Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Web, Ops, Data et Time Series - Avril 2021
falco sysdig sécurité dashboard raspberrypi pico hashicorp vault vector containerd git git-filter-repo psp gitlab-ci podman warp10 sqlite terraform timescale velero docker docker compose grafana loki tempo kubernetes minio influxdata notebook geospatial agpl bme680 co2Code
- Docteur, j’ai commité 8 Go dans mon Git. C’est grave ? : un petit exemple de l’utilisation de git-filter-repo pour nettoyer son historique git de fichiers inutiles.
- Les pipelines parent-enfant de gitlab-ci : article sur la modularisation de gitlab-ci avec les pipelines parent/enfant au sein d’un même dépôt de code ou entre plusieurs dépot avec passage de variables entre eux.
- Minio Changes License to AGPL : Minio passe (aussi) son code en AGPL, l’annonce officielle n’est pas encore arrivée.
Conteneur et orchestration
- Electro Monkeys - Docker Compose avec Nicolas de Loof : Retour sur la Developper Experience autour de Docker, l’historique et le futur de docker-compose, la création de la spécification Compose, les intégrations AWS/ECS et Azure/ACI, l’intégration Kubernetes, etc.
- nerdctl: Docker-compatible CLI for contaiNERD : une CLI qui imite la CLI Docker mais en interagissant directement avec containerd. Elle permet aussi de bénéficier de certaines fonctionnalités de containerd qui ne sont pas prévues pour tout de suite dans Docker apparemment.
- Blog: Kubernetes 1.21: Power to the Community : au programme de cette nouvelle version : Cronjobs GA, Immutable Secrets and ConfigMaps GA, IPv4/IPv6 dual-stack support, Graceful Node Shutdown, PersistentVolume Health Monitor mais aussi PodSecurityPolicy Deprecation et TopologyKeys Deprecation
- PodSecurityPolicy Deprecation: Past, Present, and Future: article plus détaillé sur la dépréciation des PSP.
- Podman v3.1.0 Released : ajout de la gestion des secrets, améliorations des commandes kube avec notamment la génération des PersistentVolumeClaim ou encore la gestion des propriétaires des volumes.
- Velero 1.6.0 : améliorations diverses comme le support des identifiants par buckets (et non globaux uniquement), mise à jour de restic vers 0.12.0, etc.
- Compose CLI Tech Preview :
composedevrait devenir une sous-commande officiel de la CLI Docker ; on pourra alors fairedocker compose up -d - Docker 20.10.6 : version de maintenance avec le support des puces Apple Silicon M1.
- Kubernetes : vers 3 releases par an au lieu de 4 : de quoi courrir un peu moins derrière les versions et à relier avec le support de chaque version étendue à 1 an depuis la 1.19.
Data
- sq: swiss-army knife for data : le
jqpour les données relationelles. Du SQL ou des fichiers Excel/CSV/JOSN/XML en entrée et les mêmes formats en sortie (et un peu plus). - SQLite is not a toy database : On a souvent une fausse image de sqlite - l’article permet de se mettre à jour…
IaC
- Conditional nested blocks in Terraform : si les dynamic blocks avec terraform sont utiles pour peupler dynamiquement des structures à partir de tableaux/listes/objets, il peut aussi être utiliser pour gérer la présence conditionnelle de blocs.
- Announcing HashiCorp Terraform 0.15 General Availability : la plus grosse annonce étant que la 0.15 initie les travaux en vue de la release 1.0 ; pour ceux qui sont à jour, la mise à jour ne devait pas poser de problèmes (cf guide). Pour plus d’informations, cf CHANGELOG.
- HashiCorp is the latest victim of Codecov supply-chain attack : victime de la supply chain attach de codecov, Hashicorp vient de publier les versions patchées de Terraform des versions 0.11 à 0.15. Faites la mise à jour rapidement même si la clé volée n’a a priori pas été utilisée frauduleusement.
IoT
- Pico 2 Pi Adapter Board : un petit adapteur sympathique pour Raspeberry Pi Pico et vous permettre de brancher facilement vos composants sans soudure et mener ainsi vos expériences.
- Piper Make : Pour programmer facilement votre Raspberry Pi Pico en MicroPython mais avec une logique de blocs à la Scratch.
- Utilisation des BME680 et RV3028 avec Raspberry Pi Pico : le composant BME680 permet d’évaluer la qualité de l’air - le projet permet donc de capturer et d’afficher cette information avec un Raspberry Pi. Son successeur, le BME688 dispose d’une pincée d’IA.
- Projet CO2 et Makers CO2 : pour mieux comprendre les enjeux autour de l’aération des pièces et comment faire vos capteurs.
Observabilité & Monitoring
- Coder ses dashboards Grafana avec Grafonnet : Grafonnet est une extension de jsonnet ; il permet de déclarer ses dashboards Grafana via un lanage formalisé plutôt que de copier/coller des dashboards en JSON. Cela permet ainsi d’avoir une approche un peu plus “Dashboard as code”.
- Grafana 7.5 released: Loki alerting and label browser for logs, next-generation pie chart, and more! : un nouveau panel pour les “camembers” (“pie charts”), des améliorations pour les autres produits grafana (loki, tempo), ainsi qu’Elasticsearch, Postgresql et Cloudwatch et sur la version Entreprise.
- Vector v0.12.0 Release Notes, 0.12.1, 0.12.2 : Comme indiqué en février, la release de Vector apportant leur nouveau langage de traitement “Vector Remap Language est disponible, ainsi que des améliorations sur
vector top, la sourceinternal_logset l’API GraphQL. Un guide de mise à jour vers la nouvelle syntaxe est disponible. - Release Announcement: Telegraf 1.18.1 : version de maintenance
- Grafana, Loki, and Tempo will be relicensed to AGPLv3 & Q&A with Grafana Labs CEO Raj Dutt about our licensing changes : les produits phares de Grafana Labs passent d’une licence Apache 2 à AGPLv3. Les autres produits pourront rester sous licence ASL 2.0. L’AGPL étant contaminante, cela pourrait interdire l’usage de ces produits dans certains contextes, y compris à la CNCF. Vu l’implication de Grafana Labs dans le monde Prometheus, il va falloir suivre comment cela va se passer.
Réseau
- The Mystery of AS8003 : Une entité inconnue jusque là mais liée à l’administration américaine a annoncé la gestion d’une très grande plage réseau. Les implications et les motivations sont encore à éclaircir. Le billet émet différents hypothèses. Le thread twitter associé est intéressant aussi.
Sécurité
- Electro Monkeys - La sécurité dans tous ses états – détection de comportements indésirables grâce à Falco avec Thomas Labarussias : Présentation des projets falco et sysdig qui permettent d’analyser les comportements de vos applications (conteneurisées ou pas) en se basant sur les syscalls.
