Web, Ops, IoT & Time Series
Notre veille technique mensuelle : IA, données, time-series, craft et tout ce qui bouge dans nos métiers.
Ma comptabilité, une série temporelle comme les autres - partie 6 - Les FEC et le compte de résultat
Suite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512
- Partie 6 - Les FEC et le compte de résultat (ce billet)
Dans ce sixième et dernier billet pour cette série, nous continuons avec les Fichier d’Ecritures Comptables (FEC) pour produire le compte de résultat et déterminer ainsi le bénéfice de l’exercice en cours. Il faut donc prendre toutes les opérations en classe 6 (charges) et 7 (produits). Pour chaque classe de compte, il peut y avoir des crédits ou des débits (ex pour un compte de classe 7 : un avoir sur une facture émise). C’est donc un chouilla plus compliqué que le compte de trésorerie.
Web, Ops, Data et Time Series - Octobre 2021
BI
- Smart Data Analytics : Exploration des données comptables : pour changer des outils de séries temporelles, je me suis livré au même exercice d’ingestion et de traitement des FEC avec la Smart Data Analytics (SDA) de DataTask. Basée sur singer, dbt et metabase, la SDA permet via une Web UI de définir son flow d’ingestion et de transformation. Une fois ces transformations réalisées, il ne reste plus qu’à explorer les données avec Metabase et produire ses dashboards.
Code
- vscode.dev : l’ère de l’IDE dans le navigateur continue après gitpod ou githuab codspaces, c’est au tour de vscode.dev qui permet d’avoir une IDE dans son navigateur. Affaire à suivre…
Observabilité et monitoring
- Vector 0.17.0, Vector 0.17.1, Vector 0.17.2 & Vector 0.17.3 avec l’adaptive concurrency qui permet de gérer le “back pressure” pour les destinations accessibles via HTTP, et pour les sources une gestion simplifiée pour le décodage d’éléments et leur “framing”.
- Vector Remap Language : extension Vector pour VSCode
Orchestration & conteneurs
- damon, un dashboard pour nomad en ligne de commande.
- Announcing HashiCorp Nomad 1.2 Beta : ajout des “System Batch” qui sont des (petits) jobs globaux au cluster, des améliorations de l’interface et l’ajout des Nomad Pack, une sorte de catalogue d’applications prêtes à être déployées dans votre cluster.
SQL
- PostgreSQL 14 Released! ou en français PostgreSQL 14 ou un thread twitter pour découvrir les nouveautés de cette version : amélioration du support de JSONB, type multirange, fonctions autour des dates, etc.
Sécurité
- Popular NPM library hijacked to install password-stealers, miners : analyse de la librairie ua-parser-js compromise dans ses version 0.7.29, 0.8.0 et 1.0.0 avec l’ajout un mining de crypto et un voleur de mot de passes. Le passage en version 0.7.30 / 0.8.1 et 1.0.1 est à faire dans les plus brefs délais. Pour les dépendances indirectes, il est possible d’ajouter dans son fichier
package.json:"resolutions": { "ua-parser-js": "^0.7.30" }via Security issue: compromised npm packages of ua-parser-js (0.7.29, 0.8.0, 1.0.0) - Questions about deprecated npm package ua-parser-js
Time Series
Annonces & Produits :
n8n & Warp 10 - Automatisez vos manipulations de séries temporelles
Il y a quelques temps et sachant que j’utilisais n8n pour automatiser la génération des brèves du BigData Hebdo, Mathias m’a demandé s’il était possible de faire la même chose entre n8n et Warp 10 qu’avec node-red et Warp 10.
La réponse est oui mais voyons comment faire cela.
