Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Web, Ops, IoT et Time Series - Mars 2022
python asgi git grep docker zip cli django numérique rgpd privacy shield docker-compose dockerfile google analytics matomo fugue duckdb pandas sqlConteneur et Orchestration
- Docker Engine 20.10.13 : Docker compose v2 arrive dans docker : ce qui permet de faire
docker compose(au lieu de l’originaldocker-composecoté en python) COPY --chmodreduced the size of my container image by 35% : pour réduire la taille de vos images, plutôt que de faire unADD ...puis unRUN chmod ..., faites directement unADD/COPY --chmod. Marche aussi avec--chown.- Docker Compose > depends > condition: ready :
depends_ona une syntaxe longue qui permet de définir une condition sur l’état du service dépendant : démarré (valeur par défaut de la version courte), “sain” (en fonction du résultat d’un healthcheck) ou “terminé avec succès” (si votre service dépend du résultat d’un job ou d’une tâche).
Numérique
- LCC 273 - Interview sur le darwinisme numérique avec Didier Girard - partie 1, LCC 274 - Interview le darwinisme numérique avec Didier Girard - partie 2 et LCC 275 - Interview sur le darwinisme numérique avec Didier Girard - partie 3 : interview en 3 volets de Didier Girard sur la notion de darwinisme numérique au niveau d’une nation, d’une entreprise et de l’individu.
Open Data
- adresse.data.gouv.fr : le site national des adresses dont l’objectif est de référencer l’intégralité des adresses du territoire et les rendre utilisables par tous.
Outils
- GitUI : si vous trouvez
tigpas très intuitif/pratique, GitUI pourrait vous plaire. Prévu pour le terminal, il permet de se ballader facilement dans votre historique git & co. L’ outil en codé en Rust. - igrep : un grep interactif qui permet d’ouvrir le fichier dans un éditeur et d’aller directement à la ligne contenant le motif recherché. Basé sur l’excellent ripgrep.
Python
- Awesome AGSI : liste de ressources compatibles ASGI (Asynchronous Server Gateway Interface)
- Demystifying Python’s Async and Await Keywords : une intro à async/await avec asyncio.
- Python’s zipfile: Manipulate Your ZIP Files Efficiently : le module zipfile inclus dans la librairie standard Python permet de manipuler aisément des archives Zip. La page illustre les différentes méthodes et capacités du module.
- How to Write User-friendly Command Line Interfaces in Python : si le module
argparseest assez connu et peut être aussi Fire, c’est l’occasion de découvrir Click (par l’équipe derrière Flask & co et à ne pas confondre avec clikt en Kotlin), Typer (par le fondateur de FastAPI). - Build a User-Friendly CLI from Pure Python Functions : suite de l’article précédent avec la mise en place de DynaCLI dont le but est de générer des CLI depuis des fonctions pythons “pures”.
- Pass-by-value, reference, and assignment | Pydon’t 🐍 : Python passe-t-il ses variables par valeur ? par référence ou par assignement ?
- (Dajngo) Classy Class-Based Views : une représentation détaillée des méthodes, attributs et propriétés des “Class based views” de Django
- Fugue and DuckDB: Fast SQL Code in Python : Fugue permet de combiner du SQL et du code Python et DuckDB permet de faire tourner une base OLAP. De quoi accélérer le traitement de vos données en python ?
RGPD & Privacy Shield
- “Privacy Shield 2.0”? - First Reaction by Max Schrems : La Commission Européenne et les USA ont annoncé une nouvelle version du Privacy Shield. Max Schrems est sceptique pour le moment…
- Google Analytics 4 (GA4) vs Universal Analytics (UA) : Matomo se livre à un comparatif et une analyse (forcément un peu biaisés) de Google Analytics 4 vs Universal Analytics. Dans tous les cas, la conclusion est de prendre une solution qui répond à vos critères et respectent les règles du jeu (GDPR, etc).
Web, Ops, IoT et Time Series - Février 2022
traefik iot edge httpx semiconducteur rgpd google analytics font podman nebula wireguard jless json réseau tsfel timescaleCode & Langages
- httpx : en gros, requests mais avec le support de l’asynchrone. L’API semble être la même. httpx peut aussi s’installer en tant que cli.
- The Algorithms - Go : collection d’implémentation d’algorithme en Go à fin d’apprentissage
Fonts
- Luciole : La police Luciole a été créée à destination des personnes malvoyantes et apporte un certain confort de lecture et une meilleure lisibilité.
Hardware
- The Semiconductor Ecosystem – Explained : Pour ceux qui veulent en connaitre un peu plus sur le monde des semi-conducteurs.
IoT
- Anomaly Detection: Glimpse into the Future of IoT Data : intéressant le triplet Objet IoT, Edge / Data Routeur capable de réaliser des opérations et le noeud central. L’edge computing permet d’éviter de saturer le noeud central et de prendre des décisions au plus près de l’objet IoT.
Ops
- Announcing Traefik Proxy 2.6 : amélioration sur le protocole HTTP/3, nouveaux middleware de “rate-limiting” au niveau TCP, amélioration au niveau de la Kubernetes API Gateway ou encore support de Consul Enterprise.
- Firecracker v1.0.0 : la MicroVM créée par AWS pour Fargate et Lambda passe en version 1.0
- Podman v4.0 has been released! : nouvelle verison do podman avec pas mal de nouveautés.
- Introducing Nebula, the open source global overlay network from Slack : Présentation de nebula, la solution de connectivité de Slack qui a remplacé leur VPN basé sur IPSEC.
- Our User-Mode WireGuard Year : retour d’expérience de Fly.io sur leur usage de Wireguard pour permettre un accès SSH à leur VMs / Conteneur dockers.
- Le réseau de zéro - Partie 1 & Partie 2 : pour comprendre ce qu’il se trame sur votre réseau en partant de zéro.
Outils
- jless — a command-line JSON viewer : un outil en ligne de commande pour parcourir/explorer vos fichiers JSON.
