Web, Ops, IoT & Time Series
Notre veille technique mensuelle : IA, données, time-series, craft et tout ce qui bouge dans nos métiers.
Web, Ops, IoT et Time Series - Février 2024
Code
- The power of conventional commits : je suis assez fan de Gitmoji + Conventional Commits pour avoir des messages de comits visuels et pertinents. Si la mise en oeuvre est parfois pas très naturel, le plaisir d’avoir un changelog autogénéré et propre ou bien de pouvoir facilement retrouver un commit, son intention et le ticket gitlab associé, cela n’a pas de prix.
- En liaison avec le billet précédent, le générateur de changelog Git-cliff est sorti en version 2.0 avec notamment une intégration plus poussée avec Github, des templates et plein d’autres choses. Git-cliff depuis la version 1.4 peut aussi générer votre prochain numéro de version sur la base de vos commits et la commande bump
- Postgres à nouveau élu SGBD de l’année en 2023, mais je suis inquiet: le cloud et les ORM notamment ont permis de s’affranchir des DBA. Si dans un sens c’est tant mieux, à un certain stade, cela s’avère nécessaire de recourir à l’expertise d’un DBA (même si c’est parfois trop tard). Reste que le problème fondamental est plutôt que les développeurs n’ont plus les fondamentaux en SQL dans ce cas particulier et en architecure logicielle de manière plus globale et c’est peut être surtout ça le vrai problème.
- The continuous amnesia issue : notre industrie est malade, on souffre d’une amnésie continue en ignorant les enseignements du passé. Le “jeunisme”, “la hype” et le fait qu’au delà de 30 ans, il faut être passé du coté du management font qu’on ne valorise/capitalise pas assez sur ce que nos ainés ont fait.
- The High-Risk Refactoring : l’amémioration / la réécriture de code a son lot inhérent de risques techniques et métiers. L’article permet d’appréhener et de cadrer cette décision de façon assez pragmatique pour arriver au niveau de code juste nécessaire.
DNS
- L’ICANN propose le domaine .internal pour votre réseau local : historiquement, il y avait le .local mais dont l’usage a été revu pour du zeroconf notamment. L’usage du
.internalest en cours de discussion pour une décision en avril. On va pouvoir (enfin) sortir des domaines fictifs, des domaines publics utilisés en interne (adieumacompany.org) ou encore du “DNS menteur” (macompany.comrésolu différemment suivant si on est en interne ou en externe). Néanmoins, une bonne question émerge : comment gérer et garantir les certificats en.internalque tout le monde peut revendiquer ? Aucune entité de certification publique ne pourra émettre de tels certificats… Cela repose alors la question de la PKI privée et de la diffusion des certificats de la CA pour valider les domaines sur votre parc informatique…
OPS
- Traefik Proxy v2.11 is Now Available! Here are the Latest Updates. : Cette version apporte notamment les directives
keepAliveMaxRequestsetkeepAliveMaxTimepour éviter que trop de connections ouvertes restent entre votre reverse proxy et votre applicatif. - Announcing Traefik Proxy v3.0 RC1: Au programme: Wasm, OpenTelemetry, HTTP/3, SPIFFE et des choses dans le monde Kubernetes. Alors que la migration V1/V2 avait été un peu pénible, l’équipe de Traefik promet une migration en douceur entre V2/V3.
Web
- L’AVIF prend enfin ses aises sur Internet : c’est quoi ce format d’image ? : L’AVIF, un format d’image opensource et qui a pour vocation de remplacer le JPEG est enfin supporté sous Microsoft Edge (les autres navigateurs le supportent depuis 2020/21). Reste plus que le poids des habitudes pour remplacer le bon vieux jpeg par un avif.
- JXL et AVIF – Les nouveaux champions des formats d’image : en continuité du point précédent, il y a aussi JXL pour JPEG XL et des outils pour générer vos premiers fichiers aux formats AVIF/JXL.
- iOS 17.4 seems to remove web app support in the EU - Update on apps distributed in the European Union - Support - Apple Developer - En Europe, iOS 17.4 enterre les applications web - Next : le support des PWA sous iOS 17.4 a sauté au prétexte du DMA européen mais l’Europe demande des explications sur le sujet.
- What PWA Can Do Today : Pour savoir ce qu’il est (encore) possible de faire avec une PWA sous iOS et Android.