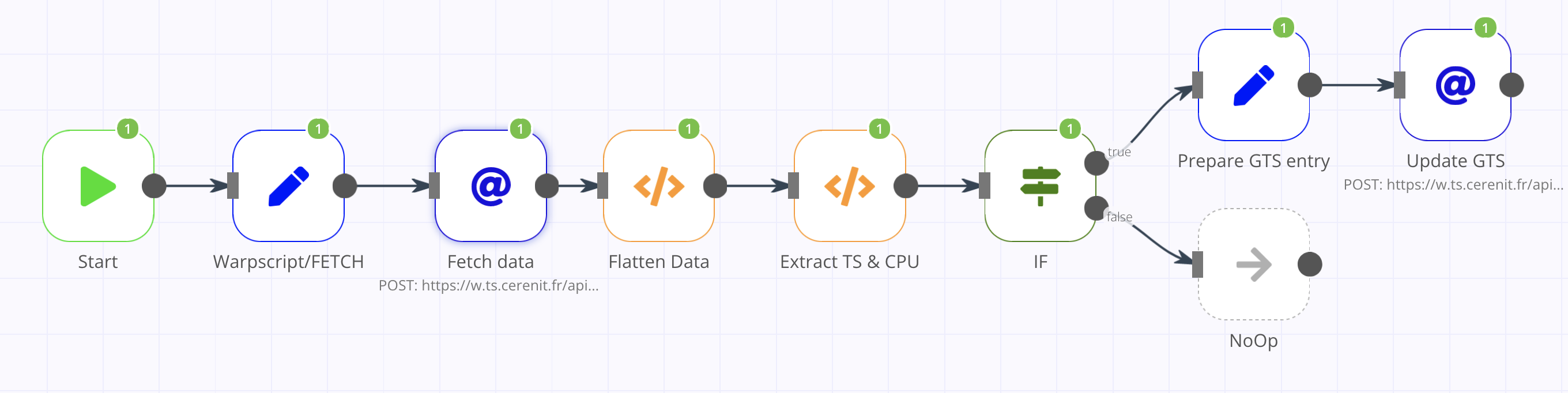
Pour ceux qui ne connaissent pas n8n, c’est un clone open source (sous licence fair-code) à des services comme Zapier ou IFTTT. Il permet d’automatiser des processus via la création de workflows. Ces workflows sont composés d’étapes et d’actions. n8n dispose d’un grand nombre de connecteurs vers les différents services existants, des opérateurs génériques (faire un appel http, appliquer une fonction), des opérateurs logiques (si, etc), des opérateurs de transformation de données, etc. Chacun de ces éléments est implémenté via une node. A chaque étape du workflow, une node est instanciée puis paramétrée. Les nodes peuvent être reliées entre-elles et la sortie d’une node peut alimenter la suivante.
InfluxDB et les alertes : Tasks, Checks et Notifications
CérénIT vient de finaliser la migration pour un de ses clients d’un socle InfluxDB/Chronograf/Kapacitor vers InfluxDB2. Ce billet est l’occasion de revenir sur la partie alerting et de la migration de Kapacitor vers des alertes dans InfluxDB2.
Dans le cadre du socle InfluxDB/Chronograf/Kapacitor, le fonctionnement était le suivant :
- Les utilisateurs créent une alerte via l’application métier en définissant un à plusieurs critères d’alertes ; ex: est-ce que l’unité est opérationnelle et est-ce que l’humidité est supérieure à tel taux ou la température supérieure à telle valeur.
- L’application métier traduisait l’alerte en TickScript et enregistrait l’alerte auprès de Kapacitor via son API HTTP
- Kapacitor, en mode streaming, évalue si l’alerte doit être levée ou pas au fur et à mesure de l’arrivée des données
- En cas de seuil franchi, Kapacitor envoie un message à l’application métier via l’API HTTP de cette dernière.
- L’application métier envoie ensuite un mail et/ou un SMS à l’auteur de l’alerte.
Avant d’envisager la migration InfluxDB2, un point de vocabulaire :
InfluxDB, shard, shard duration et retention policies
CérénIT a été contacté pour mener l’audit d’une instance InfluxDB 1.8 OSS utilisée dans un projet IoT lié à l’énergie. L’audit avait plusieurs objectifs :
- Comprendre la consommation mémoire de l’instance (48Go / 64Go de la VM)
- Faire un état de santé de la plateforme et estimer sa capacité à stocker et procésser des données supplémentaires dans le cadre de l’ouverture d’une application métier
- Expliquer la raison des problèmes observés par le passé et évaluer les solutions apportées
- Etablir des recommendations et éventuellement les implémenter.