RGPD & Vie Privée
- Utilisation de Google Analytics et transferts de données vers les États-Unis : la CNIL met en demeure un gestionnaire de site web : vers une interdiction partielle ou complète de Google Analytics ? Prochaine cible, les Google Fonts ?
- Google Analytics : retour sur la mise en demeure de la CNIL : une synthèse en l’état de la situation par NextInpact.
Time Series
- Year of the Tiger: $110 million to build the future of data for developers worldwide : Timescale fait une 3ème levée de 110 M$ et atteint le statut de licorne avec une valorisation à 1 Mds $
- Time Series Feature Extraction Library (TSFEL for short) : Bibliothèque Python à destination des Data Scientistes permettant d’extraire des features de séries temporelles avec 60 fonctions statistiques / temporelles / …
- Increase your storage savings with TimescaleDB 2.6: Introducing compression for continuous aggregates : Version 2.6 de TimescaleDB avec principalement de la compression autour des “continous aggregation”.
Bilan 2021 et perspectives 2022
bilan perspective cérénit timeseries bigdatahebdo influxace iotRoutine habituelle de début d’année pour la clôture de ce 5ème exercice (déjà !).
Bilan 2021
Au global, une année mitigée qui se termine un peu sur le fil du rasoir au niveau comptable. Pour la partie positive, j’ai l’impression que cette année a été “l’année des possibles” où les efforts commencés les années précédentes commencent à payer. Des premiers projets en Go, des missions Time Series intéressantes et ambitieuses par certains aspects et un projet annexe en Python/Django sur la fin d’année qui consolide différents éléments permettant de gagner en confiance et de réduire un peu ce cher syndrome de l’imposteur avec lequel j’apprends à composer et à dépasser parfois.
CérénIT
D’un point de vue comptable, cela donne :
| 2021 | 2020 | 2019 | 2018 | 2017 | Variation n/n-1 | |
|---|---|---|---|---|---|---|
| Chiffre d’affaires | ~130 K€ | ~138 K€ | ~150 K€ | ~132 K€ | ~100 K€ | -6% |
| Résultat après impôts | ~1K€ | ~10 K€ | ~13.5 K€ | ~10 K€ | ~20 K€ | -90% 😱 |
| Jours facturés | 164 | 175 | 197 | 178 | 160 | -6% |
| TJM | 793€ | 789€ | 761€ | 742€ | 625€ | +0.5% |
Les années précédentes, les missions annexes (missions courtes d’audit/expertise principalement) venaient apporter le bénéfice annuel et la mission principale couvrait les charges. Cette année, avec une réduction de mes missions principales en fin d’année, les missions annexes ont permis de couvrir les charges mais sans permettre de dégager de bénéfices. Un TJM plus élevé sur ces missions annexes permet d’amortir et de compenser la baisse d’activité.
| 2021 | 2020 | 2019 | Variation n/n-1 | |
|---|---|---|---|---|
| Chiffre d’affaires Total | ~130 K€ | ~138 K€ | ~150 K€ | -6% |
| Chiffre d’affaires Time Series | ~25K€ | ~5 K€ | ~2 K€ | +400% 💪 |
Une des grandes satisfactions de l’année est incontestablement l’essor de l’activité Time Series. Etre référencé comme InfluxAce m’a apporté une mission chez Axens sur les Shard Duration & Retention Policies et quelques contacts/prospects qui n’ont pas pu aboutir durant cette année. C’est aussi la poursuite de mon accompagnement des équipes de la SAFT pour la 3ème année consécutive et la mise à jour d’InfluxDB OSS v1.x vers v2.x avec un sujet de migration des alertes Kapacitor vers des Tasks en Flux.
Autres activités
Pour le reste, j’ai eu le plaisir de :
- contribuer au podcast BigData Hebo avec une participation à 17 épisodes et la publication de 44 brèves,
- continuer à animer le Meetup Time Series France avec 5 éditions et en parvenant à lui donner une dimension autour des usages,
- continuer à approfondir mes connaissances autour de Warp 10 avec notamment la publication d’un billet sur le blog de SenX sur n8n & Warp 10 ou le fait de gagner le challenge sur les GeoShapes 🥇,
- finalement parvenir à commencer à jouer avec des ESP32 en toute fin d’année en faisant des détecteurs de CO2.
Pas de contribution de ma société à un quelconque projet comme en 2020 avec une contribution financière au projet Makair suite à la question du rôle social d’une entreprise dans notre société en temps de COVID. Petite déception à ce niveau-là.
Perspectives 2022
2021 s’est terminée avec une certaine forme de lassitude autour de l’activité de freelance (et de la solitude du freelance, même si j’ai toujours cherché à gommer cet aspect dans mes missions) et des activités autour de l’automatisation/industrialisation comme une fin en soit. J’éprouvais le besoin de créer un commun avec des personnes et je voulais accélérer la bascule vers l’IoT industriel mais ne sachant pas par quel bout attaquer le sujet. Une mission “DevOps AWS pour déployer un outil de CI/CD” sans autre finalité ne m’intéressait pas/plus (🤢).
Et là, de nulle part surgit une prise de contact sur LinkedIn par une recruteuse pour rejoindre une entreprise dans l’IoT industriel, avec une dimension environnementale qui cherchait un profil de responsable technique DevOps/IoT. Les astres ne pouvant pas être plus alignés, les cases du job idéal / de la mission idéale étant toutes cochées, je ne pouvais pas laisser passer cette opportunité. Depuis mi-janvier, j’ai donc commencé une mission pour cette entreprise pour qu’on fasse connaissance et pour avancer rapidement sur le sujet le temps que d’autres points soient traités de leur côté. De jolies choses semblent se dessiner et devraient aboutir prochainement… 🤩
Affaire à suivre comme on dit, 2022 semble pleine de promesses, de défis et de changements ! 😎
Web, Ops, IoT et Time Series - Janvier 2022
mqtt tinygo influxdb postgresql openhab awstats goaccess grafana esp32 stm32 gitpod wireguard vpn python socketIDE
- Gitpod à la place d’Intellij ou de VSCode ? : Si l’IDE dans le cloud vous intéresse, cet article est assez détaillé sur sa mise en place et sa personnalisation.