- Announcing HashiCorp Vault 1.7 : version mineure avec des améliorations internes au produit, sur la version entreprise et un peu au niveau UI.
Time Series
- InfluxDays EMEA 2021 Virtual Experience : InfluxData organise la session européenne de sa conférence avec le point sur les différents produits et les développements à venir. Des nouvelles de l’écosystème (Grafana, etc) sont attendues aussi, ainsi que des retours clients. Des formations Flux et Telegraf sont aussi prévues respectivement les 10/11 mai et le 17 Mai.
- InfluxData releases InfluxDB Notebooks to enhance collaboration for teams working with time series data & Build notebooks in InfluxDB Cloud | InfluxDB Cloud Documentation : InfluxData lance son offre de notebook intégré à sa plareforme InfluxDB (version cloud uniquement pour le moment)
- Build a Complete Application with Warp 10, from TCP Stream to Dashboard : exemple complet de l’utilisation de la plateforme Warp 10 depuis l’ingestion des messages AIS des bateaux via un client TCP jusqu’à la visualisation des données après un passage par les étapes de stockage et nettoyage des données. Très intéressant même si je vais devoir relire tranquillement le billet pour bien comprendre certaines astuces et certains “raccourcis” au niveau du code.
- Working with GEOSHAPEs & Working with GEOSHAPEs: code contest! : un billet (et un concours) pour exploiter la dimension géospatiale de Warp 10.
- TimescaleDB 2.2.0 : diverses améliorations mais surtout une annonce sur la fin de support de Postgresql 11 à compter de mi-juin et de la prochaine version de TimescaleDB. C’est justifié par l’absence d’une fonctionnalité dans Postgresql 11.x et requise pour la prochaine version de TimescaleDB.
Web, Ops, Data et Time Series - Mars 2021
gke gcp kubernetes nomad hashicorp consul vault timescale warp10 iot ptsm tsfr spark databricks tempo indluxdataLa prochaine édition de Time Series France aura lieu le mardi 30 Mars à 18h avec la présentation de la base StuteoDB, basée sur Apache Cassandra. Par ici pour les détails et inscriptions.
Container et orchestration
- Introducing GKE Autopilot | Google Cloud Blog : Google sort sa version de GKE où l’on ne gère plus les nodes. Intéressant sur le papier mais cela suppose aussi de bien définir ses limits/requests pour payer le bon prix.
- GKE Autopilot, with Yochay Kiriaty - #139 - Kubernetes Podcast: Episode du Kubernetes Podcast sur GKE Autopilot
- A Kubernetes User’s Guide to HashiCorp Nomad : Nomad peut être vu comme une solution d’orchestration de conteneurs plus légère et simple que Kubernetes. Néanmoins, elle n’est pas aussi complète - il faudra vite rajouter Consul et Vault dans l’équation.
- Hashicorp Nomad 1.0.4 : version de maintenance apportant ses améliorations et ses correctifs.
- Hashicorp Vault 1.6.3 : version de maintenance avec un correctif de sécurité
- Hashicorp Consul 1.9.4 : version de maintenance apportant ses améliorations et ses correctifs.
- Docker 20.10.4 et 20.10.5: version de maintenance
Time Series
- TimescaleDB 2.1.0 : Support de Postgresql 13.2+ et support des ajouts et renommage de colonnes pour les hypertables
- TimescaleDB 2.0.2 : Version de maintenance
- Warp 10 2.7.4 : Version de maintenance, correction d’un bug sur datalog lors avec l’image docker
- Warp 10 2.7.5 : Version de maintenance, rajout du fichier VERSION perdu en 2.7.4, ajout des fonctions de crypto autour de “Shamir Secret Sharing Scheme” (->SSSS et ->SSSS)/
- Edge computing: Build your own IoT Platform : Article très détaillé sur l’utliisation de Warp 10 dans un contexte IoT, depuis la partie edge jusqu’à la partie centrale de votre projet.
- Review of DELL compatible batteries using Warp 10 : Ex de l’usage de CALL pour appeler un script local et en récupérer les données puis les manipuler et les ingérer dans Warp 10
- Paris Time Series Meetup devient Time Series France : Pour être plus représentatif de l’audience et des contributeurs, le PTSM se renomme Time Series France
- TL;DR InfluxDB Tech Tips — Time Series Forecasting with Telegraf : Telegraf dispose de processeurs que l’on peut exécuter sur les données collectées. Dans cet exemple, la donnée est enrichie par le résultat d’un traitement de prévision de valeurs. Si d’un coté, on peut s’étonner de faire des traitements à l’endroit de la collecte et se demander si c’est une bonne idée d’un point de vue ressources matérielles ou profondeur de données disponibles pour le traitement, d’un autre cela ouvre aussi des possibilités dans un déploiement de type “edge” pour permettre des traitements au plus proche et au plus rapide avec une boucle de feedbacks très courte.
- databrickslabs/tempo - replay du meetup de présentation de Tempo: Databricks propose la librairie Tempo à utiliser avec Spark pour préparer et manipuler plus facilement des données de type séries temporelles.
- Getting Started with Time Series Data Science : InfluxData publie une collection d’articles et de ressources sur la manipulation des données issues d’InfluxDB d’un stade débutant à un stade plus avancé.
- Release Announcement: Telegraf 1.18.0 & New in Telegraf 1.18.0: Beat, Directory, NFS, XML, Sensu, SignalFX and More! : nouvelle version de l’agent de collecte Telegraf avec un lot conséquent d’améliorations.
Ma comptabilité, une série temporelle comme les autres - partie 4 - dashboards
warp10 timeseries comptabilité discovery dashboardSuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale
- Partie 4 - Dashboards (ce billet)
- Partie 5 - Les FEC et le compte 512
- Partie 6 - Les FEC et le compte de résultat
Nous allons voir aujourd’hui comment présenter ces données à l’aide de Discovery, la solution de Dashboard as Code pour Warp 10 fournie par SenX.
Installation de Discovery
Tout est décrit dans le billet Truly Dynamic Dashboards as Code
Dans mon cas, warp 10 est dans une partition dédiée /srv/warp10 - warp 10 est donc installé dans /srv/warp10/warp10. C’est la valeur de $WARP10_HOME.
Pour la configuration du plugin HTTP, j’ai un fichier $WARP10_HOME/etc/conf.d/80-discovery.conf contenant :
# Load the HTTP Plugin
warp10.plugin.http = io.warp10.plugins.http.HTTPWarp10Plugin
# Define the directory where endpoint spec files will reside
http.dir = /srv/warp10/discovery
# Define the host and port the plugin should bind to
http.host = 127.0.0.1
http.port = 8081
# Expose the Directory and Store so FETCH requests can be performed via the plugin
egress.clients.expose = true
Le plugin HTTP sera donc accessible via une url de base en http://127.0.0.1:8081/
J’ai ensuite créé le fichier /srv/warp10/discovery/discovery.mc2 où /srv/warp10/discovery est la valeur associée à http.dir dans le fichier précédent.