Web, Ops, IoT et Time Series - Janvier 2024
Après presque 2 ans de silence et le remplacement de Hugo et Bootstrap par Zola et Tailwind/daisyUI l’été dernier pour générer le site, je vous souhaite une bonne année à tous et la résolution de publier plus régulièrement mes trouvailles…
Data
- Multi-Database Support in DuckDB : Cela multiplie les possibilités :sunglasses:
TL;DR: DuckDB can attach MySQL, Postgres, and SQLite databases in addition to databases stored in its own format. This allows data to be read into DuckDB and moved between these systems in a convenient manner.
IoT
- Devenez un expert LoRaWAN via LoRa et LoRaWAN pour l’Internet des Objets: si vous cherchez un cours théorique et pratique pour vous former aux protocoles LoRa et LoRaWan, je vous le recommande chaudement.
Ops
- DKron via Dkron pilote vos crontab : un gestionnaire de cron distribué, avec une jolie interface et uen API - que demander de plus ? Sur un modèle agent/serveur, le serveur dRkon distribue les tâches aux agents dKron concernés. les agents dKron étant déployés sur les serveurs sur lesquels les jobs doivent s’exécuter.
Reverse Proxy
- Caddy : si vous avez besoin d’un reverse-proxy avec gestion automatique des certificats et redirection HTTP > HTTPS et plein d’autres choses encore mais sans nécessité d’intégration avec Docker comme Traefik, alors jetez un coup d’oeil à Caddy. Il permet également d’avoir un certificat sur localhost. Comme Traefik, il est écrit en Go.
J’avoue que la concision de Caddy vs Traefik et le provider file est bien appréciable:
Vers de nouveaux horizons...
Je l’évoquais dans le billet “Bilan 2021 et perspectives 2022”, je peux en parler maintenant officiellement : j’ai été contacté par Flovea pour piloter le projet Flowbox Interactive et mettre en place l’équipe projet associée.
Après trois mois environ de mission permettant de faire connaissance, d’auditer la solution existante, de définir une roadmap et de mettre en place l’équipe projet, mon recrutement en tant que DSI/CIO de Flovéa est acté depuis début avril. J’ai le plaisir de rejoindre une belle équipe pour réaliser un beau projet tant d’un point de vue technique que d’un point de vue du sens et de son utilité. La seule ombre au tableau étant le contexte de pénurie de composants qui illustre bien la dimension “hard” d’un projet “hardware”.
Web, Ops, IoT et Time Series - Mars 2022
Conteneur et Orchestration
- Docker Engine 20.10.13 : Docker compose v2 arrive dans docker : ce qui permet de faire
docker compose(au lieu de l’originaldocker-composecoté en python) COPY --chmodreduced the size of my container image by 35% : pour réduire la taille de vos images, plutôt que de faire unADD ...puis unRUN chmod ..., faites directement unADD/COPY --chmod. Marche aussi avec--chown.- Docker Compose > depends > condition: ready :
depends_ona une syntaxe longue qui permet de définir une condition sur l’état du service dépendant : démarré (valeur par défaut de la version courte), “sain” (en fonction du résultat d’un healthcheck) ou “terminé avec succès” (si votre service dépend du résultat d’un job ou d’une tâche).
Numérique
- LCC 273 - Interview sur le darwinisme numérique avec Didier Girard - partie 1, LCC 274 - Interview le darwinisme numérique avec Didier Girard - partie 2 et LCC 275 - Interview sur le darwinisme numérique avec Didier Girard - partie 3 : interview en 3 volets de Didier Girard sur la notion de darwinisme numérique au niveau d’une nation, d’une entreprise et de l’individu.
Open Data
- adresse.data.gouv.fr : le site national des adresses dont l’objectif est de référencer l’intégralité des adresses du territoire et les rendre utilisables par tous.
Outils
- GitUI : si vous trouvez
tigpas très intuitif/pratique, GitUI pourrait vous plaire. Prévu pour le terminal, il permet de se ballader facilement dans votre historique git & co. L’ outil en codé en Rust. - igrep : un grep interactif qui permet d’ouvrir le fichier dans un éditeur et d’aller directement à la ligne contenant le motif recherché. Basé sur l’excellent ripgrep.
Python
- Awesome AGSI : liste de ressources compatibles ASGI (Asynchronous Server Gateway Interface)
- Demystifying Python’s Async and Await Keywords : une intro à async/await avec asyncio.
- Python’s zipfile: Manipulate Your ZIP Files Efficiently : le module zipfile inclus dans la librairie standard Python permet de manipuler aisément des archives Zip. La page illustre les différentes méthodes et capacités du module.