IoT
- Use MQTT with the Wio Terminal and TinyGo : TinyGo est une version de Go à destination des micro-controlleurs. Le billet d’écrit comment s’abonner à un topic MQTT et afficher un message sur le Wio Terminal.
- openHAB 3.2 Release : cette version apporte notamment des améliorations au niveau du moteur de règle avec un version Javascript, le support de Blockly ou encore d’un modèle de règle (rule template).
- stm32duino wiki : si vous envisagez de faire un projet arduino avec des cartes ST Micro Electronics STM32…
- MQTT 101 Tutorial: Introduction and Hands-on using Eclipse Mosquitto : Introduction et éventuel atelier pratique pour découvrir MQTT avec le broker Mosquitto.
- MQTT Essentials : si vous avez besoin de vous (re)mettre à niveau sur MQTT, une série de billets couvrant les différents aspects du protocole et son fonctionnement.
- MQTT5 Essentials : la suite avec un focus sur les apports de MQTT v5.
Monitoring & Observabilité
- Introducing Grafana University: our virtual hands-on education platform that’s free and easy to use : Grafana Labs ouvre les portes de son université pour se former à ses produits.
Python
- Socket Programming in Python (Guide) : Pour tout savoir sur les sockets en Python.
Réseau
- Introducing ‘innernet’ : innernet est un gestionnaire de réseau basé sur WireGuard. Il permet de déclarer l’ensemble de votre réseau wireguard et de définir des politiques réseaux (VLAN, Associations, etc)
Time Series
- lmmentel /awesome-time-series : un dépot github recensant des projets / librairies / ouvrages / documentation sur les séries temporelles.
- InfluxDB FDW 1.1.1 released : InfluxDB FDW est un Foreign Data Wrapper pour Postgresql 10+ qui permet de se connecter à une source InfluxDB 1.x
- Santa asset tracking and delivery service : une démo de suivi d’actif avec Warp 10 et Discovery en prenant l’exemple de la livraison des cadeaux de Noel.
Web
- GoAccess 1.4, a detailed tutorial : en cherchant à déployer une instance AWStats pour avoir des statistiques de visites sur la base des logs du serveur web nginx, je suis tombé sur GoAccess qui semble offir les mêmes fonctionnalités et même plus tout en étant plus simple à déployer/configurer.
IoT - Qualité de l'air avec un esp32 (TTGo T-Display), le service ThingSpeak, du MQTT, Warp 10 et Discovery
iot mqtt arduino warp10 thingspeak co2 esp32 discovery dashboardLe projet Nous Aérons propose de réaliser ses propres détecteurs de CO2 avec un ESP32 avec un écran comme le Lilygo TTGo T-Display et un capteur Senseair S8-LP.
L’idée est donc de déployer plusieurs capteurs, faire remonter les valeurs via ThingSpeak et ensuite les ingérer puis analyser avec Warp 10 et faire un dashboard avec Discovery.
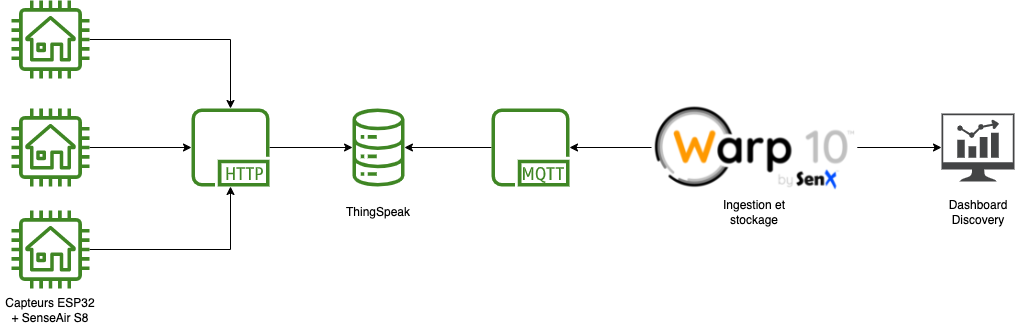
Montage
Pour le montage, je vous invite à consuler principalement :
- Capteur de CO2 et le code
- Les instructions des projets “BEL AIR” et “GRAND AIR” à récupérer via le site de Nous Aérons
- Premiers pas ESP32 : Application de démo du TTGO T-Display : pour la configuration d’Arduino IDE - pour l’application de démo, les chemins ont changé par contre.
- Sous OSX, j’ai du récupérer la version 1.6+ du driver du chipset et être en mesure d’avoir le port
/dev/cu.wchusbserial*afin de pouvoir uploader le code depuis Arduino IDE vers l’ESP32.
ThingSpeak
L’exemple de code fourni utilise le service ThingSpeak pour la remontée des valeurs. Comme il s’agit de mon premier projet Arduino et que cela fonctionne, j’ai cherché à rester dans les clous du code proposé et tester par la même occasion ce service. J’aurais pu directement poster les valeurs sur mon instance Warp 10 mais c’est aussi l’occasion de tester la récupération d’informations via le client MQTT de Warp 10.
Il vous faut :
- Créer un compte
- Créer un channel avec le champ 1 qui accueillera vos données
- Récupérer la clé d’API en écriture
- Noter votre Channel ID
Code Arduino
Disclaimer : c’est mon premier projet Arduino.
En repartant du code fourni sur le site Capteur de CO2, j’ai fait quelques ajustements :
- Remplacer l’appel HTTP par la librairie ThingSpeak
- La librairie retourne des status code :
200si c’est OK,40xsi incorrect et-XXXsi erreur ; j’ai un amélioré le message de debug pour savoir si l’insertion était OK ou KO. - Ajustement de positionnement du “CO2” et du “ppm” sur l’écran pour une meilleure lisibilité.