{
'path' '/discovery/'
'prefix' true
'parsePayload' true
'macro' <%
'cerenit/dashboards/' @senx/discovery/dispatcher
%>
}
Ce fichier indique que :
- Les dashboards seront disponibles à partir de l’url
/discovery/<nom_du_dashboard>ou/discovery/<dossier_ou_arborescence>/<nom_du_dashboard> - Le dossier où seront les dashboards seront stockés dans
$WARP10_HOME/macros/cerenit/dashboards. Il s’agira de fichier WarpScript ou Flows avec l’extension en.mc2.
Avec ces deux fichiers, nous savons maintenant que :
- nous accèderons aux dashboards via
http://127.0.0.1:8081/discovery/<nom_du_dashboard>. - les dashboards seront des fichiers stockés dans ``$WARP10_HOME/macros/cerenit/dashboards`
- donc le dashboard
$WARP10_HOME/macros/cerenit/dashboards/mon_dashboard.mc2sera accessible viahttp://127.0.0.1:8081/discovery/mon_dashboard.
Création du premier dashboard
Un dashboard se décompose en différentes parties. Celle contenant les données a le mot clé tiles et contient différente tile. Chaque tile affiche un graphique, un zone de texte, un titre ou tout composant warpView. Pour le reste, on s’appuiera sur le template par défaut.
Donc créeons un fichier $WARP10_HOME/macros/cerenit/dashboards/comptabilite/compta1.mc2 contenant :
<%
{
'tiles' [
{
'type' 'display'
'w' 4 'h' 1 'x' 3 'y' 0
'data' 'Compta - Exemple 1'
}
{
'type' 'line'
'w' 4 'h' 2 'x' 1 'y' 3
'data' [
@cerenit/accountancy/revenue
'revenue' STORE
$revenue
]
}
{
'type' 'line'
'w' 4 'h' 2 'x' 5 'y' 3
'data' [
@cerenit/accountancy/expense
'expense' STORE
$expense
]
}
{
'type' 'line'
'w' 4 'h' 2 'x' 3 'y' 5
'data' [
$revenue $expense -
]
}
]
}
@senx/discovery/render
%>
Comme indiqué précédemment, je me focalise sur le contenu de tiles. La grille de présentation des dashboards est fixé à 12 colonnes par défaut.
Ici, je cherche donc à afficher 4 éléments :
- Le premier élément est un bloc titre, contenant “Compta - Exemple 1”. Il est placé sur la 3ème item de la grille en parant de la gauche (valeur de x), il est en haut (valeur y de 0) et il occupe une largeur de 4 (valeur de w) et une hauteur de 1 (valeur de h),
- les trois éléments suivants sont des graphiques de tyme “line” avec un positionnement pour deux les deux premiers soient sur une ligne et le dernier en dessous et plutôt centré par rapport aux deux premmiers.
- le deuxième et troisième éléments font appels à des macros
@cerenit/accountancy/xxx. Je pourrais mettre du code Warpscript directement dans le fichier comme dans l’exemple. Toutefois, le code exécuté dans le dashboard est visible dans le navigateur. Dans la mesure où mes requêtes pour récupérer les données demandent de l’authentification avec un passage de token, je déporte ce code dans une macro et je ne fais donc qu’appeler cette macro. Ainsi, le code sera généré coté serveur et seul le résultat sera retourné dans le navigateur. - le dernier élement illustre la capacité intéressante et différentiante de Discovery : on ne fait pas que décrire le dashboard avec du code, on peut aussi faire des opérations sur nos données. Ici je calcule dynamiquement le résultat à partir des données de chiffre d’affaires (revenue) et de dépenses (expense). J’aurais pu faire l’appel à une troisième macro comme les deux éléments précédents, mais vu que j’ai cette capacité de réaliser des opérations au sein d’un dashboard, pourquoi me priver ?
- enfin, on appelle la fonction
@senx/discovery/renderpour générer le dashboard.
Revenons sur nos macros ; Warp 10 permet d’avoir des macros exécutées coté serveur. Ces macros peuvent être utiles pour créer/partager du code, elles peuvent prendre des paramètres en entrée si besoin et elles sont exécutées coté serveur. Dans notre cas, pour éviter que nos tokens se balladent dans le navigateur comme indiqué précédemment, c’est cette propriété qui va nous intéresser.
La macro @cerenit/accountancy/revenue se trouve donc dans le fichier $WARP10_HOME/macros/cerenit/accountancy/revenue.mc2 et contient :
<%
{
'name' 'cerenit/accountancy/revenue'
'desc' 'Provide revenue'
} INFO
// Actual code
SAVE 'context' STORE
'<readToken>' 'readToken' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } NOW [ 2016 12 1 ] TSELEMENTS-> ] FETCH
0 GET
$context RESTORE
%>
'macro' STORE
$macro
Je ne vais pas m’étendre sur la rédaction des macros mais succintement :
- Le permier bloc donne le nom de la macro et sa description
- La suite indique le code qui va être réalisé - pour ma part, un FETCH sur la classe “revenue” pour la compagny “cerenit” du 01/12/2016 jusqu’à maintenant. Cette liste n’a qu’un élément que je récupère. C’est ce qui me sera retourné.
La macro @cerenit/accountancy/expense est sur le même modèle en remplaçant revenue par expense.
Ces deux macros nous retournent donc chacune une série temporelle sur la période 12/2016 jusqu’à ce jour : une pour le chiffre d’affaires, une pour les dépenses.