- How to Write User-friendly Command Line Interfaces in Python : si le module
argparseest assez connu et peut être aussi Fire, c’est l’occasion de découvrir Click (par l’équipe derrière Flask & co et à ne pas confondre avec clikt en Kotlin), Typer (par le fondateur de FastAPI). - Build a User-Friendly CLI from Pure Python Functions : suite de l’article précédent avec la mise en place de DynaCLI dont le but est de générer des CLI depuis des fonctions pythons “pures”.
- Pass-by-value, reference, and assignment | Pydon’t 🐍 : Python passe-t-il ses variables par valeur ? par référence ou par assignement ?
- (Dajngo) Classy Class-Based Views : une représentation détaillée des méthodes, attributs et propriétés des “Class based views” de Django
- Fugue and DuckDB: Fast SQL Code in Python : Fugue permet de combiner du SQL et du code Python et DuckDB permet de faire tourner une base OLAP. De quoi accélérer le traitement de vos données en python ?
RGPD & Privacy Shield
- “Privacy Shield 2.0”? - First Reaction by Max Schrems : La Commission Européenne et les USA ont annoncé une nouvelle version du Privacy Shield. Max Schrems est sceptique pour le moment…
- Google Analytics 4 (GA4) vs Universal Analytics (UA) : Matomo se livre à un comparatif et une analyse (forcément un peu biaisés) de Google Analytics 4 vs Universal Analytics. Dans tous les cas, la conclusion est de prendre une solution qui répond à vos critères et respectent les règles du jeu (GDPR, etc).
Web, Ops, IoT et Time Series - Février 2022
Code & Langages
- httpx : en gros, requests mais avec le support de l’asynchrone. L’API semble être la même. httpx peut aussi s’installer en tant que cli.
- The Algorithms - Go : collection d’implémentation d’algorithme en Go à fin d’apprentissage
Fonts
- Luciole : La police Luciole a été créée à destination des personnes malvoyantes et apporte un certain confort de lecture et une meilleure lisibilité.
Hardware
- The Semiconductor Ecosystem – Explained : Pour ceux qui veulent en connaitre un peu plus sur le monde des semi-conducteurs.
IoT
- Anomaly Detection: Glimpse into the Future of IoT Data : intéressant le triplet Objet IoT, Edge / Data Routeur capable de réaliser des opérations et le noeud central. L’edge computing permet d’éviter de saturer le noeud central et de prendre des décisions au plus près de l’objet IoT.
Ops
- Announcing Traefik Proxy 2.6 : amélioration sur le protocole HTTP/3, nouveaux middleware de “rate-limiting” au niveau TCP, amélioration au niveau de la Kubernetes API Gateway ou encore support de Consul Enterprise.
- Firecracker v1.0.0 : la MicroVM créée par AWS pour Fargate et Lambda passe en version 1.0
- Podman v4.0 has been released! : nouvelle verison do podman avec pas mal de nouveautés.
- Introducing Nebula, the open source global overlay network from Slack : Présentation de nebula, la solution de connectivité de Slack qui a remplacé leur VPN basé sur IPSEC.
- Our User-Mode WireGuard Year : retour d’expérience de Fly.io sur leur usage de Wireguard pour permettre un accès SSH à leur VMs / Conteneur dockers.
- Le réseau de zéro - Partie 1 & Partie 2 : pour comprendre ce qu’il se trame sur votre réseau en partant de zéro.
Outils
- jless — a command-line JSON viewer : un outil en ligne de commande pour parcourir/explorer vos fichiers JSON.
RGPD & Vie Privée
- Utilisation de Google Analytics et transferts de données vers les États-Unis : la CNIL met en demeure un gestionnaire de site web : vers une interdiction partielle ou complète de Google Analytics ? Prochaine cible, les Google Fonts ?
- Google Analytics : retour sur la mise en demeure de la CNIL : une synthèse en l’état de la situation par NextInpact.
Time Series
- Year of the Tiger: $110 million to build the future of data for developers worldwide : Timescale fait une 3ème levée de 110 M$ et atteint le statut de licorne avec une valorisation à 1 Mds $
- Time Series Feature Extraction Library (TSFEL for short) : Bibliothèque Python à destination des Data Scientistes permettant d’extraire des features de séries temporelles avec 60 fonctions statistiques / temporelles / …
- Increase your storage savings with TimescaleDB 2.6: Introducing compression for continuous aggregates : Version 2.6 de TimescaleDB avec principalement de la compression autour des “continous aggregation”.
Bilan 2021 et perspectives 2022
Routine habituelle de début d’année pour la clôture de ce 5ème exercice (déjà !).