Il vous faut modifier :
- la configuration wifi :
ssid1,password1et éventuellementssid2,password2 - la configuration ThingSpeak :
channelID,writeAPIKey
Compiler le tout et uploader le code sur votre ESP32.
/************************************************
*
* Capteur de CO2 par Grégoire Rinolfi
* https://co2.rinolfi.ch
*
***********************************************/
#include <TFT_eSPI.h>
#include <SPI.h>
#include <Wire.h>
#include <WiFiMulti.h>
#include <ThingSpeak.h>
WiFiMulti wifiMulti;
TFT_eSPI tft = TFT_eSPI(135, 240);
/************************************************
*
* Paramètres utilisateur
*
***********************************************/
#define TXD2 21 // série capteur TX
#define RXD2 22 // série capteur RX
#define BOUTON_CAL 35
#define DEBOUNCE_TIME 1000
const char* ssid1 = "wifi1";
const char* password1 = "XXXXXXXXXXXXXXXX";
const char* ssid2 = "wifi2";
const char* password2 = "XXXXXXXXXXXXXXXX";
unsigned long channelID = XXXXXXXXXXXXXXXX;
char* readAPIKey = "XXXXXXXXXXXXXXXX";
char* writeAPIKey = "XXXXXXXXXXXXXXXX";
unsigned int dataFieldOne = 1; // Field to write temperature data
const unsigned long postingInterval = 12L * 1000L; // 12s
unsigned long lastTime = 0;
// gestion de l'horloge pour la validation des certificats HTTPS
void setClock() {
configTime(0, 0, "pool.ntp.org", "time.nist.gov");
Serial.print(F("Waiting for NTP time sync: "));
time_t nowSecs = time(nullptr);
while (nowSecs < 8 * 3600 * 2) {
delay(500);
Serial.print(F("."));
yield();
nowSecs = time(nullptr);
}
Serial.println();
struct tm timeinfo;
gmtime_r(&nowSecs, &timeinfo);
Serial.print(F("Current time: "));
Serial.print(asctime(&timeinfo));
}
/************************************************
*
* Thinkgspeak functions
* https://fr.mathworks.com/help/thingspeak/read-and-post-temperature-data.html
*
***********************************************/
float readTSData( long TSChannel,unsigned int TSField ){
float data = ThingSpeak.readFloatField( TSChannel, TSField, readAPIKey );
Serial.println( " Data read from ThingSpeak: " + String( data, 9 ) );
return data;
}
// Use this function if you want to write a single field.
int writeTSData( long TSChannel, unsigned int TSField, float data ){
int writeSuccess = ThingSpeak.writeField( TSChannel, TSField, data, writeAPIKey ); // Write the data to the channel
if(writeSuccess == 200){
Serial.println("Channel updated successfully!");
}
else{
Serial.println("Problem updating channel. HTTP error code " + String(writeSuccess));
}
return writeSuccess;
}
// Use this function if you want to write multiple fields simultaneously.
int write2TSData( long TSChannel, unsigned int TSField1, long field1Data, unsigned int TSField2, long field2Data ){
ThingSpeak.setField( TSField1, field1Data );
ThingSpeak.setField( TSField2, field2Data );
int writeSuccess = ThingSpeak.writeFields( TSChannel, writeAPIKey );
if(writeSuccess == 200){
Serial.println("Channel updated successfully!");
}
else{
Serial.println("Problem updating channel. HTTP error code " + String(writeSuccess));
}
return writeSuccess;
}
/************************************************
*
* Code de gestion du capteur CO2 via ModBus
* inspiré de : https://github.com/SFeli/ESP32_S8
*
***********************************************/
volatile uint32_t DebounceTimer = 0;
byte CO2req[] = {0xFE, 0X04, 0X00, 0X03, 0X00, 0X01, 0XD5, 0XC5};
byte ABCreq[] = {0xFE, 0X03, 0X00, 0X1F, 0X00, 0X01, 0XA1, 0XC3};
byte disableABC[] = {0xFE, 0X06, 0X00, 0X1F, 0X00, 0X00, 0XAC, 0X03}; // écrit la période 0 dans le registre HR32 à adresse 0x001f
byte enableABC[] = {0xFE, 0X06, 0X00, 0X1F, 0X00, 0XB4, 0XAC, 0X74}; // écrit la période 180
byte clearHR1[] = {0xFE, 0X06, 0X00, 0X00, 0X00, 0X00, 0X9D, 0XC5}; // ecrit 0 dans le registe HR1 adresse 0x00
byte HR1req[] = {0xFE, 0X03, 0X00, 0X00, 0X00, 0X01, 0X90, 0X05}; // lit le registre HR1 (vérifier bit 5 = 1 )
byte calReq[] = {0xFE, 0X06, 0X00, 0X01, 0X7C, 0X06, 0X6C, 0XC7}; // commence la calibration background
byte Response[20];
uint16_t crc_02;
int ASCII_WERT;
int int01, int02, int03;
unsigned long ReadCRC; // CRC Control Return Code
void send_Request (byte * Request, int Re_len)
{
while (!Serial1.available())
{
Serial1.write(Request, Re_len); // Send request to S8-Sensor
delay(50);
}
Serial.print("Requete : ");
for (int02 = 0; int02 < Re_len; int02++) // Empfangsbytes
{
Serial.print(Request[int02],HEX);
Serial.print(" ");
}
Serial.println();
}
void read_Response (int RS_len)
{
int01 = 0;
while (Serial1.available() < 7 )
{
int01++;
if (int01 > 10)
{