Si vous allez sur http://127.0.0.1:8081/discovery/comptabilite/compta1, vous verrez le dashboard suivant :
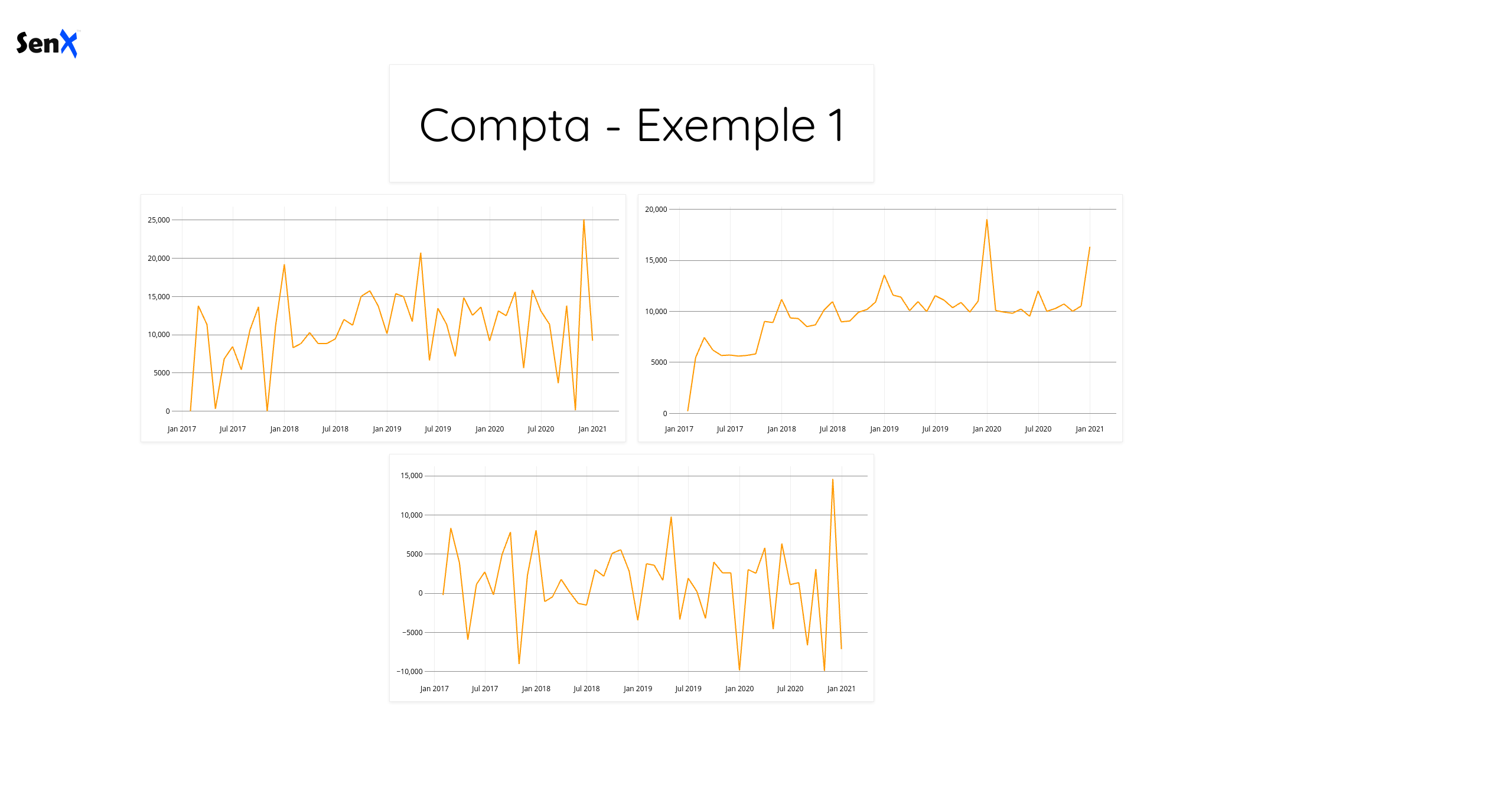
Le template par défaut est assez minimaliste et on note la présence d’un logo SenX. Je n’ai rien contre, mais comme c’est la compatabilité de mon entreprise que je présente, autant changer cet aspect des choses.
Ajustements graphiques
Pour continuer progressivement, nous allons :
- Rajouter un titre et une description à notre dashboard en précisant les propriétés
titleetdescriptionen début de fichier - Rajouter un footer en bas de page en précisant la propriété
footer - Supprimer le logo SenX en précisant la propriété
template - Ajuster la position des blocs pour qu’ils soient centrés comme le reste des éléments
On met cela dans un nouveau fichier $WARP10_HOME/macros/cerenit/dashboards/comptabilite/compta2.mc2.
<%
{
'title' 'Comptabilité CerenIT'
'description' 'Comptabilité CérénIT depuis 2016'
'tiles' [
{
'type' 'display'
'w' 4 'h' 1 'x' 4 'y' 0
'data' 'Compta - Exemple 2'
}
{
'title" "Chiffre d'affaires'
'type' 'line'
'w' 4 'h' 2 'x' 2 'y' 3
'data' [
@cerenit/accountancy/revenue
'revenue' STORE
$revenue
]
}
{
'title' 'Dépenses'
'type' 'line'
'w' 4 'h' 2 'x' 6 'y' 3
'data' [
@cerenit/accountancy/expense
'expense' STORE
$expense
]
}
{
'title' 'Résultat'
'type' 'line'
'w' 4 'h' 2 'x' 4 'y' 5
'data' [
$revenue $expense -
]
}
]
'footer' '<p style="text-align: center;">CérénIT © 2021 - Réalisé avec Discovery et Warp 10 de SenX</p>'
'template'
<'
<!DOCTYPE html><html><head><title id="pageTitle"></title>
{{{CSS}}}
{{{HEAD}}}
</head>
<body>
<div class="heading">
<div class="header"><h1 id="title" class="discovery-title"></h1><p id="desc" class="discovery-description"></p></div>
</div>
{{{HEADER}}}
{{{GRID}}}
{{{FOOTER}}}
{{{JS}}}
</body></html>
'>
}
@senx/discovery/render
%>
Si les propriétés title, description et footer vont de soi, pour trouver comment supprimer le logo SenX, il m’a fallu lire le contenu de la macro @senx/discovery/html pour mieux comprendre les différents placehoders et leur fonctionnement.