De l’audit, on notera que :
- L’instance contient ~35.000 shards / ~36.000 tsm files pour environ 200 bases permanentes et des dizaines de bases éphémères permettant de calculer des indicateurs ou de recalculer des historiques de données suite à des changements de paramètres de l’application métier (plusieurs dizaines de milliers de bases temporaires par semaine, avec des profondeurs de données variables)
- Les recommendations pour InfluxDB Enterprise sont d’avoir 30/40 bases par data nodes et 1.000 shards par data node
Avant d’aller plus loin, précisons un peu cette notion de shard et les notions liées pour bien appréhender le sujet :
Web, Ops, Data et Time Series - Septembre 2021
Cloud
- LCC 262 - Interview Cloud de Confiance avec Quentin Adam : Interview posée, pédagogue et claire sur les enjeux du cloud de confiance / cloud souverain mais pas que. A écouter absolument.
- Announcing Cloudflare R2 Storage: Rapid and Reliable Object Storage, minus the egress fees : après son billet vindicatif vis à vis des couts de transferts AWS, Cloudflaire sort son système de fichiers distribué qui se veut une alternative à S3 et avec un cout de migration depuis AWS marginal/progressif puisque apparemment seuls les fichiers appelés seront sortis de leur bucket d’origine pour aller sur R2 et être servi depuis R2 ensuite
- The Compelling Economics of Cloudflare R2 : quelques exemples des économies réalisées entre R2 et S3 ou R2 en mode proxy devant S3.
Container et Orchestration
- Docker is Updating and Extending Our Product Subscriptions : TL;DR: Docker Desktop requiert un abonnement Pro/Team/Business si vous êtes une organisation de plus de 250 employés et 10 Millions de Chiffre d’affaires. L’abonnement commence à 5$/mois/utilisateur. Ce changement démarre au 31/08/2021 avec une période de grâce jusqu’au 31/01/2022. Si certains crient au scandale, il faut bien voir tout ce que Docker Desktop fourni et le travail d’intégration que cela représente. Il faut bien que la société Docker vive pour maintenir ses produits. Tout cela se retrouve dans The Magic Behind the Scenes of Docker Desktop.
- Podman Release v3.3.0 : cette version apporte “podman machine” qui devrait notamment permettre un meilleur support de podman sous OSX avec une couche de virtualisation intermédiaire dans la même veine que Docker Desktop dans le but de proposer une intégration native. Cela ne semble pas fonctionner sur un Apple M1 à cause de l’incompatibilité actuelle de Virtual Box avec ces puces. Si Podman peut certes être une alternative à Docker (Desktop), cela montre aussi le travail d’intégration réalisé par Docker Inc notamment pour le support des Apple M1.
- Podman on Macs Update : statut sur le support de Podman dans un context MacOS/Intel, Windows/Intel et le reste à faire pour MacOS/M1. En attendant,
podman machineest supporté nativement sur Linux et MacOS/Intel et en remote client sur Windows/Intel. - How Docker broke in half : restrospective sur Docker de ses origines à aujourd’hui et quelques pistes pour le futur…
- Docker Compose V2.0.0 : L’outil a été réécrit en go plutôt qu’en python et se veut accessible via la docker cli en tant que sous système (ie
docker compose xxx). Pour Windows & OSX, il est fourni avec Docker Desktop. - Accelerating New Features in Docker Desktop où l’on parle de l’arrivée prochaine d’un Docker Desktop For Linux !!
- No, we don’t use Kubernetes : un billet rafraichissant qui rappelle que Kubernetes n’est pas l’alpha et l’omega de l’infrasatructure.
IoT
- CircuitPython 7.0.0 Released! : version majeure de CircuitPython qui apporte son lot d’améliorations matérielles et logicielles depuis la version 6.3
- tinygo 0.20 : principalement l’ajout du support de Go 1.17 et de nouveaux controlleurs.
JVM
- Good-bye AdoptOpenJDK. Hello Adoptium! : le projet AdoptOpenJDK est repris sous le projet Eclipse Adoptium, qui vient de signer sa première release. Il faudra prévoir une migration vers leurs binaires et leurs dépots ultérieurement (date non définie à ce jour).