while (Serial1.available())
Serial1.read();
break;
}
delay(50);
}
Serial.print("Reponse : ");
for (int02 = 0; int02 < RS_len; int02++) // Empfangsbytes
{
Response[int02] = Serial1.read();
Serial.print(Response[int02],HEX);
Serial.print(" ");
}
Serial.println();
}
unsigned short int ModBus_CRC(unsigned char * buf, int len)
{
unsigned short int crc = 0xFFFF;
for (int pos = 0; pos < len; pos++) {
crc ^= (unsigned short int)buf[pos]; // XOR byte into least sig. byte of crc
for (int i = 8; i != 0; i--) { // Loop over each bit
if ((crc & 0x0001) != 0) { // If the LSB is set
crc >>= 1; // Shift right and XOR 0xA001
crc ^= 0xA001;
}
else // else LSB is not set
crc >>= 1; // Just shift right
}
} // Note, this number has low and high bytes swapped, so use it accordingly (or swap bytes)
return crc;
}
unsigned long get_Value(int RS_len)
{
// Check the CRC //
ReadCRC = (uint16_t)Response[RS_len-1] * 256 + (uint16_t)Response[RS_len-2];
if (ModBus_CRC(Response, RS_len-2) == ReadCRC) {
// Read the Value //
unsigned long val = (uint16_t)Response[3] * 256 + (uint16_t)Response[4];
return val * 1; // S8 = 1. K-30 3% = 3, K-33 ICB = 10
}
else {
Serial.print("CRC Error");
return 99;
}
}
// interruption pour lire le bouton d'étalonnage
bool demandeEtalonnage = false;
void IRAM_ATTR etalonnage() {
if ( millis() - DEBOUNCE_TIME >= DebounceTimer ) {
DebounceTimer = millis();
Serial.println("Etalonnage manuel !!");
tft.fillScreen(TFT_BLACK);
tft.setTextSize(3);
tft.setTextColor(TFT_WHITE);
tft.drawString("Etalonnage", tft.width() / 2, tft.height()/2);
demandeEtalonnage = true;
}
}
// nettoie l'écran et affiche les infos utiles
void prepareEcran() {
tft.fillScreen(TFT_BLACK);
// texte co2 à gauche
tft.setTextSize(4);
tft.setTextColor(TFT_WHITE);
tft.drawString("CO",25, 120);
tft.setTextSize(3);
tft.drawString("2",60, 125);
// texte PPM à droite ppm
tft.drawString("ppm",215, 120);
// écriture du chiffre
tft.setTextColor(TFT_GREEN,TFT_BLACK);
tft.setTextSize(8);
}
void setup() {
// bouton de calibration
pinMode(BOUTON_CAL, INPUT);
// ports série de debug et de communication capteur
Serial.begin(115200);
Serial1.begin(9600, SERIAL_8N1, RXD2, TXD2);
// initialise l'écran
tft.init();
delay(20);
tft.setRotation(1);
tft.fillScreen(TFT_BLACK);
tft.setTextDatum(MC_DATUM); // imprime la string middle centre
// vérifie l'état de l'ABC
send_Request(ABCreq, 8);
read_Response(7);
Serial.print("Période ABC : ");
Serial.printf("%02ld", get_Value(7));
Serial.println();
int abc = get_Value(7);
// active ou désactive l'ABC au démarrage
if(digitalRead(BOUTON_CAL) == LOW){
if(abc == 0){
send_Request(enableABC, 8);
}else{
send_Request(disableABC, 8);
}
read_Response(7);
get_Value(7);
}
tft.setTextSize(2);
tft.setTextColor(TFT_BLUE,TFT_BLACK);
tft.drawString("Autocalibration", tft.width() / 2, 10);
if( abc != 0 ){
tft.drawString(String(abc)+"h", tft.width() / 2, 40);
}else{
tft.drawString("OFF", tft.width() / 2, 40);
}
// gestion du wifi
wifiMulti.addAP(ssid1, password1);
wifiMulti.addAP(ssid2, password2);
Serial.print("Connexion au wifi");
tft.setTextSize(2);
tft.setTextColor(TFT_WHITE,TFT_BLACK);
tft.drawString("Recherche wifi", tft.width() / 2, tft.height() / 2);
int i = 0;
while(wifiMulti.run() != WL_CONNECTED && i < 3){
Serial.print(".");
delay(500);
i++;
}
if(wifiMulti.run() == WL_CONNECTED){
tft.setTextColor(TFT_GREEN,TFT_BLACK);
Serial.println("Connecté au wifi");
Serial.println("IP address: ");
Serial.println(WiFi.localIP());
tft.drawString("Wifi OK", tft.width() / 2, 100);
setClock();
}else{
tft.setTextColor(TFT_RED,TFT_BLACK);
Serial.println("Echec de la connexion wifi");
tft.drawString("Pas de wifi", tft.width() / 2, 100);
}
delay(3000); // laisse un temps pour lire les infos
// préparation de l'écran
prepareEcran();
//interruption de lecture du bouton
attachInterrupt(BOUTON_CAL, etalonnage, FALLING);
}
unsigned long ancienCO2 = 0;
int seuil = 0;
void loop() {
// effectue l'étalonnage si on a appuyé sur le bouton
if( demandeEtalonnage ){
demandeEtalonnage = false;
// nettoye le registre de verification
send_Request(clearHR1, 8);
read_Response(8);
delay(100);
// demande la calibration
send_Request(calReq, 8);
read_Response(8);
delay(4500); // attend selon le cycle de la lampe
// lit le registre de verification
send_Request(HR1req, 8);
read_Response(7);
int verif = get_Value(7);
Serial.println("resultat calibration "+String(verif));
if(verif == 32){
tft.setTextColor(TFT_GREEN);
tft.drawString("OK", tft.width() / 2, tft.height()/2+30);
}else{
tft.setTextColor(TFT_RED);
