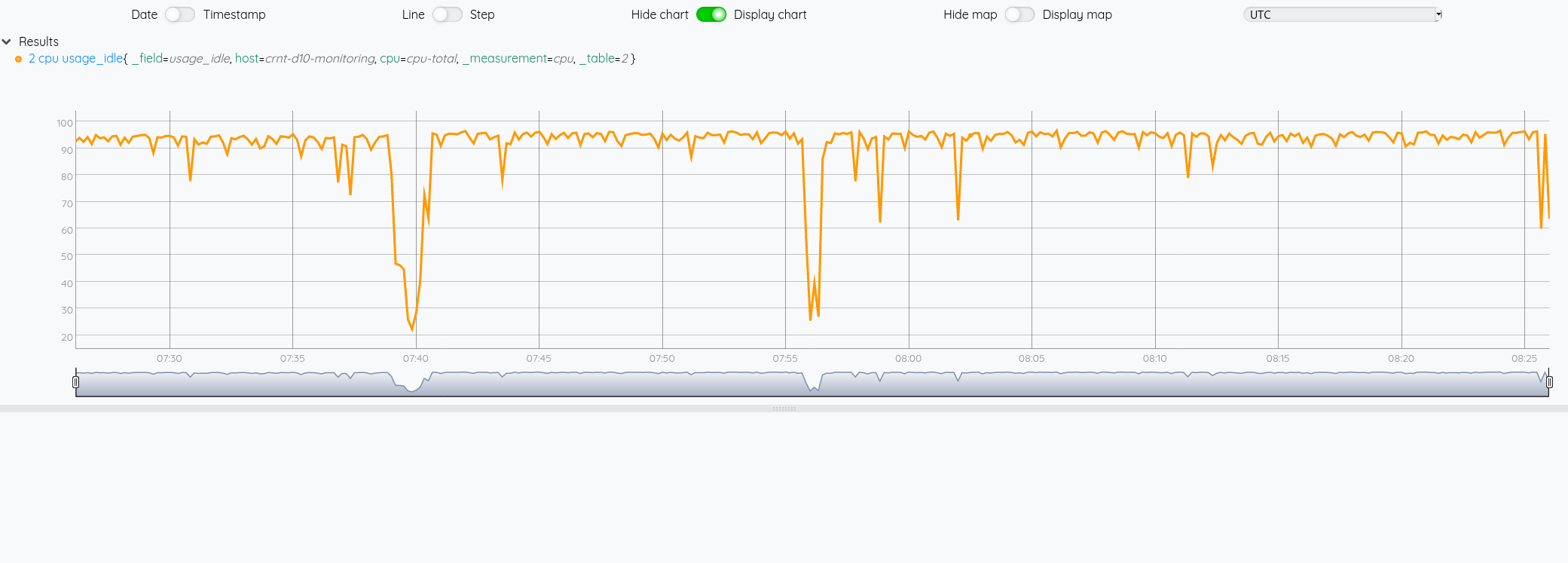
Sauvegarder des données dans InfluxDB
La semaine dernière, nous écrivions en WarpScript :
'<read_token>' 'readToken' STORE
'<write_token>' 'writeToken' STORE
# Récupération des dépenses sous la forme d'une série (GTS)
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
# Récupération du chiffre d'affaires mensuel sous la forme d'une série (GTS)
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
# Calcul du résulat mensuel
$revenue $exp -
# Stockage de la série obtenue dans une série appelée "result"
"result" RENAME
{ "company" "cerenit" } RELABEL
$writeToken UPDATE
# Récupération du résultat mensuel sous la forme d'une série (GTS)
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
# Version 1.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' true 'url' "http://url.to.influxdb:8086" 'measurement' "result" 'db' "crntcompta" 'password' "myPassword" 'user' "myUser" }
'params' STORE
# Utilisatoin de la fonction INFLUXDB.UPDATE qui prend la variable 'params' pour les paramètres de connection et une GTS ou liste de GTS pour les données à sauvegarder
$result $params INFLUXDB.UPDATE
# Version 2.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' false 'url' "http://url.to.influxdb:9999" 'measurement' "result" 'bucket' "crntcompta" 'token' "myToken" 'org' "myOrganisation" }
'params' STORE
$result $params INFLUXDB.UPDATE
En FLoWS, cela donne :
<'
# Gestion des tokens de lecture et écriture
readToken = '<read_token>'
writeToken = '<write_token>'
# Récupération de la liste de GTS dans Warp 10
expense_fetch = FETCH([readToken, 'expense', {'company':'cerenit'}, '2016-12-01T00:00:00Z', '2020-06-01T00:00:00Z'])