Recherche
- Nrtsearch: Yelp’s Fast, Scalable and Cost Effective Search Engine : nouvel entrant dans le monde de la recherche distribuée et opensource basée sur Lucene. Après ElasticSearch et OpenSearch, c’est au tour de Nrtsearch édité par Yelp qui a cherché à résoudre les problèmes qu’ils rencontraient avec ElasticSearch.
Sécurité
- GitHub security update: Vulnerabilities in tar and @npmcli/arborist : si vous utilisez le package
tarde NodeJS directement (ou indirectement), il est judicieux de mettre à jour votre version denpmetnodeet de vérifier vos dépendances. - Demon’s Cries vulnerability (some NETGEAR smart switches) : si vous avez des “smart switchs” de la marque Netgear, il est temps de patcher le firmware de votre équipement.
- Let’s Encrypt’s Root Certificate is expiring! : si vous avez de vieux équipements dans la nature et qu’ils utilisent ce certificat de Lets Encrypt, il y a des chances qie cela se passe mal à compter de demain…
Time Series
- Industrie du futur : les données sur le chemin critique, Industrie du futur : les données sur le chemin critique – Partie 2 et Industrie du futur : les données sur le chemin critique – Partie 3 : Suite d’un premier article “Les séries temporelle : le futur de la donnée qui continue à poser les enjeux de l’industrie du futur et les évolutions que cela va apporter pour permettre une maintenance analytique (version optimisée de la maintenance préventive et réactive/conditionelle), la data pour la création de nouveaux services et générateurs de revenus (directs ou indirects), les jumeaux numériques et sur un fond de synergies entre l’informatique technique et celle de gestion pour une optimisation des process.
- Server monitoring with Warp 10 and Telegraf : Premiers pas pour la mise en place d’une stack de monitoring avec Telegraf / Warp 10 et Discovery ; manque plus que la suite à Alerts are real time series pour avoir la partie alerting (et notifications ?).
- Discovery : la documentation de la solution de Dashboard as Code pour Warp 10 est (enfin) arrivée !
- winedarksea/AutoTS : tout est dans la description : “AutoML for forecasting with open-source time series implementations.” ; c’est en Python et cela embarque beaucoup de classes / modèles / transformations / …
- Anomaly Detection Toolkit (ADTK) : un framework de détéction d’anomalies en python.
- QuestDB 6.0.5 & QuestDB 6.0.5 September release, geospatial support : la géotimeseries devient tendance : après InfluxDB qui l’a introduit il y a un an environ, et bien longtemps après Warp 10, c’est au tour de QuestDB d’introduire le support des données géospatiales. La version apporte aussi des améliorations sur
first()etlast()ainsi que les nouvelles fonctionstimestamp_floor()ettimestamp_ceil()pour gérer les arrondis inférieurs/supérieurs. Enfin, l’API HTTP accepte des paramètres liés au “Out Of Order”. - QuestDB 6.0.6 : version de maintenance
- QuestDB 6.0.7 : la version 6.0.6 introduit un bug dans le cadre de la migration depuis une version antérieure. La version 6.0.7 apporte un correctif sur le sujet. Si vous êtes en en 6.0.6, mettre à jour * [en 6.0.7 - si vous êtes dans une version inférieure à 6.0.6, passez à la version 6.0.7 sans passer par la case 6.0.6
- QuestDB 6.0.7.1 : en espérant que cette version soit enfin la bonne pour les migrations.
- TimescaleDB 2.4.2 : version de maintenance
- InfluxDB’s Checks and Notifications System : un billet très détaillé sur le fonctionnement des checks et des notifications sous InfluxDB v2 pour mettre en place vos alertes.
- New in Grafana 8.1: Gradient mode for Time series visualizations and dynamic panel configuration : un mode gradient pour les time series qui permet d’appliquer des couleurs sur ses graphs en fonction de seuils.