tft.drawString("Erreur", tft.width() / 2, tft.height()/2+20);
}
delay(3000);
prepareEcran();
seuil = 0;
}
// lecture du capteur
send_Request(CO2req, 8);
read_Response(7);
unsigned long CO2 = get_Value(7);
String CO2s = "CO2: " + String(CO2);
Serial.println(CO2s);
// efface le chiffre du texte
if(CO2 != ancienCO2){
tft.fillRect(0,0, tft.width(), 60, TFT_BLACK);
}
if( CO2 < 800 ){
tft.setTextColor(TFT_GREEN,TFT_BLACK);
if( seuil != 1 ){
tft.setTextSize(2);
tft.fillRect(0,61, tft.width(), 25, TFT_BLACK);
tft.drawString("Air Excellent", tft.width() / 2, tft.height() / 2 + 10);
}
seuil = 1;
}else if( CO2 >= 800 && CO2 < 1000){
tft.setTextColor(TFT_ORANGE,TFT_BLACK);
if( seuil != 2 ){
tft.setTextSize(2);
tft.fillRect(0,61, tft.width(), 25, TFT_BLACK);
tft.drawString("Air Moyen", tft.width() / 2, tft.height() / 2 + 10);
}
seuil = 2;
}else if (CO2 >= 1000 && CO2 < 1500){
tft.setTextColor(TFT_RED,TFT_BLACK);
if( seuil != 3 ){
tft.setTextSize(2);
tft.fillRect(0,61, tft.width(), 25, TFT_BLACK);
tft.drawString("Air Mediocre", tft.width() / 2, tft.height() / 2 + 10);
}
seuil = 3;
}else{
tft.setTextColor(TFT_RED,TFT_BLACK);
if( seuil != 4 ){
tft.setTextSize(2);
tft.fillRect(0,61, tft.width(), 25, TFT_BLACK);
tft.drawString("Air Vicie", tft.width() / 2, tft.height() / 2 + 10);
}
seuil = 4;
}
tft.setTextSize(8);
tft.drawString(String(CO2), tft.width() / 2, tft.height() / 2 - 30);
// envoi de la valeur sur le cloud
if((millis() - lastTime) >= postingInterval) {
if((wifiMulti.run() == WL_CONNECTED)) {
WiFiClient client;
ThingSpeak.begin( client );
writeTSData( channelID , dataFieldOne , CO2 );
lastTime = millis();
}
}
ancienCO2 = CO2;
delay(10000); // attend 10 secondes avant la prochaine mesure
}
MQTT
Sur ThingSpeak, aller dans Devices > MQTT et compléter si besoin avec la lecture de la documentation MQTT Basics:
- Créer un device,
- Ajouter la/les channel(s) voulu(s),
- Limiter les droits à la partie “subscribe” ; notre client en effet n’est pas prévu pour publier des données sur ThingSpeak,
- Conserver précautionneusement vos identifiants MQTT.
Sur l’instance Warp 10, déployer le plugin MQTT :
Avec le script /path/to/warp10/mqtt/test.mc2 :
// subscribe to the topics, attach a WarpScript™ macro callback to each message
// the macro reads ThingSpeak message to extract the first byte of payload,
// the server timestamp, the channel id and the value
'Loading MQTT ThingSpeak Air Quality Warpscript™' STDOUT
{
'host' 'mqtt3.thingspeak.com'
'port' 1883
'user' 'XXXXXXXXXX'
'password' 'XXXXXXXXXX'
'clientid' 'XXXXXXXXXX'
'topics' [
'channels/channelID 1/subscribe'
'channels/channelID 2/subscribe'
'channels/channelID 3/subscribe'
]
'timeout' 20000
'parallelism' 1
'autoack' true
'macro'
<%
//in case of timeout, the macro is called to flush buffers, if any, with NULL on the stack.
'message' STORE
<% $message ISNULL ! %>
<%
// message structure :
// {elevation=null, latitude=null, created_at=2022-01-11T10:02:27Z, field1=412.00000, field7=null, field6=null, field8=null, field3=null, channel_id=1630275, entry_id=417, field2=null, field5=null, field4=null, longitude=null, status=null}
$message MQTTPAYLOAD 'ascii' BYTES-> JSON-> 'TSmessage' STORE
$TSmessage 'created_at' GET TOTIMESTAMP 'ts' STORE
$TSmessage 'channel_id' GET 'channelId' STORE
$TSmessage 'field1' GET 'sensorValue' STORE
$message MQTTTOPIC ' ' +
$ts ISO8601 + ' ' +
$channelId TOSTRING + ' ' +
$sensorValue +
STDOUT // print to warp10.log
%> IFT
%>
}
Vous devriez avoir dans /path/to/warp10/log/warp10.log :
Loading MQTT ThingSpeak Air Quality Warpscript™
channels/<channelID 1>/subscribe 2022-01-11T10:30:51.000000Z <channelID 1> 820.00000
channels/<channelID 2>/subscribe 2022-01-11T10:30:53.000000Z <channelID 2> 715.00000
channels/<channelID 3>/subscribe 2022-01-11T10:30:54.000000Z <channelID 3> 410.00000
Maintenant que l’intégration MQTT est validée, supprimez ce fichier et passons à la gestion de la persistence des données dans Warp 10.
Avec le script suivant :
// subscribe to the topics, attach a WarpScript™ macro callback to each message
// the macro reads ThingSpeak message to extract the first byte of payload,
// the server timestamp, the channel id and the value.
{
'host' 'mqtt3.thingspeak.com'
'port' 1883
'user' 'XXXXXXXXXX'
'password' 'XXXXXXXXXX'
'clientid' 'XXXXXXXXXX'
'topics' [
'channels/channelID 1/subscribe'
'channels/channelID 2/subscribe'
'channels/channelID 3/subscribe'
]
'timeout' 20000
'parallelism' 1
'autoack' true
'macro'
<%
//in case of timeout, the macro is called to flush buffers, if any, with NULL on the stack.