Si vous allez sur http://127.0.0.1:8081/discovery/comptabilite/compta2, vous verrez le dashboard suivant :
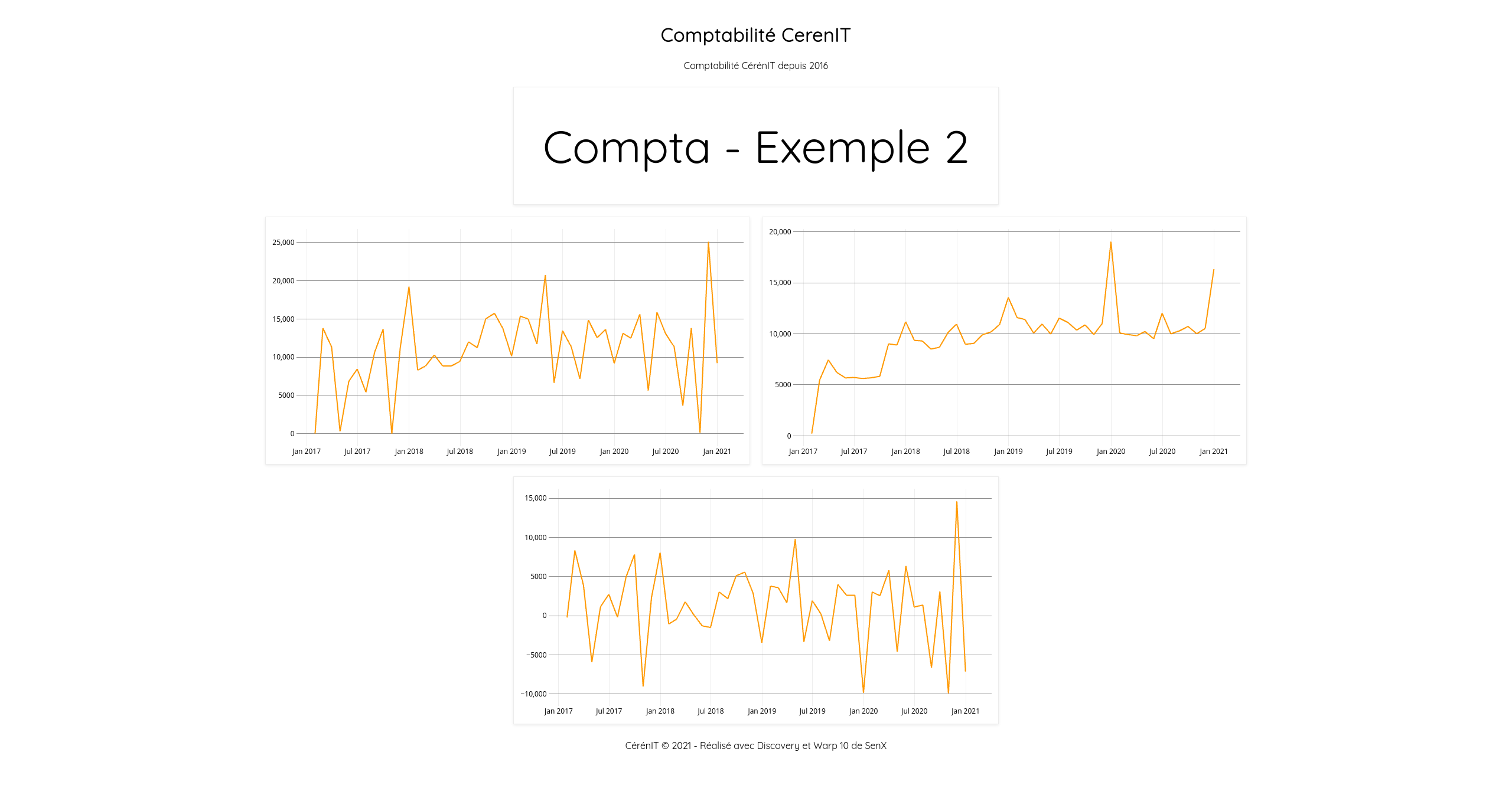
A ce stade, on note que les propriétés title de chaque graphique n’est pas affiché. En dehors de ça, nous retrouvons bien tous nos éléments ajustés.
Néanmoins, cette lecture de @senx/discovery/html permet de voir que l’on a pas mal de points d’entrée pour rajouter des éléments spécifiques. Le tout sera de veiller à ne pas impacter les composants graphiques WarpView dans leur sémantique pour ne pas créer de dysfonctionnement.
Un petit coup de bar(re)
Pour finir ce tutoriel, nous allons :
- lisser un peu ces lignes d’une part, en remplaçant le type de
lineàsplinepour les trois graphiques déjà réalisés (pour les autres modes de réprésentation, voir les options de chart) - rajouter un histogramme avec le cumul annuel de nos données avec un chart de type
bar.
On met cela dans un nouveau fichier $WARP10_HOME/macros/cerenit/dashboards/comptabilite/compta3.mc2.
<%
{
'title' 'Comptabilité CerenIT'
'description' 'Comptabilité CérénIT depuis 2016'
'tiles' [
{
'type' 'display'
'w' 4 'h' 1 'x' 4 'y' 0
'data' 'Compta - Exemple 3'
}
{
'title' 'Chiffre d\'affaires'
'type' 'spline'
'w' 4 'h' 2 'x' 2 'y' 3
'data' [
@cerenit/accountancy/revenue
'revenue' STORE
$revenue
]
}
{
'title' 'Dépenses'
'type' 'spline'
'w' 4 'h' 2 'x' 6 'y' 3
'data' [
@cerenit/accountancy/expense
'expense' STORE
$expense
]
}
{
'title' 'Résultat'
'type' 'spline'
'w' 4 'h' 2 'x' 4 'y' 5
'data' [
$revenue $expense -
]
}
{
'title' 'Consolidation annuelle'
'type' 'bar'
'w' 4 'h' 2 'x' 4 'y' 7
'data' [
[ $revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ @cerenit/accountancy/result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
]
'options' { 'timeMode' 'timestamp' }
}
]
'footer' '<p style="text-align: center;">CérénIT © 2021 - Réalisé avec Discovery et Warp 10 de SenX</p>'
'template'
<'
<!DOCTYPE html><html><head><title id="pageTitle"></title>
{{{CSS}}}
{{{HEAD}}}
</head>
<body>
<div class="heading">
<div class="header"><h1 id="title" class="discovery-title"></h1><p id="desc" class="discovery-description"></p></div>
</div>
{{{HEADER}}}
{{{GRID}}}
{{{FOOTER}}}
{{{JS}}}
</body></html>
'>
}
@senx/discovery/render
%>
Pour ce dernier graphique, il est donc de type bar. Pour le détail des requêtes, je vous renvoie à la partie 2 qui explique cela. Dans notre cas, il faut juste veiller à passer une option supplémentaires pour que timeMode interprête la date issue de la requête comme un timestamp et non comme une date par défaut. D’autres options comme la gestion de la présentation en mode vertical/horizontal ou en mode “stacked” ou pas.