Web, Ops, Data et Time Series - Aout 2021
Conteneurs et orchestration
- Engineering Update: BuildKit 0.9 and Docker Buildx 0.6 Releases : diverses améliorations au niveau du format Dockerfile, de buildtkit et de docker-buildx. Le changement le plus visible et apprécié sera surement le support de la syntaxe “Here-Documents”
- Rook v1.7 Storage Enhancements : Possibilité d’installer un cluster Ceph via un chart Helm (plutôt que via les manifests), des options d’amélioration de la résilience d’un cluster (file mirroring, resource protection from delettion, “stretch cluster” passe en stable) et d’autres améliorations diverses (mise à jour des CRD, etc). A noter que le driver flex va disparaitre en 1.8 au profit du driver CSI.
- Announcing Traefik Proxy 2.5 : Support de Kubernetes 1.22 (et mise à jour des CRD associées, ainsi que des API dépréciées), support de Consul Connect (le service mesh fourni par consul), gestion des plugins locaux et possibilité de créer ses propres providers (dans la même veine que Docker, Kubernetes, etc), support expérimental d’HTTP/3 et enfin ajout des middleware au niveau TCP (et pas uniquement HTTP)
- Integrating Consul Connect Service Mesh with Traefik 2.5 : ex d’intégration Traefik 2.5 avec Consul Connect.
- Beta Support for CRDs in the Terraform Provider for Kubernetes : la resource
kubernetes_manifestpermet de définir ses propres manifests et donc permet d’utiliser des CRD non disponibles dans le provider officiel. Plus pratique que de générer les manifests via des templates et de faire dukubectl applypar dessus.
Go
- Learning Go by examples : Les parties 4 à 7 sont arrivées avec du CLI, du Bot, du jeu, des app Desktop/GUI, etc.
Monitoring & Observabilité
- Grafana Labs Raises $220 Million Round at $3 Billion Valuation : Grafana Labs continue sur sa lancée avec une 3ème levée de fonds de 220 M$ quasiment un an jour pour jour après leur série B. Soit un total de 295 M$ et une valorisation de 3 Mds $. Ils avaient annoncé il y a quelques années vouloir batir une solution à 360° de l’observabilité, c’est en train de se réaliser. Avec l’intelligence de pouvoir utiliser tout ou partie de leurs produits en fonction de nos besoins.
- Vector v0.16.0 release notes : Ajout d’une source nats, support des proxys HTTP, amélioration du rate limiting des sinks faisant des appels HTTP, chart helm en beta et d’autres améliorations.
Time Series
- Release Announcement: InfluxDB OSS & Enterprise 1.8.9 : version de maintenance de la branche 1.8 OSS & Entreprise - les versions les plus récentes en 0SS étant 2.0.8 et en Entreprise 1.9.3
- Release Announcement: InfluxDB OSS 2.0.8 : passage à Go 1.16, mise à jour de Flux, d’Influx-UI et de flux-lsb-browser. Il est également possible de ne plus lancer l’UI Web. Cette version est la dernière qui aura le client influx fourni avec le binaire du serveur. A compter la version 2.1.0, il faudra télécharger le client indépendamment. Il faudra le récupérer depuis le projet github influx-cli ou la page de téléchargement InfluxData
- Move fast, but don’t break things: Introducing the experimental schema (with new experimental features) in TimescaleDB 2.4, TimescaleDB 2.4.0 et TimescaleDB 2.4.1 : Comme annoncé précédemment, Postgresql 11 n’est plus supporté pour pouvoir apporter certaines nouvelles fonctionnalités. Cette version apporte le “schéma experimental” qui permet de tester des fonctionnalités en avance de phase, sans impacter ceux qui n’en ont pas besoin. Cela apporte aussi des fonctions comme
time_bucket_ngqui permet de faire de nouvelles aggrégations et d’avoir prochainement un support des timezones. La seconde fonctionnalité expérimentale porte sur la capacité à bouger de la donnée entre plusieurs nodes en mode cluster.
Web, Ops, Data et Time Series - Juillet 2021
CI/CD
- Builder simplement des images Docker avec Gitlab-CI (sans DinD) : Personnellement, j’avais migré sous Kaniko depuis un moment. Je ne savais pas que Buildah pouvait ingérer directement des Dockerfile - il me semblait qu’il fallait passer par Podman pour ça. En reprenant le changelog, il semblerait que la fonctionnalité existe depuis un moment.