# On n'a toujours qu'une liste à 1 élement, on récupère donc la GTS en prenant l'index 0 de la liste
expense = expense_fetch[0]
# Même logique pour le chiffre d'affaires
revenue_fetch = FETCH([readToken, 'revenue', {'company':'cerenit'}, '2016-12-01T00:00:00Z', '2020-06-01T00:00:00Z'])
revenue = revenue_fetch[0]
# On calcule la résultat en faisant la différence entre les 2 GTS revenue et expense
r = revenue - expense
# la GTS obtenue n'ayant pas de nom, on lui en fournit un
RENAME(r, 'result')
# On ajoute les labels manquants
RELABEL(r, {"company":"cerenit"})
# On persiste la GTS dans Warp 10
UPDATE(r, writeToken)
# On récupère la contenu de la GTS result sur le même modèle que revenue et expense précédemment
result_fetch = FETCH([readToken, 'result', {'company':'cerenit'}, '2016-12-01T00:00:00Z', '2020-06-01T00:00:00Z'])
result = result_fetch[0]
# InfluxDB 1.X
# Définition des paramètres de connection
params = {'v1':true, 'url':"http://url.to.influxdb:8086", 'measurement':"result", 'db':"crntcompta", 'password':"myPassword", 'user':"myUser"}
# Persistance des données dans InfluxDB 1.x
INFLUXDB.UPDATE(result, params)
# InfluxDB 2.X
# Définition des paramètres de connection
params = {'v1':false, 'url':"http://url.to.influxdb:9999", 'measurement':"result", 'bucket':"crntcompta", 'token':"myToken", 'org':"myOrganisation" }
# Persistance des données dans InfluxDB 2.x
INFLUXDB.UPDATE(result, params)
'>
# Fin du code FLoWS
# Application de la fonction FLOWS à notre ensemble de code
FLOWS
Coté InfluxDB, on retrouve bien nos données :
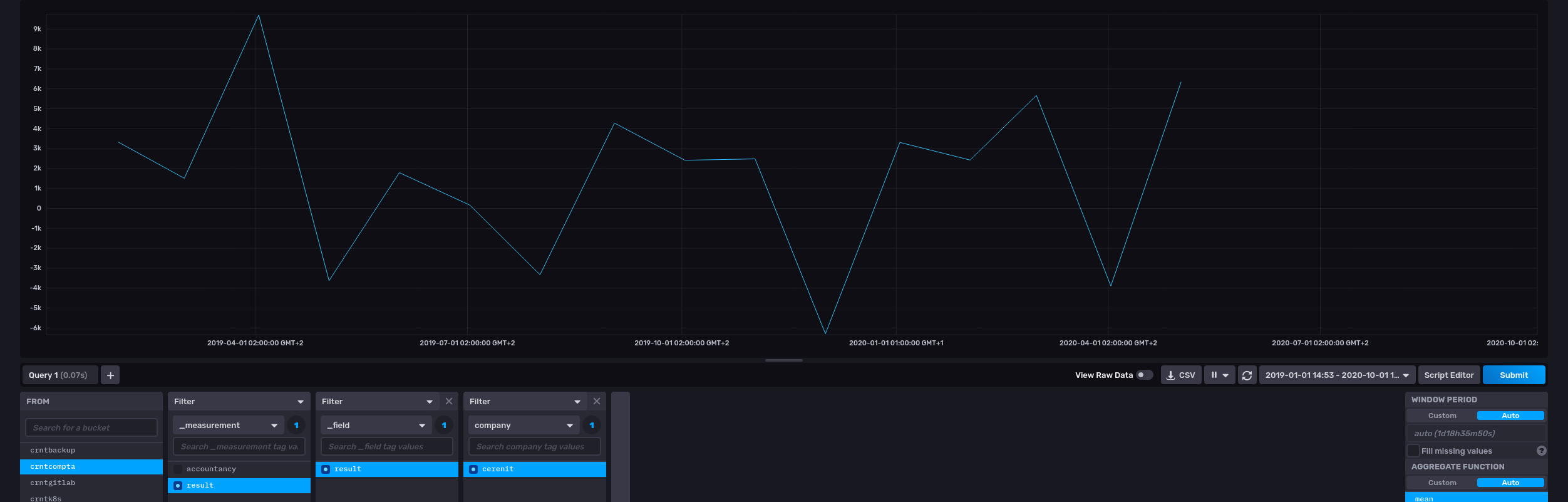
Si au contraire, je veux regrouper plusieurs valeurs dans un même measurement InfluxDB, il faut passer une liste de GTS à INFLUXDB.UPDATE.