Si vous allez sur http://127.0.0.1:8081/discovery/comptabilite/compta3, vous verrez le dashboard suivant :
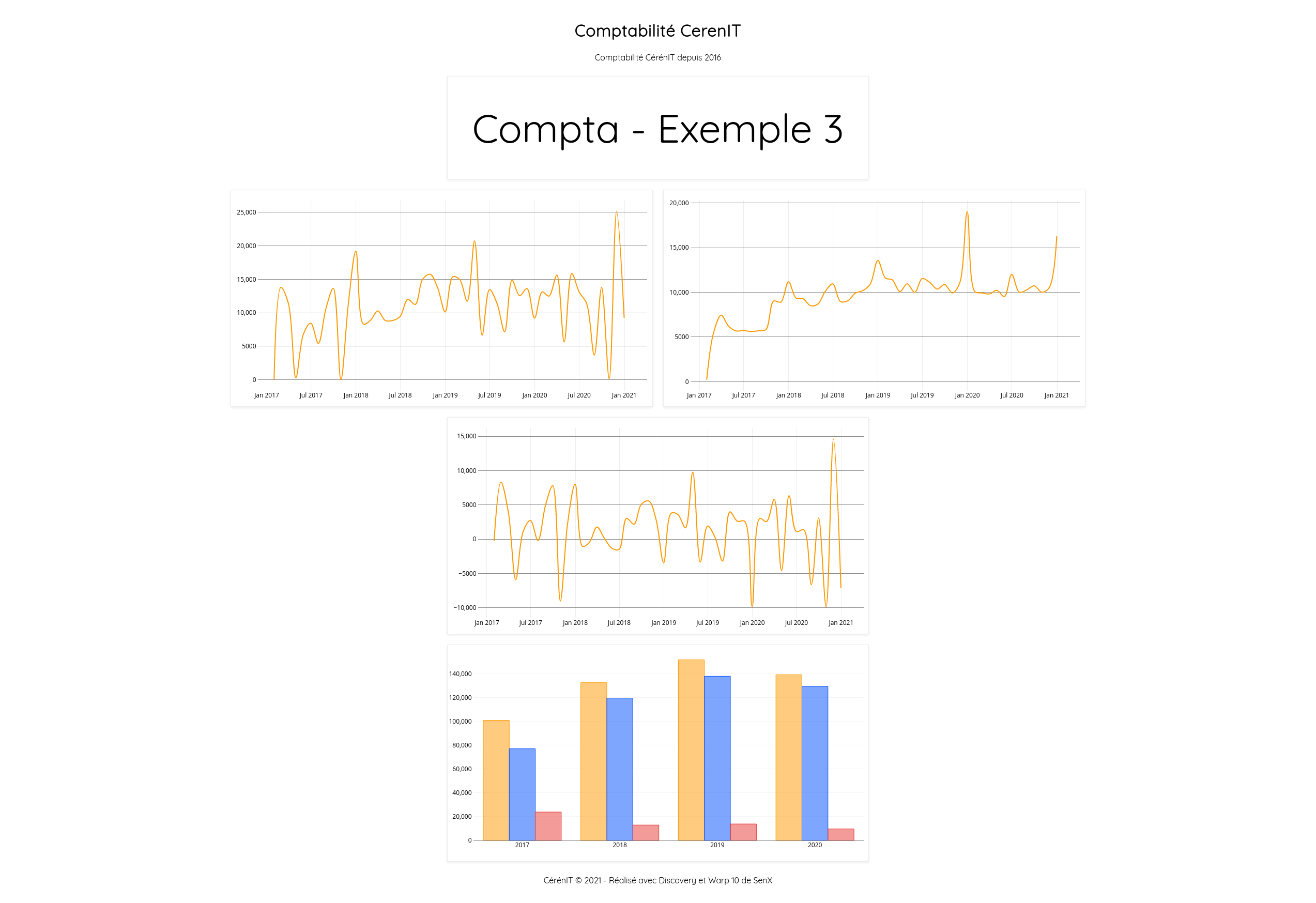
Pour résumer ce billet, nous aovns pu voir que :
- Warp 10 dispose d’une solution de Dashboard avec Discovery
- Comme on pouvait le voir dans le studio, à partir du moment où l’on a nos requêtes, il est aisé de les mettre dans des dashboards
- Les macros permettent de ne pas exposer des tokens dans le navigateur et de faire des calculs cotés serveur
- Il est possible de personnaliser l’apparence des dashboards - des points d’entrée et des mécanismes de surcharges sont à notre disposition pour en faire ce que l’on souhaite
- Les composants WarpView sont assez riches et se configurent facilement
Web, Ops & Data - Février 2021
java repository artefact timescale postgres kapacitor grafana nomad hashicorp podman docker compose registry docker golang vscode warp10 dataviz transformation vector linterContainer et orchrestration
- Running Nomad for home server : pour avoir mené une expérience très similaire sur le mois de janvier, je me retrouve complètement dans ce retour d’expérience sur nomad (vs kubernetes dans une certaine mesure). Le trio nomad/consul/vault permet de faire des choses assez proches de ce que l’on peut faire avec kubernetes et parfois même de façon plus simple. Et ce, avec moins de couches intermédiaires (CSI, CNI, etc) mais aussi quelques fonctionnalités en moins. Un compromis assez réussi je trouve entre un docker nu et/ou avec docker-compose et un kubernetes.
- Podman 3.0 has been released! : support de docker-compose, support des noms courts d’image, amélioration sur le réseau, apport de la dernière version de buildah, correction d’une CVE, etc.
- Donating Docker Distribution to the CNCF : Docker Inc donne sa registry à la fondation CNCF pour fédérer les initiatives autour d’un même standard et élargir le champ des contributeurs/mainteneurs.
- Panorama des outils de sécurité autour des conteneurs : comparaison des outils de bonnes pratiques et d’analyses de vulnérabilités des containers docker pour améliorer la sécurité de vos conteneurs.
Code
- Gopls on by default in the VS Code Go extension - The Go Blog : amélioration du support de Go dans VSCode.
- Awesome Linters : si vous cherchez un linter, vous devriez le trouver dans ce dépot
- Into the Sunset on May 1st: Bintray, JCenter, GoCenter, and ChartCenter : JFrog va arrêter les services Bintray, JCenter, GoCenter et ChartCenter le 1er mai. La proposition est de migrer sur l’offre JFrog Cloud ou de trouver une alternative.
Monitoring & observabilité
- Datadog Acquires Timber Technologies | Datadog : Datadog achète la société Timber Technologies qui édite le project vector. Pourvu que cela ne nuise pas au projet.
- Datadog Signs Definitive Agreement to Acquire Sqreen | Datadog : Datadog achète aussi Sqreen qui était dans le domaine de la sécurité.
- Vector Remap Language : la version 0.12 de vector va apporter un nouveau langage plus fonctionnel pour définir le traitement sur ses logs. A tester !
- Building a Telegraf Assistant – UC Berkeley Codebase : des étudiants de l’universite de Berkeley ont travaillé sur la capacité de pousser une configuration à distance à telegraf. A voir si le code arrive jusque dans le produit telegraf, ce serait sympathique en tous cas !
Time Series
- Time-Series Analytics for PostgreSQL: Introducing the Timescale Analytics Project : Timescale va publier des fonctions orientées time series sous la forme d’extensions postgres. A priori réutilisable sans utiliser le reste de la base Timescale (à confirmer). De quoi simplifier certaines manipulations ?!
- TimescaleDB 2.0 is now Generally Available : annonce officielle de la sortie de TimescaleDB 2.0 même si la 2.0.0 est sortie à Noel et la 2.0.1 fin janvier.