Cloud
- AWS’s Egregious Egress : Réflexions de Cloudflare sur la tarification du traffic sortant chez AWS et la marge réalisée. A priori, cela ne se base pas uniquement sur des raisons objectives…
- 23 entreprises européennes de technologie du cloud forment l’Alliance industrielle européenne du cloud (EUCLIDIA) : nouvelle association en faveur du cloud européen sur la base de technologies et de sociétés europénnes.
- « Service après-vente bonjour ! » : Le futur de la French Tech ? : tribune d’acteurs français suite à la doctrine du “cloud souverain” et l’utilisation de licences américaines.
Container & Orchestration
- Kubernetes API and Feature Removals In 1.22: Here’s What You Need To Know : les habituelles dépréciéations d’API prévus pour la version 1.22 (Aout 2021)
- Kubernetes Kosmos : sCaleway lance son offre kuberentes multi-cloud et piloté par leur controle plane. En mode private beta pour le moment.
Golang
- Learning Go by examples: Introduction : Après ses explications sur Docker, Istio et Kubernetes, Aurélie Vache s’attaque à Go.
- Learning Go by examples: part 2 - Create an HTTP REST API Server in Go
- Learning Go by examples: part 3 - Create a CLI app in Go
IA
- AI Days 2020 : la playlist youtube des AI Days 2021 est disponible, avec un angle industriel qui change de d’habitude.
Monitoring
- Vector v0.15.0 release notes : de nouveaux sinks & sources, des transformations et de la visualisation. Vector s’améliore au fil des versions.
Sécurité
- Remote code execution in cdnjs of Cloudflare : cdnjs est un CDN pour des ressources en javascript. Mais que peut-il se passer en cas de faille ou de compromission de ce CDN ? C’est le propos de ce billet.
Time Series
- Covid Tracker built with Warp 10 and Discovery : un tutoriel pour apprendre plein de choses sur Discovery, la solution de dashboard as code de SenX pour Warp 10.
- Kats: a Generalizable Framework to Analyze Time Series Data in Python : j’avais évoqué Katz dans une édition précédente, voici un billet qui rentre un peu plus dans le détail des fonctionnalités disponibles.
WireGuard
- WireGuard Site to Site Configuration : si la documentation pour une configuration itinérante (“Road Warrior”) est assez bien documentée, pour du site à site, c’est plus rare. Une explication simple et efficace.
- OPNsense WireGuard VPN Site-to-Site configuration : la même chose mais appliquée à un routeur géré par OPNSense
- OPNsense WireGuard VPN for Road Warrior configuration : la version “Road Warrior” du tutoriel précédent
- WireGuard Road Warrior Setup : la documentation officielle d’OPNSense pour la version “Road Warrior”
Web, Ops, Data et Time Series - Juin 2021
Automatisation
- Announcing HashiCorp Terraform 1.0 General Availability : Terraform 1.0 est (enfin) GA.
- Announcing Consul 1.10 GA : des améliorations surtout sur la partie “Service Mesh” aka Consul Connect, ainsi que coté UI.
Conteneurs et orchestration
- Lens 5 Released - Release Notes : le “Kubernetes IDE” passe en version 5 avec diverses améliorations dont notamment du collaboratif avec du partage de contexte kubernetes.
- Traefik 2.5, quoi de neuf ? : actuellement en RC2, la version 2.5.0 de Traefik devrait apporter un support expérimental d’HTTP/3, le support des plugins privés, la mise à jour des CRD Kubernetes et les métriques par routeur (désactivé par défaut)
Monitoring & Observabilité
- Grafana 8.0: Unified Grafana and Prometheus alerts, live streaming, new visualizations, and more! : Grafana dans sa version 8.0 avec son lots d’amélioration.
- GrafanaCONline 2021: Your guide to the newest announcements from Grafana Labs : Résumé de la 1ère journée de GrafanaCon avec Grafan 8, Tempo 1.0, etc.
- What’s new in Grafana v8.0 : une version plus détaillée des apports de la version 8.0 de Grafana
- Vector v0.14.0 Release Notes : Vector permet maintenant d’exécuter des scripts externes via la source
exec. - Release Announcement: Telegraf 1.19.0 : version incrémentale avec son lot d’améliorations et de corrections.