'message' STORE
<% $message ISNULL ! %>
<%
// message structure :
// {elevation=null, latitude=null, created_at=2022-01-11T10:02:27Z, field1=412.00000, field7=null, field6=null, field8=null, field3=null, channel_id=1630275, entry_id=417, field2=null, field5=null, field4=null, longitude=null, status=null}
$message MQTTPAYLOAD 'ascii' BYTES-> JSON-> 'TSmessage' STORE
$TSmessage 'created_at' GET TOTIMESTAMP 'ts' STORE
$TSmessage 'channel_id' GET 'channelId' STORE
$TSmessage 'field1' GET 'sensorValue' STORE
// Tableau de correspondance entre mes channel IDs et mes devices en vue de définir des labels pour les GTS
{
<channelID 1> 'air1'
<channelID 2> 'air2'
<channelID 3> 'air3'
} 'deviceMap' STORE
// Récupération du nom du device dans la variable senssorId
$deviceMap $channelId GET 'sensorId' STORE
// Création d'une GTS air.quality.home
// Le label "device" aura pour valeur le nom du device, via la variable sensorId
// On crée une entrée qui correspond à la valeur que nous venons de récupérer
// sensorValue est une string, il faut la repasser sur un format numérique
// Une fois la GTS reconstituée avec son entrée, on la periste en base via UPDATE
'<writeToken>' 'writeToken' STORE
NEWGTS 'air.quality.home' RENAME
{ 'device' $sensorId } RELABEL
$ts NaN NaN NaN $sensorValue TODOUBLE TOLONG ADDVALUE
$writeToken UPDATE
%> IFT
%>
}
Depuis le WarpStudio, vérifiez la disposnibilité de vos données :
'<readToken>' 'readToken' STORE
[ $readToken 'air.quality.home' {} NOW -1000 ] FETCH
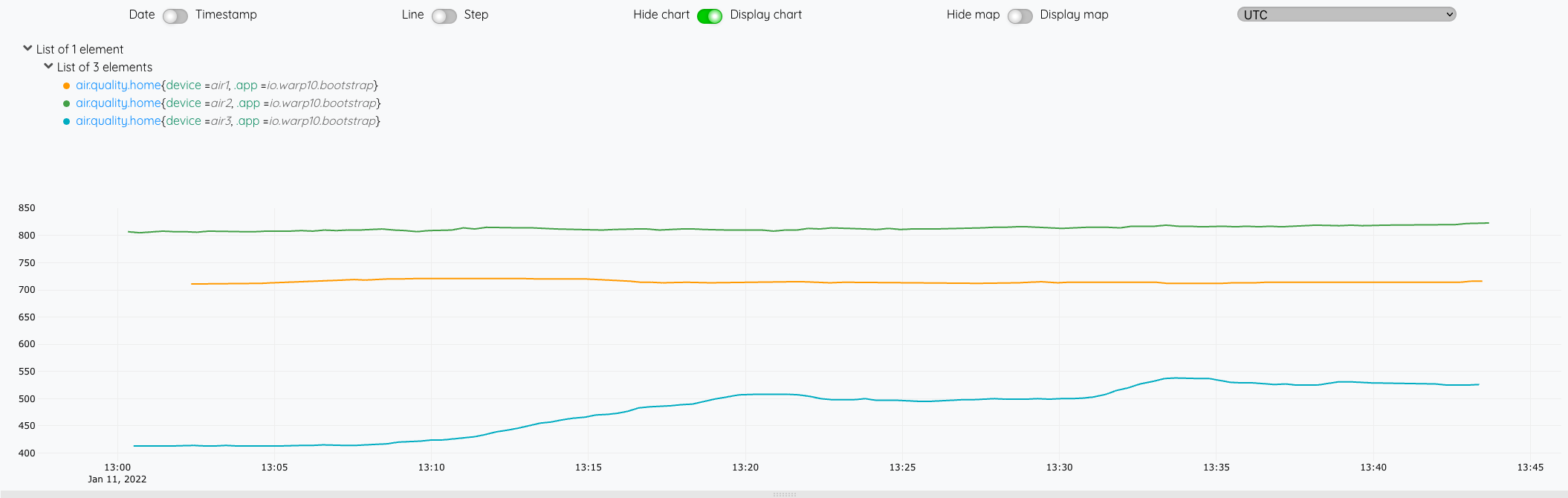
Ensuite, il nous reste plus qu’à faire une petite macro et un dashboard pour présenter les données.
Pour la macro :
- On lui passe un nom de device en paramètre qui servira à filtrer sur le label
- Elle retourne une GTS avec l’ensemble des valeurs disponibles
<%
{
'name' 'cerenit/iot/co2'
'desc' 'Provide CO2 levels per device'
'sig' [ [ [ [ 'device:STRING' ] ] [ 'result:GTS' ] ] ]
'params' {
'device' 'String'
'result' 'GTS'
}
'examples' [
<'
air1 @cerenit/iot/co2
'>
]
} INFO
// Actual code
SAVE 'context' STORE
'device' STORE // Save parameter as year
'<readToken>' 'readToken' STORE
[ $readToken 'air.quality.home' { 'device' $device } MAXLONG MINLONG ] FETCH
0 GET
$context RESTORE
%>
'macro' STORE
$macro
Et pour le dashboard Discovery :
- Chaque tile utilise la macro que l’on vient de réaliser en lui passant le device en paramètre,
- Chaque tile affiche un système de seuils avec des couleurs associées.