- Grafana 7.4 released: Next-generation graph panel with 30 fps live streaming, Prometheus exemplar support, trace to logs, and more : amélioration des panels, mode livrestream pour un panel, support des variables dans les notifications d’alertes et plein d’autres choses.
- Kapacitor 1.5.8 — Rollback Announcement | InfluxData : Rollback de la version 1.5.8 de Kapacitor (la couche de processing en mode batch/streaming dans un contexte InfluxDB 1.x) pour cause d’opération pouvant conduire à de la perte de données. Un correctif est attendu sous peu.
- TL;DR InfluxDB Tech Tips – How to Monitor States with InfluxDB : ce billet est intéressant pour compléter le billet sur le calcul de la durée d’un état avec des timeseries. Notamment, l’apport de la fonction
monitor.stateChanges()etmonitor.stateChangesOnly(). - Warp 10 2.7.3 : version de maintenance.
- A review of smoothing transforms in WarpLib : revue des possibilités de “lissage” de vos séries avec différents algorithmes inclus dans Warp 10 de la moyenne glissante simple à des algorithmes capables d’excluer les anomalies et pics ponctuels.
Si vous êtes en manque de news, vous pouvez aller consulter (et vous abonner) aux brèves du BigData Hebdo
Ma comptabilité, une série temporelle comme les autres - partie 3 - exécution distante
warp10 timeseries comptabilité remote execution rexec lmap templateSuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale (ce billet)
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512
- Partie 6 - Les FEC et le compte de résultat
A l’issue du précédent billet, depuis le WarpStudio et en stockant les données dans la sandbox, nous avons manipuler les données pour :
- refaire les précisions de juin à décembre 2020 à partir des données de 01/2017 à 05/2017
- comparer ses prévisions avec les résultats réels
- faire les prévisions pour 2021.
Cependant, cela n’est pas parfait :
- La durée de vie des données dans la sandbox est limitée à 2 semaines
- Il faut copier/coller ses requêtes dans le studio pour obtenir les graphiques
- Mais cela permet d’évaluer les extensions commerciales déployées sur la sandbox mais que vous n’avez pas forcément sur votre instance Warp 10 (au moins pour le moment)
Nous allons voir aujourd’hui comment rappatrier les données générées dans sa propre instance Warp 10.
Génération des prévisions
Pour commencer du bon pied et être sur que tout le monde est au même niveau, nous allons regénérer les prévisions et chaque prévision sera alors stockée dans une sériée dédiée. Cela nous permet d’avoir notre jeu de données de départ. On doit pouvoir sauver directement nos données dans une base distante, mais pour simplifier le tutoriel, nous allons le faire en deux étapes.
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des séries 2017 > 2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// Prévision sur les 12 prochains mois avec AUTO
// On n'a pas besoin d'afficher les données
// Donc plus besoin de les stocker sous forme de variable avec utilisation de la fonction STORE
// Par contre, on veut perstister les données en base
// ce qui se fait avec UPDATE et l'utilsation d'un token en écriture
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_result" RENAME
$writeToken UPDATE
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_revenue" RENAME
$writeToken UPDATE
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_expense" RENAME
$writeToken UPDATE
# Prévisions avec SAUTO
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_result" RENAME
$writeToken UPDATE
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_revenue" RENAME
$writeToken UPDATE
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_expense" RENAME
$writeToken UPDATE
Si nous vouulons vérifier que vos données sont bien en base, il faut utiliser FETCH :
// Ex de FETCH avec la série auto_revenue
'<read token>' 'readToken' STORE
[ $readToken 'auto_revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2022-01-01T00:00:00Z' ] FETCH
0 GET
Attaquons maintenant la grande traversée des données vers mon instance Warp 10.
Activation de l’exécution à distance
Alors on pourrait simplement migrer les données à coup de “curl in/curl out” mais l’idée ici est plus d’illustrer les interactions possibles entre des instances Warp 10.
Pour exécuter du warpscrip sur une instance distante, il faut utiliser la fonction REXEC
Cette exécution distante est désactivée par défaut, il faut donc activer cette extension:
Dans /path/to/warp10/etc/conf.d/70--extensions.conf, nous avons :
// REXEC
#warpscript.extension.rexec = io.warp10.script.ext.rexec.RexecWarpScriptExtension
#warpscript.rexec.endpoint.patterns = .*
// REXEC connect timeout in ms (default = 0, no timeout)
#warpscript.rexec.timeout.connect = 3600000
// REXEC read timeout in ms (default = 0, no timeout)
#warpscript.rexec.timeout.read = 3600000
Décommentons ces lignes et relançons warp 10.
Pour valider que REXEC est bien activé, depuis le studio, nous pouvons faire un test simple:
'2 2 +' 'https://warp10.url:port/api/v0/exec' REXEC
La réponse est 4.
Attention, il faut choisir votre instance comme endpoint dans la liste déroulante du studio. Si vous êtes sur le endpoint de la sandbox, vous auez le message d’erreur suivant :
https://sandbox.senx.io/api/v0/exec
line #2: Exception at ''2%202%20+' 'https://warp10.url:port/api/v0/exec' =>REXEC<=' in section [TOP] (REXEC encountered a forbidden URL 'http://warp10.url:port/api/v0/exec')
En effet, depuis la Sandbox, il n’est pas possible d’accéder à n’importe quelle machine par mesure de sécurité.
Requêtage simple à distance
Dans le studio, à partir de maintenant, il doit être configuré pour utliiser votre instance Warp 10 comme endpoint.
Le test simple étant fonctionnel, passons à un test un peu plus compliqué, à savoir recupérer nos données hébergées depuis la sandbox en lecture pour le moment.
// tokens pour la sandbox
'<sandboxReadToken>' 'sandboxReadToken' STORE
'<sandboxWriteToken>' 'sandoxWriteToken' STORE
// Url de la sandbox
'https://sandbox.senx.io/api/v0/exec' 'url' STORE
// On introduit ici la notion de template - comme on va vouloir récupérer plusieurs séries avec les mêmes paramètres
// Autant automatiser un peu et s'appuyer sur une boucle ! :-)
// On crée donc un TEMPLATE pour la fonction FETCH qui va récupérer un token en écriture
// et un nom de classe permettant de récupérer nos GTS.
// Rappel le <' ... '> permet de faire des strings en multi-lignes
// On stocke le template sous la forme d'une variable fetchTpl.
<'
{
'token' '{{ remoteReadToken }}'
'class' '{{ remoteClass }}'
'labels' {}
'start' '2016-12-01T00:00:00Z'
'end' '2022-01-31T00:00:00Z'
} FETCH
'>
'fetchTpl' STORE
// Avec la fonction TEMPLATE, on remplace les clés par leurs valeurs en fournissant le template
// et un dictionnaire à la fonction.