La semaine dernière, nous écrivions en WarpScript :
# Version 1.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' true 'url' "http://url.to.influxdb:8086" 'measurement' "accountancy" 'db' "crntcompta" 'password' "myPassword" 'user' "myUser" }
'params' STORE
# Passage d'une liste de GTS plutôt qu'une seule série de l'expemple précédent
[ $result $revenue $exp ] $params INFLUXDB.UPDATE
# Version 2.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' false 'url' "http://url.to.influxdb:9999" 'measurement' "accountancy" 'bucket' "crntcompta" 'token' "myToken" 'org' "myOrganisation" }
'params' STORE
# Passage d'une liste de GTS plutôt qu'une seule série de l'expemple précédent
[ $result $revenue $exp ] $params INFLUXDB.UPDATE
Cette semaine en FLoWS :
# InfluxDB 1.X
# Définition des paramètres de connection
params = {'v1':true, 'url':'http://url.to.influxdb:8086', 'measurement':'result', 'db':'crntcompta', 'password':'myPassword', 'user':'myUser'}
# Persistance des données dans InfluxDB 1.x en passant une liste de GTS
INFLUXDB.UPDATE([result, revenue, expense], params)
# InfluxDB 2.X
# Définition des paramètres de connection
params = {'v1':false, 'url':'http://url.to.influxdb:9999', 'measurement':'result', 'bucket':'crntcompta', 'token':'myToken', 'org':'myOrganisation' }
# Persistance des données dans InfluxDB 2.x en passant une liste de GTS
INFLUXDB.UPDATE([result, revenue, expense], params)
'>
FLOWS
Coté InfluxDB, on retrouve bien nos données :
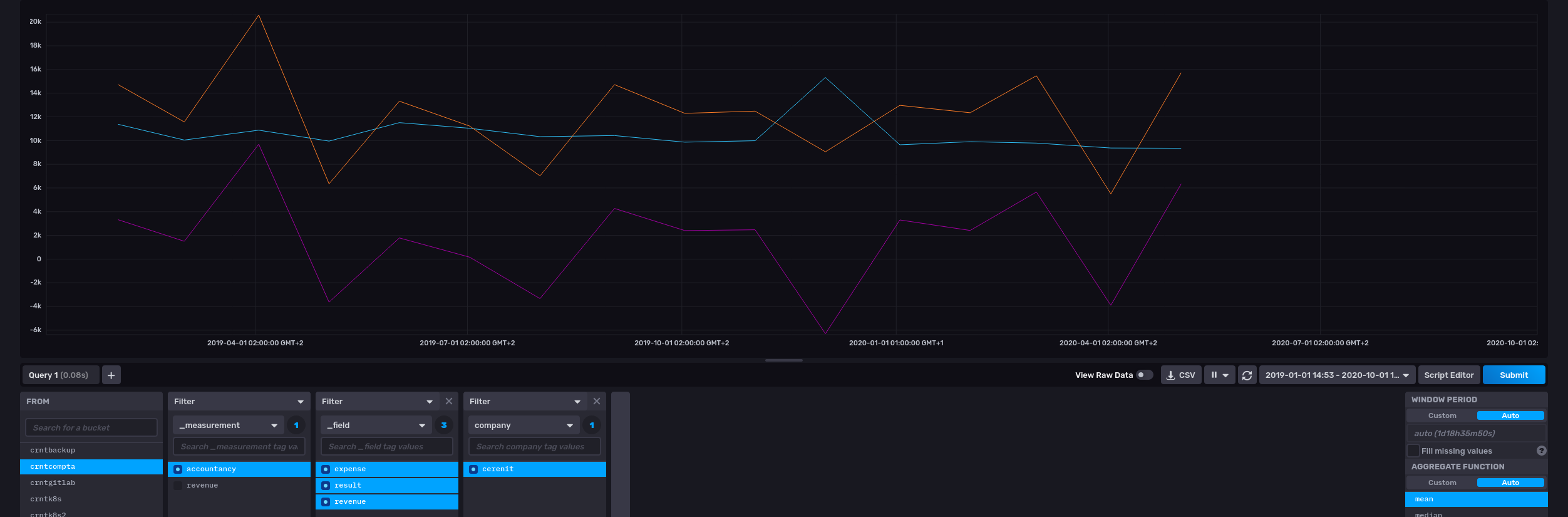
Conclusion
Personnellement, au travers de cette exercice, je trouve FLoWS plutôt agréable à utiliser et il remplit bien son objectif de faciliter la prise en main de Warp 10 :