<%
{
'title' 'Home CO2 Analysis'
'description' 'esp32 + Senseair S8 sensors at home'
'options' {
'scheme' 'CHARTANA'
}
'tiles' [
{
'title' 'Informations'
'type' 'display'
'w' 6 'h' 1 'x' 0 'y' 0
'data' {
'data' 'Détails et informations complémentaires : <a href="https://www.cerenit.fr/blog/air-quality-iot-esp32-senseair-thingspeak-mqtt-warp10-discovery/">IoT - Qualité de l air avec un esp32 (TTGo T-Display), le service ThingSpeak, du MQTT, Warp 10 et Discovery</a>'
}
}
{
'title' 'Device AIR1'
'type' 'line'
'w' 6 'h' 2 'x' 0 'y' 1
'macro' <% 'air1' @cerenit/macros/co2 %>
'options' {
'thresholds' [
{ 'value' 400 'color' '#008000' }
{ 'value' 600 'color' '#329932' }
{ 'value' 800 'color' '#66b266' }
{ 'value' 960 'color' '#ffdb99' }
{ 'value' 1210 'color' '#ffa500' }
{ 'value' 1760 'color' '#ff0000' }
]
}
}
{
'title' 'Device AIR2'
'type' 'line'
'w' 6 'h' 2 'x' 6 'y' 1
'macro' <% 'air2' @cerenit/macros/co2 %>
'options' {
'thresholds' [
{ 'value' 400 'color' '#008000' }
{ 'value' 600 'color' '#329932' }
{ 'value' 800 'color' '#66b266' }
{ 'value' 960 'color' '#ffdb99' }
{ 'value' 1210 'color' '#ffa500' }
{ 'value' 1760 'color' '#ff0000' }
]
}
}
{
'title' 'Device AIR3'
'type' 'line'
'w' 6 'h' 2 'x' 0 'y' 3
'macro' <% 'air3' @cerenit/macros/co2 %>
'options' {
'thresholds' [
{ 'value' 400 'color' '#008000' }
{ 'value' 600 'color' '#329932' }
{ 'value' 800 'color' '#66b266' }
{ 'value' 960 'color' '#ffdb99' }
{ 'value' 1210 'color' '#ffa500' }
{ 'value' 1760 'color' '#ff0000' }
]
}
}
]
}
{ 'url' 'https://w.ts.cerenit.fr/api/v0/exec' }
@senx/discovery2/render
%>
Le résultat est alors :
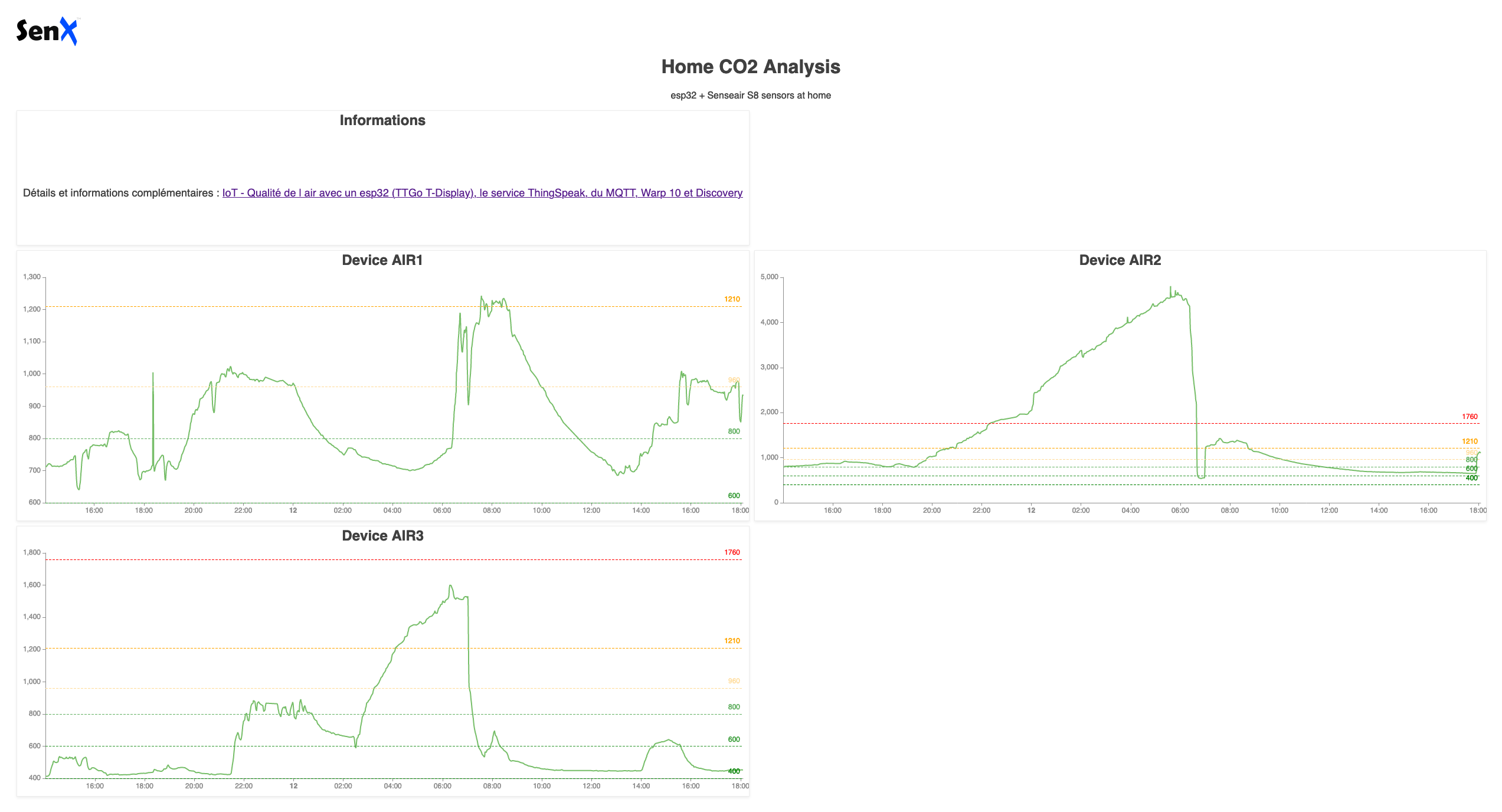
Bilan de ce que nous avons vu :
- Comment monter son capteur de CO2 en profitant des ressources mises à disposition par le projet “Nous Aérons”,
- Comment envoyer les données du capteur vers le service ThingSpeak,
- Comment récupérer les données du service ThingSpeak via le protoole MQTT et les stocker dans Warp 10,
- Comment créer un dashboard Discovery avec une macro permettant de récupérer les données et mettre en place un système de seuils.