Bilan 2021
Au global, une année mitigée qui se termine un peu sur le fil du rasoir au niveau comptable. Pour la partie positive, j’ai l’impression que cette année a été “l’année des possibles” où les efforts commencés les années précédentes commencent à payer. Des premiers projets en Go, des missions Time Series intéressantes et ambitieuses par certains aspects et un projet annexe en Python/Django sur la fin d’année qui consolide différents éléments permettant de gagner en confiance et de réduire un peu ce cher syndrome de l’imposteur avec lequel j’apprends à composer et à dépasser parfois.
Web, Ops, IoT et Time Series - Janvier 2022
IDE
- Gitpod à la place d’Intellij ou de VSCode ? : Si l’IDE dans le cloud vous intéresse, cet article est assez détaillé sur sa mise en place et sa personnalisation.
IoT
- Use MQTT with the Wio Terminal and TinyGo : TinyGo est une version de Go à destination des micro-controlleurs. Le billet d’écrit comment s’abonner à un topic MQTT et afficher un message sur le Wio Terminal.
- openHAB 3.2 Release : cette version apporte notamment des améliorations au niveau du moteur de règle avec un version Javascript, le support de Blockly ou encore d’un modèle de règle (rule template).
- stm32duino wiki : si vous envisagez de faire un projet arduino avec des cartes ST Micro Electronics STM32…
- MQTT 101 Tutorial: Introduction and Hands-on using Eclipse Mosquitto : Introduction et éventuel atelier pratique pour découvrir MQTT avec le broker Mosquitto.
- MQTT Essentials : si vous avez besoin de vous (re)mettre à niveau sur MQTT, une série de billets couvrant les différents aspects du protocole et son fonctionnement.
- MQTT5 Essentials : la suite avec un focus sur les apports de MQTT v5.
Monitoring & Observabilité
- Introducing Grafana University: our virtual hands-on education platform that’s free and easy to use : Grafana Labs ouvre les portes de son université pour se former à ses produits.
Python
- Socket Programming in Python (Guide) : Pour tout savoir sur les sockets en Python.
Réseau
- Introducing ‘innernet’ : innernet est un gestionnaire de réseau basé sur WireGuard. Il permet de déclarer l’ensemble de votre réseau wireguard et de définir des politiques réseaux (VLAN, Associations, etc)
Time Series
- lmmentel /awesome-time-series : un dépot github recensant des projets / librairies / ouvrages / documentation sur les séries temporelles.
- InfluxDB FDW 1.1.1 released : InfluxDB FDW est un Foreign Data Wrapper pour Postgresql 10+ qui permet de se connecter à une source InfluxDB 1.x
- Santa asset tracking and delivery service : une démo de suivi d’actif avec Warp 10 et Discovery en prenant l’exemple de la livraison des cadeaux de Noel.
Web
- GoAccess 1.4, a detailed tutorial : en cherchant à déployer une instance AWStats pour avoir des statistiques de visites sur la base des logs du serveur web nginx, je suis tombé sur GoAccess qui semble offir les mêmes fonctionnalités et même plus tout en étant plus simple à déployer/configurer.
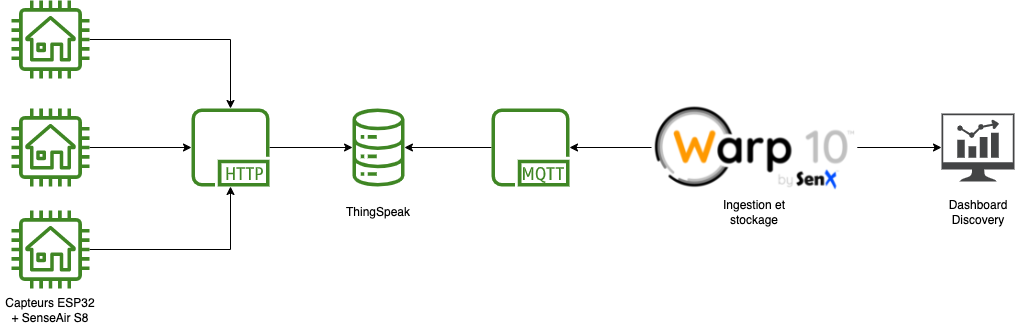
IoT - Qualité de l'air avec un esp32 (TTGo T-Display), le service ThingSpeak, du MQTT, Warp 10 et Discovery
Le projet Nous Aérons propose de réaliser ses propres détecteurs de CO2 avec un ESP32 avec un écran comme le Lilygo TTGo T-Display et un capteur Senseair S8-LP.