- Grafana Labs Brings Modern Open Source Load Testing to Observability with Acquisition of k6 : Grafana Labs étend son offre d’observabilité avec l’acquisition de k6, un outil de test de charge et de performance.
Postgresql
- PostgreSQL as a Microservice : on pense souvent qu’une base de données permet la persistence des données. Ce n’est pas le principal enjeu d’une base de données mais la gestion de la concurrence.
Time Series
- Release Announcement: InfluxDB OSS 2.0.7 : version de maintenance avec des correctifs et la mise à jour de Flux.
- Release Announcement: Chronograf 1.9.0 : Version 1.9 de Chronograf, l’outil de dasboard et exploration des données d’InfluxData pour InfluxDB 1.x et 2.x. Cette version apporte un meilleur support de Flux (template variable, etc), le support au niveau UI du support TickScript & Flux de Kapacitor 1.6 (release à venir), un mode HA et pleins d’autres améliorations. Une version qui peut être utile dans le cadre d’une migration progressive d’InfluxDB 1.x vers 2.x
- influxdata/influxdb-stack-manager : pour gérer plus efficacement vos “stacks” InfluxdB (dashboard, tasks, etc). Requiert la cli influx.
- TSFR Edition #11 - Récapitulatif InfluxDays EMEA 2021 : Edition un peu particulière du meetup - n’ayant pas pu l’organiser dans les temps mais l’ayant préparé, voici sous forme vidéo le résumé des annonces produits d’InfluxData dans le cadre des InfluxDays EMEA 2021.
- TSFR Edition #12 - Le Bateau Qui Vole - Exploiter des données de navigation pour remporter les courses au large : un retour pragmatique et assez complet sur la mise en place d’un process de collecte / traitement / analyse des données d’un trimaran et des problématiques rencontrées.
- Interacting with Git repositories from Warp 10 : dans le cadre de la version 2.8 de Warp 10, des nouvelles capacités autour de l’interaction avec des dépots git sont disponibles. L’article présente des interactions de base mais j’ai encore du mal à voir les cas d’usage auxquels cela semble vouloire répondre.
- Protecting your Macros and Functions with Capabilities : Avec Warp 10 2.8, il est désormais possible de définir des “capacités” et de contrôler plus finement les actions des utilisateurs au travers de ces capacités.
- WarpStudio v2: What’s new in our Web IDE? : nouvelle version du WarpStudio de SenX, l’IDE Web prévue pour Warp 10 : support de FLoWS, documentation intégrée, intégration git, support de Disocvery (Dashboard as code), snippets, etc.
- Ma comptabilité, une série temporelle comme les autres - partie 5 - Les FEC et le compte 512 : si vous l’avez raté, nouvelle partie sur la comptaiblité, une série temporelle comme les autres avec cette fois-ci l’ingestion des fichiers d’écritures comptables (FEC) et l’analyse du compte 512 (banque)
- Don’t write your own persistence layer: why we chose RocksDB : retour d’exéprience de QuasarDB sur le choix de la couche de persistence entre batir sa propre solution (spoiler : mauvaise isée), utiliser LevelDB (comme Warp 10) ou faire le choix de RocksDB.
- Meet Kats — a one-stop shop for time series analysis - facebookresearch/Kats - Kats - One stop shop for time series analysis in Python : Facebook vient de sortir une librairie en python qui veut fournir un “tout en un” de la manipulation de séries temporelles. On y retrouve notamment Prophet pur la partie prédiction.
Ma comptabilité, une série temporelle comme les autres - partie 5 - Les FEC et le compte 512
Suite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512 (ce billet)
- Partie 6 - Les FEC et le compte de résultat
Dans ce cinquième billet, nous allons parler de Fichier d’Ecritures Comptables (FEC) et d’un compte simple à analyser : le compte 512 qui correspond à votre compte en banque.
Besoin d'un C(P)TO / Architecte « hands-on » ?
On orchestre, on conçoit — et on code aussi. Parlons de votre plateforme, vos données ou votre projet IoT.
Contactez-nous →