$fetchTpl
{ 'remoteReadToken' $sandboxReadToken 'remoteClass' 'revenue' } TEMPLATE
// Execution de la requête distante avec REXECZ
// La différence avec REXEC est qu'une compression est appliquée sur la réponse à la requête
$url REXECZ
// La liste de GTS issue de FETCH ne contient qu'une liste, on prend donc la première
0 GET
// Stockage sous la forme d'une variable
'revenueGTS' STORE
// Affichage de la série
$revenueGTS
Si vous allez dans l’onglet dataviz, vous pouvez constater que vos données issues de la sandbox mais qui ont transité via votre instance sont bien disponibles.
Transfert des données - 1 série
Si nous commençons par une seule série :
// tokens de l'instance
'<instanceReadToken>' 'instanceReadToken' STORE
'<instanceWriteToken>' 'instanceWriteToken' STORE
// tokens pour la sandbox
'<sandboxReadToken>' 'sandboxReadToken' STORE
'<sandboxWriteToken>' 'sandoxWriteToken' STORE
// Url de la sandbox
'https://sandbox.senx.io/api/v0/exec' 'url' STORE
// Template de code warpscript
<'
{
'token' '{{ remoteReadToken }}'
'class' '{{ remoteClass }}'
'labels' {}
'start' '2016-12-01T00:00:00Z'
'end' '2022-01-31T00:00:00Z'
} FETCH
'>
'fetchTpl' STORE
// Substitution des variables
$fetchTpl
{ 'remoteReadToken' $sandboxReadToken 'remoteClass' 'revenue' } TEMPLATE
// Exécution de la requête
$url REXECZ
// La liste de GTS issue de FETCH ne contient qu'une liste, on prend donc la première
0 GET
// Il faut renommer "localement" la série avant de pouvoir la stocker dans l'instance
// Peut éviter de mauvaises manipulations que l'on pourrait regretter :-)
"revenue" RENAME
// Persistance des données
$instanceWriteToken UPDATE
Il y a quelques occurences de “revenue” en dur dans le code, il va falloir améliorer cela.
Transfert des données - plusieurs séries
Et maintenant, traitons nos 9 series d’un coup
// tokens de l'instance
'<instanceReadToken>' 'instanceReadToken' STORE
'<instanceWriteToken>' 'instanceWriteToken' STORE
// tokens pour la sandbox
'<sandboxReadToken>' 'sandboxReadToken' STORE
'<sandboxWriteToken>' 'sandoxWriteToken' STORE
// Url de la sandbox
'https://sandbox.senx.io/api/v0/exec' 'url' STORE
// Template de code warpscript
<'
{
'token' '{{ remoteReadToken }}'
'class' '{{ remoteClass }}'
'labels' {}
'start' '2016-12-01T00:00:00Z'
'end' '2022-01-31T00:00:00Z'
} FETCH
'>
'fetchTpl' STORE
// Création d'une liste avec nos 9 séries
// C'est cette liste que nous allons passer ensuite dans une MACRO.
// Cette MACRO va être exécutée sur chaque élément de la liste via l'utilisation de la fonction LMAP
// https://www.warp10.io/doc/LMAP
[ 'revenue' 'exp' 'result' 'auto_revenue' 'auto_result' 'auto_expense' 'sauto_revenue' 'sauto_result' 'sauto_expense' ]
// Début de la MACRO
<%
// On récupère la valeur de la liste que l'on stocke sous la forme d'une variable
'remoteClass' STORE
// Substitution des valeurs de template
$fetchTpl
{ 'remoteReadToken' $sandboxReadToken 'remoteClass' $remoteClass } TEMPLATE
// Exécution distante de la requête
$url REXECZ
// On récupère ici une liste de GTS - plutôt que d'en extraire la GTS comme précédemment
// on va garder une liste de GTS à 1 élément, mais ce qui permet à nouveau d'utiliser la fonction LMAP
// Sur chaque entrée de la liste, une seconde macro est appliquée
// Le contenu de notre macro consiste à utliser la fonction RENAME
// '+' RENAME, cela revient à renommer la GTS en prenant le même nom que celui qui est fourni
// '+x' RENAME aurait ajouté un x au nom de la série
// Il reste l'index de la liste à traiter - soit on le supprime avec DROP
//<% DROP '+' RENAME %> LMAP
// Soit on passe F comme 3ème argument à LMAP - cela permet d'ignorer cet index
// <% '+' RENAME %> F LMAP
// Prenons la seconde forme :
<% '+' RENAME %> F LMAP
// Toutes nos séries ont été correctement renommées !
// On persiste la GTS dans la base locale
$instanceWriteToken UPDATE
%>
// Fin de la MACRO
// Application de la fonction LMAP pour que notre macro soit exécutée sur chaque élément de la liste.
// Comme on ne veut que les valeurs de la liste et pas les index, on positionne aussi F
// comme 3ème argument à LMAP
F LMAP
Et voilà, nos données ont été récupérées de la Sandbox et stockées dans notre instance locale.
Bonus
Une version alternative - dans mes données, je peux tricher et ne filtrer que sur le label company avec pour valeur cerenit:
// tokens de l'instance
'<instanceReadToken>' 'instanceReadToken' STORE
'<instanceWriteToken>' 'instanceWriteToken' STORE
// tokens pour la sandbox
'<sandboxReadToken>' 'sandboxReadToken' STORE
'<sandboxWriteToken>' 'sandoxWriteToken' STORE
// Url de la sandbox
'https://sandbox.senx.io/api/v0/exec' 'url' STORE
// Warpscript template
<'
{
'token' '{{ remoteReadToken }}'
'class' '~.*'
'labels' { 'company' 'cerenit' }
'start' '2016-12-01T00:00:00Z'
'end' '2022-01-31T00:00:00Z'
} FETCH
'>
'fetchTpl' STORE
// Substitution dans le template
$fetchTpl
{ 'remoteReadToken' $sandboxReadToken } TEMPLATE
// Execution de la requête
$url REXECZ
// Renommage des séries
<% '+' RENAME %> F LMAP
// Presistence des données
$instanceWriteToken UPDATE
Bravo si vous m’avez suivi jusqu’ici, nous avons pu voir l’utilisation de :
- Comment permettre un requêtage à distance d’une instance Warp 10 avec les fonctions
REXECetREXECZ - Comment traiter dynamiquement notre liste de GTS avec
LMAPet uneMACRO - Comment faire un template warpscript et de la substitution de variables avec
TEMPLATE
Nous verrons dans un prochain épisode :
- Comment utiliser Discovery pour faire nos premiers dashboards
- Pourquoi/comment utiliser des macros coté server (spoiler: pour éviter que vos tokens se retrouvent dans votre navigateur à l’exécution des dashboards)