- Même si je commençais à m’habituer à la NPI/RPN, avoir une approche plus traditionnelle évite de devoir se concentrer sur l’ordre,
- La séparation par des virgules et/ou par des deux points (:) dans les listes et tableaux (MAP) facilitent leur lisiblité
- La migration d’un code en Warpscript vers FLoWS peut se faire de façon très progressive puisque les deux peuvent cohabiter ; c’est d’ailleurs comme ça que j’ai procédé pour ce billet et valider ainsi que je ne perdais rien au fur et à mesure. Il suffit à la fin d’enlever tous les blocs intermédiaires pour n’avoir plus qu’un seul bloc de code en FLoWS. C’est plutôt malin ! Et si une extension ou un code ne serait pas encore disponible en FLoWS, il est possible de débrancher sur du Warpscript.
- Il manque la complétion FLOWS dans le studio (et VSCode je présume) mais c’est pour bientôt !
- Le code gagne en lisiblité car on identifie les blocs qui vont ensemble.
Pour illustrer ce dernier point : quand je repense au code du tutoriel sur les cyclone “Number per year”, nous avons ce code à un moment :
$fetch_wind $end $end $start - TIMECLIP NONEMPTY SIZE
La fonction TIMECLIP prend trois arguments sauf que là, j’en vois potentiellement cinq. Il faut alors comprendre que le troisième argument est en fait le résulat de l’opération $end $start -.
En FLoWS, on aura alors :
TIMECLIP(fetch_wind, end, end - start)
et au global (non testé) :
SIZE(NONEMPTY(TIMECLIP(fetch_wind, end, end - start)))
Ce qui me semble nettement plus clair/lisible.
Le pari de FLoWS était de rendre Warp 10 plus accessible et de rendre les développeurs productifs plus rapidement, il semblerait bien que les objectifs soient remplis.