L’idée est donc de déployer plusieurs capteurs, faire remonter les valeurs via ThingSpeak et ensuite les ingérer puis analyser avec Warp 10 et faire un dashboard avec Discovery.
Montage
Pour le montage, je vous invite à consuler principalement :
- Capteur de CO2 et le code
- Les instructions des projets “BEL AIR” et “GRAND AIR” à récupérer via le site de Nous Aérons
- Premiers pas ESP32 : Application de démo du TTGO T-Display : pour la configuration d’Arduino IDE - pour l’application de démo, les chemins ont changé par contre.
- Sous OSX, j’ai du récupérer la version 1.6+ du driver du chipset et être en mesure d’avoir le port
/dev/cu.wchusbserial*afin de pouvoir uploader le code depuis Arduino IDE vers l’ESP32.
ThingSpeak
L’exemple de code fourni utilise le service ThingSpeak pour la remontée des valeurs. Comme il s’agit de mon premier projet Arduino et que cela fonctionne, j’ai cherché à rester dans les clous du code proposé et tester par la même occasion ce service. J’aurais pu directement poster les valeurs sur mon instance Warp 10 mais c’est aussi l’occasion de tester la récupération d’informations via le client MQTT de Warp 10.
Web, Ops, Data et Time Series - Décembre 2021
Code & Frameworks
- Django 4.0 released : compatible python 3.8+, il appot son lot de nouveautés et notamment la capacité de personnaliser un peu plus le rendu des formulaires pour ce qui me concerne.
Conteneurs & Orchestration
- Anti-Patterns When Building Container Images : Jérome Petazzoni donne une liste de mauvaises pratiques et des solutions pour y remédier.
IoT
- “New” old functionality with Raspberry Pi OS (Legacy) : la fondation Raspbery Pi annonce l’arrivée d’un OS 64 bits (enfin) mais aussi la mise à disposition d’une version legacy de Raspberry Pi OS basée sur Debian 10/Buster pour ceux qui rencontrent des problèmes avec le passage à Debian 11/Bullseye.
Monitoring & Observabilité
- Grafana 8.3 released: Recorded queries, panel suggestions, new panels, added security, and more & What’s new in Grafana v8.3 : Ajout d’une recommendation/suggestion de panel, le nouvel alerting est déployé par défaut, Candelstick en mode beta pour les données financières et amélioration du panel GeoMap pour la version OSS. title: “Web, Ops, Data et Time Series - NovemDécembre 2021”
Tests
- RobotFramework : robot opensource d’automatisation tant pour des tests que des process d’automatisation robotique, il semble assez complet pour permettre de faire des tests assez complets tout en proposant une interface relativement simple. A voir ce que cela donne…
- Dredd : pour tester vos API au format Blueprint ou OpenAPI
- Keep calm and release your API in prod : Tavern permet de tester des API HTTP via une déclariaton des scénarios en YAML. Il s’appuie sur pytests, requests et dispose d’une intégration MQTT. Le billet montre un cas d’exemple.
Time Series
- Demystifying the use of the Parquet file format for time series : retour sur le format Parquet et son usage pour des séries temporelles. Au delà de l’explication, il est intéressant de mettre cela en perspective vis à vis d’InfluxData qui a prévu que son moteur de stockage Iox soit notamment basé sur Parquet.
Web, Ops, Data et Time Series - Novembre 2021
Containers & Orchestration
- Announcing General Availability of HashiCorp Nomad 1.2 : Arrivée des “system batchs jobs” prévu pour gérer des jobs à destination du cluster nomad en lui même (purge, backup, etc) et non des clients. Cette version apporte également des améliorations au niveau de l’interface, ainsi que les “nomad pack”, format de distribution de vos applications à destination de nomad.
IoT
- Sortie de Raspberry Pi OS Bullseye et Raspberry Pi 4 à 1,8GHz : Première version de Raspberry Pi OS basée sur Debian 11 et possible overclocking du CPU des RPi4 à 1.8 Ghz (au lieu de 1.5 Ghz)
Monitoring & Observabilité
- Vector v0.18.0 release notes : une version avec beaucoup de changements - je vous laisse aller voir les release notes.
Time Series
Annonces & Produits :
Besoin d'un C(P)TO / Architecte « hands-on » ?
On orchestre, on conçoit — et on code aussi. Parlons de votre plateforme, vos données ou votre projet IoT.
Contactez-nous →